刚好看到这篇文献有github代码,而且也比较新,感觉可以当作自己论文中的对比方法。
https://www.sciencedirect.com/science/article/pii/S0888327024006484 (论文地址)

(看到4090,有点想劝退自己......)
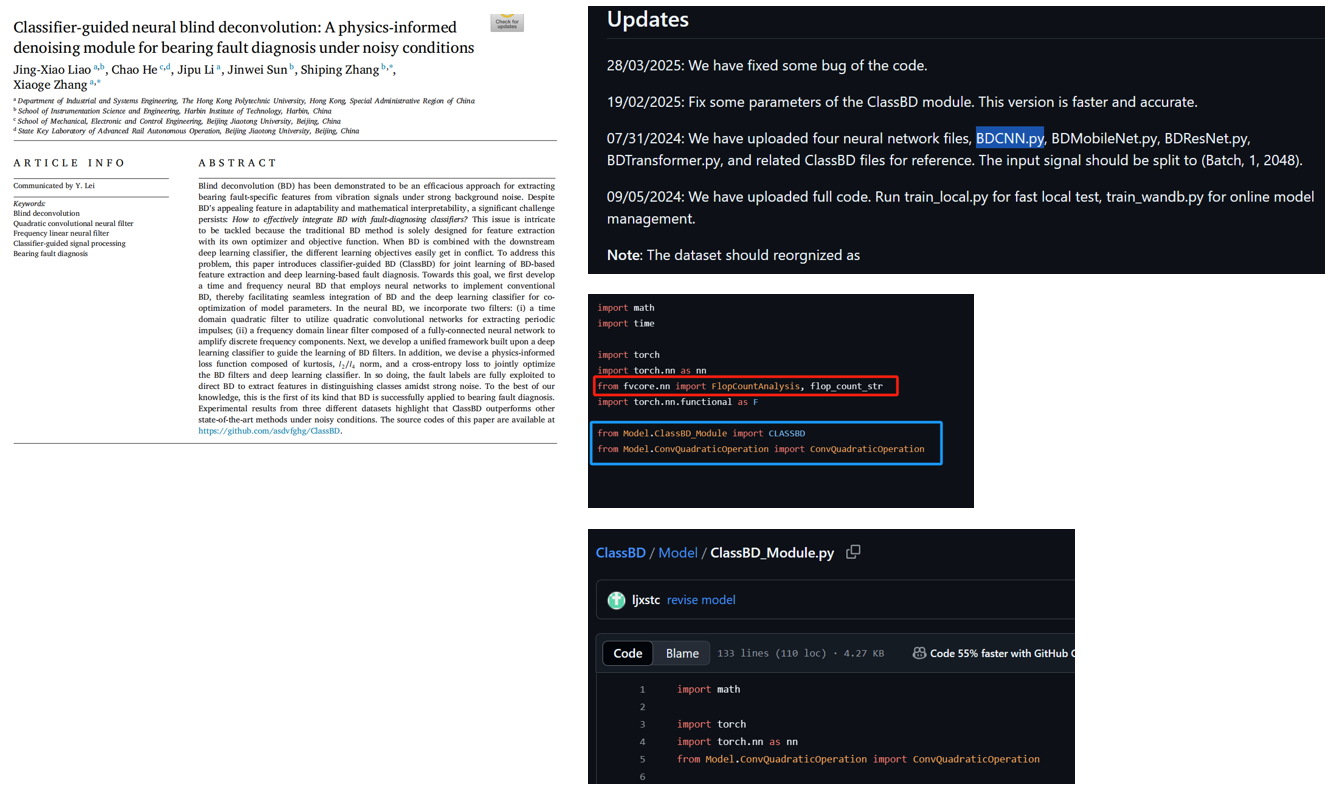
算了,来都来了,试试吧。https://github.com/asdvfghg/ClassBD
[还好没劝退,其实在4060上也能用]
一. 准备工作
这篇文献是在python 3.8和pytorch 2.1中运行。
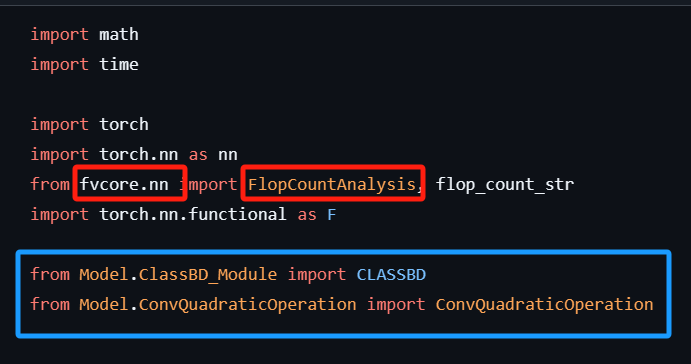
然后观察我想运行的BDCNN的代码,除了torch外,还得看我有没有下载fvcore。
蓝色的框是Github代码包里就自带的。
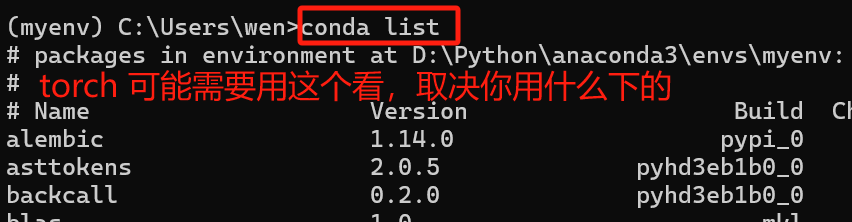
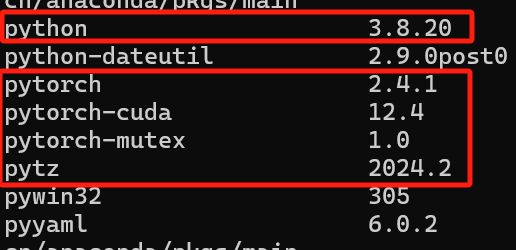 (注:建立环境按照论文写的来,python3.8)
(注:建立环境按照论文写的来,python3.8)
{不会建立环境和下pytorch的小伙伴看这里:计算生物学习——Code_PyTorch(06.15-06.19)_libcupti.so.11.8-CSDN博客}
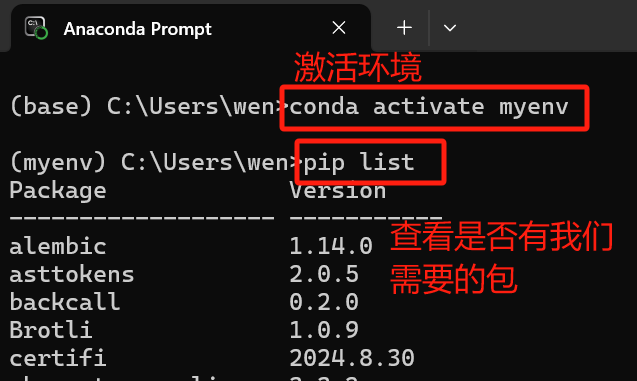
没有fvcore,下一个。官网:GitCode - 全球开发者的开源社区,开源代码托管平台
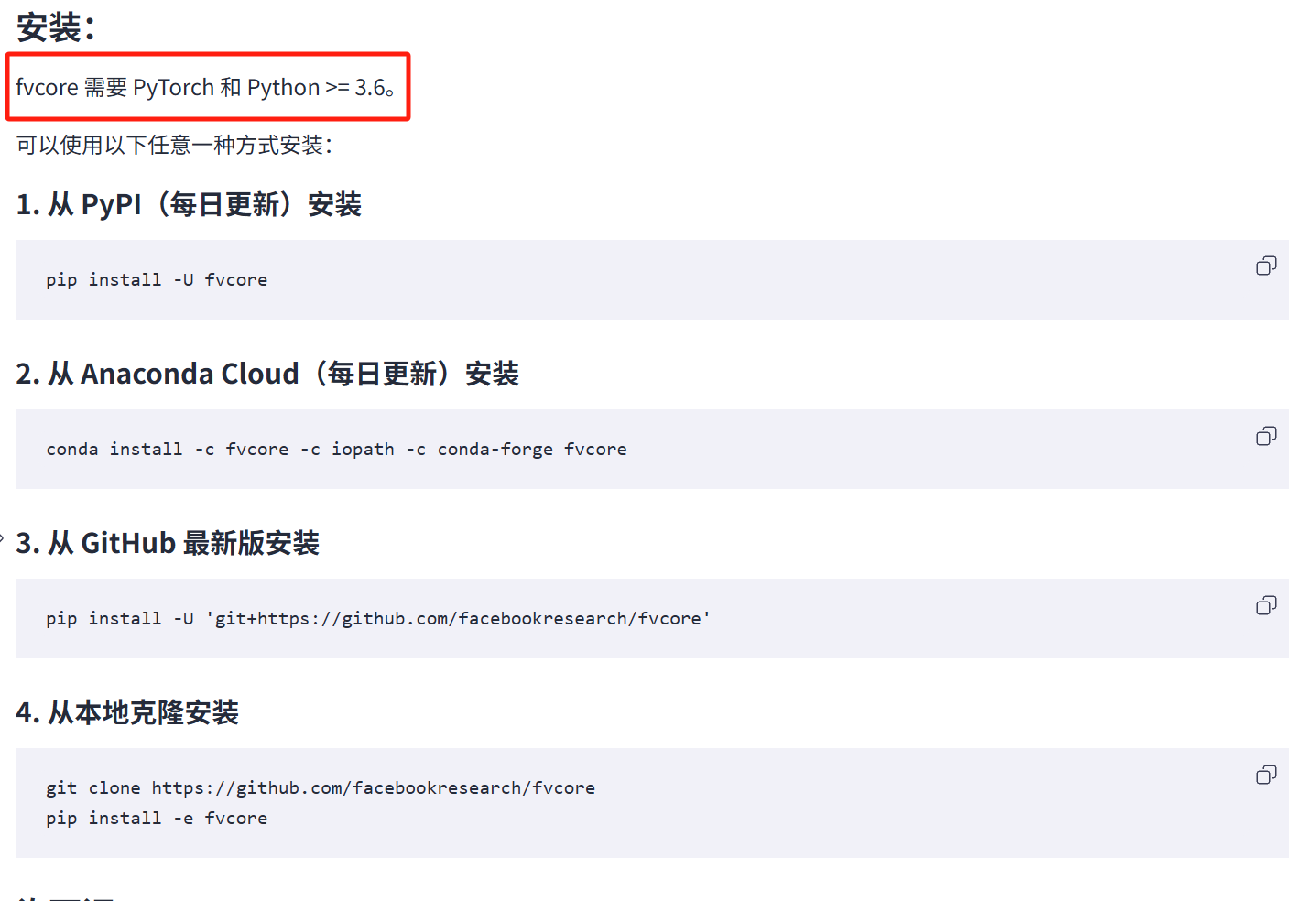
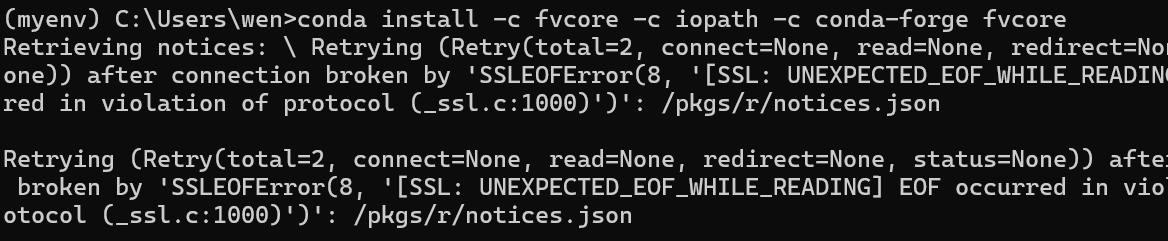
可能因为当时正在用梯子,没下成功。
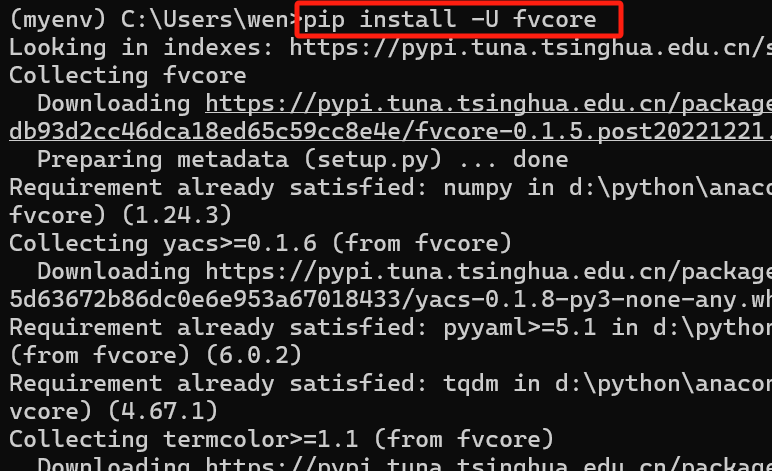
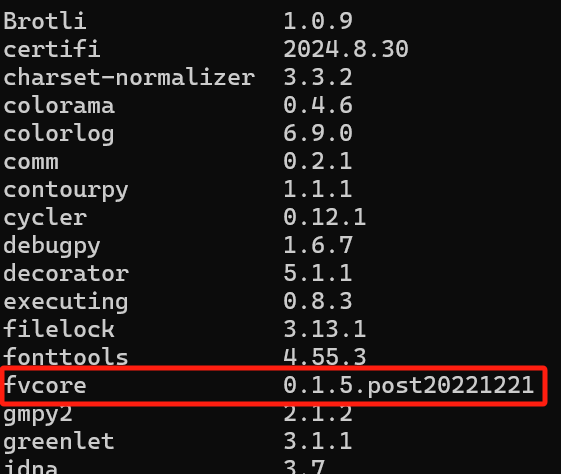
关了梯子,用代码:pip install -U fvcore,就可以成功啦~~~(再用pip list确认一下,fvcore下好了)
二. 调用 BDWDCNN
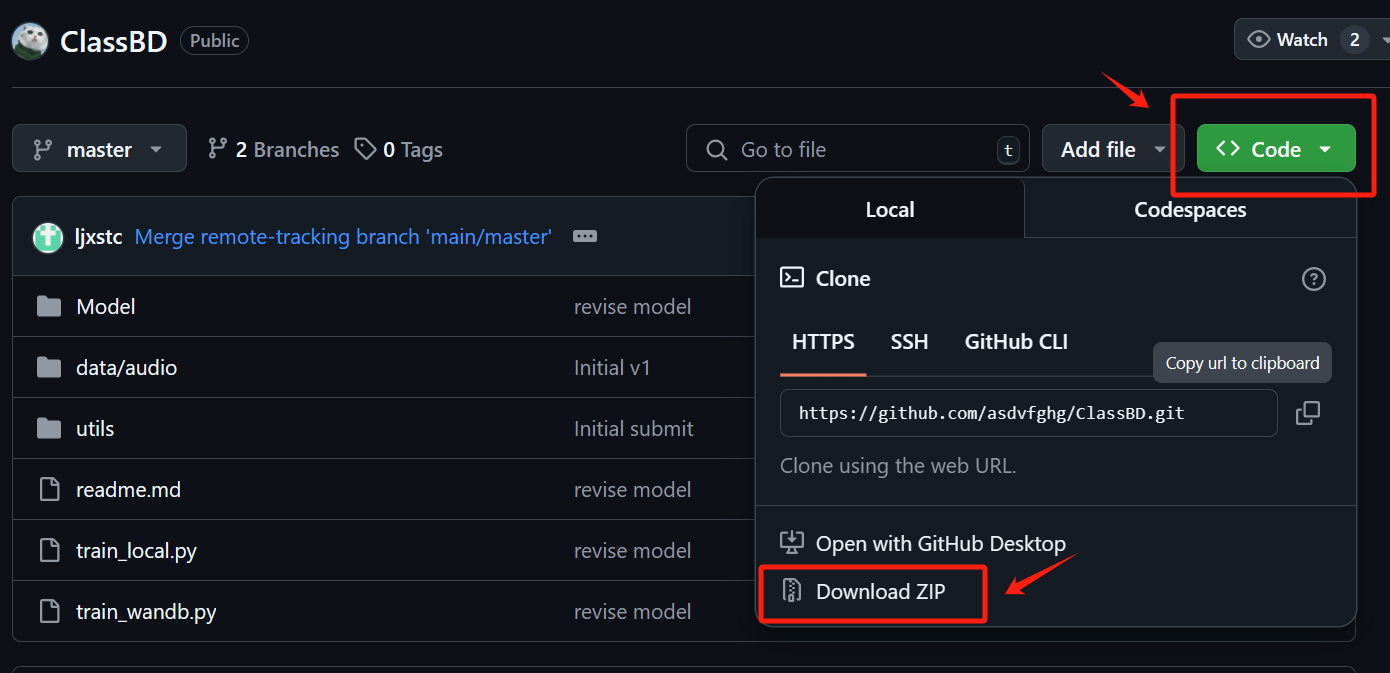
① 下载的压缩包,解压打开,创建一个新的文件。(确保的代码运行目录在这个包里)
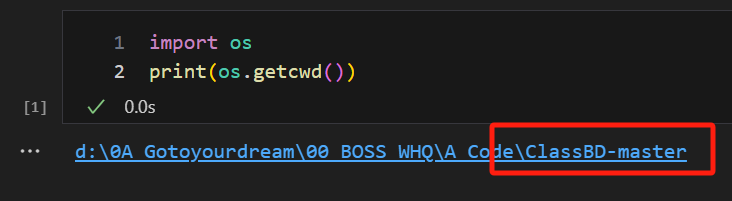
② 尝试调用包
三. 模型应用
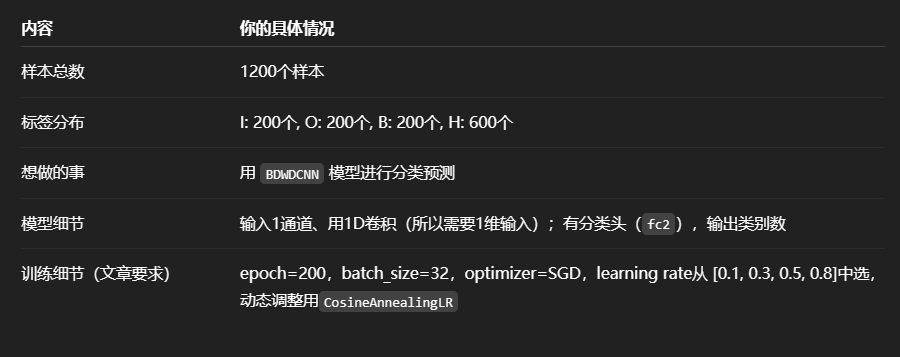
1.准备数据
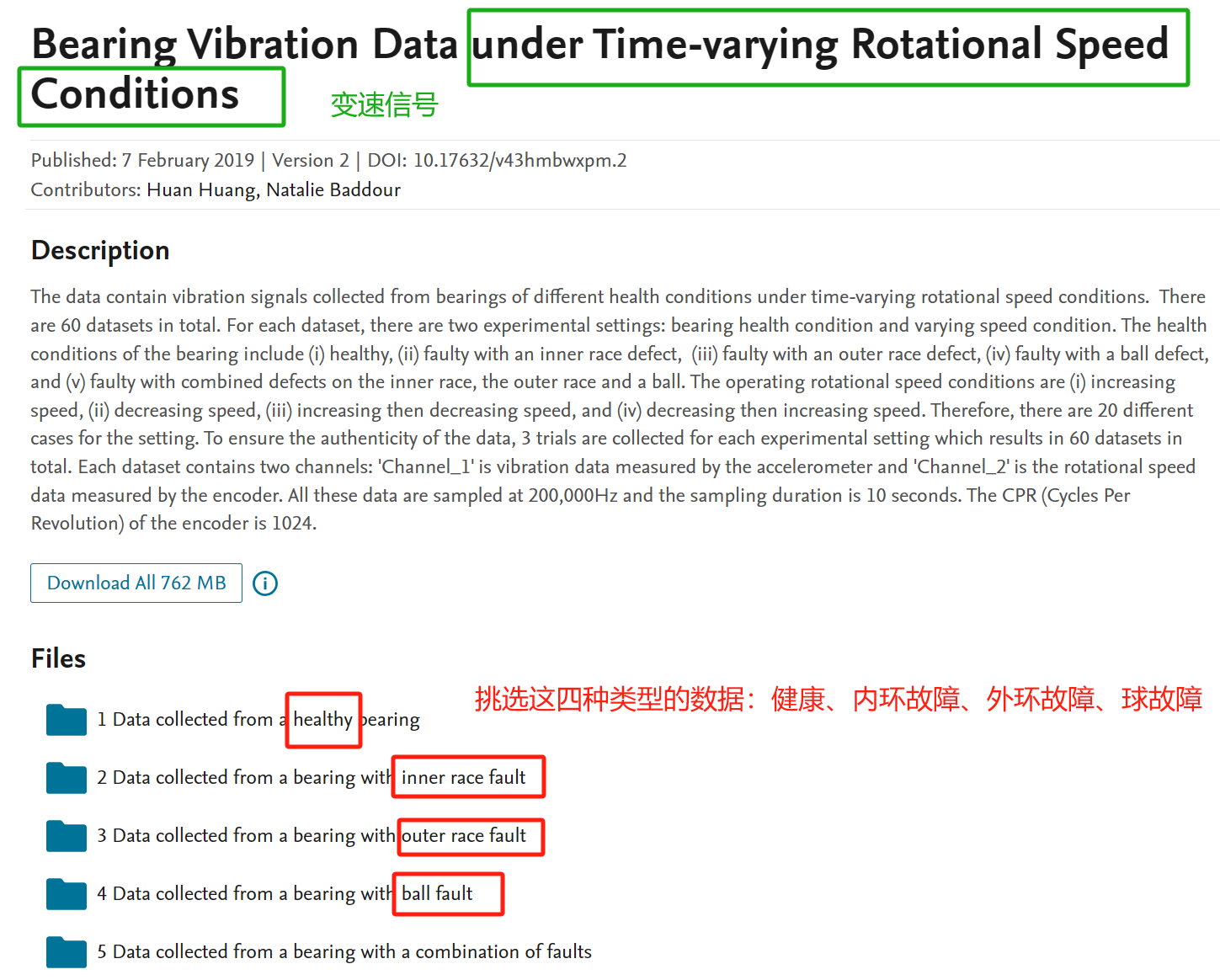
挑选加拿大渥太华的变速轴承数据集
Bearing Vibration Data under Time-varying Rotational Speed Conditions - Mendeley Data
import scipy.io as sio
import numpy as np
import random
import os
# 定义基础路径
base_path = 'D:/0A_Gotoyourdream/00_BOSS_WHQ/A_Code/A_Data/'
# 定义各类别对应的mat文件
file_mapping = {
'H': 'H-B-1.mat',
'I': 'I-B-1.mat',
'B': 'B-B-1.mat',
'O': 'O-B-2.mat'
}
# 定义每个类别需要抽取的数量
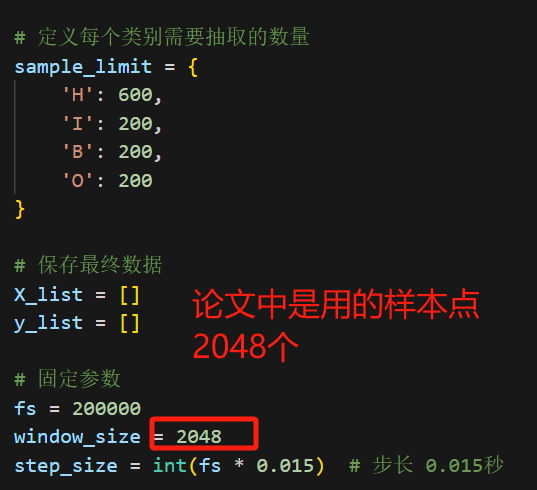
sample_limit = {
'H': 600,
'I': 200,
'B': 200,
'O': 200
}
# 保存最终数据
X_list = []
y_list = []
# 固定参数
fs = 200000
window_size = 2048
step_size = int(fs * 0.015) # 步长 0.015秒
# 类别编码
label_mapping = {'H': 0, 'I': 1, 'B': 3, 'O': 2} # 注意和你之前保持一致
# 创建保存目录(可选)
output_dir = os.path.join(base_path, "ClassBD-Processed_Samples")
os.makedirs(output_dir, exist_ok=True)
# 遍历每一类数据
for label_name, file_name in file_mapping.items():
print(f"正在处理类别 {label_name}...")
mat_path = os.path.join(base_path, file_name)
dataset = sio.loadmat(mat_path)
# 提取振动信号并去直流分量
vib_data = np.array(dataset["Channel_1"].flatten().tolist()[:fs * 10])
vib_data = vib_data - np.mean(vib_data)
# 滑窗切分样本
vib_samples = []
start = 0
while start + window_size <= len(vib_data):
sample = vib_data[start:start + window_size].astype(np.float32) # 降低内存占用
vib_samples.append(sample)
start += step_size
vib_samples = np.array(vib_samples)
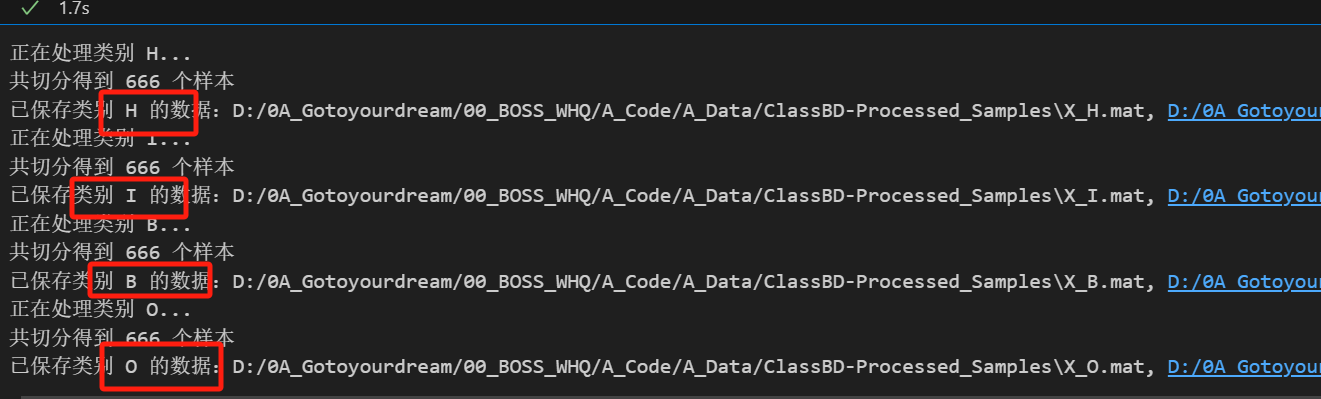
print(f"共切分得到 {vib_samples.shape[0]} 个样本")
# 抽样
if vib_samples.shape[0] < sample_limit[label_name]:
raise ValueError(f"类别 {label_name} 样本不足(仅 {vib_samples.shape[0]}),无法抽取 {sample_limit[label_name]} 个")
selected_indices = random.sample(range(vib_samples.shape[0]), sample_limit[label_name])
selected_X = vib_samples[selected_indices]
selected_y = np.full(sample_limit[label_name], label_mapping[label_name], dtype=np.int64)
# 保存
save_path_X = os.path.join(output_dir, f"X_{label_name}.mat")
save_path_y = os.path.join(output_dir, f"y_{label_name}.mat")
sio.savemat(save_path_X, {'X': selected_X})
sio.savemat(save_path_y, {'y': selected_y})
print(f"已保存类别 {label_name} 的数据:{save_path_X}, {save_path_y}")
2. 读取并合并数据
import os
import scipy.io as sio
import numpy as np
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
# ========== 1. 读取四类数据 ==========
base_path = "D:/0A_Gotoyourdream/00_BOSS_WHQ/A_Code/A_Data/ClassBD-Processed_Samples"
def load_data(label):
X = sio.loadmat(os.path.join(base_path, f"X_{label}.mat"))["X"]
y = sio.loadmat(os.path.join(base_path, f"y_{label}.mat"))["y"].flatten()
return X.astype(np.float32), y.astype(np.int64)
X_H, y_H = load_data("H")
X_I, y_I = load_data("I")
X_B, y_B = load_data("B")
X_O, y_O = load_data("O")
# ========== 2. 合并数据 + reshape ==========
X_all = np.concatenate([X_H, X_I, X_B, X_O], axis=0)
y_all = np.concatenate([y_H, y_I, y_B, y_O], axis=0)
X_all = X_all[:, np.newaxis, :] # (N, 1, 200000)
3.划分训练集/测试集
我这里定义的训练集70%,测试集30%。可以随意更改。
# ========== 3. 划分训练/测试集 ==========
X_train, X_test, y_train, y_test = train_test_split(X_all, y_all, test_size=0.3, stratify=y_all, random_state=42)
4.DataLoader
文献里的batch_size是128,想想自己的笔记本,还是调小一点...
# ========== 4. DataLoader ==========
train_dataset = TensorDataset(torch.tensor(X_train), torch.tensor(y_train))
test_dataset = TensorDataset(torch.tensor(X_test), torch.tensor(y_test))
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
5. 定义模型结构
# ========== 5. 定义模型结构 ==========
from Model.BDCNN import BDWDCNN # 确保你能import成功
model = BDWDCNN(n_classes=4)6. 定义损失函数、优化器、调度器
# ========== 6. 定义损失函数、优化器、调度器 ==========
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=200)7. 开始训练
我这里定义的是90次,原文是200次
# ========== 7. 开始训练 ==========
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
for epoch in range(1, 91):
model.train()
running_loss = 0.0
correct = 0
total = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs, _, _ = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
scheduler.step()
train_acc = correct / total * 100
# 测试集评估
model.eval()
correct_test = 0
total_test = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs, _, _ = model(inputs)
_, predicted = outputs.max(1)
total_test += labels.size(0)
correct_test += predicted.eq(labels).sum().item()
test_acc = correct_test / total_test * 100
print(f"Epoch {epoch:03d}: Loss={running_loss:.4f}, Train Acc={train_acc:.2f}%, Test Acc={test_acc:.2f}%")出来结果比我想象中快很多。
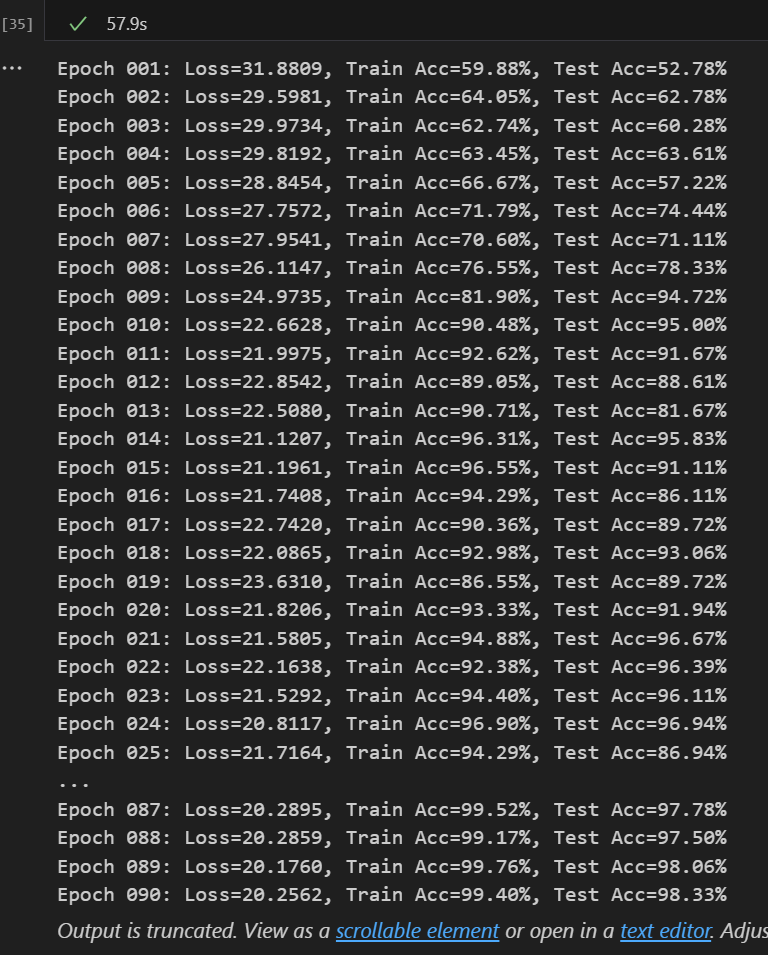
如果训练集比较足够的时候有用,准确率很高。
因为之后想针对少样本、跨数据集的研究。所以我也顺便试了一下在少样本的情况下的表现。
(训练集只有10%,迭代次数增加到200)
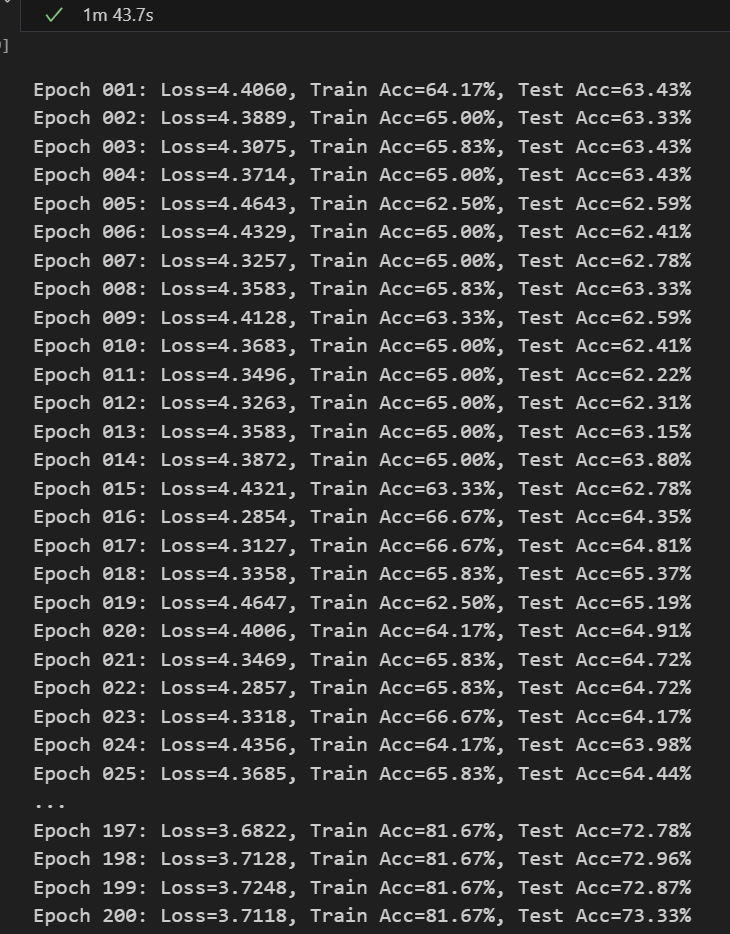
【可以加在论文里当作对比了,嘿嘿】