目录
- 0 专栏介绍
- 1 无约束优化与线搜索
- 2 Arjimo准则
- 3 Goldstein准则
- 4 Wolfe准则
- 5 强Wolfe准则
- 6 案例分析与Python实现
-
- 6.1 案例一:Wood函数
- 6.2 案例二:二次型
0 专栏介绍
🔥课设、毕设、创新竞赛必备!🔥本专栏涉及更高阶的运动规划算法轨迹优化实战,包括:曲线生成、碰撞检测、安全走廊、优化建模(QP、SQP、NMPC、iLQR等)、轨迹优化(梯度法、曲线法等),每个算法都包含代码实现加深理解
🚀详情:运动规划实战进阶:轨迹优化篇
1 无约束优化与线搜索
无约束优化问题可形式化为
x ∗ = a r g min x F ( x ) \boldsymbol{x}^*=\mathrm{arg}\min _{\boldsymbol{x}}F\left( \boldsymbol{x} \right) x∗=argxminF(x)
其中 x = [ x 1 x 2 ⋯ x n ] ∈ R n \boldsymbol{x}=\left[ \begin{matrix} x_1& x_2& \cdots& x_n\\\end{matrix} \right] \in \mathbb{R} ^n x=[x1x2⋯xn]∈Rn称为优化变量, F : R n → R F:\mathbb{R} ^n\rightarrow \mathbb{R} F:Rn→R称为目标函数, x ∗ \boldsymbol{x}^* x∗是最优解。
由于目标函数的形式未知,所以上式一般没有解析解,需要通过迭代的方式计算:给定当前迭代点 x k \boldsymbol{x}_k xk,下一次迭代
x k + 1 = x k + α k d k \boldsymbol{x}_{k+1}=\boldsymbol{x}_k+\alpha _k\boldsymbol{d}_k xk+1=xk+αkdk
其中 d k \boldsymbol{d}_k dk是迭代方向向量, α k \alpha _k αk是迭代步长。给定当前迭代点 x k \boldsymbol{x}_k xk,假设已经得到了优化方向 d k \boldsymbol{d}_k dk,本节介绍如何选择合适的步长 α k \alpha _k αk使目标函数尽可能高效地下降,可形式化为一维优化问题
α k ∗ = a r g min α k F ( x k + α k d k ) \alpha _{k}^{*}=\mathrm{arg}\min _{\alpha _k}F\left( \boldsymbol{x}_k+\alpha _k\boldsymbol{d}_k \right) αk∗=argαkminF(xk+αkdk)
直观地,令 ∂ F ( x k + α k d k ) / ∂ α k = 0 {{\partial F\left( \boldsymbol{x}_k+\alpha _k\boldsymbol{d}_k \right)}/{\partial \alpha _k}}=0 ∂F(xk+αkdk)/∂αk=0,可解得
∂ F ( x k + α k d k ) ∂ α k = ∂ F ( x k + 1 ) ∂ x k + 1 ∂ x k + 1 ∂ α k = ∇ T F ( x k + 1 ) d k = 0 \frac{\partial F\left( \boldsymbol{x}_k+\alpha _k\boldsymbol{d}_k \right)}{\partial \alpha _k}=\frac{\partial F\left( \boldsymbol{x}_{k+1} \right)}{\partial \boldsymbol{x}_{k+1}}\frac{\partial \boldsymbol{x}_{k+1}}{\partial \alpha _k}={\nabla ^TF\left( \boldsymbol{x}_{k+1} \right) \boldsymbol{d}_k=0} ∂αk∂F(xk+αkdk)=∂xk+1∂F(xk+1)∂αk∂xk+1=∇TF(xk+1)dk=0
通过上述过程计算 α k \alpha _k αk的方法称为精确线搜索。精确线搜索对一些无约束最优化方法的有限终止起着关键作用,但对一般问题而言,其带来的计算复杂度无法接受。
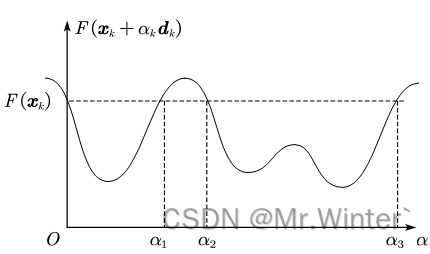
取而代之的是非精确线搜索,其核心原理是通过设置判定准则来近似 。事实上,所有满足 F ( x k + α k d k ) < F ( x k ) F\left( \boldsymbol{x}_k+\alpha _k\boldsymbol{d}_k \right) <F\left( \boldsymbol{x}_k \right) F(xk+αkdk)<F(xk)的步长都是可接受的,如图所示的搜索区域
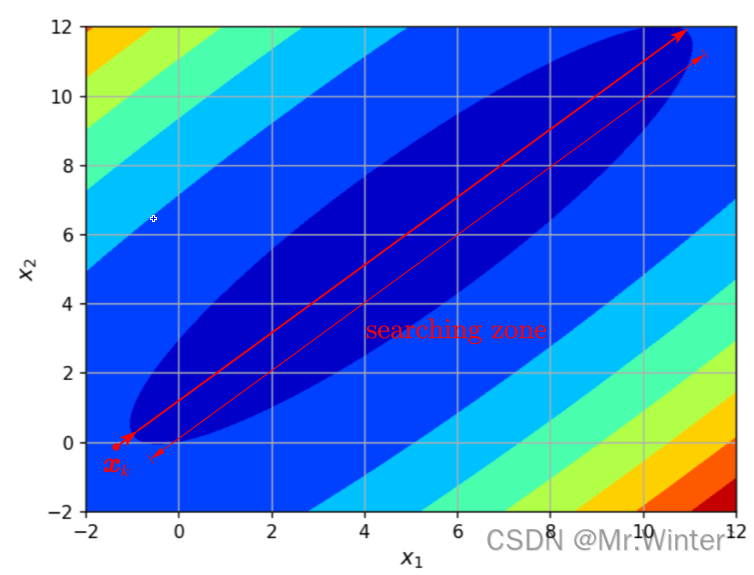
方便起见,将线搜索投影到一维如图所示,可接受的步长区间为 ( 0 , α 1 ) \left( 0,\alpha _1 \right) (0,α1)与 ( α 2 , α 3 ) \left( \alpha _2,\alpha _3 \right) (α2,α3),但在这些区间内任意取值可能会导致效率低下,例如取到 0 + 0^+ 0+或 α 3 − \alpha _{3}^{-} α3−,对应于图中的等值边界。为了使迭代速度更快,需要引入额外的约束
2 Arjimo准则
Arjimo准则选择的步长 α \alpha α需要满足
F ( x k + α d k ) ⩽ F ( x k ) + ρ α ∇ T F ( x k ) d k , ρ ∈ ( 0 , 1 ) F\left( \boldsymbol{x}_k+\alpha \boldsymbol{d}_k \right) \leqslant F\left( \boldsymbol{x}_k \right) +\rho \alpha \nabla ^TF\left( \boldsymbol{x}_k \right) \boldsymbol{d}_k, \rho \in \left( 0,1 \right) F(xk+αdk)⩽F(xk)+ρα∇TF(xk)dk,ρ∈(0,1)
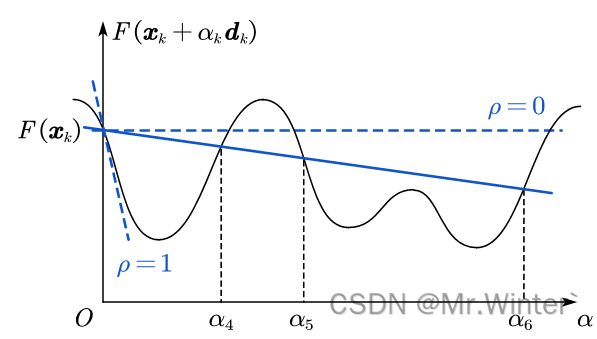
其中 ρ \rho ρ一般可取为 1 0 − 3 10^{-3} 10−3。上式右侧是关于 α \alpha α的线性减函数,其斜率由 ρ \rho ρ控制。如图所示,满足Armijo准则的可选区间为 ( 0 , α 4 ) \left( 0,\alpha _4 \right) (0,α4)与 ( α 5 , α 6 ) \left( \alpha _5,\alpha _6 \right) (α5,α6)。直观地,应用Armijo准则后可以避免 α \alpha α过大而接近右边界
3 Goldstein准则
Goldstein准则选择的步长 α \alpha α需要满足
F ( x k + α d k ) ⩽ F ( x k ) + ρ α ∇ T F ( x k ) d k F ( x k + α d k ) ⩾ F ( x k ) + ( 1 − ρ ) α ∇ T F ( x k ) d k F\left( \boldsymbol{x}_k+\alpha \boldsymbol{d}_k \right) \leqslant F\left( \boldsymbol{x}_k \right) +\rho \alpha \nabla ^TF\left( \boldsymbol{x}_k \right) \boldsymbol{d}_k\\F\left( \boldsymbol{x}_k+\alpha \boldsymbol{d}_k \right) \geqslant F\left( \boldsymbol{x}_k \right) +\left( 1-\rho \right) \alpha \nabla ^TF\left( \boldsymbol{x}_k \right) \boldsymbol{d}_k F(xk+αdk)⩽F(xk)+ρα∇TF(xk)dkF(xk+αdk)⩾F(xk)+(1−ρ)α∇TF(xk)dk
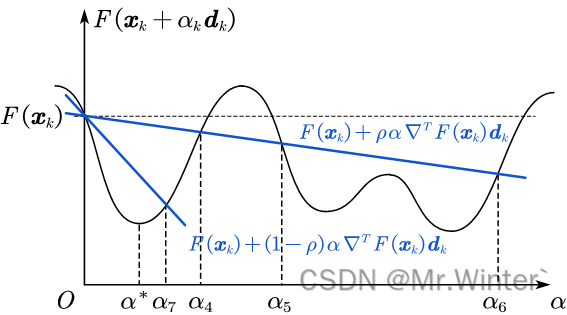
Goldstein准则通过引入下界函数改进了Armijo准则没有对步长下限做限制的缺陷。如图所示,满足Goldstein准则的可选区间为 ( α 7 , α 4 ) \left( \alpha _7,\alpha _4 \right) (α7,α4)与 ( α 5 , α 6 ) \left( \alpha _5,\alpha _6 \right) (α5,α6),避免取到 0 + 0^+ 0+值
4 Wolfe准则
Wolfe准则选择的步长 α \alpha α需要满足
F ( x k + α d k ) ⩽ F ( x k ) + ρ α ∇ T F ( x k ) d k ∇ T F ( x k + α d k ) d k ⩾ σ ∇ T F ( x k ) d k F\left( \boldsymbol{x}_k+\alpha \boldsymbol{d}_k \right) \leqslant F\left( \boldsymbol{x}_k \right) +\rho \alpha \nabla ^TF\left( \boldsymbol{x}_k \right) \boldsymbol{d}_k\\\nabla ^TF\left( \boldsymbol{x}_k+\alpha \boldsymbol{d}_k \right) \boldsymbol{d}_k\geqslant \sigma \nabla ^TF\left( \boldsymbol{x}_k \right) \boldsymbol{d}_k F(xk+αdk)⩽F(xk)+ρα∇TF(xk)dk∇TF(xk+αdk)dk⩾σ∇TF(xk)dk
其中 0 < ρ < σ < 1 0<\rho <\sigma <1 0<ρ<σ<1。Goldstein准则虽然避免取到步长左边界,但下界函数过于松弛导致可能错过最优解,例如上面那张图中的最优 α ∗ \alpha^* α∗不在选择区间内。考虑到最优点位置是平坦的,Wolfe准则通过梯度约束保证最优值在候选区间内。如图所示,满足Wolfe准则的可选区间为 ( α 8 , α 4 ) \left( \alpha _8,\alpha _4 \right) (α8,α4)、 ( α 9 , α 10 ) \left( \alpha _9,\alpha _{10} \right) (α9,α10)与 ( α 11 , α 6 ) \left( \alpha _{11},\alpha _6 \right) (α11,α6),避免取到边界值的同时保留了最优值
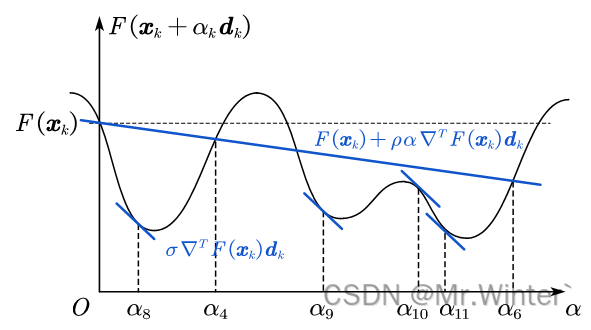
5 强Wolfe准则
强Wolfe准则选择的步长 α \alpha α需要满足
F ( x k + α d k ) ⩽ F ( x k ) + ρ α ∇ T F ( x k ) d k ∣ ∇ T F ( x k + α d k ) d k ∣ ⩽ σ ∣ ∇ T F ( x k ) d k ∣ F\left( \boldsymbol{x}_k+\alpha \boldsymbol{d}_k \right) \leqslant F\left( \boldsymbol{x}_k \right) +\rho \alpha \nabla ^TF\left( \boldsymbol{x}_k \right) \boldsymbol{d}_k\\\left| \nabla ^TF\left( \boldsymbol{x}_k+\alpha \boldsymbol{d}_k \right) \boldsymbol{d}_k \right|\leqslant \sigma \left| \nabla ^TF\left( \boldsymbol{x}_k \right) \boldsymbol{d}_k \right| F(xk+αdk)⩽F(xk)+ρα∇TF(xk)dk∣∣∇TF(xk+αdk)dk∣∣⩽σ∣∣∇TF(xk)dk∣∣
其中令 σ → 0 \sigma \rightarrow 0 σ→0将导致 ∇ T F ( x k + α d k ) d k → 0 \nabla ^TF\left( \boldsymbol{x}_k+\alpha \boldsymbol{d}_k \right) \boldsymbol{d}_k\rightarrow 0 ∇TF(xk+αdk)dk→0,所以强Wolfe准则是对精确线搜索的近似,一般取 。如图所示,满足强Wolfe准则的可选区间为 ( α 8 , α 12 ) \left( \alpha _8,\alpha _{12} \right) (α8,α12)、 ( α 9 , α 13 ) \left( \alpha _9,\alpha _{13} \right) (α9,α13)与 ( α 11 , α 14 ) \left( \alpha _{11},\alpha _{14} \right) (α11,α14)
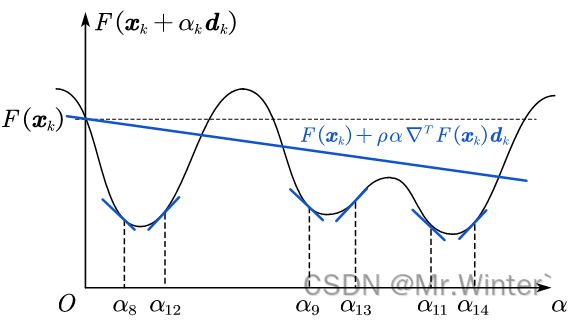
6 案例分析与Python实现
非精确线搜索可视为二分法结合上述判定准则。首先给定一个初始搜索区间 [ 0 , α max ] \left[ 0,\alpha _{\max} \right] [0,αmax]并开始二分查找直到找到满足准则的步长。基于此算法原理编写线搜索框架
def _inexactLineSearch(self, func, g_func, x: np.array, d: np.array) -> float:
start_time = time.time()
fx, gx = func(x), g_func(x)
gx_d = gx.T @ d
# initial interval
start, end = self.alpha_0, self.alpha_0
while func(x + end * d) <= fx + self.rho * end * gx_d:
end = end * self.gamma
iter_num = 0
alpha = self.alpha_0
while iter_num < self.max_iters:
f_alpha, g_alpha = func(x + alpha * d), g_func(x + alpha * d)
if abs(start - end) < 1e-15:
alpha_star = alpha
min_value = f_alpha
break
# Armijo condition
condition_1 = (func(x + alpha * d) <= fx + self.rho * alpha * gx_d)
# other criterion
condition_2 = True
if self.criterion == "Goldstein":
condition_2 = (f_alpha >= fx + (1 - self.rho) * alpha * gx_d)
elif self.criterion == "Wolfe":
condition_2 = (g_alpha.T @ d >= self.sigma * gx_d)
elif self.criterion == "Strong Wolfe":
condition_2 = (abs(g_alpha.T @ d) <= self.sigma * abs(gx_d))
# update start or end point or stop iteration
if condition_1 and condition_2:
alpha_star = alpha
min_value = f_alpha
break
else:
if self.interpolation_type == "bisection":
alpha = (start + end) / 2
elif self.interpolation_type == "quadratic":
g_start = g_func(x + start * d).T @ d
g_end = g_func(x + end * d).T @ d
if g_start < 0 and g_end > 0:
alpha = self._quadraticInterpolation(
start, end, func(x + start * d), func(x + end * d), g_start
)
else:
alpha = (start + end) / 2
elif self.interpolation_type == "cubic":
g_start = g_func(x + start * d).T @ d
g_end = g_func(x + end * d).T @ d
if g_start < 0 and g_end > 0:
alpha = self._cubicInterpolation(
start, end, func(x + start * d), func(x + end * d), g_start, g_end
)
else:
alpha = (start + end) / 2
if g_func(x + alpha * d).T @ d > 0:
end = alpha
else:
start = alpha
iter_num += 1
end_time = time.time()
if self.verbose:
print("===========================================================")
print(f"Method: inexact line searching")
print(f"Criterion: {self.criterion}")
print(f"Interpolation type: {self.interpolation_type}")
print(f"Iterations: {iter_num}, Using time: {end_time - start_time}")
print(f"Start Point: {x}")
print(f"Start Value: {fx}")
print(f"Step: {alpha_star}")
print(f"End Point: {x + d * alpha_star}")
print(f"End Value: {min_value}")
print("===========================================================\n")
return alpha_star
6.1 案例一:Wood函数
Wood函数是数值优化实验中常用的测试函数,其表达式为
f ( x ) = 100 ( x 1 2 − x 2 ) 2 + ( x 1 − 1 ) 2 + ( x 3 − 1 ) 2 + 90 ( x 3 2 − x 4 ) 2 + 10.1 ( ( x 2 − 1 ) 2 + ( x 4 − 1 ) 2 ) + 19.8 ( x 2 − 1 ) ( x 4 − 1 ) f(x)=100(x_1^2-x_2)^2+(x_1-1)^2+(x_3-1)^2+90(x_3^2-x_4)^2+10.1((x_2-1)^2+(x_4-1)^2) + 19.8(x_2-1)(x_4-1) f(x)=100(x12−x2)2+(x1−1)2+(x3−1)2+90(x32−x4)2+10.1((x2−1)2+(x4−1)2)+19.8(x2−1)(x4−1)
假设给定初始梯度
d = [ 2 , 1 , 2 , 1 ] T d = [2,1,2,1]^T d=[2,1,2,1]T
则优化结果为
===========================================================
Method: inexact line searching
Criterion: Strong Wolfe
Interpolation type: bisection
Iterations: 2, Using time: 0.11269879341125488
Start Point: [-3 -1 -3 -1]
Start Value: 19192.0000000000
Step: 1.4551922728366853
End Point: [-0.08961545 0.45519227 -0.08961545 0.45519227]
End Value: 52.2382627586798
===========================================================
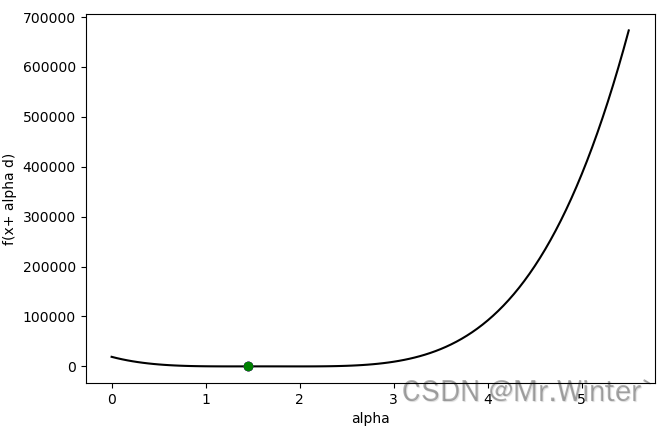
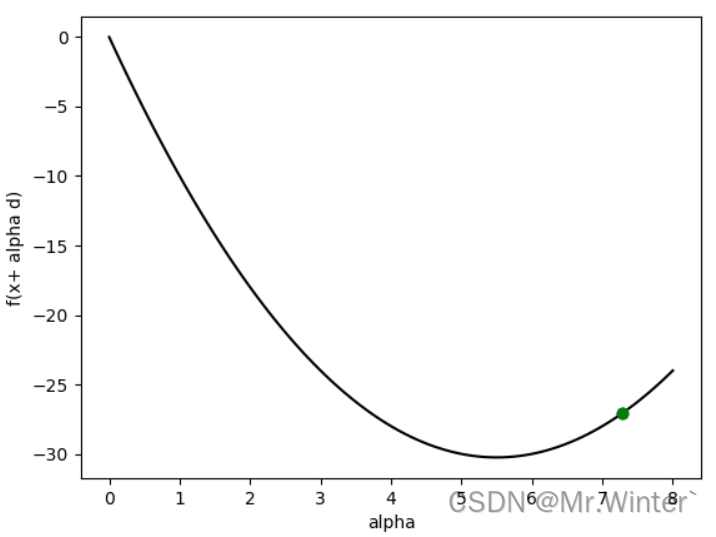
6.2 案例二:二次型
二次型是常用的数值优化形式,给定
f ( x ) = 1 2 x T Q x + q T x f\left( \boldsymbol{x} \right) =\frac{1}{2}\boldsymbol{x}^T\boldsymbol{Qx}+\boldsymbol{q}^T\boldsymbol{x} f(x)=21xTQx+qTx
其中
Q = [ 10 − 9 − 9 10 ] , q = [ 4 − 15 ] \boldsymbol{Q}=\left[ \begin{matrix} 10& -9\\ -9& 10\\ \end{matrix} \right] , \boldsymbol{q}=\left[ \begin{array}{c} 4\\ -15\\ \end{array} \right] Q=[10−9−910],q=[4−15]
假设给定初始梯度
d = [ 1 , 1 ] T d = [1,1]^T d=[1,1]T
则优化结果为
===========================================================
Method: inexact line searching
Criterion: Strong Wolfe
Interpolation type: bisection
Iterations: 1, Using time: 0.004987001419067383
Start Point: [0 0]
Start Value: 0
Step: 7.2759581141834255
End Point: [7.27595811 7.27595811]
End Value: -27.0959727766661
===========================================================
完整工程代码请联系下方博主名片获取
🔥 更多精彩专栏: