目录
一、MySQL经典数据类型一览:
数值类型:
整数类型:
| 类型 | 存储空间 | 有符号范围 | 无符号范围 | 示例 |
|---|---|---|---|---|
TINYINT |
1 字节 | -128 ~ 127 | 0 ~ 255 | 年龄 |
SMALLINT |
2 字节 | -32768 ~ 32767 | 0 ~ 65535 | 小范围计数 |
MEDIUMINT |
3 字节 | -8388608 ~ 8388607 | 0 ~ 16777215 | 中等范围数值 |
INT |
4 字节 | -2³¹ ~ 2³¹-1 | 0 ~ 2³²-1 | 用户ID、订单号 |
BIGINT |
8 字节 | -2⁶³ ~ 2⁶³-1 | 0 ~ 2⁶⁴-1 | 大整数(如分布式ID) |
- 使用unsigned禁止负数,扩大正数范围
- BOOL类型在MySQL中表现是tinyint的别名,存储0(假)或1(真)
小数类型
| 类型 | 存储空间 | 描述 | 示例 |
|---|---|---|---|
FLOAT |
4 字节 | 单精度浮点数,近似值 | 科学计算数据 |
DOUBLE |
8 字节 | 双精度浮点数,更高精度近似值 | 高精度测量值 |
DECIMAL(M,D) |
变长(M+2字节) | 精确小数,M=总位数,D=小数位 | 金额 DECIMAL(10,2) |
- decimal适合精确计算(如财务数据),避免浮点误差
- float和double可能丢失精度,适合非精确计算
日期和时间类型
| 类型 | 存储空间 | 格式 | 范围 | 示例 |
|---|---|---|---|---|
DATE |
3 字节 | YYYY-MM-DD |
1000-01-01 ~ 9999-12-31 | 生日、事件日期 |
TIME |
3 字节 | HH:MM:SS |
-838:59:59 ~ 838:59:59 | 持续时间 |
DATETIME |
8 字节 | YYYY-MM-DD HH:MM:SS |
1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 | 订单创建时间 |
TIMESTAMP |
4 字节 | Unix时间戳 | 1970-01-01 00:00:01 UTC ~ 2038-01-19 UTC | 最后登录时间(自动更新) |
YEAR |
1 字节 | YYYY |
1901 ~ 2155 | 年份 |
字符串类型
| 类型 | 最大长度 | 描述 | 示例 |
|---|---|---|---|
CHAR(n) |
255 字符 | 定长字符串,适合短且固定长度 | 国家代码 CHAR(2) |
VARCHAR(n) |
65535 字节 | 变长字符串,适合长度变化数据 | 用户名、地址 |
特殊类型
| 类型 | 描述 | 示例 |
|---|---|---|
ENUM |
枚举值(单选) | 性别 ENUM('男','女') |
SET |
集合值(多选) | 标签 SET('A','B','C') |
二、数值类型:
整形家族:
| 数据类型 | 字节数 | 带符号最小值 | 带符号最大值 | 无符号最小值 | 无符号最大值 |
|---|---|---|---|---|---|
| TINYINT | 1 | -128 | 127 | 0 | 255 |
| SMALLINT | 2 | -32768 | 32767 | 0 | 65535 |
| MEDIUMINT | 3 | -8388608 | 8388607 | 0 | 16777215 |
| INT | 4 | -2147483648 | 2147483647 | 0 | 4294967295 |
| BIGINT | 8 | -9223372036854775808 | 9223372036854775807 | 0 | 18446744073709551615 |
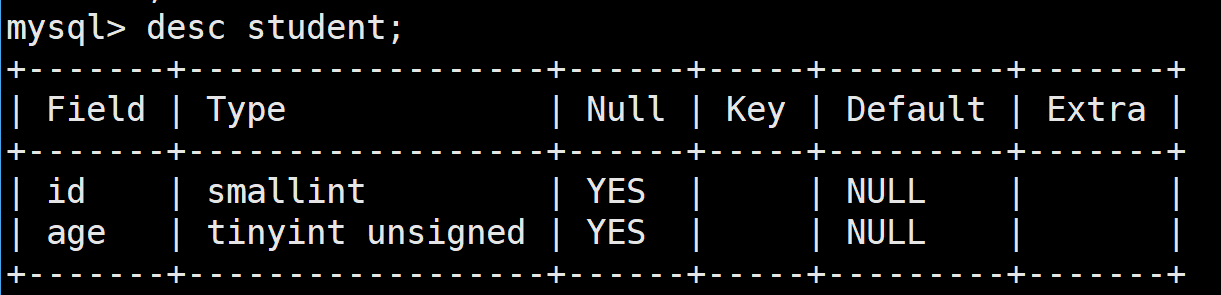
首先用SQL语句创建一个表,在其中测试smallint和tinyint unsigned
注意:SQL语句中创建无符号的类型是在类型后面加上unsigned
SQL语句:
create table if not exists student(
id smallint,
age tinyint unsigned
};
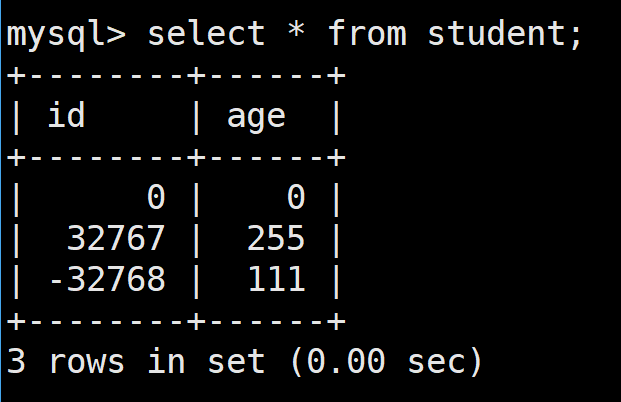
接着我们向表中插入在其范围中的语句,是能够插入的



那我们试试向表中插入不在其中范围的语句:
当向age插入负数的时候,是不可以的,因为其是无符号的,是非负的,会插入失败

也不能插入的数据不在它们表示的范围中,也会失败的
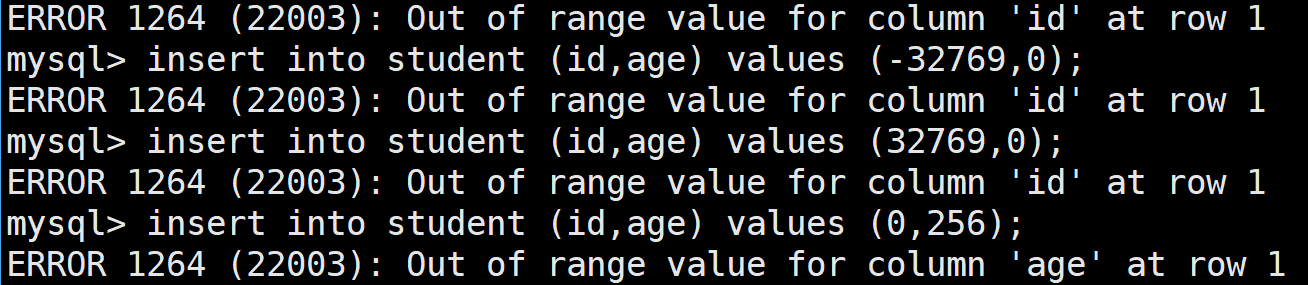
由此可见:
- MySQL对数据的检测是严格的,会直接拦截非法的数据插入
- 也就是说,只要是插入成功的数据,就一定是合法的
BIT:
基本语法:
bit[(m)]:这是位字段类型,m表示每个值的位数,范围是1~64,如果不写m,默认为1
create table t1( sex bit(1), a bit(2), aa bit(8) );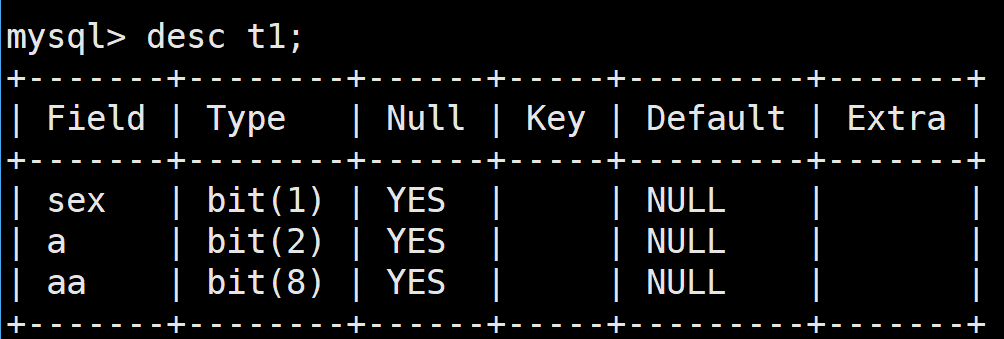
接着我们向其中插入些许数据:
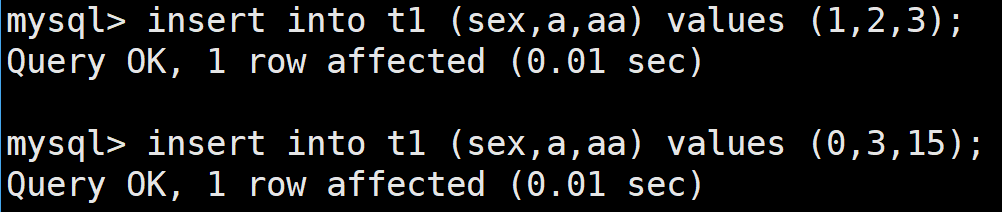
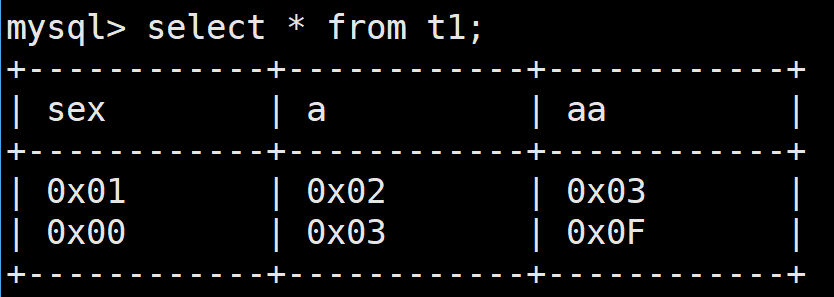
可以看到这是以十六进制进行存储的
那么我们插入其他不成功的数据看看:
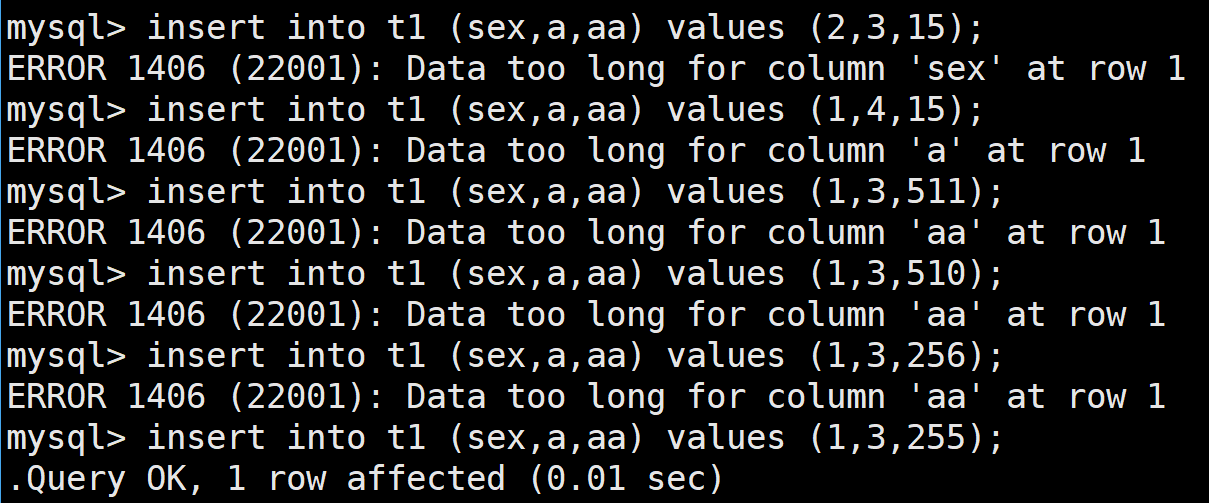
仔细观察,我们会发现其数据范围是按照位数来进行判断的:
- bit(1)代表着只有1位 所以我们只能插入1或者0
- bit(2)代表着有2位 也就是00 01 10 11代表着0,1,2,3
- bit(8)代表着有8位 所以最大是1111 1111也就是1 0000 0000 - 1的结果 也就是255
如上以此类推
三、小数类型:
float:
基本语法:
float[(m,d)] [unsigned]:其中m表示总共显示的长度,表示小数点后面的位数,其占4字节
create table t2(
浮点数 float(6,3)
);
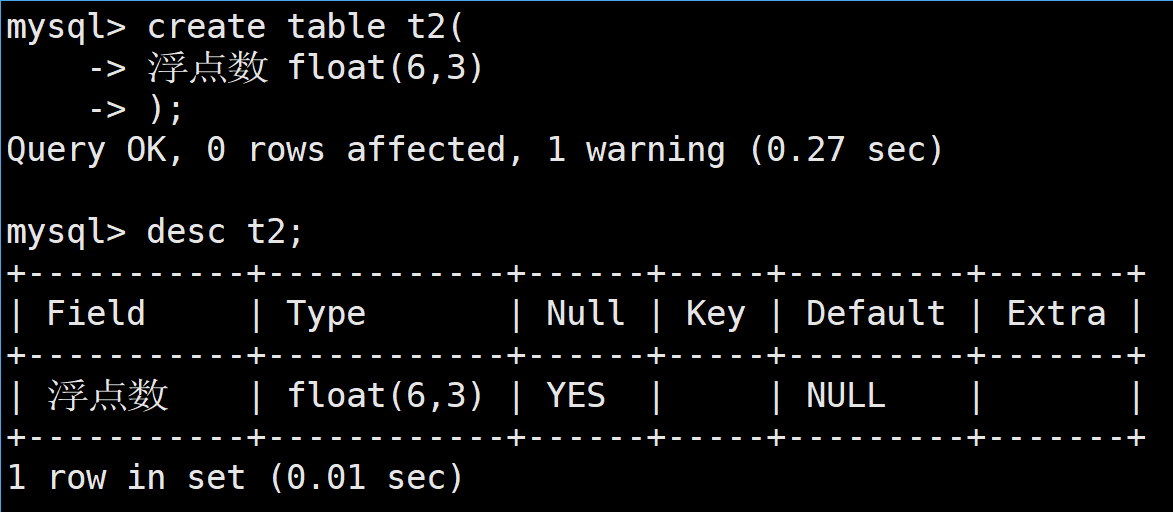
这样,其范围按照定义来说是-999.999~999.999,在该范围下的数据都能够成功插入
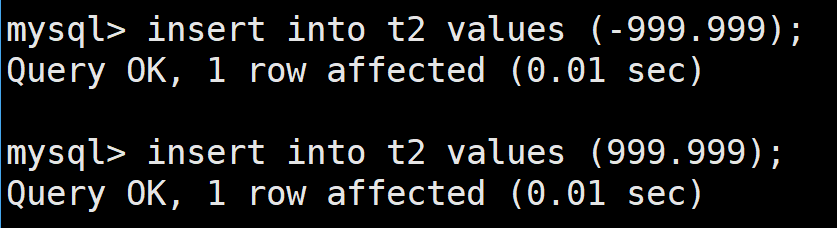


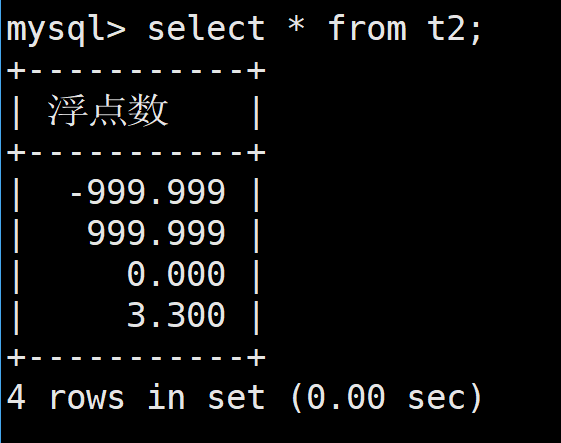
这里如果插入的时候后面比标准的小数点要少的话,会自动补齐0
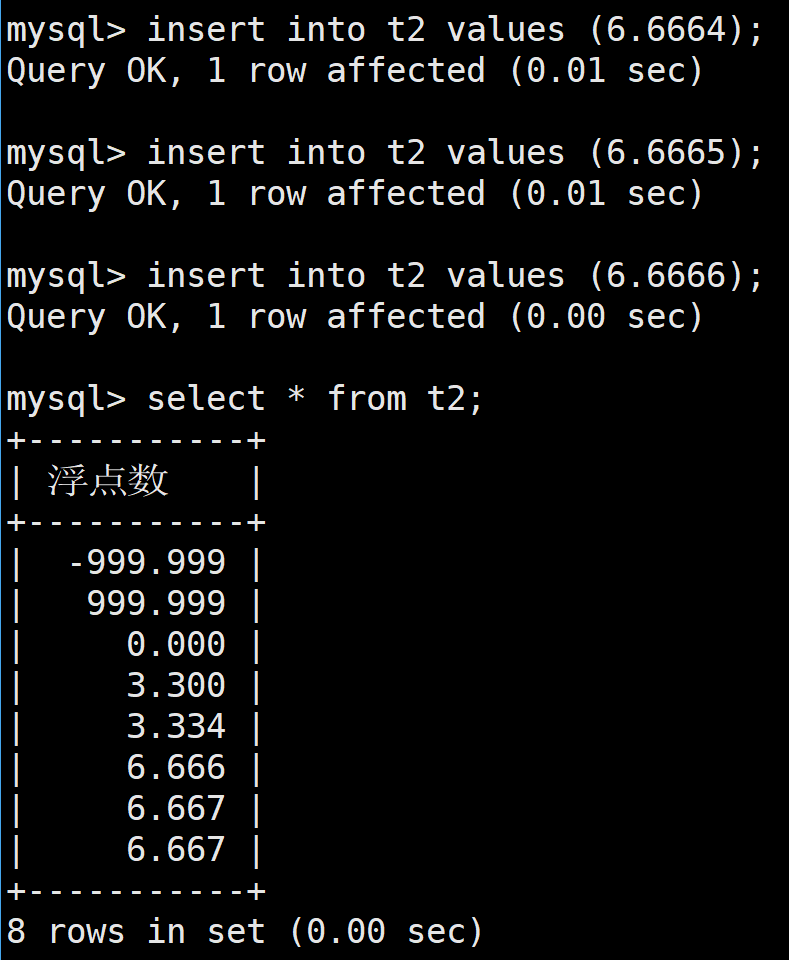
这里如果插入的时候后面比标准的小数点要多的话,会四舍五入
浮点数如果是无符号的话,比如 float(6,3) unsigned 这样的话其范围是把负数那部分直接砍掉,就是0~999.999
float存在精度损失:
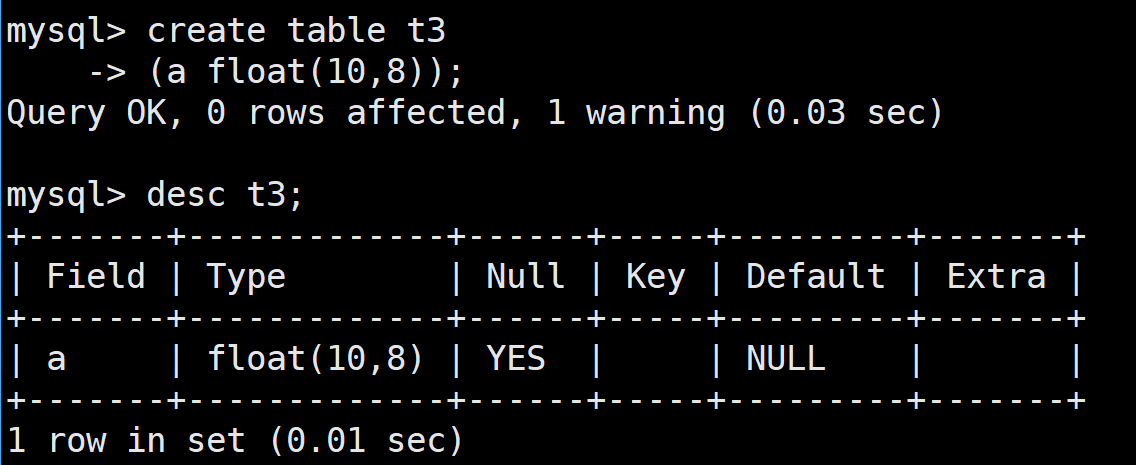
当对其进行插入操作后,然后在进行查看,发现其精度存在损失
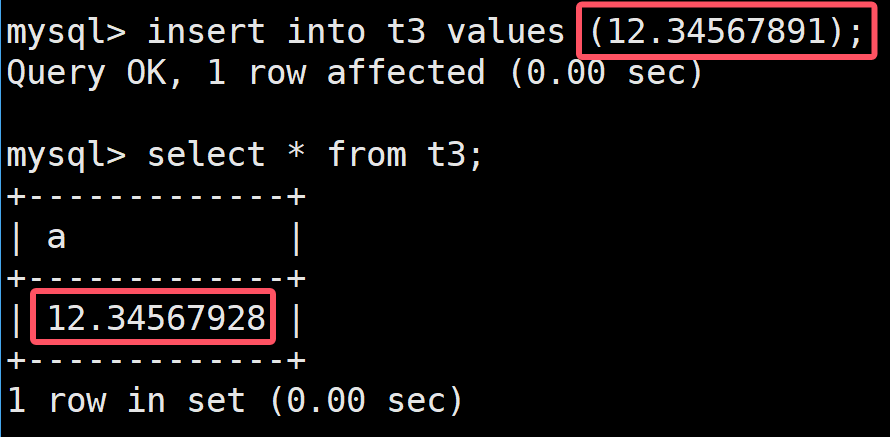
double和float的使用基本是一样的,只是存储的范围大些,要想追求高精度,就需要使用类型decimal
decimal:
decimal使用方法大致和float基本差不多,在存储浮点数时,decimal能够更好地保证小数的精度
首先创建一个表,其类型为decimal

然后向表中插入和之前float丢失的精度的数据,然后进行查看
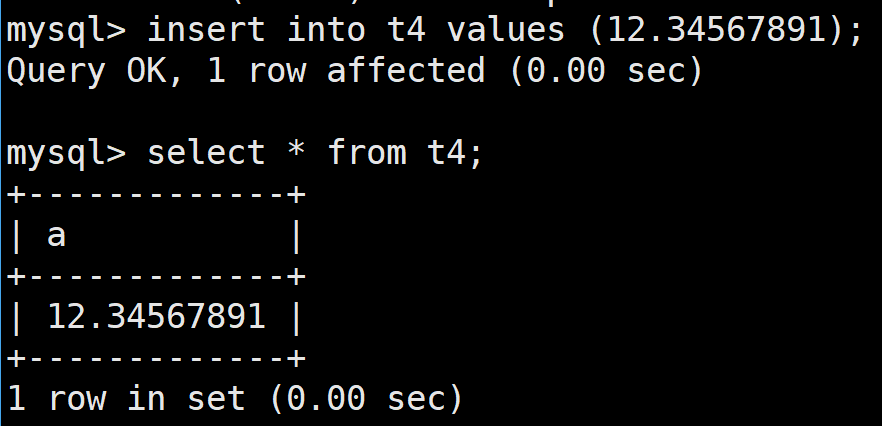
所以:
对精度的要求不是很高的,使用float或者double存储浮点数即可
对精度的要求很高的,使用decimal存储浮点数
四、字符串类型:
char:
char(L)是固定字符串,其中L是存储的长度,最大为255
首先创建一个表,里面有一个字段名称为name,类型为char(5)
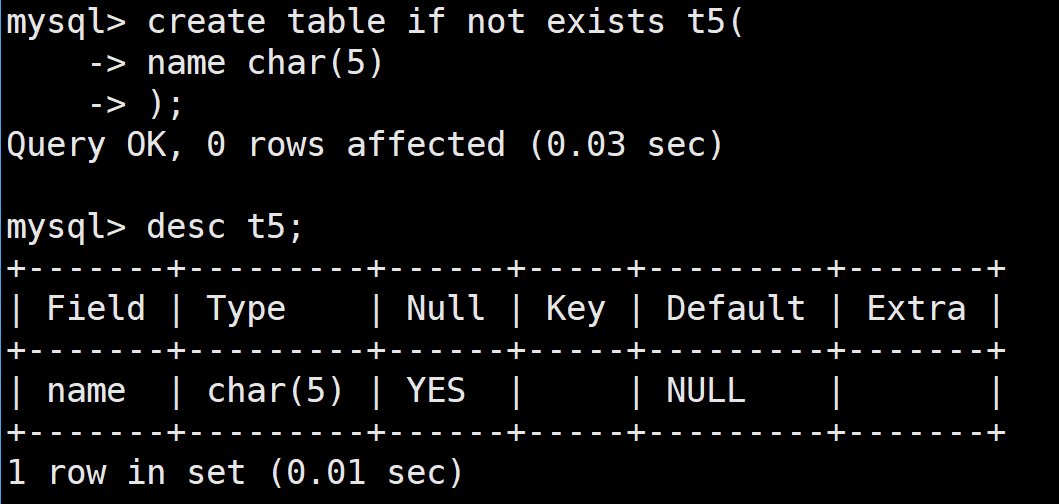
所以,我们向表中插入字符串的长度不能超过5个,这个无论是汉字还是英文字母都是这样的
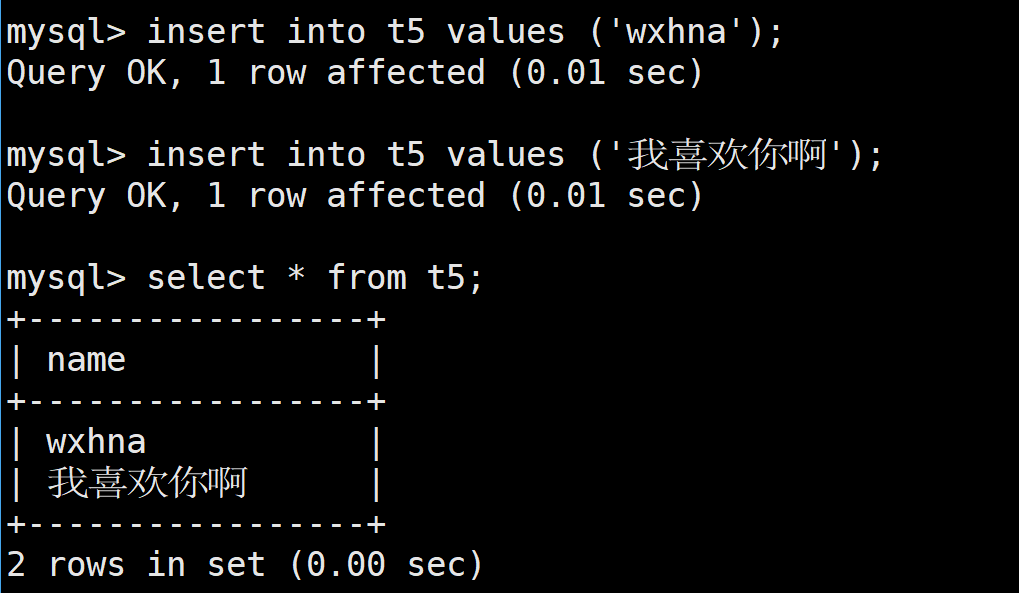

这里char不是按照字节来进行查看的,这里和C/C++是不一样的,这里是按照个数来看的,无论是英文字母还是汉字,都是满足其对应的个数即可
这样,用户在编码的时候就不必在意字节上的差异了
最后注意char类型最大长度为255

varchar:
char是固定字符串,在定义后是不能增加的,varchar是变长字符串,其最大是65535个字节的
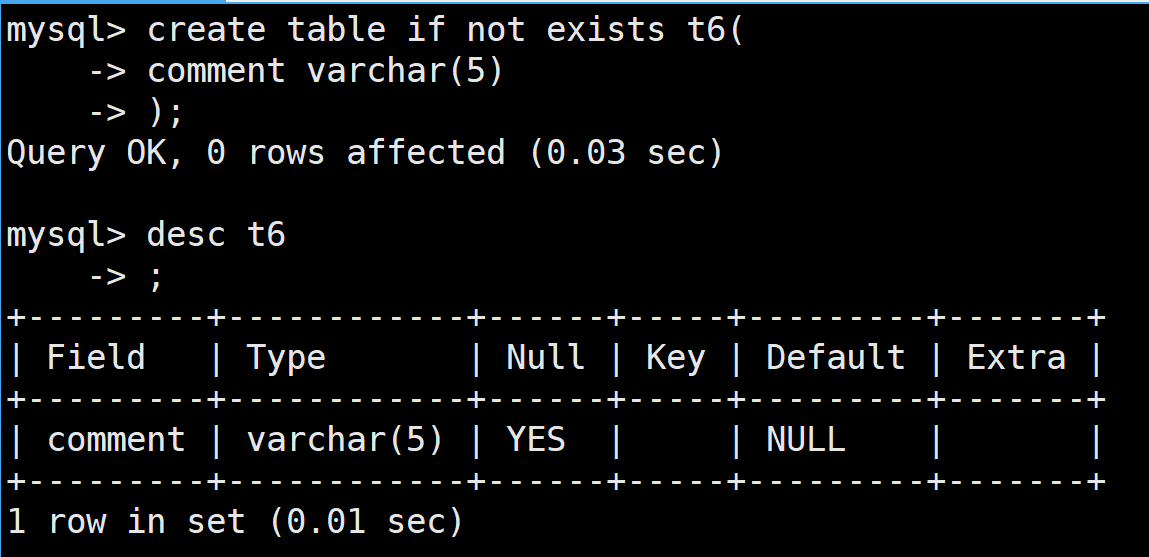
当对其进行插入的时候,发现5个字符能够插入,但是多了就不能够插入了
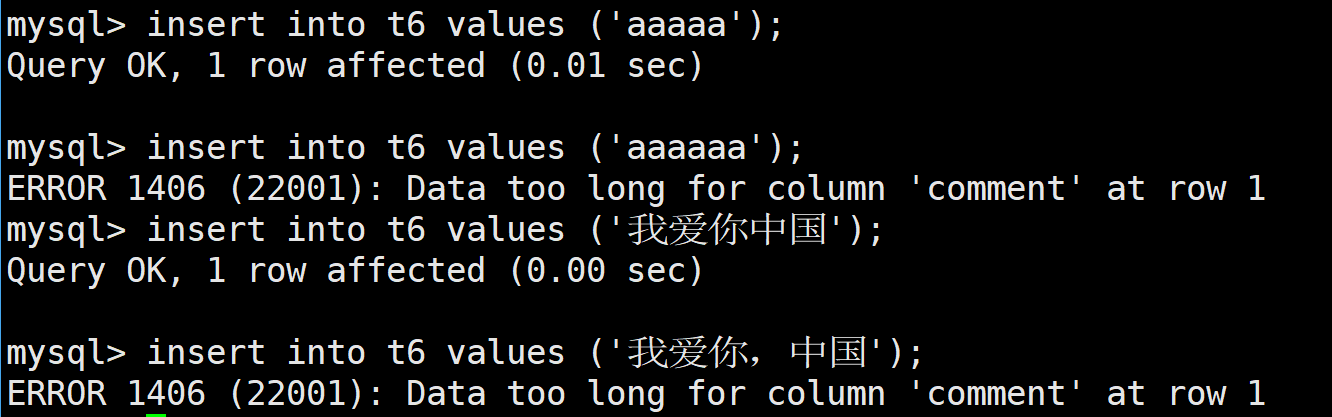
那么这个变长字符串的变长体现在哪里呢?
如上,当给varchar类型分配空间后,这里是分配了5个字符的空间,但是如果实际插入的字符串长度不足5个,比如说3个,那么就只会只使用3个字符空间,如果实际插入的字符为4个,那么就只会只使用4个字符空间,这里的变长体现在varchar类型中,会根据实际插入的字符串长度,动态分配空间,达到变长的效果
所以varchar类型是指定字符个数的上限的
上面说varchar支持的是65535个字节,那么我们设置一下看看

发现这里是不行的,会发现这里是21845,为什么呢?----- 我们知道这里是存的是中文字符,一个中文字符在utf8编码中占3个字节,那么65535 / 3 = 21845,这就是varchar支持的最大字符串长度
那么我们修改为21845

发现居然又错了,上述报错翻译过来就是:
行大小太大。使用的表类型(不计算 BLOB)的最大行大小为 65535。这包括存储开销,请查看手册。您必须将某些列更改为 TEXT 或 BLOB
实际上,对于中文字符串来说,其空间不仅仅只是记录数据的,还需要1~2个长度标识字节,还有1字节来存储其他控制信息
所以实际上,最长字符串长度为(65535-3)/3=21844

char和varchar区别:
| 对比维度 | CHAR | VARCHAR |
|---|---|---|
| 存储方式 | 固定长度,填充空格至定义长度 | 可变长度,存储实际数据+长度标识(1-2字节) |
| 空间占用 | 固定(定义长度) | 动态(实际长度+长度标识) |
| 存取性能 | 更快(直接定位固定长度) | 略慢(需解析长度标识) |
| 最大字符数 | 255(与字符集无关) | 受字符集影响(如utf8:约21844字符) |
| 尾部空格处理 | 存入时自动补空格,检索时自动去除 | 保留存入时的尾部空格 |
| 适用场景 | 短且定长的数据(如性别代码、MD5哈希) | 长度不定的数据(如用户名、地址) |
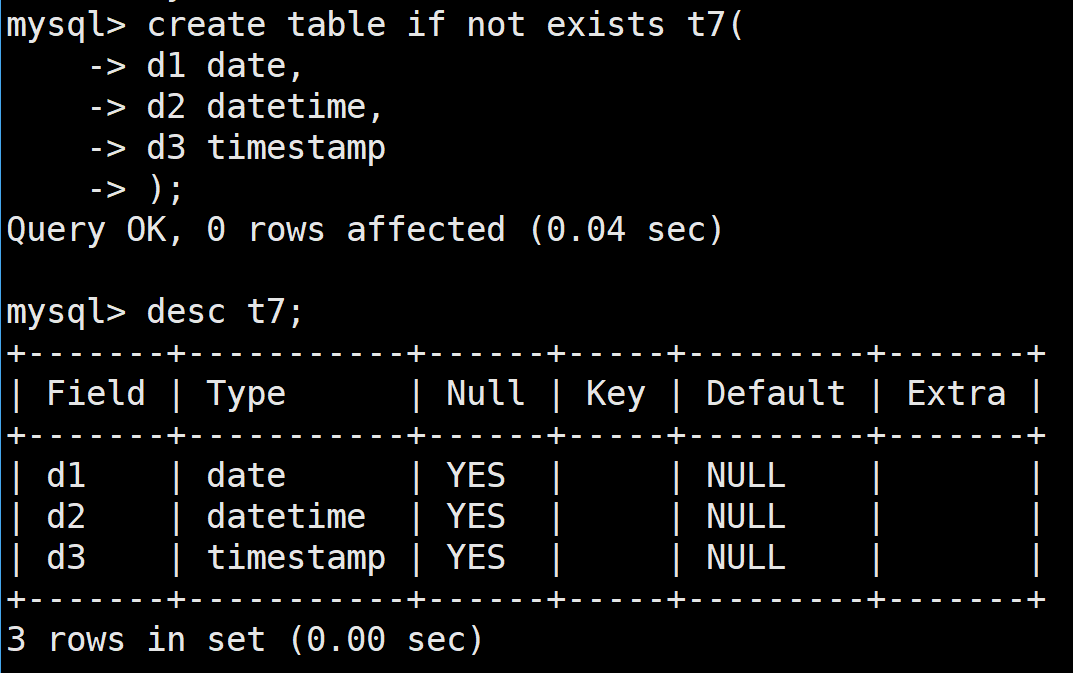
五、时间日期类型:
常用的时间类型有三种,分别是:
- date:其格式为YYYY-MM-DD,占用3字节
- datetime:其格式为YYYY-MM-DD HH:MM:SS,占用8字节
- timestamp:这是时间戳,其格式为YYYY-MM-DD HH:MM:SS,占用4字节
接着向前两个插入数据:这是比较简单的
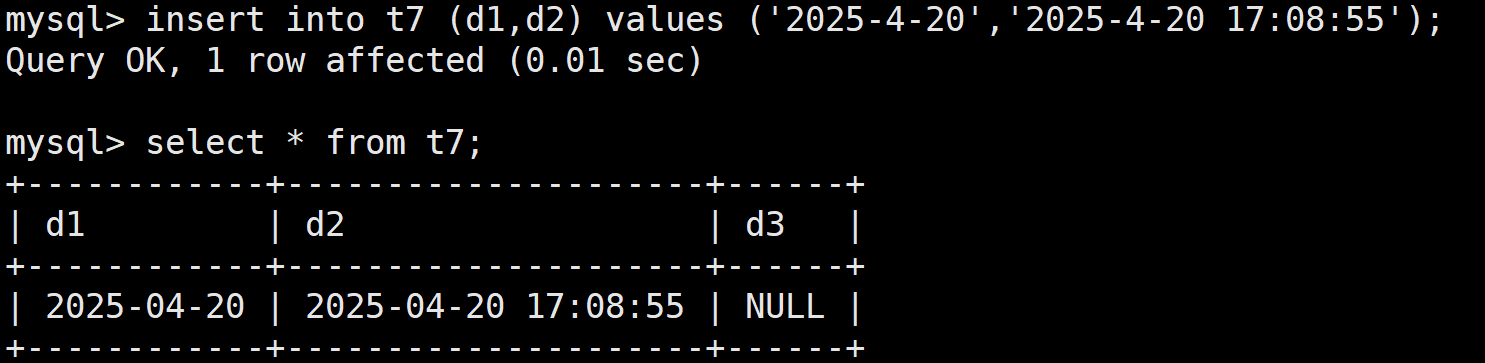
但是关于d3,也就是时间戳
从 MySQL 5.6.6 起,
TIMESTAMP列如果没有显式指定DEFAULT值
就不会在自动默认给CURRENT_TIMESTAMP
除非用户明确加上DEFAULT CURRENT_TIMESTAMP 或 ON UPDATE CURRENT_TIMESTAMP
否则该字段就是普通的NULLABLE列
如果已经创建了,可以用语句:ALTER TABLE t7
MODIFY COLUMN d3 TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP;来给t7表的d3列加上缺省
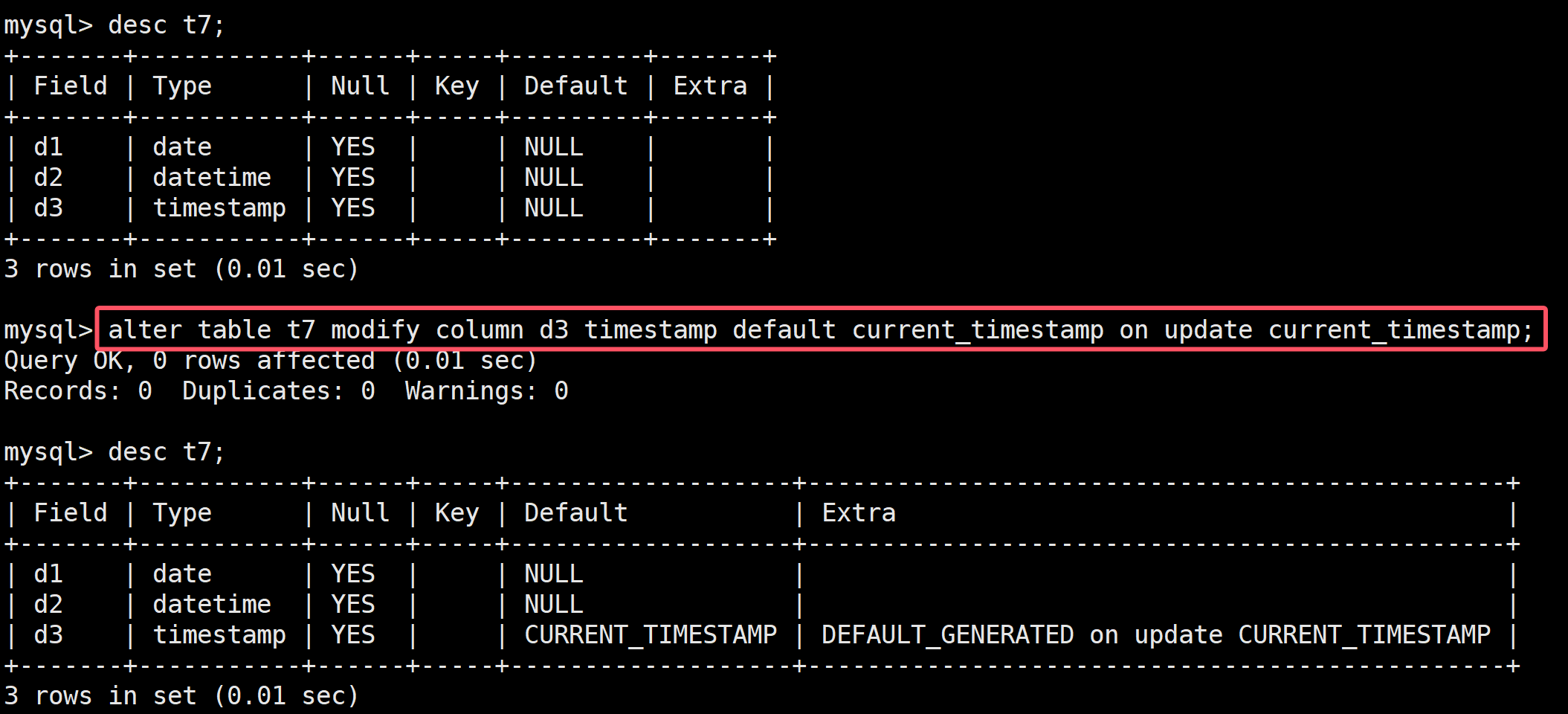
这样如果是缺省的TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE就能够当时间戳在更新时就会自动刷新,如update修改数据的时候,但是这里修改表中的列如id,或者这个列的类型是不会刷新时间戳的
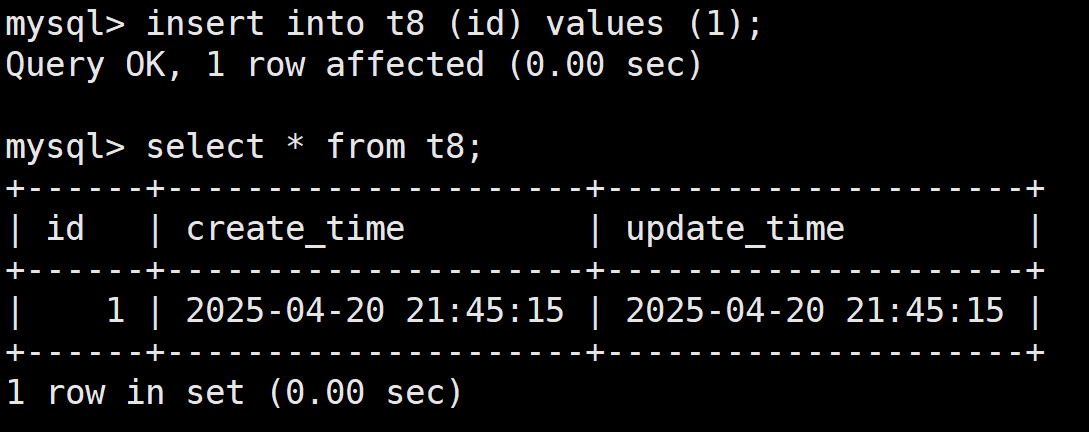
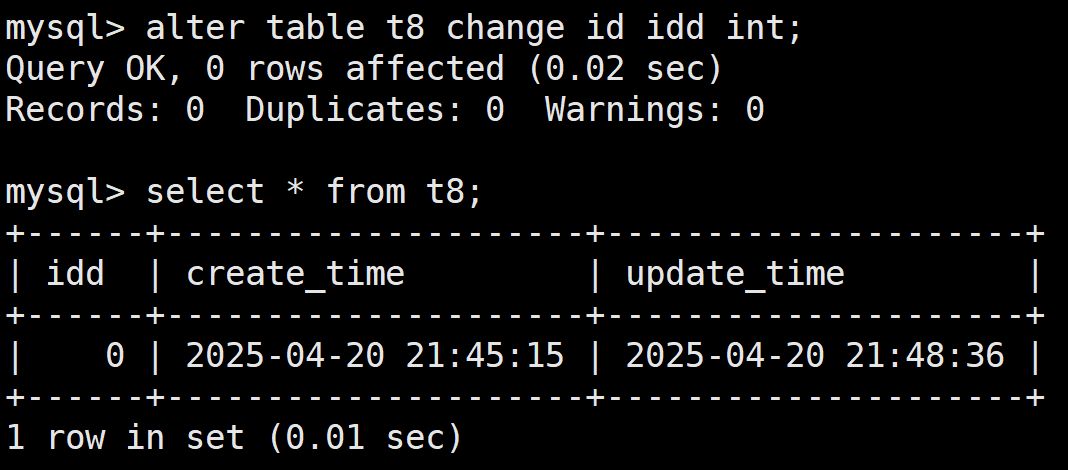
如下,t8表

向t8表中插入数据id = 1,这个时候不用管时间戳,他会自动填入的
当对表中的数据进行修改,比如将id的值从1修改为0
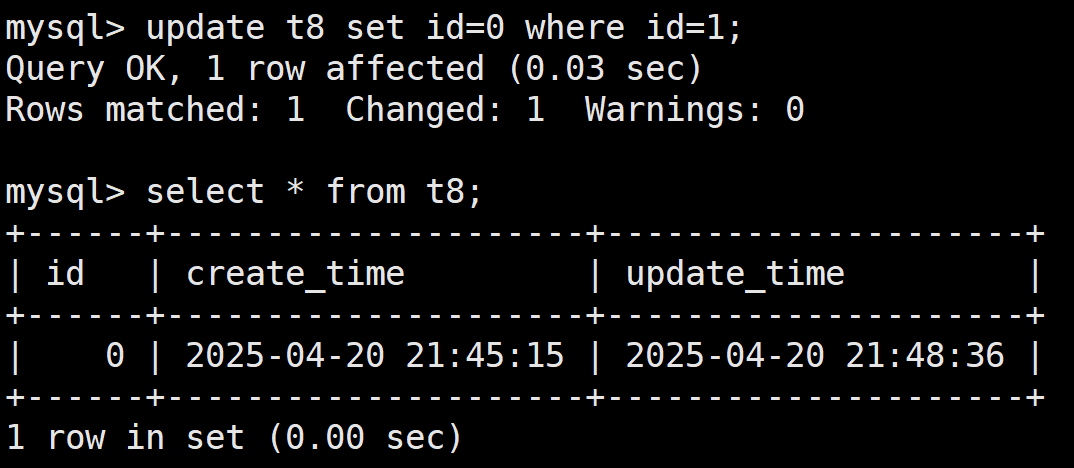
这样的话TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE修饰的时间戳就会自动更新,TIMESTAMP DEFAULT CURRENT_TIMESTAMP修饰的时间戳不会自动更新
这里是修改数据才会使其更新,如果修改表中的字段是不会引发更新的,比如将id修改为idd是不会引发更新的
六、enum与set类型:
enum:
enum被称为枚举类型,他是用于提供一批元素,然后只能选择其中的一个
我们创建一个表,其中用枚举表示男或者女
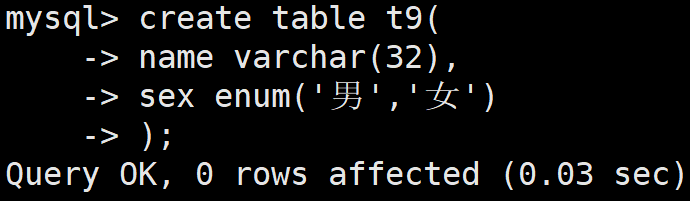
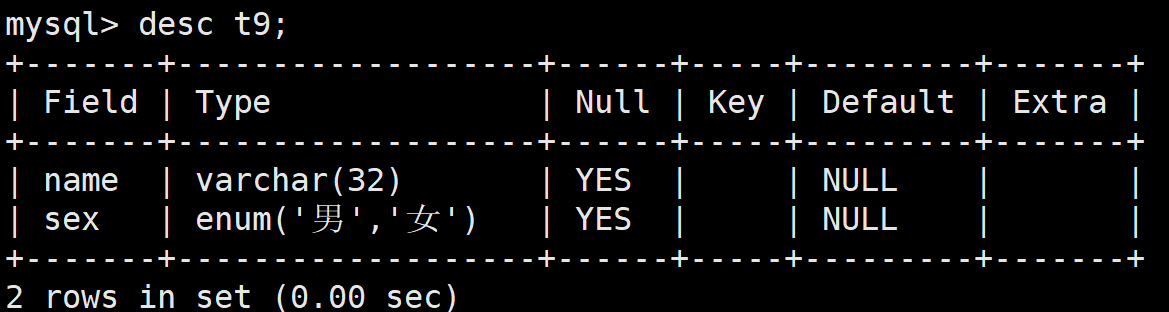
这样,在其中查看
当向其中进行插入的时候,对sex进行插入的时候,只能从其列表中进行选择一个元素进行插入
insert into t9 values ('张三','男');
insert into t9 values ('李四','女');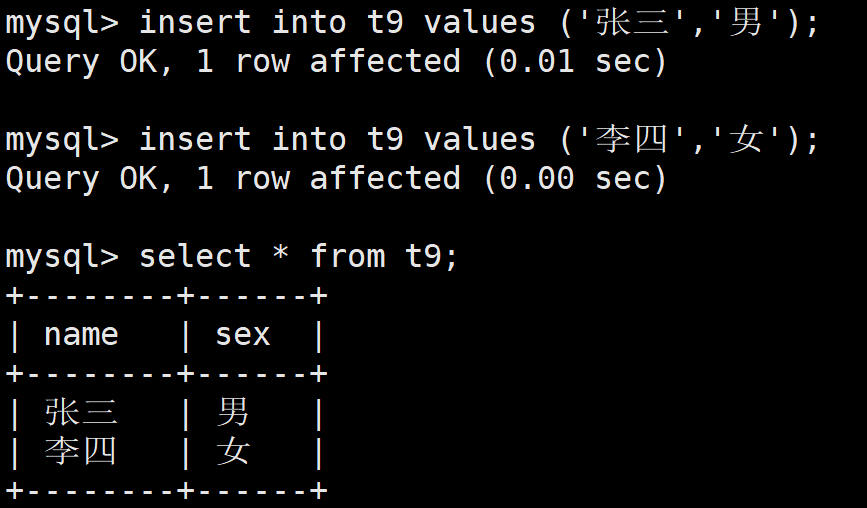
如果是列表中不存在的,或者是插入多个,都是不可以的
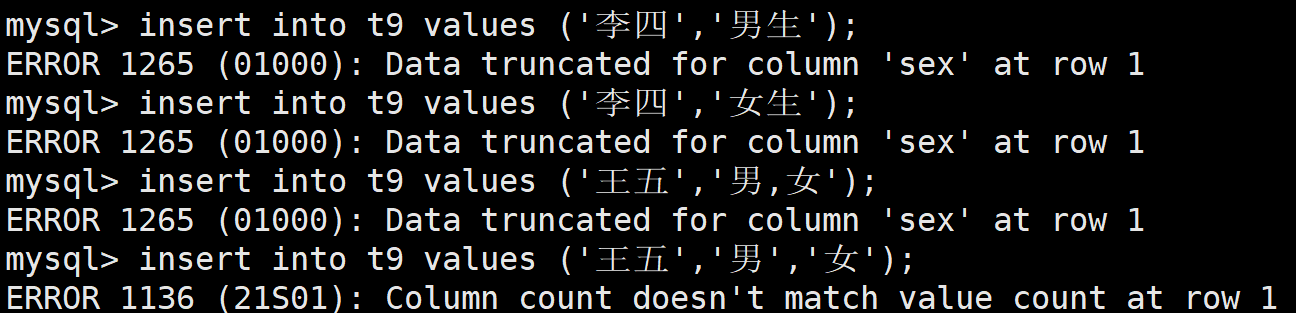
如果列表中的元素字符特别长,不想打字,那么也可以使用数字插入,从1开始对应着列表中的第一个,往后依次++,在上述案例中,男就是对应的1,女就是对应的2
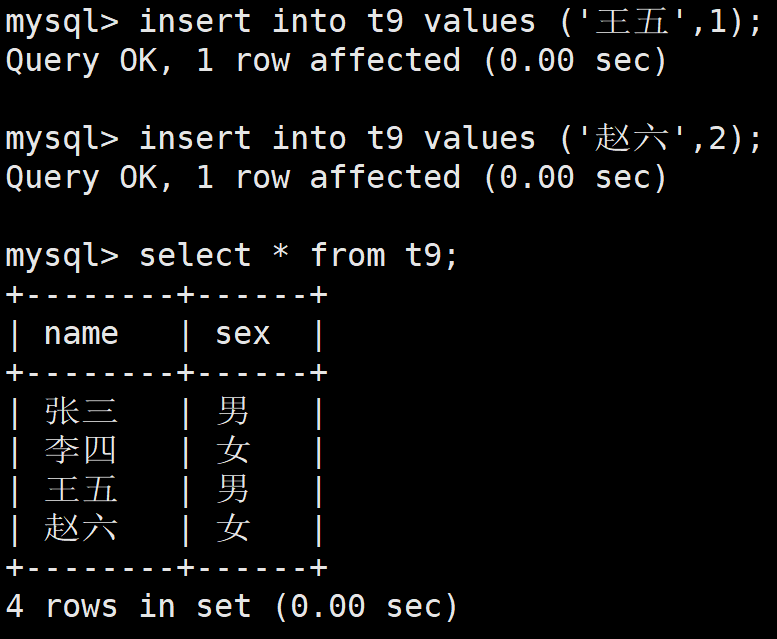
当然,插入没有对应的数字也是不行的

set:
这个被称为集合类型,是支持多选的,用法和enum差不多
我们可以在创建表的时候进行set类型的创建,也可以对已经创建好的表进行增加
alter table t9 add (drink set('可乐','雪碧','茶π','红牛','阿萨姆'));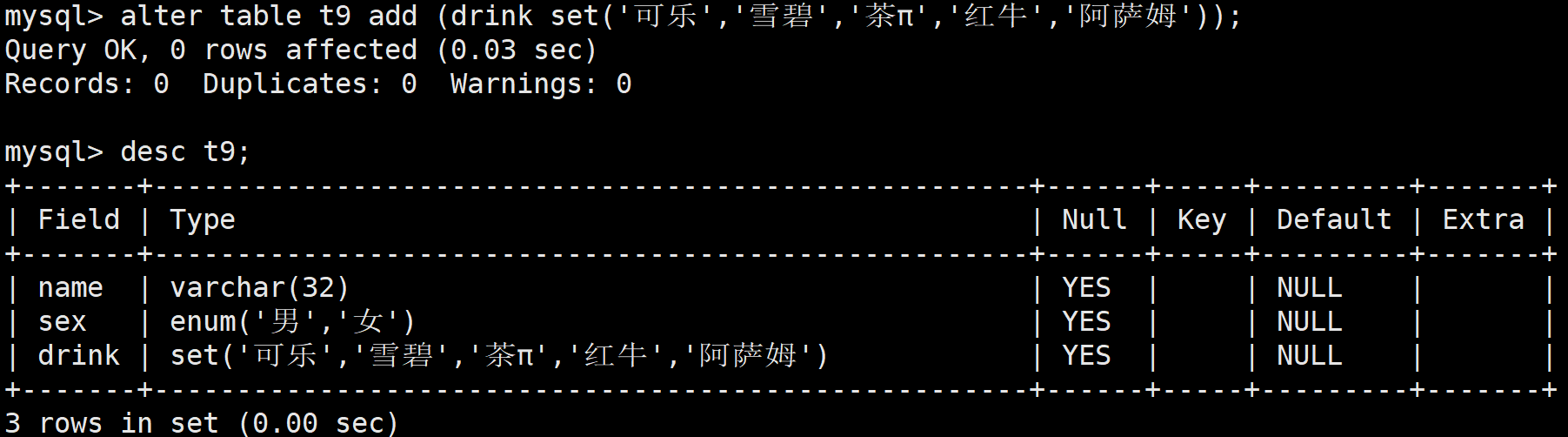
当向其中进行插入的时候,对drink进行插入的时候,只能从其列表中可以选择多个元素进行插入
insert into t9 values ('张三','男','可乐,雪碧,红牛');
insert into t9 values ('李四','女','茶π,阿萨姆');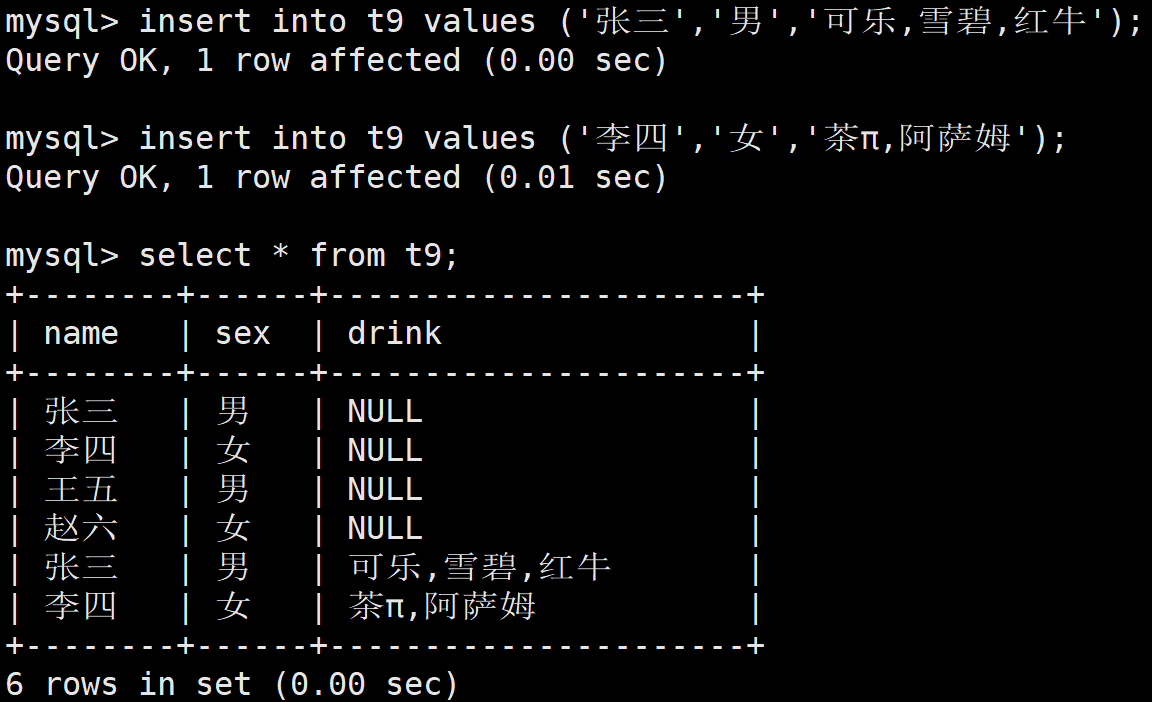
同样,也可以使用数字进行插入
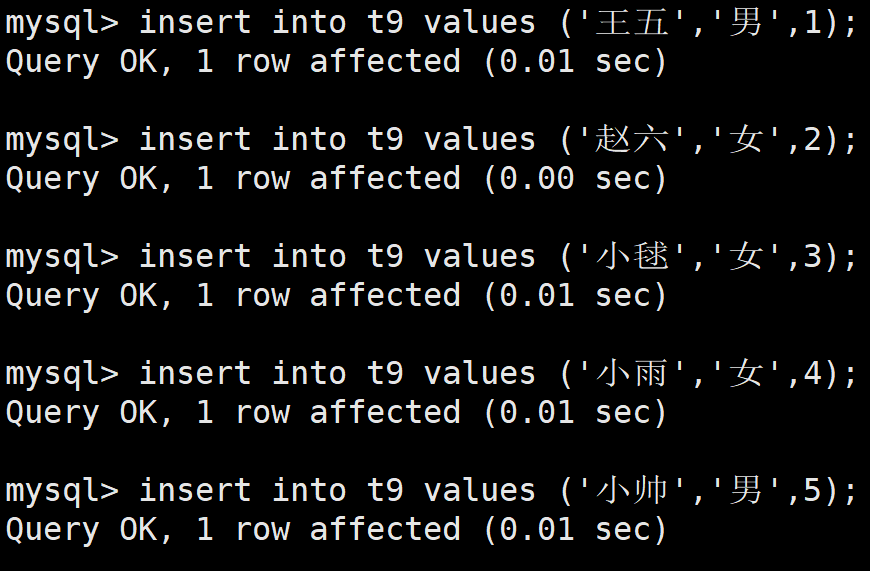
上述插入了12345,感觉像是对应着上述的5中品牌
但是查看的时候:
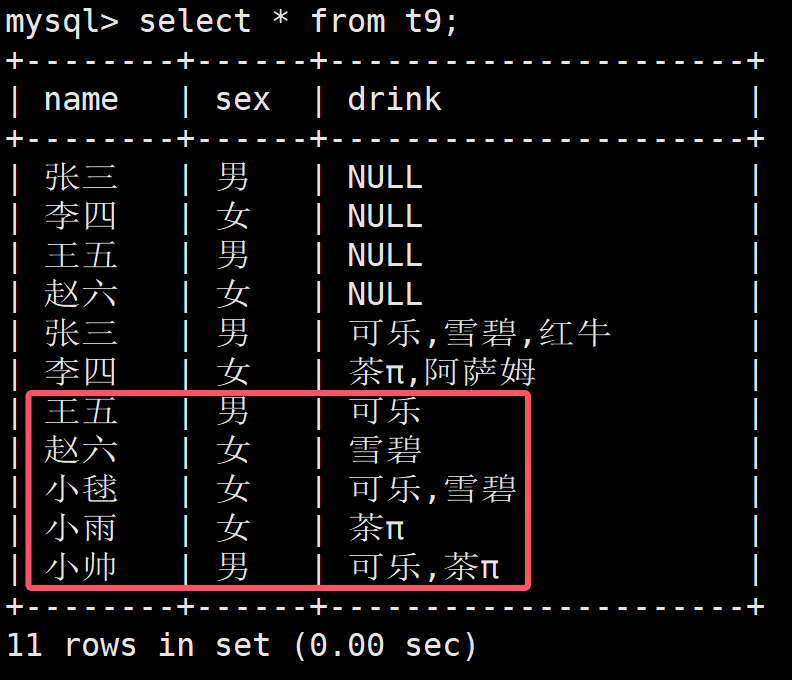
如上,红框框中是对应着上述的五条语句的,但是发现结果不是预期
这是为什么呢?
实际上,这是类似于二进制的存储方式的
当为1的时候,也就是从小到大加一,然后在倒过来看

当为2的时候,进行+1,然后就是雪碧为1,当倒过来看也就是2

当为3的时候,在进行加1,此时就是11000,倒过来就是00011就是3... 往后以此类推
所以根据上述规律,如果全部都喜欢的话,就是 11111 也就是1 00000 也就是2^5-1也就是31
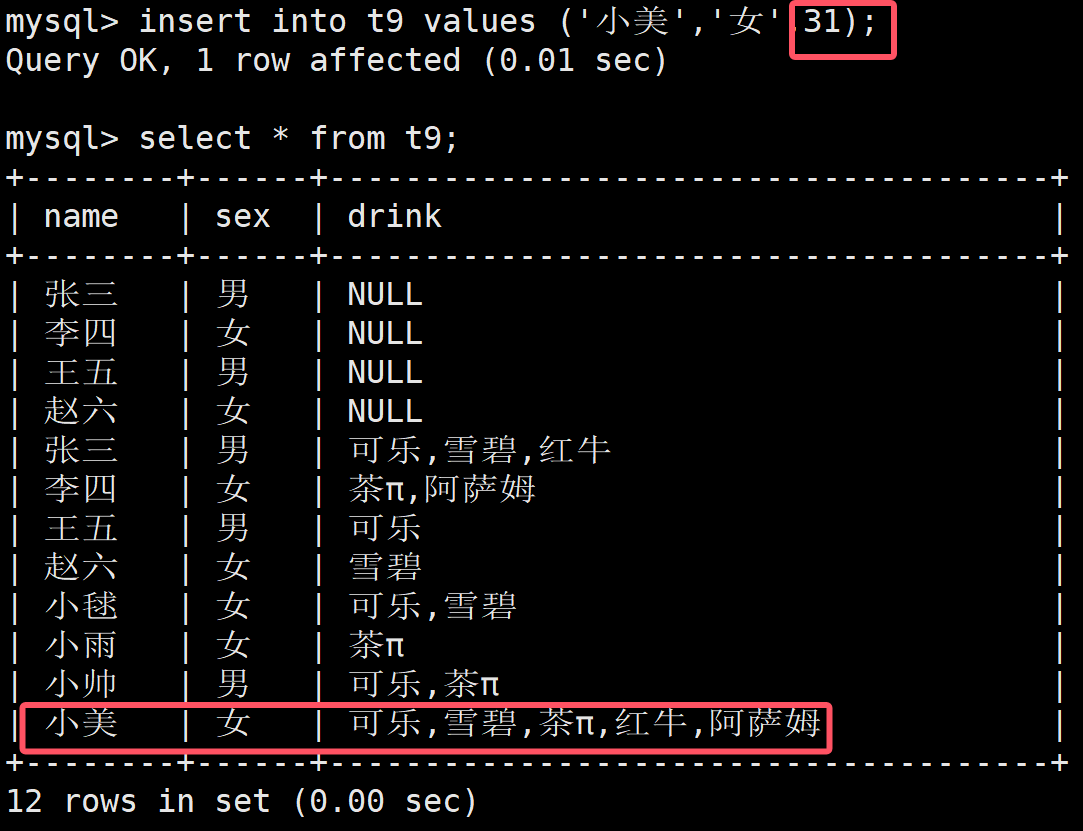
发现正如我们所料
这里有一个奇怪的,如果我们插入0,那么会发现其对应的不是NULL,而是空,这里NULL和空是不等价的,NULL表示什么都插入,空表示插入了这个类型,他是存在的,但是此时为空
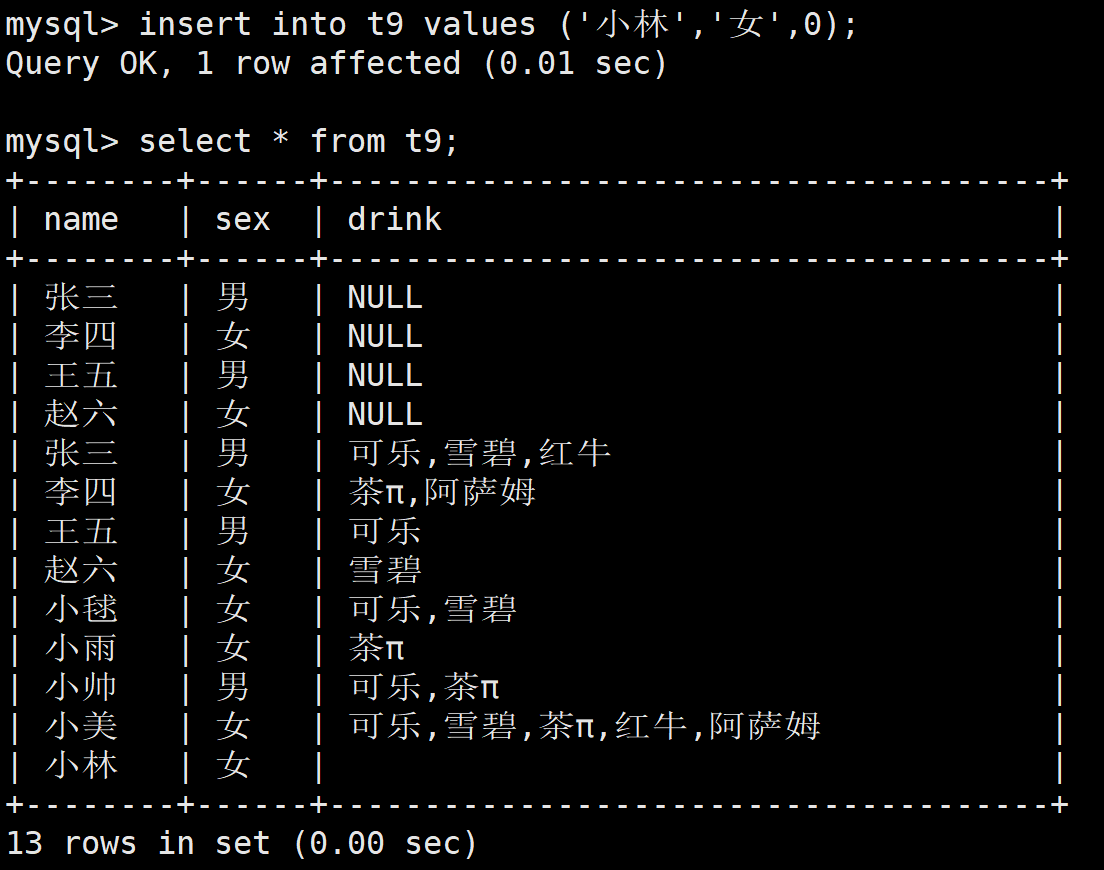
集合中的查询:
查询enum
这个比较简单,因为其是唯一的
在查询的时候直接加上 where sex='女'即可
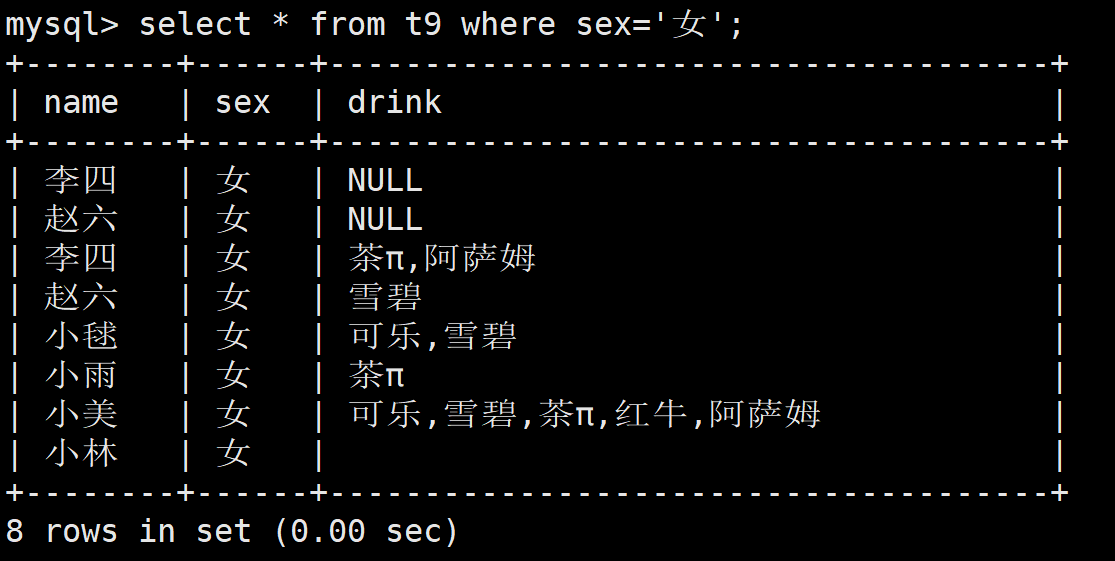
查询set
如果像查询enum一样,那么查询出来的仅仅是只有一个的
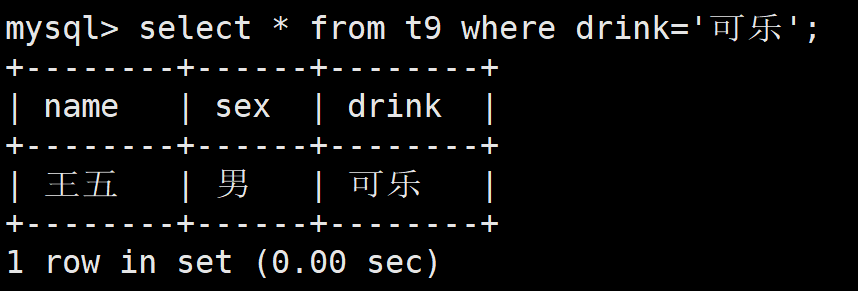
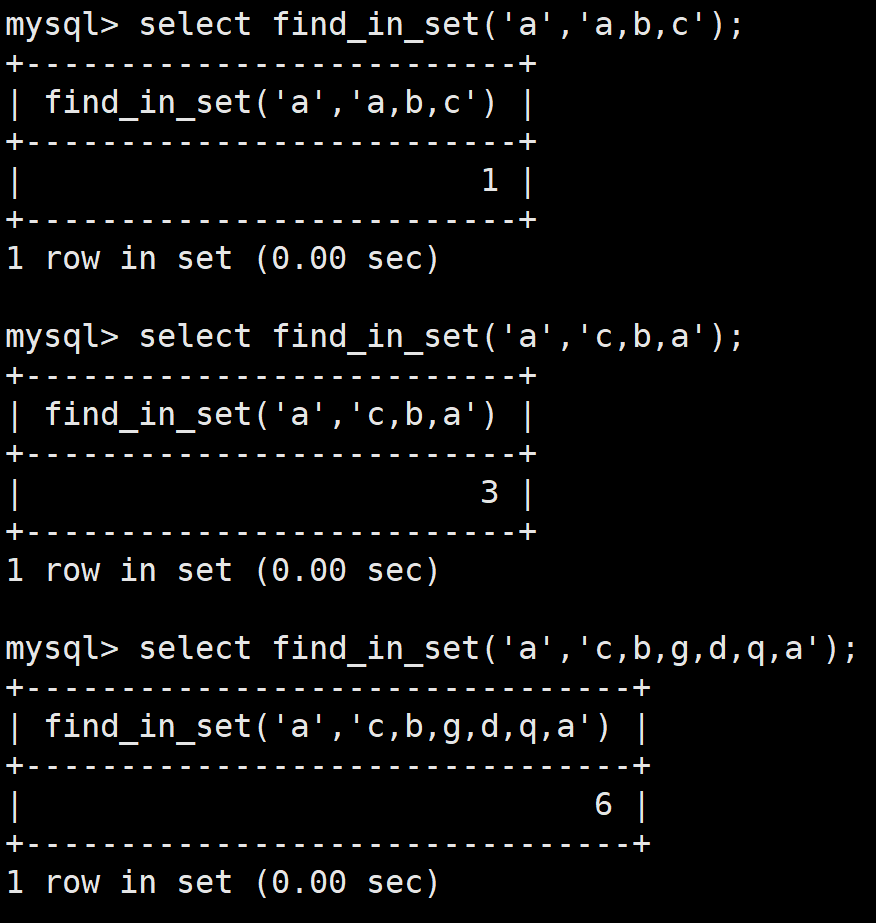
如果我们想查询包含可乐的,就需要借助函数find_in_set(str, strlist)
其作用是查询strlist中是否存在str,如果查询到了,就返回对应位置的下标(注意是从1开始的),如果没查到就返回0
select * from t9 where find_in_set('可乐',drink);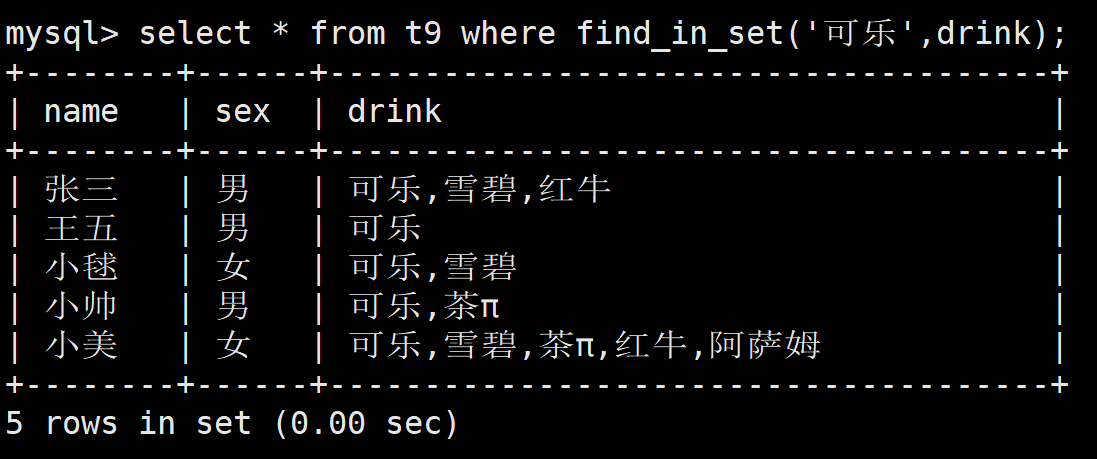
这样就能够查看所有包含可乐的了
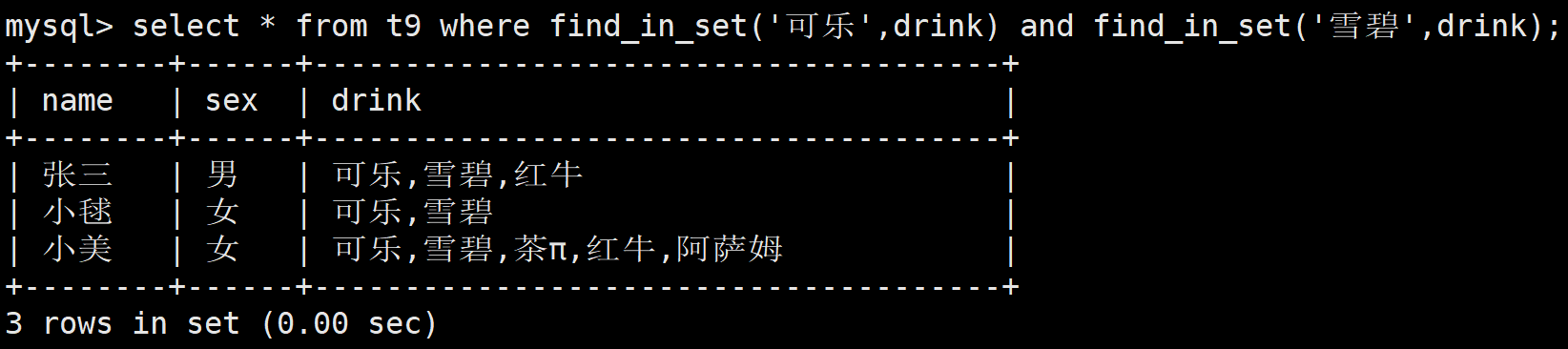
如果想查询喜欢可乐和雪碧的,就需要用and连接
select * from t9 where find_in_set('可乐',drink) and find_in_set('雪碧',drink);