hadoop3.3x和hive4.0安装部署
为什么我要安装hive4.0,因为阿里云镜像只有hive4.0

软件相互兼容性版本
系统centos7
uname -a如果内核3.0以上可以用
安装jdk1.8以上的版本(配置好环境变量)
hadoop3.3.x与hive4.0.x
1.请自行安装java
2.关闭防火墙
3.创建用户
useradd hadoop
passwd hadoop改密码,12345678
su hadoop
配置免密
ssh-keygen -t rsa
一直回车
cd ~/.ssh
#将公钥复制到公钥库
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
4.安装hadoop
1.上传安装文件到目录,解压
2.配置环境变量
vi /etc/profile
export HADOOP_HOME=/usr/local/service/hadoop-3.3.5
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
source /etc/profile
hadoop version此时正常输出

3.hadoop-env.sh修改
vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_251
export HADOOP_HOME=/usr/local/service/hadoop-3.3.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
source hadoop-env.sh
4.core-site.xml修改
vim core-site.xml
<configuration>
<!--用来指定hdfs主节点的访问端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.188.10:9000</value>
</property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/service/hadoop-3.3.5/tmp</value>
</property>
</configuration>
5.编辑hdfs配置文件
vi hdfs-site.xml
<configuration>
<!--设置名称节点的目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/emr/hadoop/namenode</value>
</property>
<!--设置数据节点的目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/emr/hadoop/datanode</value>
</property>
<!--设置辅助名称节点-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.188.10:50090</value>
</property>
<!--hdfs web的地址,默认为9870,可不配置-->
<!--注意如果使用hadoop2,默认为50070-->
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:9870</value>
</property>
<!--副本数,默认为3-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--是否启用hdfs权限,当值为false时,代表关闭-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
6.修改map配置
vi mapred-site.xml
<configuration>
<!--配置MR资源调度框架YARN-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
7.编辑yarn-site.xml
sudo hostname 192.168.188.10
vi yarn-site.xml
<configuration>
<!--配置资源管理器:192.168.188.10-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.188.10</value>
</property>
<!--配置节点管理器上运行的附加服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--关闭虚拟内存检测,在虚拟机环境中不做配置会报错-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
8.编辑works数
vi works
192.168.188.10
9.格式化namenode
hdfs namenode -format
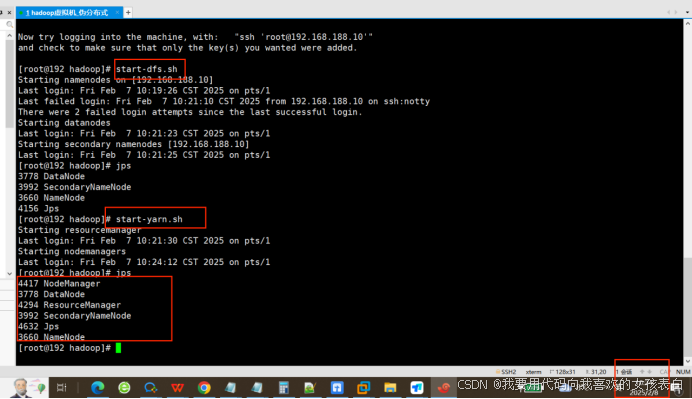
启动hadoop服务
start-dfs.sh
start-yarn.sh
jps
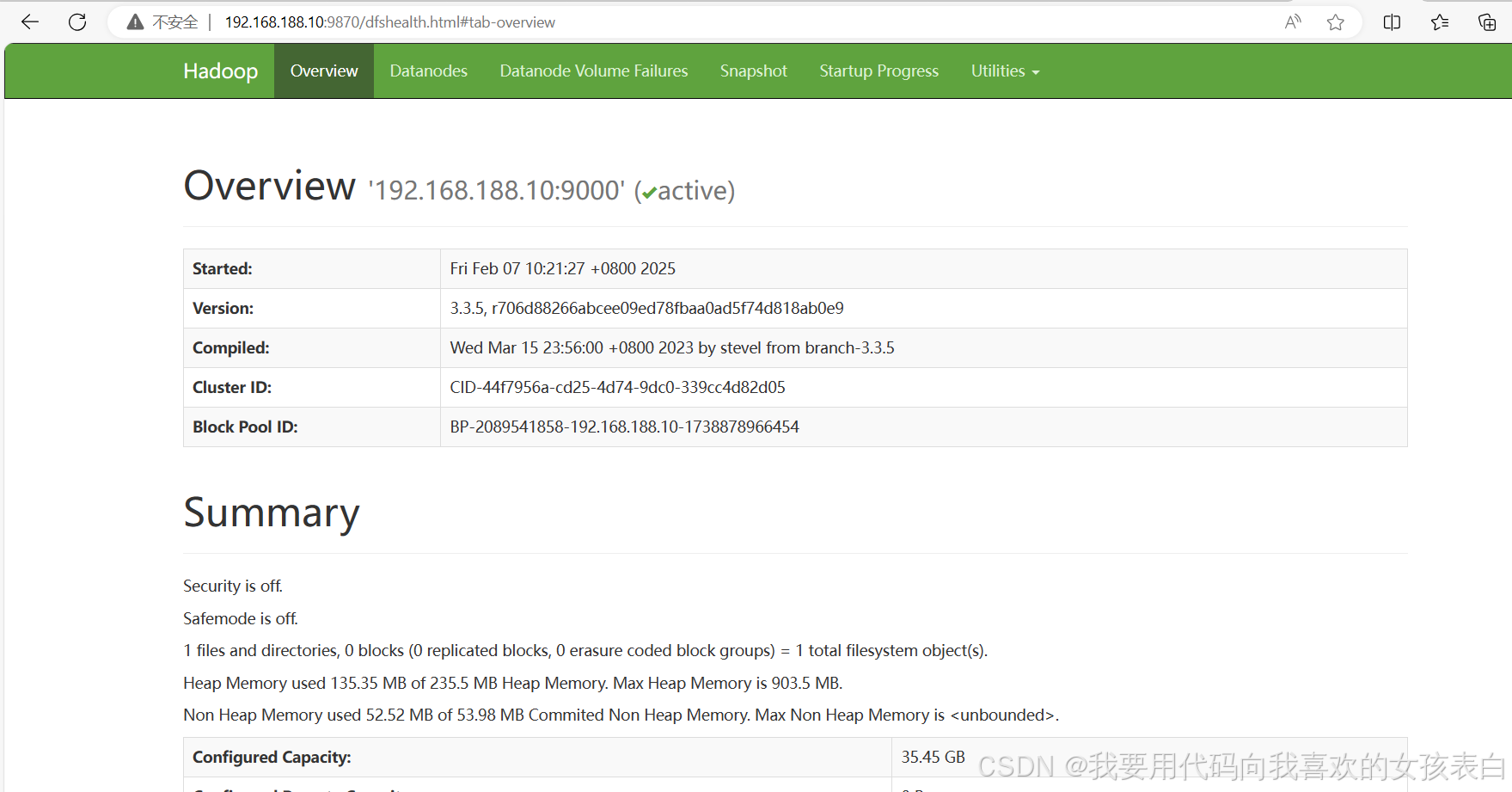
访问namenode界面
192.168.188.10:9870
安装Hive
安装元数据库mysql
卸载maridb
rpm -qa|grep mariadb
rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x86_64
参考:
yum安装有问题加这个,忽略这个 --nogpgcheck
安装hive
tar -zxvf apache-hive-4.0.1-bin.tar.gz -C /usr/local/service/
解决Hive与Hadoop之间guava版本差异
cd /usr/local/service/apache-hive-4.0.1-bin/lib
mv guava-22.0.jar guava-22.0.jar.bak
cp $HADOOP_HOME/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/service/apache-hive-4.0.1-bin/lib
修改hive-env.sh
cp hive-env.sh.template hive-env.sh
vi hive-env.sh
export HADOOP_HOME=/usr/local/service/hadoop-3.3.5
export HIVE_CONF_DIR=/usr/local/service/apache-hive-4.0.1-bin/conf
export HIVE_AUX_JARS_PATH=/usr/local/service/apache-hive-4.0.1-bin/lib
vi hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.188.10:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>ShiTeacherLoveU~520</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>192.168.188.10</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.188.10:9083</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>
上传mysql jar包到hive的lib目录下
https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.49/mysql-connector-java-5.1.49.jar

初始化hive元数据
在hive的目录执行(要保证hadoop正常运行)
bin/schematool -initSchema --dbType mysql -verbos

建立hadoop的hive相关默认文件路径
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
启动hive
mkdir -p /data/hive/logs
cd /usr/local/service/apache-hive-4.0.1-bin/bin
启动metastore
nohup ./hive --service metastore >> /data/hive/logs/metastore.log 2>&1 &
启动hiveserver
nohup ./hive --service hiveserver2 >> /data/hive/logs/hiveserver2.log 2>&1 &
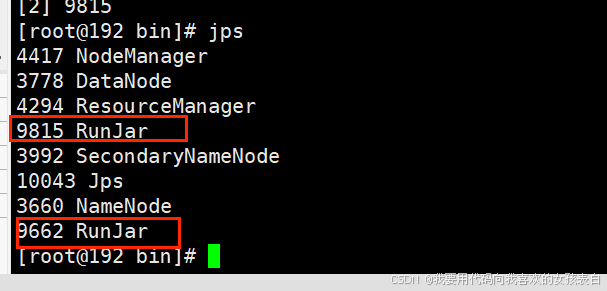
hadoop的core-site.xml里面新增
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
重启hadoop
stop-all.sh
start-all.sh
beeline连接测试
beeline>!connect jdbc:hive2://192.168.188.10:10000
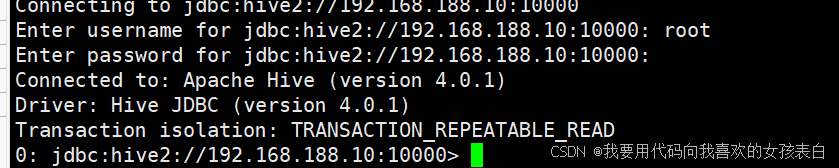
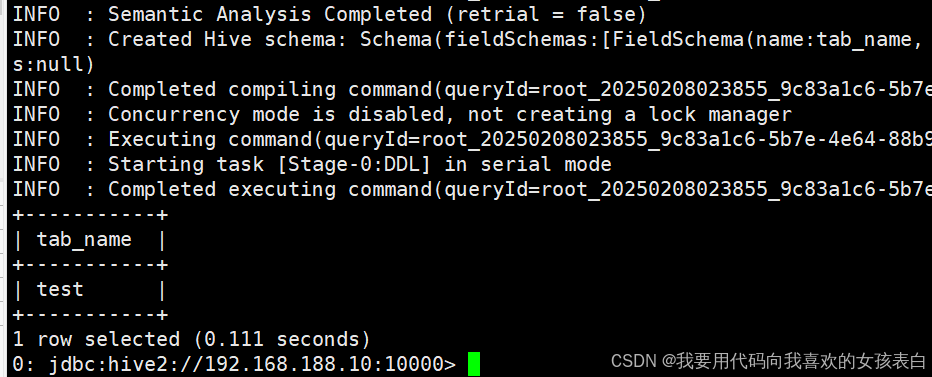
ok,完成。。
此搭建仅作为学习环境,生产需要考虑,kerbers认证以及完全分布式。
参考:
搭建伪分布式Hadoop_hadoop的伪分布式搭建-CSDN博客