统一缓存处理
什么是缓存?缓存优点?为什么要使用缓存?不同场景下缓存的作用?内存缓存淘汰机制?
内存访问速度远大于磁盘响应速度,加一层缓存来平衡两者之间速度,类似于cache
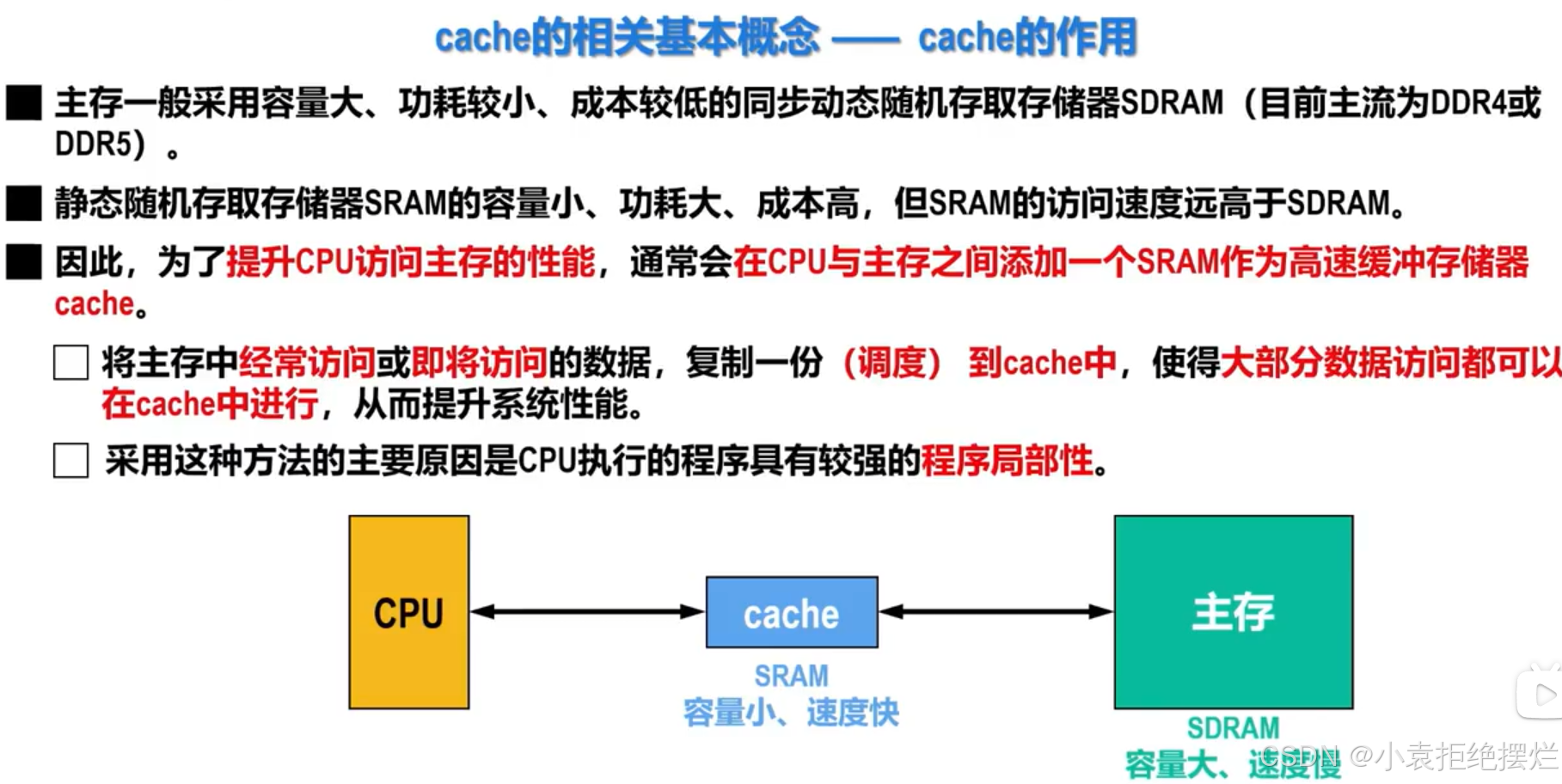
自定义
但在每个接口上加缓存也不太现实,所以我们使用Spring的特性AOP和Redis来实现
注解类
package com.mszlu.blog.common.cache;
import java.lang.annotation.*;
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Cache {
long expire() default 1 * 60 * 1000;
String name() default "";
}
切面类(规定切点和通知的关系)
就是通过缓存名类名方法名参数的md5加密字符串,生成一个key,找redis有没有对应value
有就直接返回
没有调用原方法,再将原方法的返回结果转为json存储到redis中,设置过期时间和key即可
package com.mszlu.blog.common.cache;
@Aspect
@Component
@Slf4j
public class CacheAspect {
@Autowired
private RedisTemplate<String, String> redisTemplate;
@Pointcut("@annotation(com.mszlu.blog.common.cache.Cache)")
public void pt(){}
/**
* 环绕通知方法,用于在目标方法执行前后进行缓存处理。
*
* @param pjp 连接点对象,用于获取目标方法的相关信息并控制方法的执行。
* @return 返回目标方法的执行结果,如果缓存中存在数据则直接返回缓存数据。
*/
@Around("pt()")
public Object around(ProceedingJoinPoint pjp){
try {
// 获取方法签名
Signature signature = pjp.getSignature();
// 获取目标类的简单类名
String className = pjp.getTarget().getClass().getSimpleName();
// 获取目标方法的名称
String methodName = signature.getName();
// 获取方法参数类型和参数值
Class[] parameterTypes = new Class[pjp.getArgs().length];
Object[] args = pjp.getArgs();
// 将参数转换为JSON字符串并进行MD5加密,用于生成缓存键
String params = "";
for(int i=0; i<args.length; i++) {
if(args[i] != null) {
params += JSON.toJSONString(args[i]);
parameterTypes[i] = args[i].getClass();
}else {
parameterTypes[i] = null;
}
}
if (StringUtils.isNotEmpty(params)) {
// 对参数进行MD5加密,防止缓存键过长或字符转义问题
params = DigestUtils.md5Hex(params);
}
// 获取目标方法的Method对象
Method method = pjp.getSignature().getDeclaringType().getMethod(methodName, parameterTypes);
// 获取方法上的Cache注解
Cache annotation = method.getAnnotation(Cache.class);
// 获取缓存过期时间
long expire = annotation.expire();
// 获取缓存名称
String name = annotation.name();
// 生成Redis缓存键
String redisKey = name + "::" + className+"::"+methodName+"::"+params;
// 从Redis中获取缓存值
String redisValue = redisTemplate.opsForValue().get(redisKey);
if (StringUtils.isNotEmpty(redisValue)){
// 如果缓存中存在数据,则直接返回缓存数据
log.info("走了缓存~~~,{},{}",className,methodName);
return JSON.parseObject(redisValue, Result.class);
}
// 执行目标方法
Object proceed = pjp.proceed();
// 将方法执行结果存入Redis缓存
redisTemplate.opsForValue().set(redisKey,JSON.toJSONString(proceed), Duration.ofMillis(expire));
log.info("存入缓存~~~ {},{}",className,methodName);
return proceed;
} catch (Throwable throwable) {
// 捕获并打印异常信息
throwable.printStackTrace();
}
// 返回系统错误结果
return Result.fail(-999,"系统错误");
}
}
使用
可以在这种不经常更改的使用缓存比较好
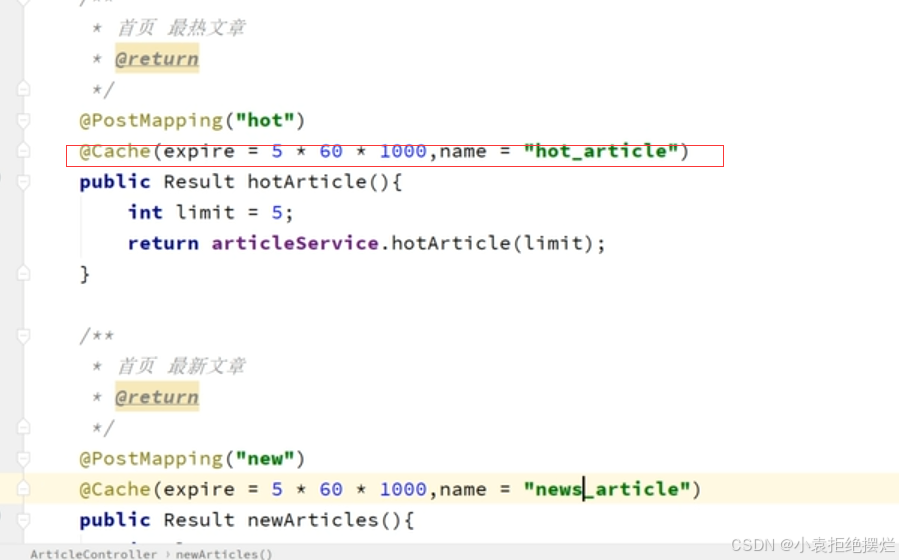
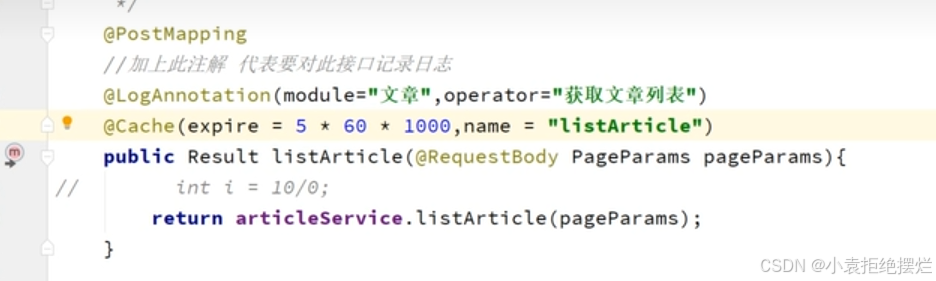
SpringCache
这里我还没学,下回详解
前后端bug
就是我们增加数据时候的id默认是雪花算法,雪花算法按照Long的最大值为最大生成数字
但是

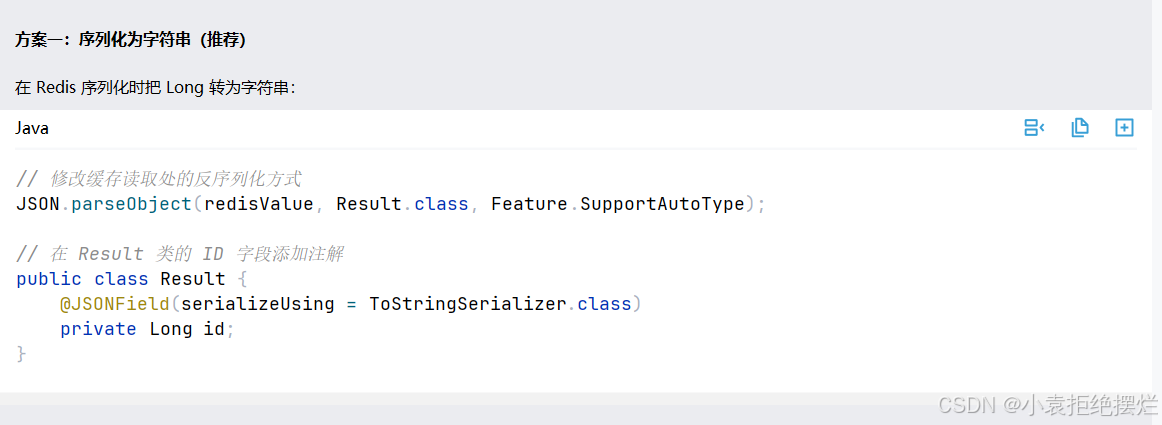
把所有都long类型的id都改成String类型即可
别的优化
