目录
DataFrame 是一个不可变分布式数据集合,它被组织成名为列,类似于关系数据库中的表。作为 SchemaRDD 在 Apache Spark 1.0 中作为实验性特性引入,它们在 Apache Spark 1.3 版本中被重命名为 DataFrames。对于熟悉 Python Pandas DataFrame 或 R DataFrame 的读者来说,Spark DataFrame 是一个类似的概念,它允许用户轻松地使用结构化数据(例如数据表);也有一些差异,因此请适当调整您的期望。
通过对分布式数据集合施加结构,这允许 Spark 用户使用 Spark SQL 或表达式方法(而不是 lambda 表达式)查询结构化数据。在本章中,我们将包括使用两种方法的代码示例。通过结构化您的数据,这允许 Apache Spark 引擎 - 特别是 Catalyst Optimizer - 显著提高 Spark 查询的性能。在 Spark 的早期 API(即 RDDs)中,由于 Java JVM 和 Py4J 之间的通信开销,Python 中执行查询可能会显著变慢。
在本章中,您将了解到以下内容:
- Python 与 RDD 通信
- Spark 的 Catalyst Optimizer 快速回顾
- 使用 DataFrames 加速 PySpark
- 创建 DataFrames
- 简单的 DataFrame 查询
- 与 RDDs 互操作
- 使用 DataFrame API 查询
- 使用 Spark SQL 查询
- 使用 DataFrames 进行准时航班性能分析
Python 到 RDD 通信
每当使用 RDDs 执行 PySpark 程序时,执行作业可能存在较大的开销。如下图所示,在 PySpark 驱动程序中,Spark 上下文使用 Py4j 启动一个 JVM,使用 JavaSparkContext。任何 RDD 转换最初都映射到 Java 中的 PythonRDD 对象。
一旦这些任务被推送到 Spark Worker(s),PythonRDD 对象使用管道启动 Python 子进程,以发送要在 Python 中处理的代码和数据: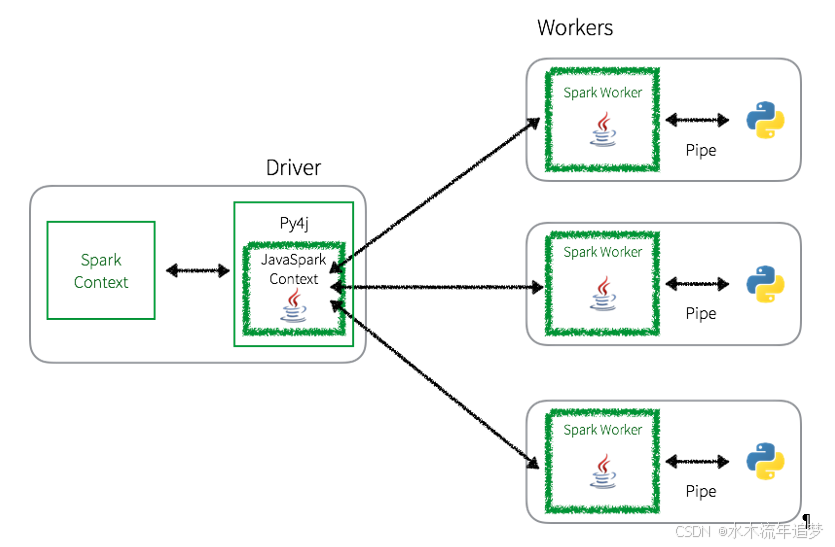
虽然这种方法允许 PySpark 将数据处理分布到多个 worker 上的多个 Python 子进程,但正如您所看到的,Python 和 JVM 之间存在大量的上下文切换和通信开销。
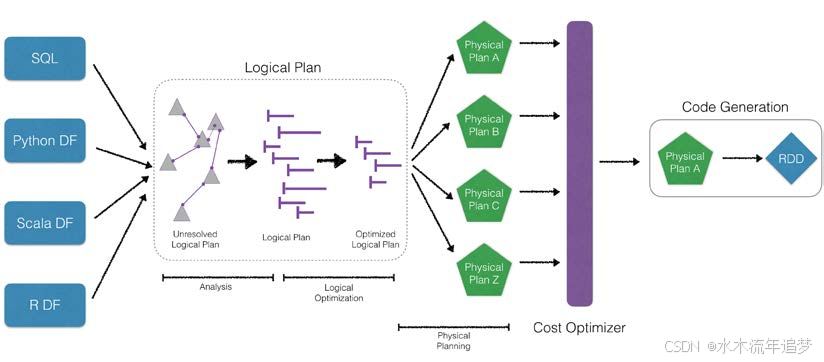
Catalyst Optimizer 回顾
正如“理解 Spark”中所指出的,Spark SQL 引擎之所以如此快速,一个主要原因是 Catalyst Optimizer。对于具有数据库背景的读者来说,这个图看起来类似于关系数据库管理系统(RDBMS)的逻辑/物理规划器和成本模型/基于成本的优化: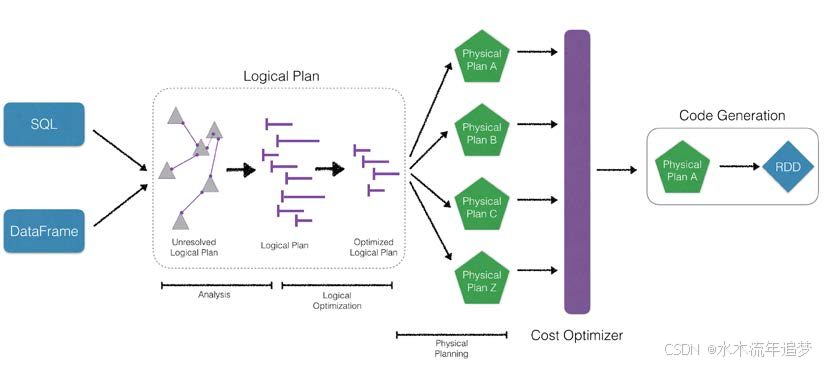
这的重要性在于,与立即处理查询不同,Spark 引擎的 Catalyst Optimizer 编译并优化了一个逻辑计划,并具有成本优化器,它确定生成的最有效的物理计划。
作为 Project Tungsten 的一部分,通过生成字节码(代码生成或 codegen)而不是解释每一行数据,进一步提高了性能。在“理解 Spark”的 Project Tungsten 部分中查找有关 Tungsten 的更多详细信息。
如前所述,该优化器基于函数式编程构造,设计时考虑了两个目的:一是简化向 Spark SQL 添加新的优化技术和特性,二是允许外部开发者扩展优化器(例如,添加特定数据源的规则、对新数据类型的支持等)。
使用 DataFrames 加速 PySpark
DataFrames 以及 Catalyst Optimizer(和 Project Tungsten)的重要性在于与非优化的 RDD 查询相比,PySpark 查询的性能得到了提升。如图中所示,在 DataFrames 引入之前,Python 查询速度通常比使用 RDD 的相同 Scala 查询慢两倍。通常,查询性能的这种下降是由于 Python 与 JVM 之间的通信开销造成的: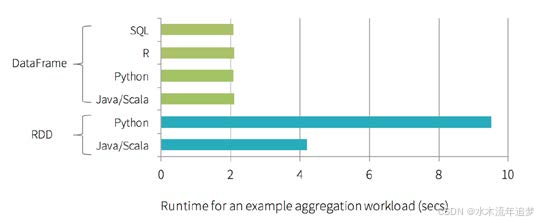
有了 DataFrames,不仅 Python 性能有了显著提升,现在 Python、Scala、SQL 和 R 之间的性能已经一致。
Python 可以利用 Spark 中的性能优化,即使 Catalyst Optimizer 的代码库是用 Scala 编写的。基本上,它是大约 2,000 行代码的 Python 包装器,使得 PySpark DataFrame 查询可以显著加快。
总的来说,Python DataFrames(以及 SQL、Scala DataFrames 和 R DataFrames)都能够利用 Catalyst Optimizer(如下更新的图表所示):