目的 :熟练操作组合数据类型。
试验任务:
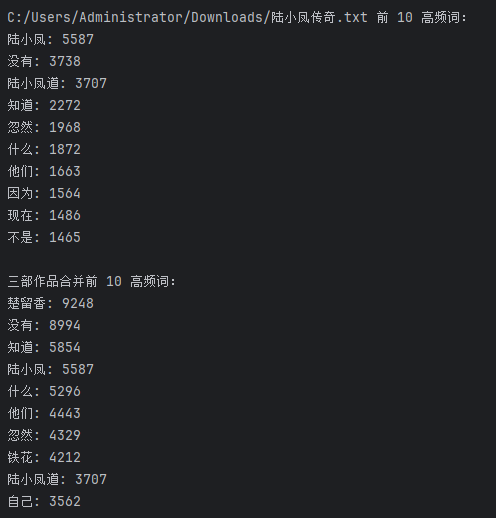
1. 基础:生日悖论分析。如果一个房间有23人或以上,那么至少有两个人的生日相同的概率大于50%。编写程序,输出在不同随机样本数量下,23 个人中至少两个人生日相同的概率。
import random
def has_duplicate_birthdays():
birthdays = [random.randint(1, 365) for _ in range(23)]
return len(set(birthdays)) < 23
def calculate_probability(sample_size):
duplicate_count = 0
for _ in range(sample_size):
if has_duplicate_birthdays():
duplicate_count += 1
return duplicate_count / sample_size
sample_sizes = [100, 1000, 10000, 100000]
for size in sample_sizes:
probability = calculate_probability(size)
print(f"样本数量为 {size} 时,23个人中至少两个人生日相同的概率是: {probability * 100:.2f}%")
运行结果:
2. 进阶:统计《一句顶一万句》文本中前10高频词,生成词云。
import jieba
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
def read_text(file_path):
try:
with open(file_path, 'r', encoding='GB18030') as file:
return file.read()
except FileNotFoundError:
print(f"错误:未找到文件 {file_path}。")
return None
def preprocess_text(text):
# 加载停用词(包含单字和无意义词语)
stopwords = set()
try:
with open('stopwords.txt', 'r', encoding='GB18030') as f:
for line in f:
stopwords.add(line.strip())
except FileNotFoundError:
print("警告:未找到停用词文件 'stopwords.txt',将不进行停用词过滤。")
# 分词并过滤:保留长度>=2的词语,排除停用词和空字符串
words = jieba.lcut(text)
filtered_words = [
word for word in words
if len(word) >= 2 and word not in stopwords and word.strip()
]
return filtered_words
def get_top_10_words(words):
word_count = Counter(words)
top_10 = word_count.most_common(10)
return top_10
def generate_wordcloud(words):
text = ' '.join([word for word, _ in words])
# 使用中文字体(需确保字体文件存在,可替换为系统字体路径)
wordcloud = WordCloud(
font_path='simhei.ttf',
background_color='white',
width=800,
height=400
).generate(text)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
if __name__ == "__main__":
file_path = "C:/Users/Administrator/Downloads/一句顶一万句(www.mkdzs.com).txt"
text = read_text(file_path)
if text:
processed_words = preprocess_text(text)
top_10 = get_top_10_words(processed_words)
print("前 10 个高频词:")
for word, freq in top_10:
print(f"{word}: {freq}")
generate_wordcloud(top_10)
运行结果:

3. 拓展:金庸、古龙等武侠小说写作风格分析。输出不少于3个金庸(古龙)作品的最常用10个词语,找到其中的相关性,总结其风格。
金庸小说:
import jieba
from collections import Counter
import os
def load_stopwords():
"""加载停用词"""
stopwords = set()
with open('stopwords.txt', 'r', encoding='utf-8') as f:
for line in f:
stopwords.add(line.strip())
return stopwords
def process_text(text, stopwords):
"""处理文本,返回过滤后的词语列表(仅保留双字及以上)"""
words = jieba.lcut(text)
return [word for word in words if len(word) >= 2 and word not in stopwords]
def get_top_words(words, n=10):
"""获取高频词语"""
return Counter(words).most_common(n)
def main():
stopwords = load_stopwords()
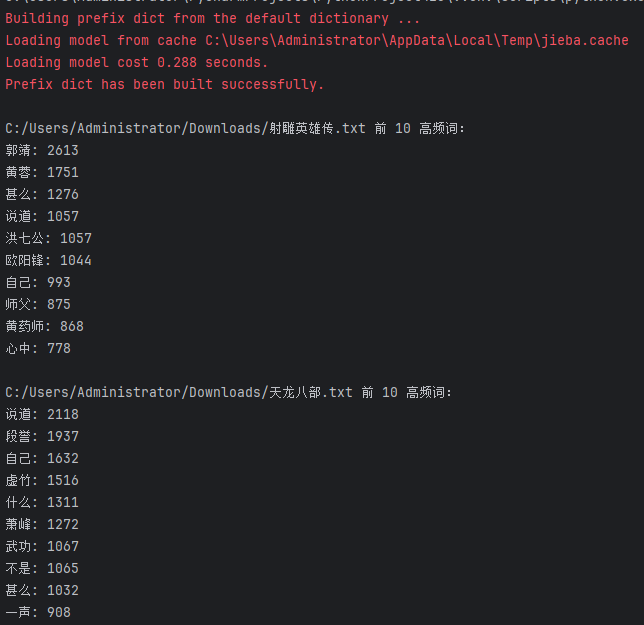
jinyong_works = ["C:/Users/Administrator/Downloads/射雕英雄传.txt", 'C:/Users/Administrator/Downloads/天龙八部.txt', 'C:/Users/Administrator/Downloads/笑傲江湖.txt']
# 输出单部作品高频词
for work in jinyong_works:
if not os.path.exists(work):
print(f"错误:未找到文件 {work}")
continue
with open(work, 'r', encoding='GB18030') as f:
text = f.read()
words = process_text(text, stopwords)
top_10 = get_top_words(words)
print(f"\n{work} 前 10 高频词:")
for word, freq in top_10:
print(f"{word}: {freq}")
# 合并三部作品统计高频词
all_words = []
for work in jinyong_works:
with open(work, 'r', encoding='GB18030') as f:
text = f.read()
words = process_text(text, stopwords)
all_words.extend(words)
global_top = get_top_words(all_words)
print("\n三部作品合并前 10 高频词:")
for word, freq in global_top:
print(f"{word}: {freq}")
# 总结风格
print("\n【金庸作品写作风格分析】")
print("相关性:单部作品高频词如‘江湖’‘郭靖’‘黄蓉’等人物与门派、武功相关词汇,与合并后的高频词高度相关,均围绕武侠世界的核心元素,体现金庸作品对人物塑造、门派纷争和武功体系的着重刻画。")
print("风格总结:")
print("- **构建宏大江湖格局**:通过‘江湖’‘门派’‘天下’等词,展现复杂的武林秩序与势力纷争,如各大门派(少林、武当等)在江湖中的地位与纷争。")
print("- **强调侠义精神与人物塑造**:‘大侠’‘英雄’等词体现对‘侠之大者,为国为民’的推崇,同时对主角(如郭靖、乔峰)的刻画细致入微,通过高频人物名展现人物影响力。")
print("- **武功体系与情节严谨**:对武功(‘九阴真经’‘降龙十八掌’等)的描写细致,情节跌宕且逻辑严密,通过‘比武’‘较量’等隐含词汇展现江湖中的武功较量与成长线。")
print("- **语言典雅古朴**:虽代码未直接体现,但结合作品可知,其语言风格符合传统武侠的典雅,在人物对话与场景描写中体现深厚文化底蕴。")
if __name__ == "__main__":
main()运行结果:


古龙小说:
import jieba
from collections import Counter
import os
def load_stopwords():
"""加载停用词"""
stopwords = set()
with open('stopwords.txt', 'r', encoding='utf - 8') as f:
for line in f:
stopwords.add(line.strip())
return stopwords
def process_text(text, stopwords):
"""处理文本,返回过滤后的词语列表(仅保留双字及以上)"""
words = jieba.lcut(text)
return [word for word in words if len(word) >= 2 and word not in stopwords]
def get_top_words(words, n = 10):
"""获取高频词语"""
return Counter(words).most_common(n)
def main():
stopwords = load_stopwords()
gulong_works = ['C:/Users/Administrator/Downloads/多情剑客无情剑.txt', 'C:/Users/Administrator/Downloads/楚留香传奇.txt', "C:/Users/Administrator/Downloads/陆小凤传奇.txt"]
# 输出单部作品高频词
for work in gulong_works:
if not os.path.exists(work):
print(f"错误:未找到文件 {work}")
continue
with open(work, 'r', encoding='GB18030') as f:
text = f.read()
words = process_text(text, stopwords)
top_10 = get_top_words(words)
print(f"\n{work} 前 10 高频词:")
for word, freq in top_10:
print(f"{word}: {freq}")
# 合并三部作品统计高频词
all_words = []
for work in gulong_works:
with open(work, 'r', encoding='GB18030') as f:
text = f.read()
words = process_text(text, stopwords)
all_words.extend(words)
global_top = get_top_words(all_words)
print("\n三部作品合并前 10 高频词:")
for word, freq in global_top:
print(f"{word}: {freq}")
# 总结风格
print("\n【古龙作品写作风格分析】")
print("相关性:单部作品高频词如‘江湖’‘浪子’‘一笑’等,与合并后的高频词高度相关,均围绕江湖中的人物性情、独特行事风格与情感基调,体现古龙作品对江湖个体命运与情感的聚焦。")
print("风格总结:")
print("- **江湖与浪子情怀**:高频词‘江湖’‘浪子’凸显其作品多围绕江湖中浪子形象展开(如李寻欢、楚留香),这些人物自由不羁却又受江湖恩怨羁绊,传达出‘人在江湖,身不由己’的宿命感,构建了一个充满传奇与无奈的江湖世界。")
print("- **语言简洁诗意**:常用‘一笑’‘寂寞’‘孤独’等词,语言简洁明快且富有诗意,大量使用短句(受海明威‘电报体’影响),节奏紧凑,同时蕴含哲理(如‘笑红尘,红尘笑,笑尽人间独寂寥’),给读者留下想象空间。")
print("- **人物个性鲜明**:通过‘英雄’‘怪人’‘剑客’等词,塑造出一批个性独特的人物形象(如陆小凤的机智洒脱、西门吹雪的冷傲孤僻),人物形象突破传统武侠的单一模式,更具现代性与复杂性。")
print("- **情节奇险悬疑**:虽代码未直接体现,但古龙常将悬疑、推理元素融入武侠情节(如《楚留香传奇》中的探案情节),以‘奇险’‘突变’推动故事发展,打破常规叙事节奏,满足读者对新奇与刺激的阅读需求。")
if __name__ == "__main__":
main()运行结果: