
| 算法 | 相关知识点 | 可以通过点击 | 以下链接进行学习 | 一起加油! |
|---|---|---|---|---|
| 双指针 | 滑动窗口 | 二分查找 | 前缀和 | 位运算 |
| 模拟 | 链表 |
在刷题的过程中,我们会频繁遇到一些“高频套路”——而哈希表正是其中最常用也最高效的工具之一。它能帮助我们在 O(1) 的时间复杂度内完成查找、插入与删除操作。
本文将围绕常见的算法题场景,系统性地拆解哈希表的应用思路,帮助你快速识别题型、构建解题模板,并提升解题效率。


🌈个人主页:是店小二呀
🌈C/C++专栏:C语言\ C++
🌈初/高阶数据结构专栏: 初阶数据结构\ 高阶数据结构
🌈Linux专栏: Linux
🌈算法专栏:算法
🌈Mysql专栏:Mysql
🌈你可知:无人扶我青云志 我自踏雪至山巅
文章目录
一、哈希表概念
哈希表就像是一个很智能的储物柜,每个数据都有一个特定的“标签”(哈希值),通过这个标签可以直接找到数据存放的位置,而不用遍历所有的内容
二、哈希表作用
哈希表的作用可以概括为:
- 快速查找:哈希表通过哈希函数把元素映射到数组的索引位置,使得查找操作非常快速,接近常数时间复杂度(O(1))。
- 元素标记:配合布尔数组使用,可以方便地标记某个元素是否存在,适用于去重或记录状态等场景。
- 统计频次:利用哈希表记录元素出现的次数,能够高效地进行频率统计,无需遍历整个数据集。
- 字符串连续下标:对于字符串等数据,哈希表可以通过哈希值将其映射到连续的下标上,便于快速索引和操作。
三、如何使用哈希表
容器(哈希表)
用数组模拟简易哈希表:字符串中的"字符" 和 “数据范围很小的时候”
1. 两数之和
【题目】:1. 两数之和
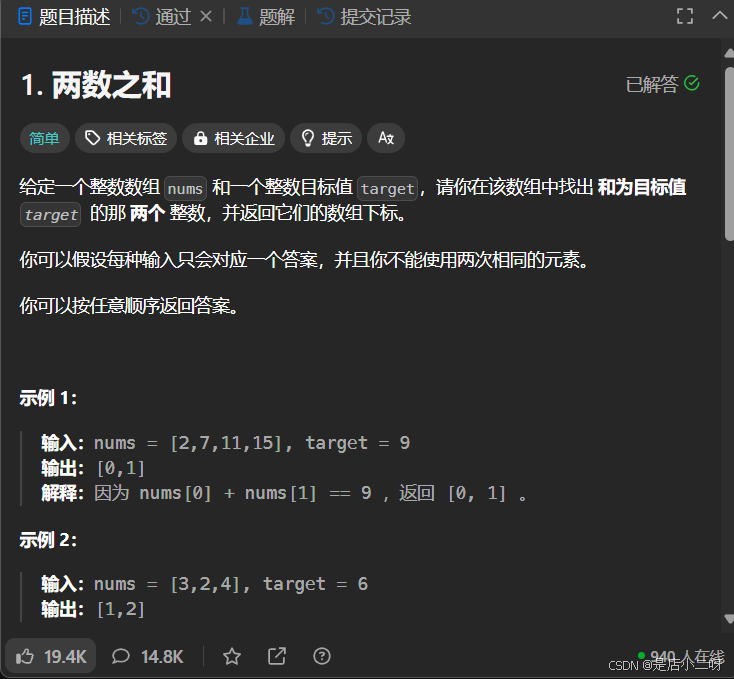
【算法思路】
解法一:暴力解法
先固定其中一个数
依次与该数之前的数相加
解法二:使用哈希表来优化

这道题与“560. 和为 K 的子数组”类似,利用了哈希表的特性。通过哈希表的 count 接口,可以迅速判断前面是否已经出现过相关元素,实现了快速查找。具体来说,问题通过 target 和 nums[i] 之间的等价关系,将原本的问题转化为寻找前面已出现元素的哈希查找问题。
哈希表存储数组元素及其对应的下标,便于快速访问和操作数组元素。
【代码实现】
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target)
{
unordered_map<int, int> hash;
for(int i = 0; i < nums.size(); i++)
{
int ret = target - nums[i];
if(hash.count(ret)) return {i, hash[ret]};
hash[nums[i]] = i;
}
return {-1, -1};
}
};
面试题 01.02. 判定是否互为字符重排
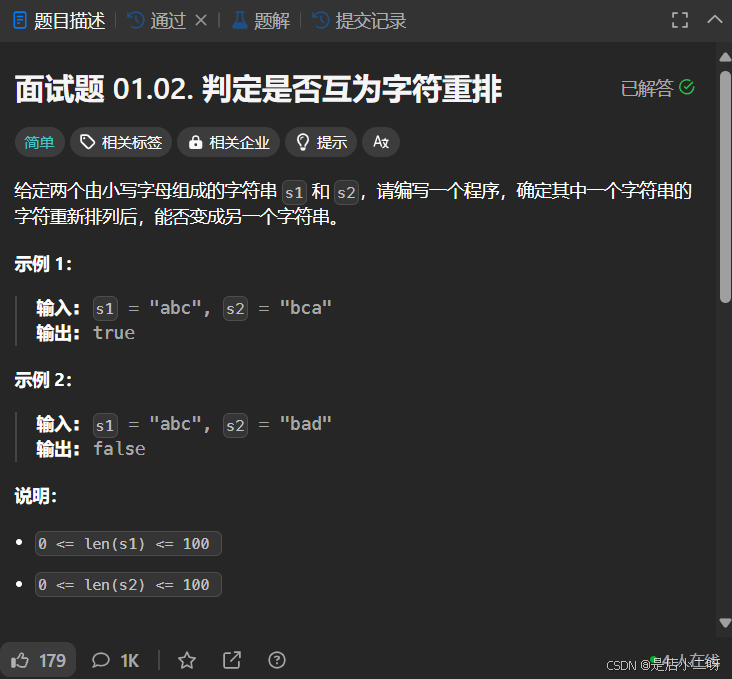
【算法思路】
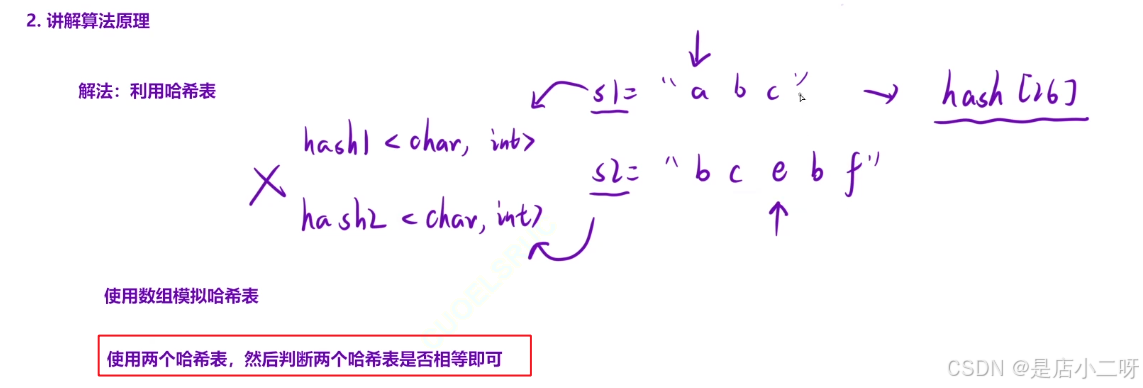
哈希表不关心元素的顺序,只要是数据就存进去,然后通过哈希值来判断元素是否相等
【优化方案】
只使用一个哈希表进行统计,然后在遍历另一个哈希表时不断减少对应元素的计数。如果哈希表中的元素次数为0,说明两个字符串相同。由于只涉及小写字母,我们可以用一个大小为26的数组来模拟哈希表,从而减少空间开销。
【代码实现】
class Solution {
public:
bool CheckPermutation(string s1, string s2)
{
int n = s1.size();
if(n != s2.size()) return false;
int hash[26] = {0};
for(auto ch: s1)
hash[ch - 'a']++;
for(auto x : s2)
{
hash[x - 'a']--;
if(hash[x - 'a'] < 0) return false;
}
return true;
}
};
217. 存在重复元素
【题目】:217. 存在重复元素
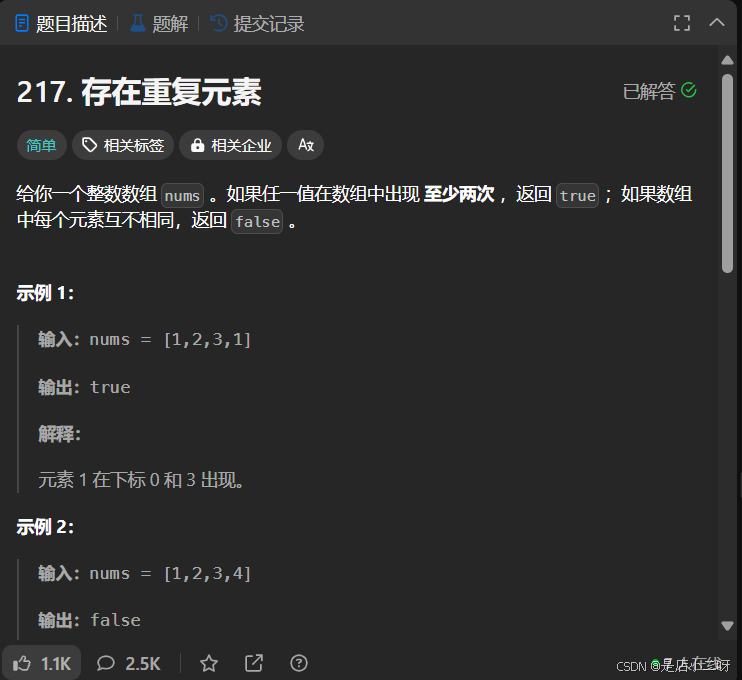
【算法思路】
判断是否存在重复元素,哈希表中count接口可以查看先前是否存储相关元素,同当前nums[i]判断,意思就是之前的数等于nums[i],当前遍历到nums[i],说明存在重复元素
【代码实现】
class Solution {
public:
bool containsDuplicate(vector<int>& nums)
{
//只需要判断是否重现即可,不需要得知次数
unordered_setint, int> hash;
for(auto x : nums)
{
if(hash.count(x)) return true;
else hash.insert(x);
}
return false;
}
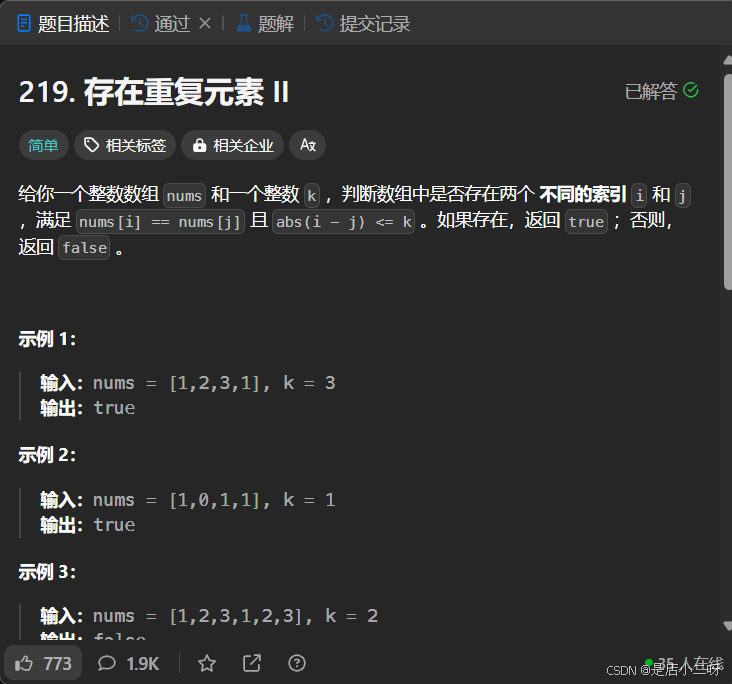
219. 存在重复元素 II
【题目】:219. 存在重复元素 II
【算法思路】
我们可以通过哈希表来实现快速查找。遍历数组时,对于每个元素 nums[i],我们在哈希表中查看是否已经出现过该元素。如果出现过,判断当前下标 i 与之前相同元素的下标差是否小于等于 k,若满足条件,则返回 true,表示存在满足条件的重复元素。如果遍历结束都没有找到满足条件的元素,则返回 false。
【代码实现】
class Solution {
public:
bool containsNearbyDuplicate(vector<int>& nums, int k)
{
unordered_map<int, int> hash;
for(int i = 0; i < nums.size(); i++)
{
if(hash.count(nums[i]))
{
if(i - hash[nums[i]] <= k) return true;
}
hash[nums[i]] = i;
}
return false;
}
};
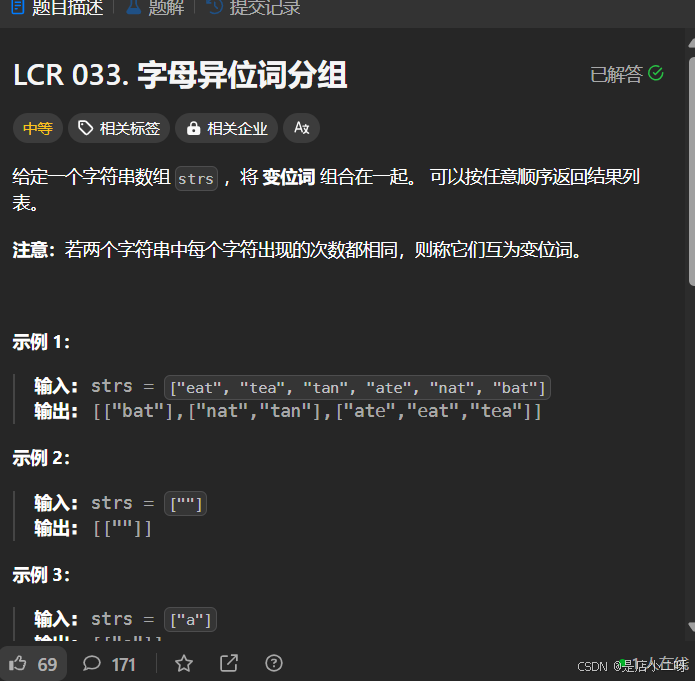
LCR 033. 字母异位词分组
【题目】:LCR 033. 字母异位词分组
【算法思路】

遍历字符串数组,将每个字符串排序后,利用哈希表的 first 存储已排序的字符串作为键,对应的值存储原始字符串。这里充分利用了哈希表作为存储容器的特性。最终,返回字符串数组时,可以通过 auto& [x, y] : hash 来遍历哈希表,这样就能方便地取出每一项的“键”和“值”,并直接使用它们。
【代码实现】
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs)
{
unordered_map<string, vector<string>> hash;
for(auto& s : strs)
{
string tmp = s;
sort(tmp.begin(), tmp.end());
hash[tmp].push_back(s);
}
vector<vector<string>> ret;
for(auto&[x,y] : hash)
{
ret.push_back(y);
}
return ret;
}
};

快和小二一起踏上精彩的算法之旅!关注我,我们将一起破解算法奥秘,探索更多实用且有趣的知识,开启属于你的编程冒险!