大家好,我是“蒋点数分”,多年以来一直从事数据分析工作。从今天开始,与大家持续分享关于数据分析的学习内容。
本文是第 5 篇,也是【SQL 周周练】系列的第 4 篇。该系列是挑选或自创具有一些难度的 SQL 题目,一周至少更新一篇。后续创作的内容,初步规划的方向包括:
后续内容规划
1.利用 Streamlit 实现 Hive 元数据展示、SQL 编辑器、 结合Docker 沙箱实现数据分析 Agent2.时间序列异常识别、异动归因算法
3.留存率拟合、预测、建模
4.学习 AB 实验、复杂实验设计等
5.自动化机器学习、自动化特征工程
6.因果推断学习
7. ……
欢迎关注,一起学习。
第 4 期题目
题目来源:自创题目,曾经在工作中遇到过该问题
一、题目介绍
公司市场部找到一些达人在抖音、快手等平台进行短视频营销,需要监测视频的点赞量。公司内有一位专职的爬虫工程师,他的项目也很多。因此很难对该项目爬虫数据提供高质量的维护,会出现一些字段缺失的情况。
我们将问题简化,有一张表记录了爬虫抓取的短视频点赞量数据,其中部分日期的点赞量是缺失的。请你利用 SQL 将这些数据补齐,即“插值”。
列名 |
数据类型 |
注释 |
video_id |
string |
短视频id |
dt |
string |
日期 |
likes_num |
int |
点赞量(用来对比结果,不要直接用) |
show_likes_num |
int |
展示点赞量(用来补全数据) |
用 SQL 实现几种比较简单的插值方法,复杂的方法可以利用 Hive 中的 transform 函数调用 Python 脚本来实现(后面哪期会根据这个点水一篇文章)
本文实现的简单补全方法有:
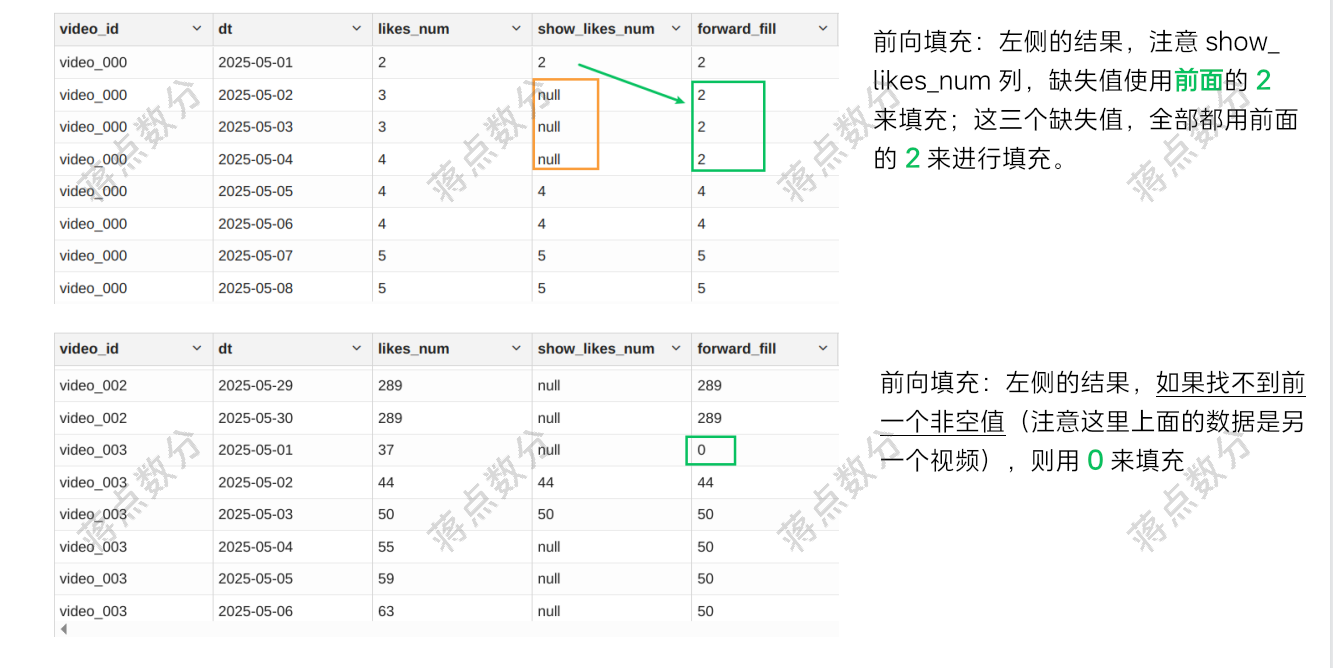
1.前向填充,使用前面最近的一个非空值来填充
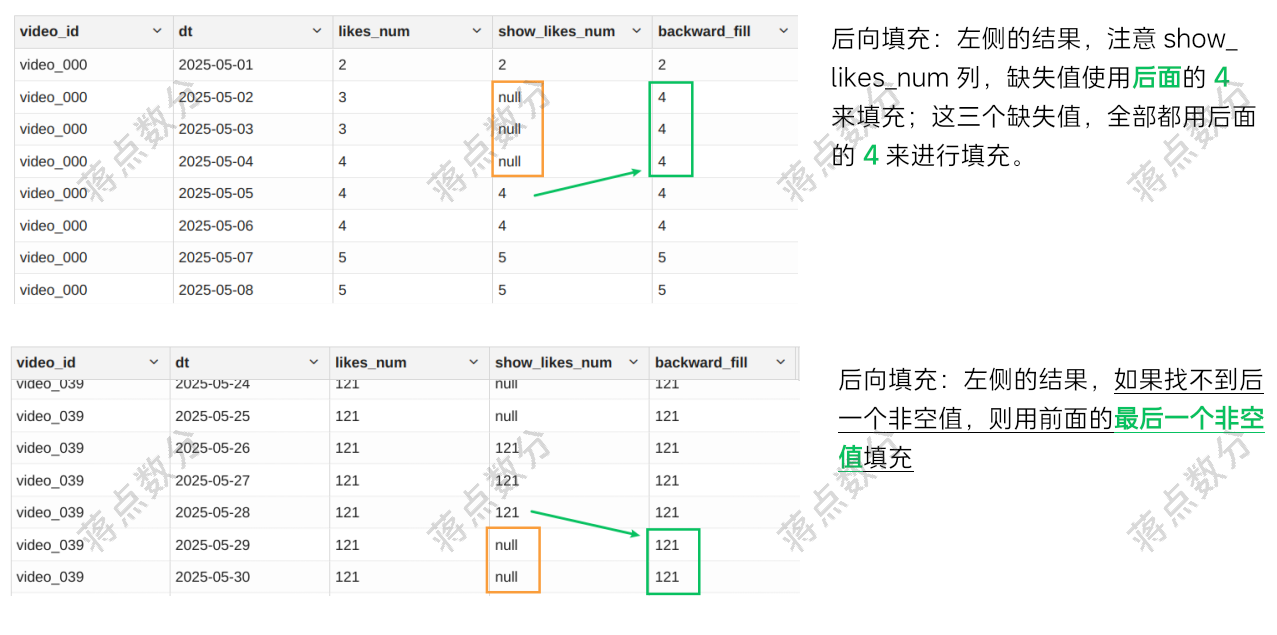
2.后向填充,使用后面最近的一个非空值来填充
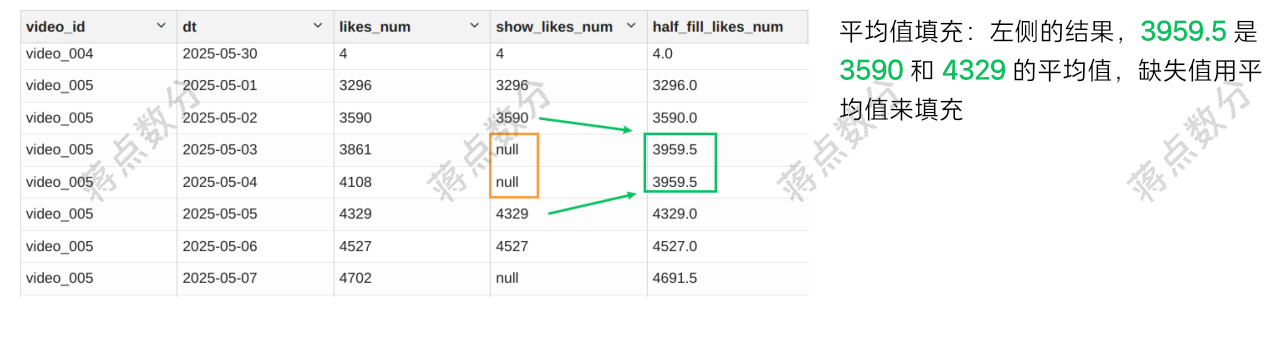
3.相邻的平均数填充,使用前后最近的非空值,取两个数的平均数填充
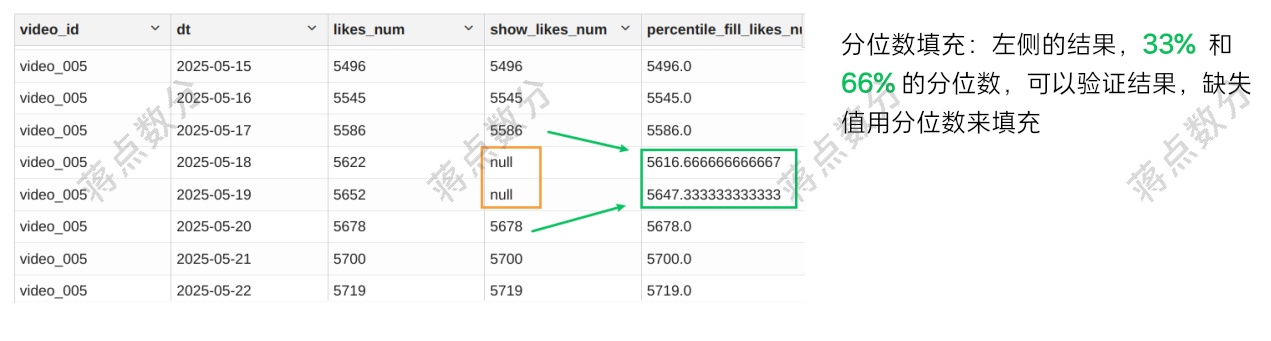
4.相邻的分位数填充,使用前后最近的非空值,缺失值根据分位数来填充
额外说明:这四种方法都依赖于缺失值邻近的前后非空值,需要存在这样的非空值。
如果该非空值不存在,比如短视频第一天发布就没有爬取到点赞量 —— 这样没有办法,找到它之前的非空点赞量。我本文的处理方法是将它“视为”前一天发布,或者说增加一个前一条点赞量为零的数据(还有其他的处理方法,我这里只提出一种)。
这条增加的数据不需要显式存在,只不过是在数据处理时兜底的逻辑等效于它。而如果短视频缺少的是最后几天的数据,比如某一天开始后面一直缺失数据,这样就将最后一个有数据的点赞量“顺延”下去。这 4 种填充方法,都用这样的逻辑兜底。
二、题目思路
想要答题的同学,可以先思考答案🤔。
.……
.……
.……
我来谈谈我的思路:
1.前向填充,使用前面最近的非空值来填充。使用 last_value 窗口函数来实现,注意 last_value 支持两个参数,其中第二个参数设置为 true 则在寻找的时候跳过 null;注意 rows 的范围,另外如果前面实在找不到非 null 值,用 0 来兜底。
2.后向填充,使用后面最近的非空值来填充。使用 first_value 窗口函数来实现,同样 first_value 也是支持两个参数,其中第二个参数设置为 true 则在寻找的时候跳过 null;这个 rows 的范围更要注意。如果后面实在找不到非 null 值,用前一个非 null 值兜底。所以这里要同时往前往后查找。
3.相邻的平均数填充,融合了前两种方法,前向和后向数据都要寻找,找到后求平均值,这里要更加小心的处理找不到的情况。
4.相邻的分位数填充,是上一种方法的改进。比如 2 个有效的点赞量中间缺少了 3 天的数据,如果这 3 天的数据都用这 2 个有效值的平均值来填充,则相当于这几天的点赞数没有变化,这逻辑不太现实。
采用分位数的方法保持线性增长的关系去填充,比上一种方法更好。注意如果真的是这 2 个有效点赞量数据一致,也就是假设这几天点赞量数据停止变化。平均数和分位数填充,计算的结果是能“兼容”这种情况。
下面,我用 NumPy 和 Scipy 生成模拟的数据集:
三、生成模拟数据
只关心 SQL 代码的同学,可以跳转到第四节(我在工作中使用 Hive 较多,因此采用 Hive 的语法)
模拟代码如下:
- 定义模拟逻辑需要的
常量,定义随机数发生器:
2. 使用 Gompertz 函数模拟短视频点赞量每日变化。大家一般都知道用 S 型曲线模拟这类增长但有上限的数据,最常见的就是 Logistic 函数。我这里用 Gompertz 函数纯粹是以前没用过,尝尝鲜。工作中肯定是用这两个函数的拟合效果来对比。网上能搜到大量文章从数学角度对两者进行对比。我这里偷懒就不研究了,大家可以自行搜索:
Gompertz 函数其中的
在 scipy.stats.lognorm 中,s 是形状参数,对应正态分布的标准差
scale 是尺度参数,对应正态分布的指数均值
根据 Gompertz 函数的定义,参数
3. 定义随机缺失数据的标识,注意点赞量是整数,四舍五入后转为整数。将前面生成的数据转为 pd.DataFrame,并输出为 csv 文件:
4. 如果表存在则删除,创建新的 Hive 表,并将数据 load 到表中:
我通过使用
PyHive包实现 Python 操作Hive。我个人电脑部署了Hadoop及Hive,但是没有开启认证,企业里一般常用Kerberos来进行大数据集群的认证。
四、SQL 解答
1.前向填充的 sql 语句,如果使用 last_value 则 rows 的范围是 between unbounded preceding and 1 preceding。如果省略这部分,只保留 order by dt asc,则默认为 between unbounded preceding and current row 从最终效果来说是一致的,但是前者写法表述更准确
部分结果验证:
2.后向填充的 sql 语句,如果使用 first_value 则 rows 的范围是 between 1 following and unbounded following。注意 first_value 和 last_value 都是跟 order by dt 的顺序有关,完全可以使用 desc 降序来切换另一个函数。
部分结果验证:
3.相邻平均数填充的 sql 语句,寻找前后相邻的非空值逻辑,这里不再赘述。对前后相邻的非空值求平均,注意这里的兜底逻辑。首先上一个非空点赞量如果不存在,那就填充零,因此求平均的分母这部分的 “1” 必然存在;如果下一个非空点赞量不存在,可以将其当成零,那么分母求平均时,它就不起作用,它的分母部分是 “0”;最后结果注意四舍五入(如果写成显式的判断逻辑也可以,需要引入 if 或 case when 语句)。
注意结果要取整,我这里不取整,是为了跟大家展示结果时去反向验证:
部分结果验证:
4.相邻分位数填充的 sql 语句,基本逻辑跟平均数一样;但是不是简单求平均,而是需要计算每个缺失值所在的分位数位置,来“线性插值”。这里稍微推导一下再写 sql:我将缺失值的上一个邻近非空值记为 s,下一个邻近非空值记为 e;因为是分位数,还要考虑位置,将上一个邻近非空值的序号记为 m,下一个邻近非空值记为 n,这个缺失值的位置记录为 i。则根据推导它的位置分位数应该是 (i-m)/(m-n),我们再推导它的值应该是 s + (e-s)*(i-m)/(m-n) 化简后为 s*(n-i)+e*(i-m)。在 sql 中,我利用日期充当序号,序号之间的减法结果,我用 datediff 函数来处理,代码如下:
注意里面的兜底逻辑,比如取一个 min(dt) 作为如果找到前面的非空值,则将其设置为更早日期的前一天,求 i_m 即 i-m 时 datediff(dt, base_dt)+1 的 +1 就是这么来的。如果 e 不存在,也就是下一个非空值找不到,直接用上一个非空值“顺延”下去。
部分结果验证:
😁😁😁我现在正在求职数据类工作(主要是数据分析或数据科学);如果您有合适的机会,恳请您与我联系,即时到岗,不限城市。