目录
1、数据库约束
有些时候,对数据库中的数据是有一定要求的,有些数据认为是合法数据,有些是非法数据,靠人工检查是不可行的,所以就有了数据库约束
数据库约束:数据库自动的对数据的合法性进行校验检查的一系列机制。其目的是为了保证数据库中能够避免被插入/修改一些非法的数据
数据库引入约束之后,执行效率就会受到影响,可能会降低很多。例如 unique 约束,会让后续插入数据/修改的数据的时候,都先触发一次查询操作。这意味着,数据库其实是比较慢的系统,也比较吃资源的系统,部署数据库的服务器,很容易成为一整个系统的“性能瓶颈”
MySQL中提供了以下约束:
- not null - 指示某列不能存储 null 值。
- unique - 保证某列的每行必须有唯一的值。
- default - 规定没有给列赋值时的默认值。
- primary key - not null 和 unique 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- foreign key - 保证一个表中的数据匹配另一个表中的值的参照完整性。
- check - 保证列中的值符合指定的条件。对于mysql数据库,对check子句进行分析,但是忽略check子句。
2、NULL约束
-- 创建表时,指定某列不为空
drop table if exists student;
create table student (
id int not null,
sn int,
name varchar(20),
qq_mail varchar(20)
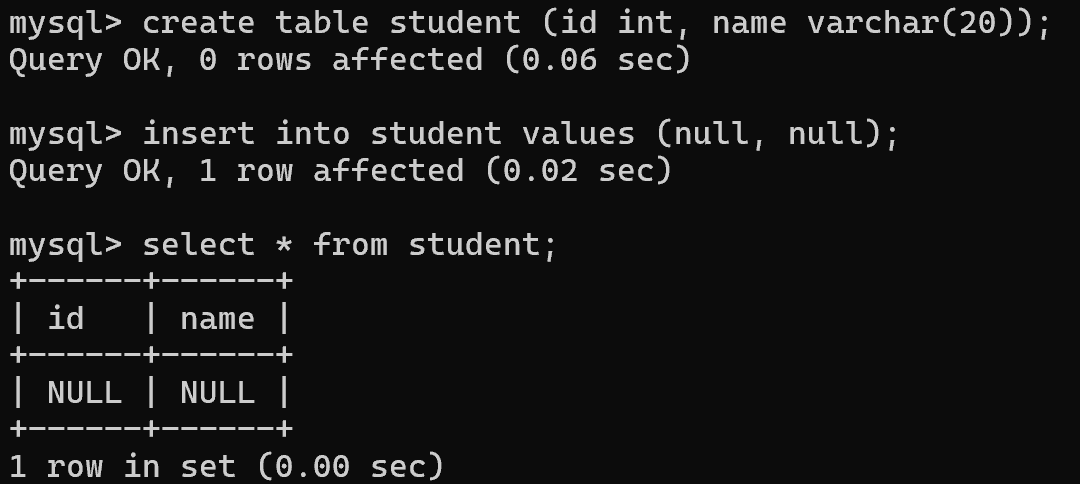
);当没有加null约束时,可以插入null
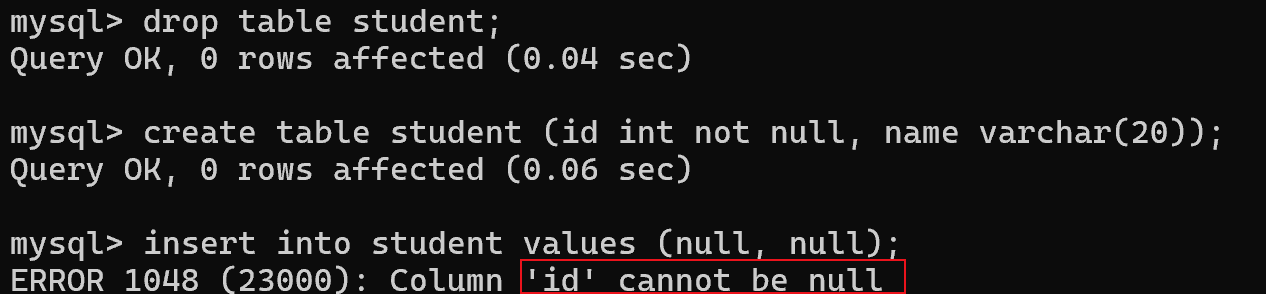
把 id 属性加上 not null 后,就不能插入空值了
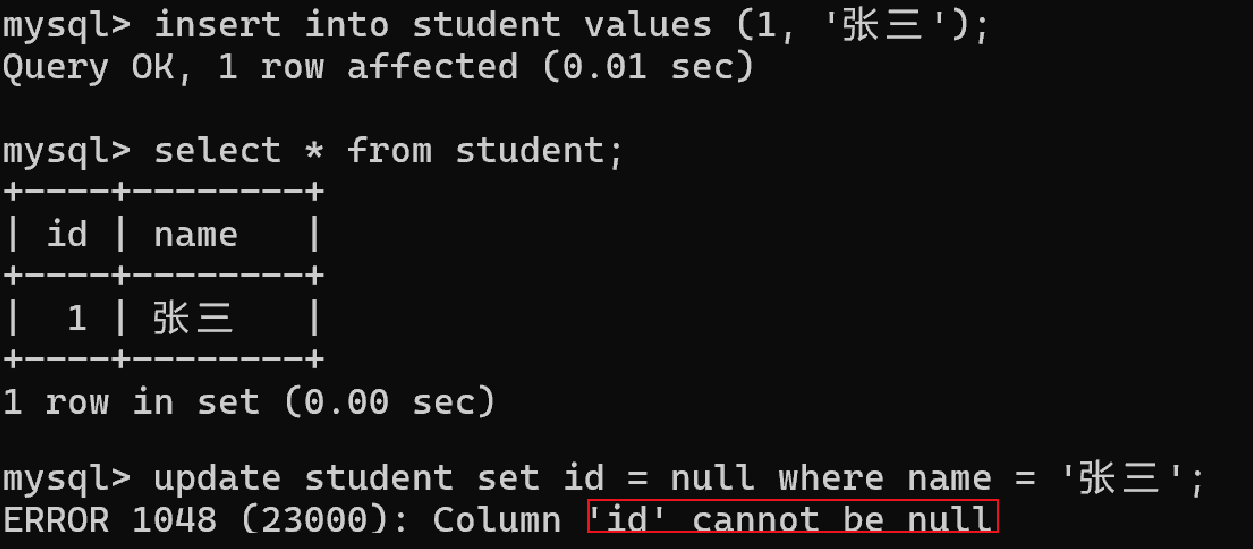
update操作中也不能修改id为空值
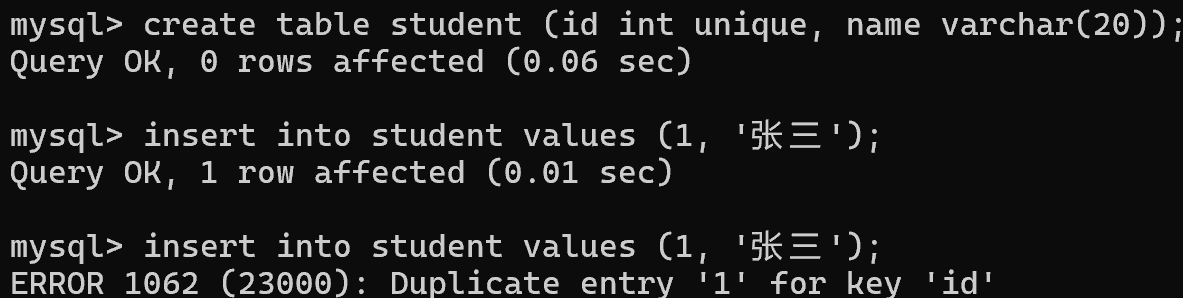
3、UNIQUE:唯一约束
-- 指定sn列为唯一的、不重复的
drop table if exists student;
create table student (
id int not null,
sn int unique,
name varchar(20),
qq_mail varchar(20)
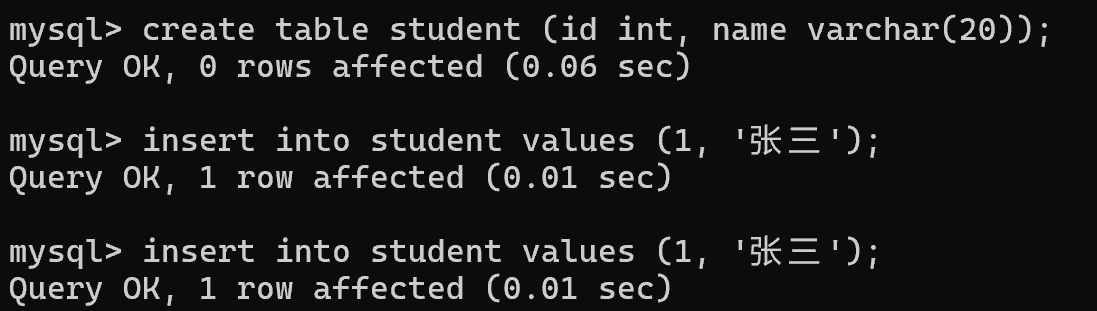
);1. 当没有加unique约束时,可以插入id重复的数据
2. 把 id 属性加上 unique 后,就不能重复插入了
3. unique约束,会让后续插入数据/修改的数据的时候,都先触发一次查询操作,通过这个查询操作,来确定当前这个记录是否已经存在
4. 与 not null 一样,unique 也不仅限制插入,也会限制修改
Duplicate:重复的
entry:入口;条目,账目,记录
Java 中的 entrySet 方法的 entry 就是条目的意思
^
Java 遍历集合类,都是通过迭代器来进行的。对应的集合类,得实现 lterable 接口才能够进行迭代器遍历,而 Map 没有实现 Iterable,于是就提供了entrySet方法:把Map转换成Set,里面的元素就是一个一个的 Entry(条目,包含了 key和 value)
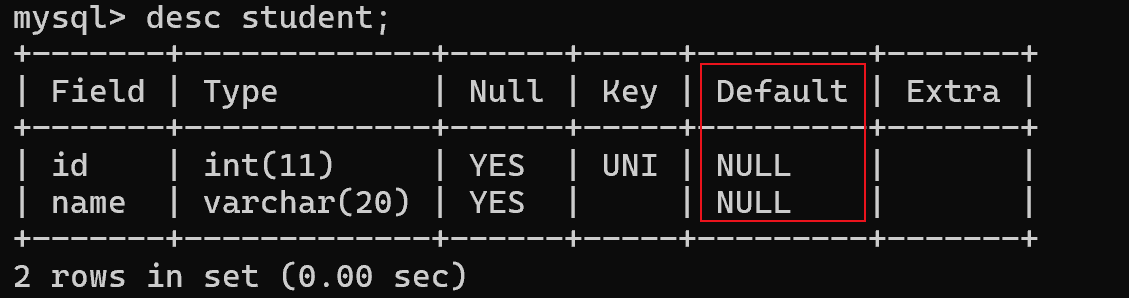
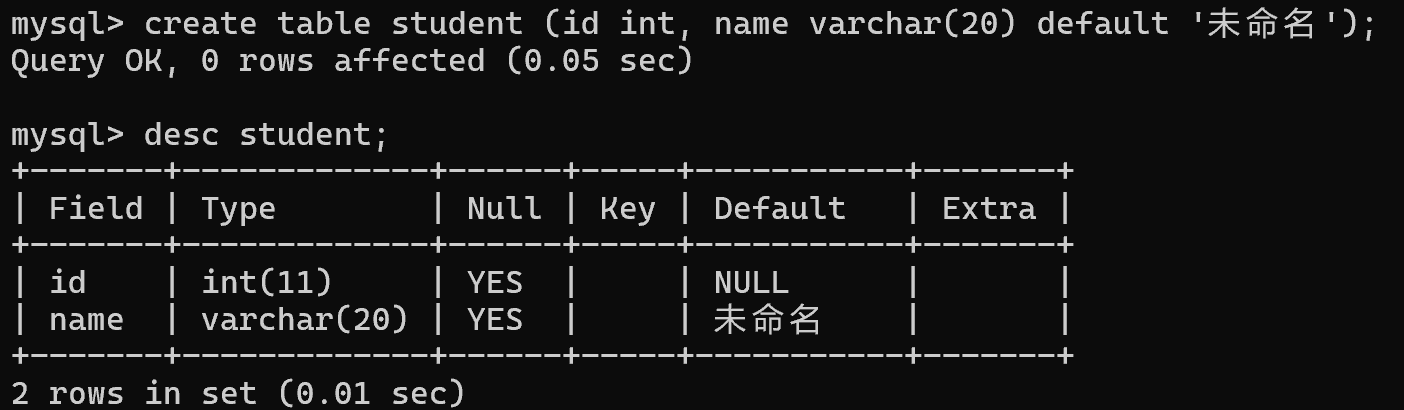
4、DEFAULT:默认值约束
-- 指定插入数据时,name列为空时,默认值unkown
drop table if exists student;
create table student (
id int not null,
sn int unique,
name varchar(20) default 'unkown',
qq_mail varchar(20)
);红框部分表示描述这一列的默认值。默认的默认值,是null。可以通过 default约束,来修改默认值
desc表名; desc=>describe描述
order by 列名 desc; desc=>descend 降序
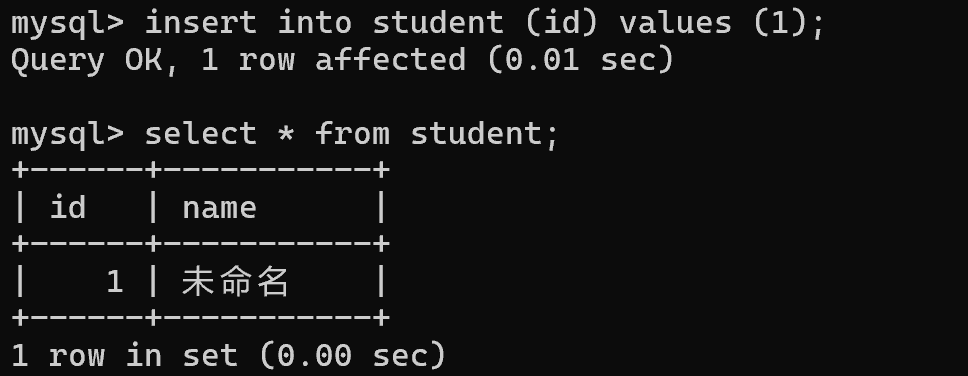
后续插入数据时,default 就会在没有显式指定插入的值的时候生效了
5、PRIMARY KEY:主键约束
-- 重新设置学生表结构
drop table if exists student;
create table student (
id int primary key,
sn int unique,
name varchar(20) default 'unkown',
qq_mail varchar(20)
);1. 一张表里只能有一个primary key(一个表里的记录,只能有一个作为身份标识的数据)
2. 虽然只能有一个主键,但是主键不一定只是一个列,也可以用多个列共同构成一个主键(联合主键)
3. 对于带有主键的表来说,每次插入数据/修改数据,也会涉及到进行先查询的操作
4. mysql 会把带有 unique 和 primary key 的列自动生成索引,从而加快查询速度


如何保证主键唯一?
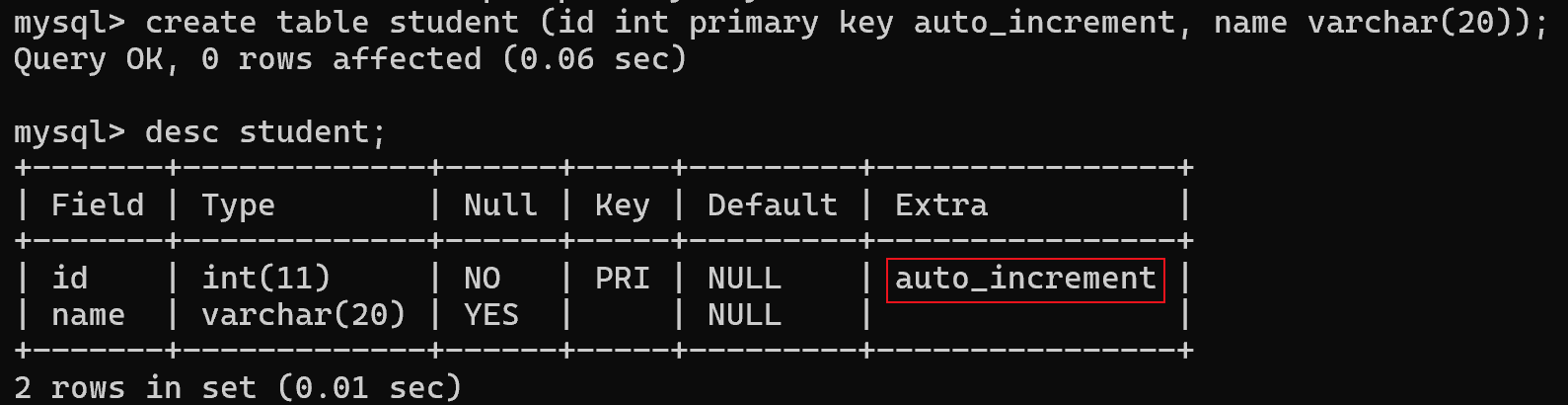
mysql提供了一种“自增主键"(auto_increment)这样机制:主键经常会使用 int / bigint,当插入数据的时候,不必手动指定主键值,由数据库服务器自己给你分配一个主键会从1开始,依次递增的分配主键的值
自增主键的插入操作:
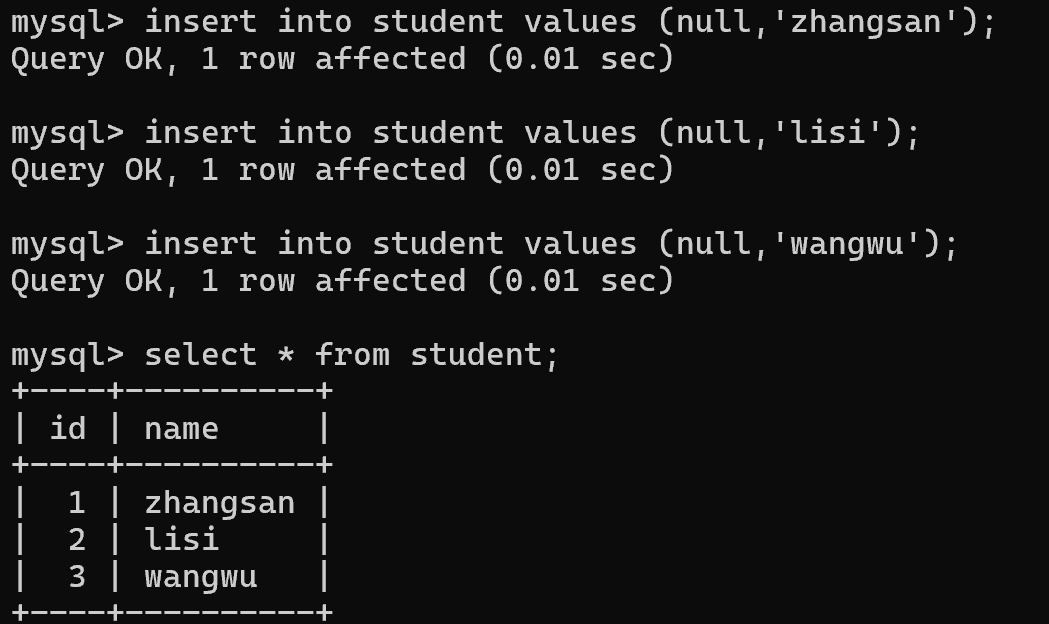
插入时写作 null 其实是交给了数据库服务器,自行分配主键值
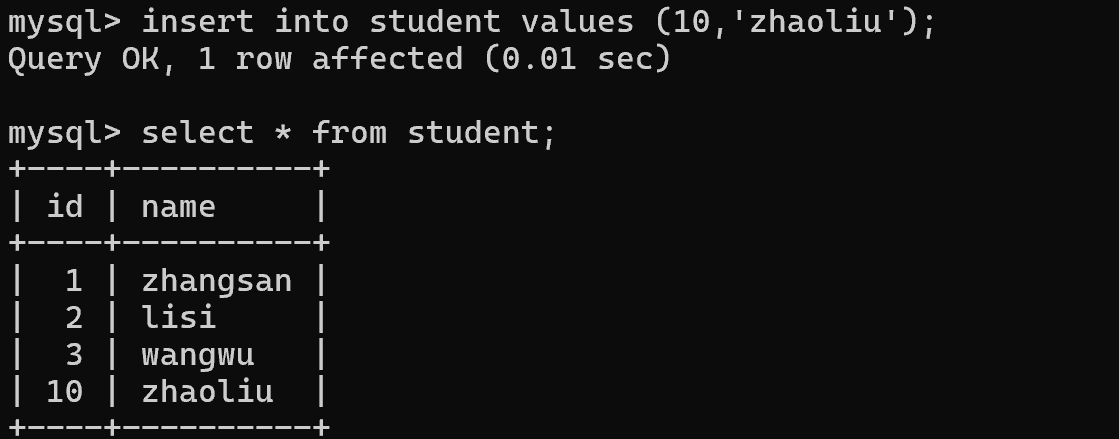
指定主键的值
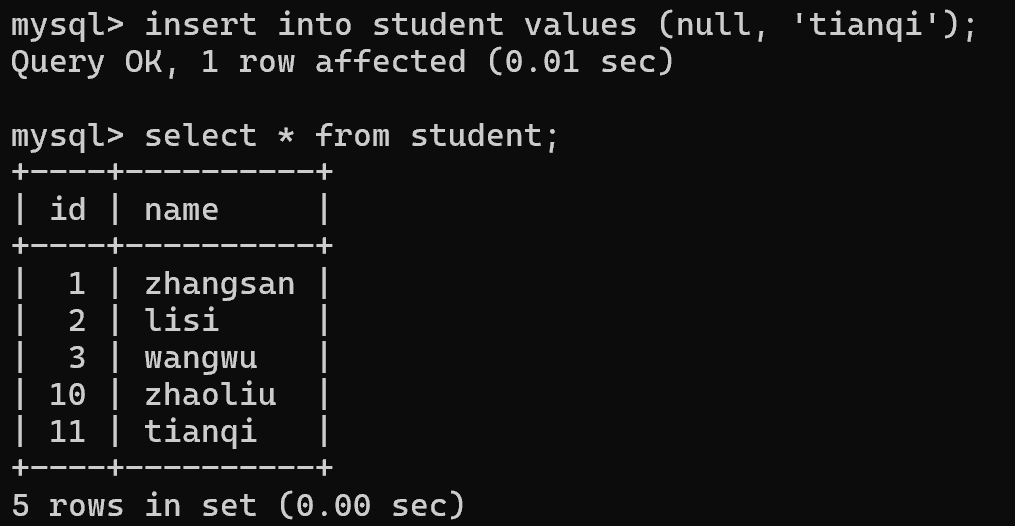
再插入就会从刚才最大的数值开始,继续往后分配
这样,4-9之间的 id 是浪费了,但浪费就浪费,没事。这时可以通过手动插入4-9,但自动分配就分配不到了
总结:自增主键在数据库内部,相当于使用了一个变量,来保存了当前表的 id的最大值,后续分配自增主键都是根据这个最大值来分配的。如果手动指定id,也会更新最大值
这里的 id 的自动分配,也是有一定局限性的。如果是单个mysql 服务器,没问题的。如果是一个分布式系统,有多个mysql服务器构成的集群,这个时候依靠自增主键就不行了
分布式系统:面临的数据量大(大数据),客户端的请求量比较大(高并发),一台主机搞不定就需要多台主机(分布式)
面试题(进阶)
一台服务器主机,硬盘空间肯定是有限的,当存储较大的数据时,可以引入多个数据库服务器的主机,用分库分表的方式存储
例如,淘宝的商品信息。一个新的商品,商品 id 如何分配呢? 如何保证这里的 id 和其他数据库中 id 不重复呢?
如果只有一个主机,那么可以使用自增主键就可以了。这个例子是使用分库分表的方式存储,一般使用下面的方法:
^
分布式系统中生成唯一id的算法:
公式:分布式唯一 id = 时间戳 + 机房编号 / 主机编号 + 随机因子
说明:
1. 如果添加商品的速度比较慢,直接使用时间戳就够了,
2. 但如果一个时间戳之内,添加了多个商品,这些商品,是在不同的主机上的,所以只需要在时间戳的基础上加机房编号 / 主机编号,这样就可以保证同一时间之内,添加到不同主机上的商品的编号,是不同的了
3. 如果在同一个时间戳的同一个主机上,也要添加多个商品。为了防止这种情况,再在之前的基础上加一个随机因子,虽然一定概率生成相同的因子,但是概率非常小
4. 公式中的 + 是指字符串拼接,不是算术相加。拼出来的结果是一个比较长的字符串
5. 如果在同一个ms之内,给同一个主机上添加的多个数据,随机因子恰好相同了,理论上来说,这样的情况是可能存在的。但是程序员做的是工程,做工程的一定会涉及到误差的,只要误差在合理的范围之内,就可以忽略不计
6、FOREIGN KEY:外键约束
例如:
class (classld, name)
student (id, name, classld)
学生表中的 classld 必须在班级表中存在,这个 classld 才是一个合法的id,外键就是用来描述这样的约束的过程的
^
class表中的数据,约束了 student表中的数据
把 class 表,称为“父表",约束别人的表
把 student 表,称为"子表",被别人约束的表
实现外键约束:
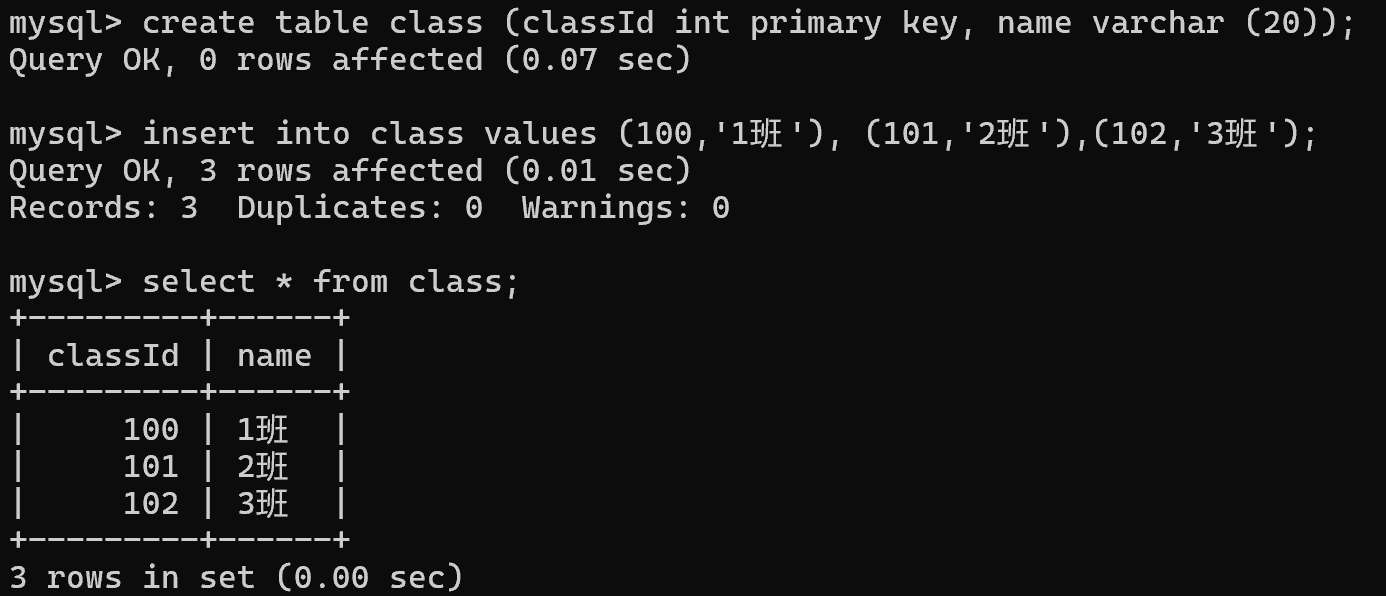
班级表:create table class (classId int primary key, name varchar (20));
学生表:create table student (id int primary key, name varchar(20), classId int, foreign key (classId) references class(classId));
references:在JavaSE中是 引用 的意思,这里表示当前表的这一列中的数据,应该出自于另一个表的哪一列
foreign key (classId):当前表中的classld是被约束的列
references class(classId):数据是被class表的classld这一列约束的
总结:student 的 classld 的数据要出自于 class 表的 classld 这一列的
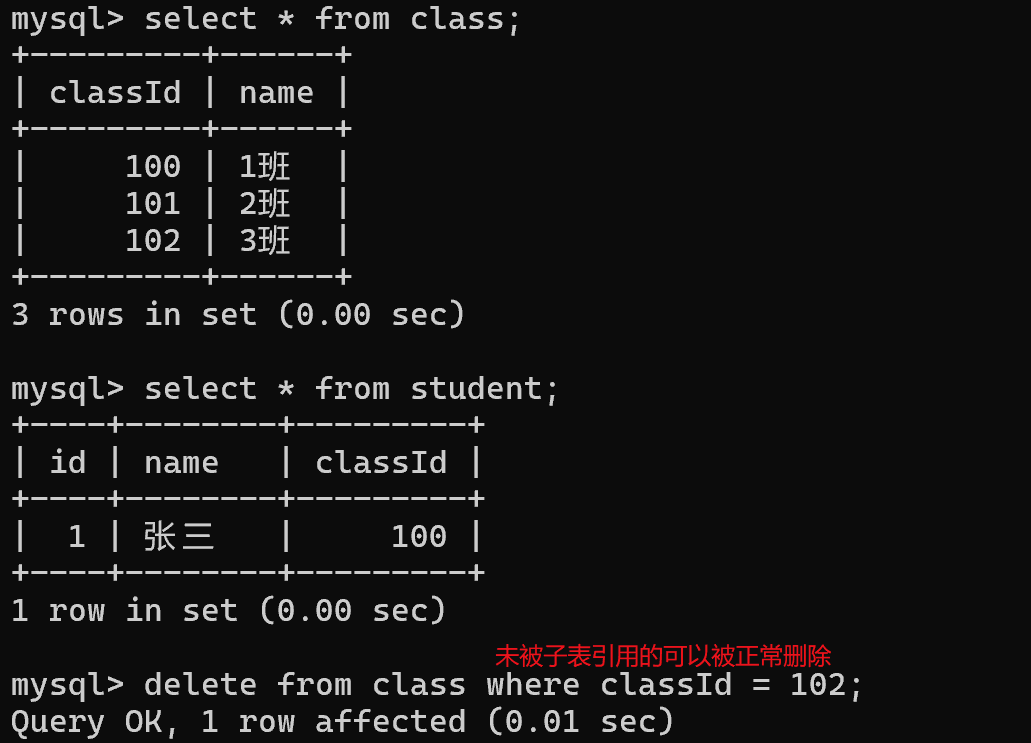
insert into class values (100,'1班'), (101,'2班'),(102,'3班');
insert into student values (1,'张三',100);
1. 当执行这个插入操作时,就会触发针对class表的查询,查询100是否是在class中存在
所以当插入一个在class中不存在的,就会显示如下报错信息
2. 在update操作中同样会受到约束
update student set classId = 200 where id = 1;
3. 针对父表进行修改 / 删除操作,如果当前被修改 / 删除的值,已经被子表引用了,这样的操作也会失败,外键约束始终要保持,子表中的数据在对应的父表的列中存在
4. 外键准确来说,是两个表的列产生关联关系,其他列的修改是不受影响的,比如classId = 100被子表引用了,修改其对应的name不受影响
5. 要想删除父表,必须先删除子表;直接删除父表会报错,因为父表没了,子表后续添加新元素,就没有参考了
6. 指定外键约束的时候,要求父表中被关联的这一列,必须是主键或者unique






案例:
创建班级表classes,id为主键:
-- 创建班级表,有使用mysql关键字作为字段时,需要使用``来标识
drop table if exists classes;
create table classes (
id int primary key auto_increment,
name varchar(20),
`desc` varchar(100)
);创建学生表student,一个学生对应一个班级,一个班级对应多个学生。使用id为主键, classes_id为外键,关联班级表 id
-- 重新设置学生表结构
drop table if exists student;
create table student (
id int primary key auto_increment,
sn int unique,
name varchar(20) default 'unkown',
qq_mail varchar(20),
classes_id int,
foreign key (classes_id) references classes(id)
);电商网站(淘宝等)的场景:
商品表(goodsld, …………);
订单表(orderld, goodsld.... , foreign key(goodsld)references商品表(goodsld));
订单表的 goodsld 的数据要出自于商品表的 goodsld 这一列的
^
当用户买了一个商品,过了一段时间之后,商家想把这个衬衫给下架(删除掉),而尝试删除商品表数据的时候,商品表的数据被订单表引用了,是不能删除的,就报错了。那么电商网站是如何做到,保证外键约束存在的前提下实现 “商品下架” 功能的呢 ?
答:给商品表新增一个单独的列,表示是否在线(不在线,就相当于下架了)
^
商品表(goodsld, name, price...., isOk);
isOk的值为1,表示商品在线值为0,表示商品下线
如果需要下架商品,使用 update 把 isOk 从 1 改为 0 即可。查询商品的时候,都加上 where isOk = 1这样的条件
这种删除方式叫 逻辑删除
电脑中的文件,想删除掉,也是通过逻辑删除的方式实现的。删除后,其实在硬盘上数据还在,只不过被标记成无效了,后续其他文件可以重复利用这块硬盘空间
比如,想把电脑的某个文件彻底删除掉,通过扔进回收站,再清空回收站,这种方式没用。想要让硬盘上的数据彻底消亡,需要一段时间,等后续有文件把这块标记无效的空间重复利用了,才会真正消失
如何才是正确的,彻底删除数据的方式呢? 物理删除(销毁硬盘)
7、CHECK约束(了解)
drop table if exists test_user;
create table test_user (
id int,
name varchar(20),
sex varchar(1),
check (sex ='男' or sex='女')
);