Undo Log(回滚日志)
为什么需要 Undo Log?
1. MySQL 的隐式开启事务
自动提交(autocommit = 1)
- 在默认的自动提交模式下(
autocommit= 1),MySQL 在执行每一条增删改语句时会隐式地开启一个独立的事务,并在执行完成后自动提交。
目的
- 原子性:保证每个“增删改”操作的原子性。
- 提高便携性:对于简单的操作,开发者不需要每次都先
begin后commit来实现事务。
2. 事务回滚——保证事务的原子性和一致性
- 保证原子性:引入 Undo Log 的主要原因是为了实现事务的回滚,以确保事务的原子性。有了回滚的选项后,无论是事务提交前发生崩溃、事务执行过程出错,都可以通过回滚操作来确保原子性。
- 保证一致性:
-
- 事务执行过程中出现异常,通过回滚来防止部分更新,确保一致性。
- 配合 MVCC,确保读取数据的一致性:
-
-
- 可重复读隔离级别:通过 Undo Log 获取数据的历史版本来确保事务执行期间看到数据的一致。
- 快照读:事务读取数据时,通过 Undo Log 获取数据的历史版本,确保读操作不会因为其他事务的修改而破坏一致性。
-
3. 为 MVCC 提供数据的历史版本——(间接)保证事务的隔离性
- 记录数据历史版本,使得 MySQL 可以提供事务的快照:
-
- 当一个数据进行更改时,先将原数据记录到 Unodo Log 中,而不是直接修改数据。
- 这样,在事务执行过程中,即使其他事务已经对该数据进行了更改,当前事务依然可以读取到事务开始时的数据版本——可重复读隔离级别。
实现事务回滚——保证事务的原子性(A)
1. 核心原理
- Undo Log 是一种用于撤销回退的日志,在事务未提交之前,MySQL 会记录更新的数据到 Undo Log 日志文件里,当事务回滚时,就可以利用 Undo Log 进行回滚。
2. 过程如下图
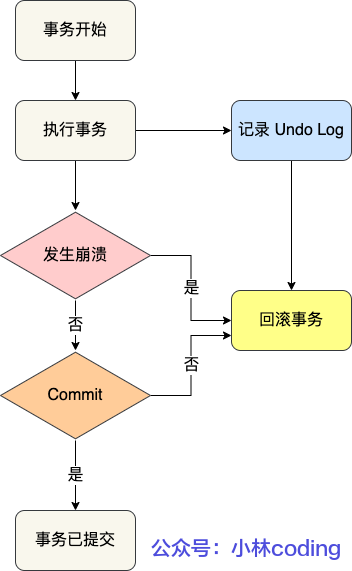
3. 具体实现
Undo Log 是由 InnoDB 提供,当 InnoDB 引擎对一条记录进行操作(插入、删除、更新)时,会按操作类型在 Undo Log 中分别进行不同的记录。
insert回滚:记录这条记录的主键值,回滚时只需要将该主键值对应的记录删除。delete回滚:把对应的记录内容都记下来,回滚时再将这些内容组成记录并插入表中。
-
delete:
-
-
- 具体过程:不会立即删除,将要删除的记录标记为
delete flag,表示已删除,最终的删除操作是由purge线程,择机扫描表中已标记为删除的记录,并进行真正的物理删除。 - 这样实现的目的:
- 具体过程:不会立即删除,将要删除的记录标记为
-
-
-
-
- 性能优化:
delete flag可以避免频繁的磁盘 I/O 操作,提高系统响应速度。 - 避免数据丢失:防止误删或操作不当,让系统管理员更灵活地恢复数据或查看删除历史。
- 并发问题:多个操作同时进行时,频繁地立即响应删除操作(更新索引、调整磁盘存储空间、处理事务锁定、日志记录等)会导致 MySQL 负载严重。
- 缺点:已被标记为删除但未清理的数据,会占用内存空间,只能等到
purge线程延迟清理后,才能释放空间。
- 性能优化:
-
-
update回滚:将更新的列的旧值记录下来,回滚时将新值改为旧值。
-
update:取决于该列是否为主键列。
-
-
- 非主键列:在 Undo Log 中直接反向记录如何
update的,即update操作直接进行。 - 主键列:分两步执行,先删除该行,再插入一行新的数据,主键值是更新后的值,其他列保持不变。
- 非主键列:在 Undo Log 中直接反向记录如何
-
-
-
-
- 目的:
-
-
-
-
-
-
- 主键值决定了数据行的位置:InnoDB 是根据主键值来组织存储的,每行数据存储在聚集索引中,如果直接更新主键,原来数据所在的位置就会发生改变。故要删除原行,插入只有主键列为新值的记录。
- 索引更新:在 InnoDB 中,聚集索引的结构就是数据本身,更新了主键列,相当于改变了数据行在内存中和磁盘上的存储位置,因此索引必须重新调整,以便与新的主键值保持一致。
-
-
-
-
-
-
-
-
- 非聚集索引:当然除了主键索引会直接受影响,其他非聚集索引因为存储的是主键值的引用(存储主键值 + 指向数据行的“行 ID”),因此也必须随主键值而更新。
- 例子:假设你有一个按
user_id升序排列的表,当更新主键时,行的位置会发生变化,新的值3可能会导致数据行需要移动到别的位置,这样原有的主键索引条目就不能再指向正确的位置。
-
-
-
-
-
-
-
-
- Undo Log 回滚记录:为了保证事务的可回滚性,InnoDB 会在 Undo Log 中分别记录这两步操作(删除原记录,插入只有主键列为新值的记录)的反向操作,从而确保即使事务失败,也能恢复原来的状态。
-
-
-
配合 ReadView 实现 MVCC(多版本并发控制)
1. 版本链
一条记录的每一次更新操作产生的 Undo Log 格式都有一个 roll_pointer 回滚指针和一个 trx_id 事务 id:
trx_id:事务 id,通过trx_id就确定记录是由哪个事务修改的,并在回滚时清理特定事务产生的修改,保证事务的原子性与一致性。roll_pointer:回滚指针,指向该数据的前一个版本,通过多个roll_pointer指针可以串成一个链表,表示从最初的数据一直到最新的数据版本,该链表成为版本链。
2. Undo Log 与隔离级别
读未提交(READ UNCOMMITTED)
- 因为可以脏读(读取未提交的数据,事务回滚后数据消失,导致数据不一致性),Undo Log 几乎无作用。
读已提交(READ COMMITTED)
- 提供历史版本数据,支持快照读(Snapshot Read)。
- 事务 A 提交前,事务 B 依然可以读取 Undo Log 里的旧数据,避免脏读。
- 问题:不可重复读(Non-Repeatable Read),即同一事务内对相同数据进行两次读取,可能得到不同的值。
可重复读(REPEATABLE READ)
- 提供当前事务开始时的数据快照,以保证事务在提交前都能读取到一致的版本。
- 即使其他事务提交了新事务,当前事务仍读取 Undo Log 里的旧数据,避免不可重复读。
串行化(SERIALIZABLE)
- 特点:所有事务串行执行,事务之间完全隔离,使用行级锁避免任何并发修改。
- 基本不依赖 Undo Log,因为事务串行执行,不需要 MVCC 提供历史版本数据。
- 问题:性能较低。
3. 通过 ReadView + Undo Log 实现 MVCC(多版本并发控制)
- 控制并发事务访问同一个记录时的行为,称为多版本并发控制(Multi-Version Concurrency Control)。
- 【读已提交】和【可重复读】隔离级别是通过【事务的 ReadView 中的字段】和【记录中的两个隐藏列(
trx_id和roll_pointer)】的比对,如果该记录版本不满足可见行,就会顺着 Undo Log 的版本链依次继续比对,直到满足其可见性为止。