前沿重器
栏目主要给大家分享各种大厂、顶会的论文和分享,从中抽取关键精华的部分和大家分享,和大家一起把握前沿技术。具体介绍:仓颉专项:飞机大炮我都会,利器心法我还有。(算起来,专项启动已经是20年的事了!)
2024年文章合集最新发布!在这里:再添近20万字-CS的陋室2024年文章合集更新
往期回顾
最近留意到一篇比较实用的论文,借助个性化实时检索来实现机器人的主动对话能力。
主动对话其实从很久之前就已经是对话系统研究的重点,目前仍有很多对话系统基本都是被动地回答客户的问题,机器人很难主动地提出问题甚至引导用户把对话尽可能聊下去。论文通过感知用户的个人偏好,结合目前对话状态,进行合适的信息检索,结合检索结果给出合适的回复,以保证对话持续进行下去。
值得注意的是,论文指出该方案已经在生产环境超过30天。
Our approach has been running stably in a real-world production environment for more than 30 days
论文链接:
论文:PaRT: Enhancing Proactive Social Chatbots with Personalized Real-Time Retrieval
原文链接:https://arxiv.org/abs/2504.20624
讲解:https://blog.csdn.net/2401_85375298/article/details/147730608
论文内没有什么公式,更多是思路的介绍和应用思路,初看可能会觉得论文的内容比较随意,但这些思路我自己的感觉还是挺有启发的,另外有一些方案细节,按照作者的意思基本是参考了一些论文的实践建议,给了不少参考文献,下文的关键部分,我也会列举一部分,有兴趣的读者也可以按需阅读。
下面我按照我的思路来介绍这篇论文并解析这篇论文对我的启发。
主动对话的概念
文章主要方法
-
用户画像
意图引导的查询优化器
检索增强生成
实验细节
启发和思考
主动对话的概念
论文核心解决的问题就是“主动对话”(proactive dialogues),所谓主动对话,我的理解是这样的。
对话系统能够主动引导对话走向、发起新话题或预判用户需求,而非被动等待用户输入。
所谓的主动,他是相比一般被动式而言的,一般的对话系统,只能根据用户提出的明确问题,提供必要的回复,但并不能主动地提出话题、引导话题。然而目前已经有众多场景其实已经有类似的需求,也有一些主动对话的方案,但人工干预的会有些多,类似任务型对话,引导填槽的那种,早就比较多了,所谓的“主动”,包括推荐系统、搜索引导(猜你想搜)、手机APP隔三差五在通知栏给你推的东西,多半都带有主动的性质。
而在大模型时代,靠着大模型的推理能力,能有效产生内容衔接流畅、匹配的内容,有很多新的方案,根据论文,目前的方案主要有两个问题:
内容泛化:即生成的话题过于泛化通用,和用户偏好并不匹配。这个其实也是大模型目前的一个大问题,很多场景下会生成一些“正确的废话”,就类似“多喝热水”式的回复。
知识局限:受限于大模型的知识边界,对有一定深度的对话,可能就比较难维持得住了。
因此,需要进一步提升主动对话的质量,就可以从这两个角度下手。
文章主要方法
文章提出了一个完整的框架PaRT(Proactive social chatbots with personalized real-time ReTrieval),主要通过3个重要模块:用户画像构建、意图引导的查询优化、检索增强生成(RAG),来提升主动对话的质量。
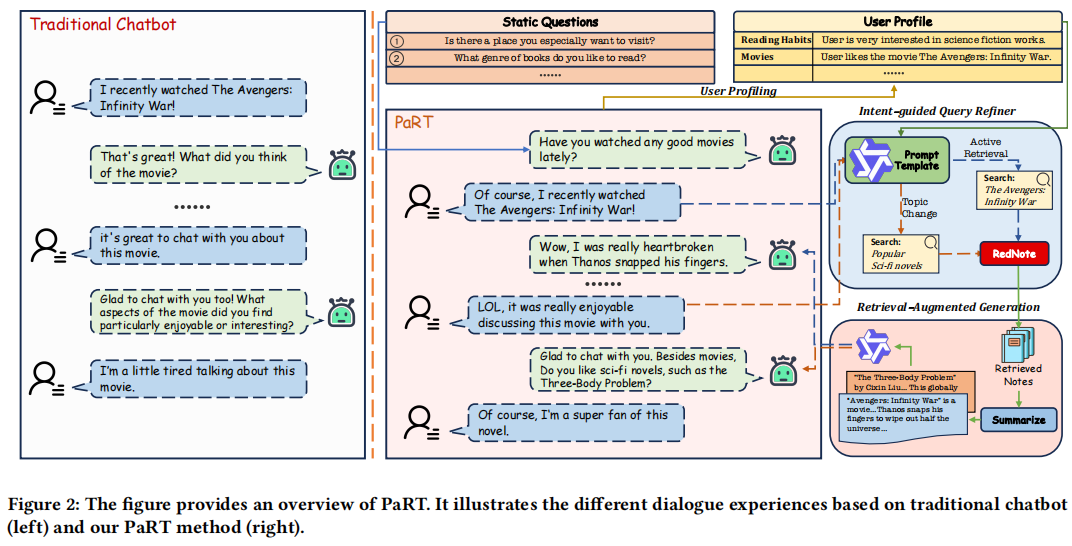
用户画像
用户画像模块里,引入了记忆机制,从对话历史中总结了关键信息,构造用户画像,这里主要记录了用户的偏好,除此以外,作者还构造出一套比较固定的问题库,通过引导用户说出个人偏好,能加速这种偏好信息的收集,例如“什么类型的书你喜欢阅读”等。在这里,有关如何记忆对话中的内容,作者有提到两篇论文,有兴趣可以了解一下。
Memochat: Tuning llms to use memos for consistent long-range open-domain conversation
Memorybank: Enhancing large language models with long-term memory
意图引导的查询优化器
随着对话的进行,有效的聊天机器人应当能够主动满足用户的需求,或者在用户参与度下降时转换话题,此处为了增强对话系统对用户隐含需求的感知能力,专门设计了更为精准的识别模块,以快速感知对话过程用户的意图变化。此处,作者把用户意图分为了3个部分。
自然过渡:指机器人应该维持当前对话并提供陪伴。
显式检索:机器人需要主动进行检索获取最新信息,才能把天聊下去。例如“你对最近上映的《沙丘2》有何看法?”
隐式检索:检测用户是否有兴趣减弱或转移话题的迹象,如果有,则需要生成新的话题个性化话题。
后两种意图是需要进行检索的,而检索质量的提升,作者把调优焦点放在了查询重写(query rewrite)上。借助大模型的优秀的理解和推理能力,充分考虑用户画像、对话上下文、意图,从而改写成对话中最合适的检索query。
在这里有4个比较重要的工作,意图识别、主动检索、兴趣减弱或转移话题、查询重写,这里作者都列举了一些论文,我整理出来供大家参考。
意图识别
-
On Leveraging Large Language Models for Multilingual Intent Discovery
Unified Dialog Model Pre-training for Task-Oriented Dialog Understanding and Generation
A Survey on Intent-aware Recommender Systems
主动检索
-
Active Retrieval Augmented Generation
Retrieval-augmented generation for knowledge-intensive nlp tasks
兴趣减弱或转移话题
-
Topic shift detection for mixed initiative response
TIAGE: A Benchmark for Topic-Shift Aware Dialog Modeling
查询重写
-
A Surprisingly Simple yet Effective Multi-Query Rewriting Method for Conversational Passage Retrieval
Large language model based long-tail query rewriting in taobao search
Few-Shot Generative Conversational Query Rewriting
检索增强生成
在有上面改写query的基础上,便可以开始进行搜索了。
此处的搜索分为两个场景,一个是问候场景,即进入后的第一句话,问候的同时带上一个基于用户画像的个性化话题,避免没有信息难以聊下去,这个话题的来源毫无疑问就是从用户画像里来的,第二个则是意图驱动的检索了。
这里的RAG会分为3步,检索、总结、生成,检索使用的是RedNote搜索引擎,检索后取TOPN,然后总结并过滤一些不相关的信息,最终生成具体回复。
这里的几个关键步骤作者也有给出建议。
RAG框架。
-
Active Retrieval Augmented Generation
Retrieval-augmented generation for knowledge-intensive nlp tasks
Retrieve-Plan-Generation: An Iterative Planning and Answering Framework for Knowledge-Intensive LLM Generation
总结。
-
The Power of Noise: Redefining Retrieval for RAG Systems
Recomp: Improving retrieval augmented lms with compression and selective augmentation.
实验细节
首先是模型的选型,此处所有细模块任务均采用的是Qwen2系列模型,最终的回复生成用的是Qwen2-72B-Instruct,其他的均采用Qwen2-7B-Instruct。
评估指标,主要分为两块,检索模块和最终的回复生成模块,检索模块主要用的就是检索指标Precision@k,即前k个结果里正确的个数,而回复生成的端到端结果则使用的是大模型来评估,分为Personalization、Informativeness、Communication Skills三个模块评分,个性化衡量内容由多适合用户偏好,信息量衡量信息的丰富度,沟通技巧则侧重于和用户的有效互动、连贯性、参与度等因素,每个维度由模型给到0-3分。
最后还进行了AB实验,衡量了在线平均的对话时长,对于这种个性化聊天对话机器人,这个时长指标也没什么毛病,总体提升了21.77%,可以说是效果拔群了。
启发和思考
下面是我自己结合论文内容的拓展分析和思考。
用户画像的构建。
-
首先是构建画像用于对话增强的这个意识,“见人说人话,见鬼说鬼话”,生成符合用户偏好的对话的前提,就是了解用户的偏好,这点不能避免;
其次,是画像内容的来源,作者目前的方案应该还是比较算早期的,后续应该还可以有更多的思路,例如依托小红书,可以以来小红书产品的偏好进行进一步的强化,这个的收益主要是针对冷启动用户,而在冷启动这块,原文应该是没有提及的。
有关通过提问引导用户说出偏好的方案,值得关注。当然,有关这点的触发逻辑,文章里并没有说的很清楚。
第三点是画像从显性到隐性,目前的画像信息是通过自然文本来表征,并在后续使用的也是自然文本来进行,然而自然文本还有些局限性,无论是表征上还是应用上。
意图。早在大模型刚出没多久我就提到了意图识别的重要性(心法利器[82] | chatgpt下query理解是否还有意义)。
-
意图识别的核心是为了分流,给系统一个可控的“分情况讨论”的能力,现在应该叫“路由”吧,思想上真的就是一个东西。
这个意图体系,显然和常见的不同,这里分的是3个,自然过渡、显式检索、隐式检索,是个根据下游的策略区别来区分的,而这个下游的区分,是结合实际业务需求的差异来分析得到的,这块的设计应该是有很多业务上的数据分析积累得到的。
改写。改写这块,其实后台有收到很多有关的问题,但改写这块我写的实在是不多,这篇文章给了我挺好的解释机会。
-
改写是一个非常以终为始的东西,我们得明确一个点——希望改成啥样,才能去做的是,否则就不叫改写,叫复述,然而简单的复述是没办法给搜索质量带来任何收益。
在本文中,改写的目标有两点,一个是让简单的query能带上基础的用户画像,让新的检索query能带有画像信息;另一个是带上意图信息,这里的意图是带有检索策略的,这样的检索,能对后续的回复更有针对性,所以这里的改写,就是有效的。我理解最终的检索效果能提升巨大,这块的改写功不可没。
总结。总结是对检索回来的内容进行总结,对检索内容进行总结。
-
这个我看挺多RAG框架内是比较少的,大家日常这么干的也不是很多,不过在特定时候收益还是有不少的,尤其是检索回来的内容存在很多问题无关的废话(尤其是那种长文档),可能只有很少的一部分有用,进行总结和清洗后更有利于模型最后生成回复。
不过不要指望这个方式用了能药到病除,这里更多是对信息密度低、高冲突(例如不同时间的内容要取新的)的内容,做清洗才可能会有收益,不是说洗了就能提,有的时候甚至洗了反而下降,例如有些重要信息被不小心洗掉了。
可能也是因为每个场景的文档内容差异巨大,清洗的需求也各不相同,所以市面上也比较难找到比较通用的工具或者文章,有的也是过于泛用实际落地并没啥用,这里更多依赖自己的分析,看什么内容更容易影响结果,针对性地处理会更有效率。
最终的评价指标。
-
这种对话机器人的设定下,使用大模型,分几个角度来综合评估的方式,在目前已经挺受认可了,质量还不错,大家可以尝试地用,但值得注意的是,尽量都要分维度,并且不要直接撒手不管,还是得自己多找case来分析验证具体的打分是否合理,有些小场景模型可能对某些问题有偏见。
除了要看端到端结果,还要看一下过程的质量,此处作者关注检索质量提升(改写模块对此贡献显著)(毕竟这里有改写模块,很合理),这里用的是Precision@k指标,也是很合理的,小红书内其实相关的内容本就很多,相关的内容肯定不少,用recall@K,可能是没什么区分度的。另外,也有小问题,这里的意图识别并没有评估,当然了,这个类目体系说实话真不好评估对错,尤其这个隐式检索。
这篇论文总体还是给了我们思路上很大的启发的,上面也列举了很多的,属于给了我们很多思路的,另外也给了我们很多有参考价值的论文,后续有需要我们可以进一步学习。不过确实,很多内容都只是说了个表面,内部的技术细节基本等于没讲,只能说可惜了。
