概述
随着机器学习和人工智能技术的飞速发展,高效且安全地存储、共享和部署训练有素的模型的方法变得越来越重要。模型权重文件格式在这个过程中发挥着关键作用。这些格式不仅保存了模型的学习参数,还能够实现可复现性,并且便于在各种不同环境和平台上进行部署。本文将深入探讨行业中最受欢迎的模型权重文件格式,研究它们的起源、结构、用例以及优势。
一、 为何模型权重文件格式至关重要
模型权重格式不仅仅是数据容器。它们:
- 实现工具和框架之间的模型可移植性和互操作性:不同的机器学习框架(如PyTorch、TensorFlow、Keras等)具有各自的特点和优势。模型权重文件格式使得在这些框架之间迁移和共享模型成为可能,极大地促进了技术的交流与发展。
- 保存训练进度,以便进行检查点设置和恢复:在训练大型模型时,可能会耗费大量的时间和计算资源。模型权重文件格式能够保存训练过程中的关键信息,如模型的权重、优化器的状态等,使得在训练中断后可以从中断的地方继续训练,避免了重复训练的麻烦。
- 支持在资源受限的环境中进行部署:在一些应用场景中,如移动设备、嵌入式系统等,计算资源和存储空间可能非常有限。特定的模型权重文件格式可以对模型进行优化,使其在这些资源受限的环境中高效运行,满足实际应用的需求。
- 在共享模型时确保安全性和完整性:当模型需要在不同的用户或组织之间共享时,模型权重文件格式能够保证模型的安全性和完整性,防止模型被篡改或泄露,保护知识产权。
每种格式都是基于特定的目标和权衡设计的,这决定了它们的使用方式和使用位置。
二、 流行模型权重文件格式概述
以下是广泛使用的模型权重格式的总结对比:
| 格式 | 框架 | 主要用例 | 关键特性 |
|---|---|---|---|
.pt / .pth |
PyTorch | 训练和推理 | 灵活、可读性强、框架原生 |
.ckpt |
TensorFlow | 检查点设置和训练恢复 | 鲁棒性强,适合大型模型 |
.h5 |
Keras / TensorFlow | 在一个文件中保存完整模型 | 包括模型、权重和优化器状态 |
.onnx |
跨平台 | 模型互操作性和部署 | 开放标准,硬件优化推理 |
.safetensors |
Hugging Face (PyTorch) | 安全且快速地共享模型 | 苹果原生,针对苹果芯片优化 |
.gguf |
GGML-based (LLaMA.cpp) | 高效的LLM推理 | 量化就绪,CPU/GPU优化 |
.tflite |
TensorFlow Lite | 移动和边缘推理 | 轻量级,硬件加速 |
.engine |
TensorRT | GPU推理优化 | 高性能,精度可调的部署 |
.mlmodel |
Core ML (Apple) | iOS/macOS部署 | 苹果原生,针对苹果芯片优化 |
三、 Pickle在模型权重文件格式中的作用
Python的pickle模块是许多机器学习文件格式的基础,特别是在PyTorch和更广泛的Python生态系统中。尽管它本身不是一种正式的模型格式,但pickle通常是用于序列化和反序列化模型权重和配置的底层机制。
3.1 什么是Pickle?
Pickle是Python的一个标准库,它将Python对象转换为字节流(序列化),并恢复它们(反序列化)。它允许将对象(如模型权重、整个模型或训练历史记录)保存到磁盘上。
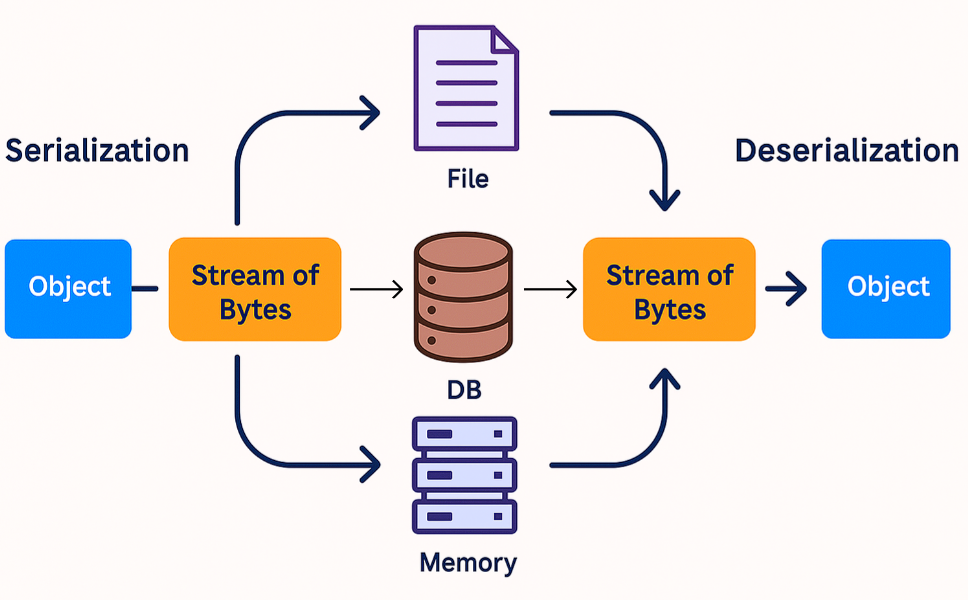
Python中的Pickle序列化和反序列化过程
3.2 Pickle在哪里使用?
- PyTorch:
.pt和.pth格式使用pickle来序列化模型状态字典或整个模型。 - Scikit-learn:模型通常使用
.pkl保存,这是使用pickle.dump()的直接结果。 - XGBoost和LightGBM:尽管它们支持原生格式,但在Python环境中,
pickle有时用于快速保存。
3.3 优点:
- Python原生:对于Python开发者来说,使用起来非常方便,易于上手和集成。
- 灵活:可以存储几乎所有Python对象,包括复杂的模型结构和训练过程中的各种信息。
3.4 缺点:
- 安全风险:从不受信任的来源加载pickle文件可能会执行任意代码,从而带来安全风险。这使得它不适合用于公共共享或面向网络的应用程序,可能会导致数据泄露或恶意代码执行等问题。
- 缺乏互操作性:pickle文件不能轻松地在Python之外或不同框架版本之间加载,限制了其在跨语言和跨框架场景中的应用。
四、 Protocol Buffers在模型权重文件格式中的作用
由Google开发的Protocol Buffers(protobuf)是一种基础编码格式,通常不是开发者直接用来保存或加载模型权重的文件扩展名。它提供了一种紧凑且高效的二进制序列化机制,非常适合表示模型架构和权重等结构化数据。

4.1 Protocol Buffers在哪里使用:
- TensorFlow
.pb文件:这些是使用Protobuf序列化的冻结模型,将架构和训练参数结合起来用于部署。 - ONNX(
.onnx):整个ONNX标准都是基于Protobuf序列化模式构建的。 - Apple Core ML(
.mlmodel):使用自定义模式下的Protobuf来定义模型组件。
4.2 优点:
- 高效性:Protocol Buffers的二进制序列化机制能够生成紧凑的数据格式,占用存储空间小,传输效率高,适合在分布式系统和网络环境中使用。
- 语言无关性:Protocol Buffers支持多种编程语言,包括C++、Java、Python等,使得不同语言编写的程序能够方便地进行数据交换和通信,提高了跨语言开发的便利性。
- 可扩展性:通过定义清晰的数据结构和字段,Protocol Buffers能够方便地对数据进行扩展和修改,适应不断变化的应用需求,而无需对现有的代码进行大规模的改动。
4.3 缺点:
- 学习成本:对于初学者来说,Protocol Buffers的学习曲线相对较陡,需要花费一定的时间来掌握其基本概念、语法和使用方法。
- 依赖性强:在使用Protocol Buffers时,需要依赖特定的编译器和库来生成代码和进行序列化/反序列化操作,这可能会增加项目的复杂性和依赖管理的难度。
五、 模型权重文件格式的详细探讨
5.1 .pt / .pth(PyTorch)
PyTorch的原生模型权重格式是当今研究和行业中使用最广泛的格式之一。由Facebook AI于2016年推出,.pt和.pth格式存储整个模型或仅其状态字典(权重和偏差)。它们依赖于Python的pickle模块进行序列化。

PyTorch的.pt和.pth模型格式
关键特性:
- 高度灵活:便于在研究工作流程中保存和加载模型,支持对模型的各种操作和自定义修改,能够满足不同研究人员和开发者的多样化需求。
- 常与Hugging Face模型一起使用:特别是基于Transformer的架构,在自然语言处理领域得到了广泛的应用,推动了预训练模型的发展和共享。
.pth和.pt在功能上是相同的:命名只是约定俗成,开发者可以根据个人喜好或项目规范进行选择。
注意事项:
- 移植性有限:尽管在PyTorch内广泛支持,但这些格式不能原生移植到其他框架,可能会导致在跨框架使用时出现兼容性问题。
- 基于pickle的加载风险:从不受信任的来源加载pickle文件可能会带来安全风险,尤其是当文件来自不可靠的来源时,可能会导致恶意代码执行或数据泄露等问题。
5.2 .ckpt(TensorFlow)
TensorFlow的检查点格式,以.ckpt表示,允许模型保存训练状态、权重和优化器配置。每个检查点通常包括三个文件:.data、.index和.meta(对于旧版模型)。

TensorFlow检查点格式表示为.ckpt文件
关键特性:
- 允许从上次停止的地方恢复训练:这对于训练大型模型和存储中间结果非常有用,能够有效避免因意外中断而导致的训练进度丢失,节省时间和计算资源。
- 在Google的BERT和T5等模型中广泛使用:这些模型在自然语言处理领域取得了显著的成果,.ckpt格式为其训练和研究提供了有力支持。
注意事项:
- 不适合部署:检查点主要用于训练过程中的保存和恢复,模型通常需要被转换为TensorFlow的SavedModel格式或
.tflite等其他格式,以便在实际应用中进行部署。 - 文件管理复杂:由于检查点包含多个文件,文件管理可能较为复杂,需要确保这些文件的完整性和一致性,否则可能会导致模型无法正确加载或恢复。
- 不包含模型架构:检查点文件仅保存模型的权重和训练状态,而不包含模型的架构信息。因此,在加载模型时,需要提供原始的模型代码来重建模型结构,这可能会给模型的共享和迁移带来一定的不便。
5.3 .h5(HDF5)
被Keras早期采用的.h5(HDF5)格式允许在一个文件中存储整个模型架构、权重和优化器状态。这种格式直观,便于共享和检查模型组件。

Keras风格的.h5模型文件图标
关键特性:
- 用户友好且文档完善:HDF5格式具有良好的文档支持和丰富的社区资源,使得开发者能够方便地学习和使用。其直观的文件结构也便于对模型进行检查和修改,有助于模型的调试和优化。
- 适用于小型到中型模型:对于规模适中的模型,.h5格式能够提供较好的性能和存储效率,满足大多数常见应用场景的需求。
注意事项:
- 逐渐被TensorFlow的SavedModel格式取代:随着TensorFlow的发展,SavedModel格式逐渐成为主流,它提供了更强大的功能和更好的兼容性,能够更好地满足模型的保存、共享和部署需求。
- 对于大型模型或复杂序列化需求效率不高:在处理大型模型或具有复杂结构的模型时,.h5格式可能会出现性能瓶颈,存储效率和加载速度相对较慢,影响模型的使用体验。
5.4.onnx(Open Neural Network Exchange)
ONNX是一种由Microsoft和Facebook联合开发的开源格式。它允许在一个框架中训练的模型(如PyTorch)在另一个框架中运行(如TensorFlow或ONNX Runtime),从而促进跨平台兼容性。
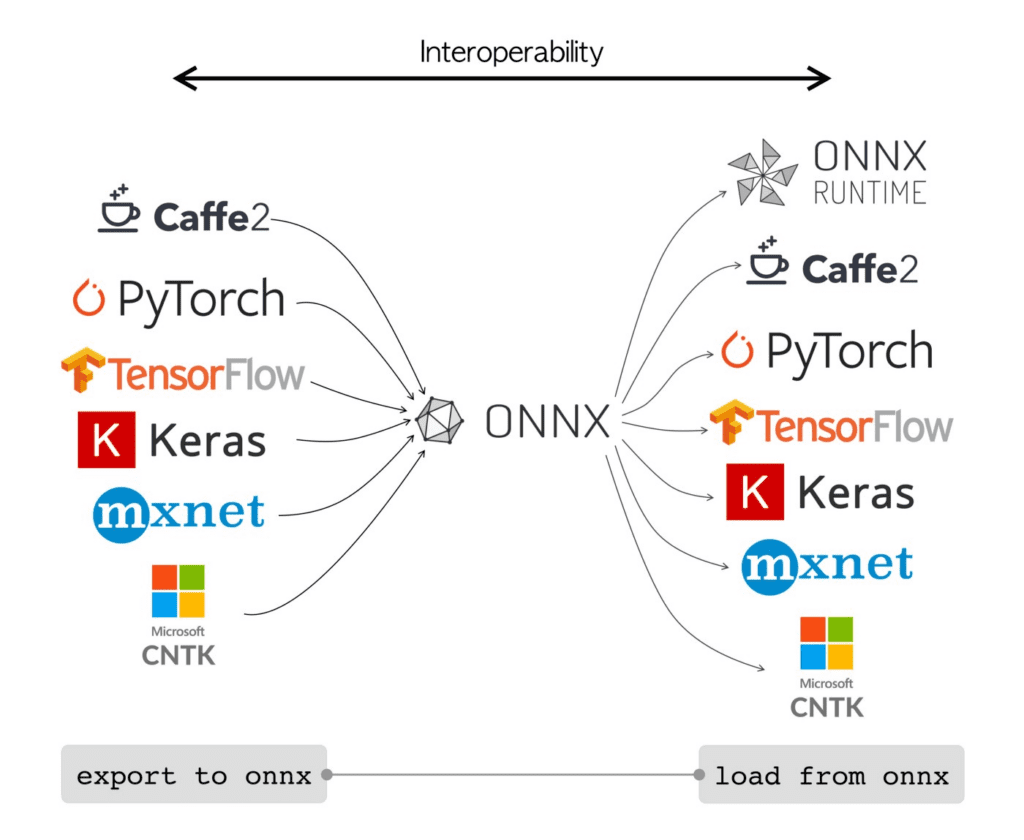
ONNX格式实现跨框架模型互操作性
关键特性:
- 开放标准:ONNX作为一种开放的模型格式标准,得到了众多框架和工具的支持,为模型的跨框架共享和部署提供了坚实的基础。
- 硬件优化推理:ONNX Runtime能够针对不同的硬件平台进行优化,提高模型的推理性能,使得模型能够在各种设备上高效运行,满足实际应用中的性能要求。
注意事项:
- 自定义层和操作的兼容性问题:如果模型中包含自定义层或特殊操作,可能需要进行ONNX兼容的重写或扩展,这可能会增加模型转换的复杂性和工作量。
- 转换工具的限制:虽然ONNX提供了丰富的转换工具,但在某些情况下,这些工具可能无法完全准确地转换模型,需要开发者进行手动调整和优化,以确保模型的正确性和性能。
5.5 .safetensors
由Hugging Face创建的.safetensors解决了基于pickle的格式(如.pt)的安全风险。它是一种二进制格式,针对安全且快速的张量存储进行了优化,尤其适用于公开共享模型。
安全高效的张量存储
关键特性:
- 零拷贝加载:启用零拷贝加载技术,显著减少模型加载时间,提高模型的加载效率,使得模型能够更快地投入使用。
- 消除代码执行风险:在反序列化过程中不会执行任何代码,从而消除了基于pickle格式可能带来的代码执行风险,提高了模型共享和加载的安全性。
- 成为Hugging Face的Transformers库的默认格式:随着Hugging Face在自然语言处理领域的广泛应用,.safetensors格式得到了越来越多的开发者和研究者的认可和使用,成为了一种重要的模型权重文件格式。
注意事项:
- 仅存储张量:.safetensors格式仅存储模型的张量数据,而不包含模型的架构信息。因此,在加载模型时,需要提供模型的架构代码,这可能会给模型的共享和使用带来一定的不便。
- 对于完整模型序列化不够灵活:虽然在安全性和效率方面表现出色,但在对模型进行完整序列化时,.safetensors格式的灵活性相对较低,可能无法满足一些复杂的模型序列化需求。
5.6 .gguf(GGML Unified Format)
.gguf是为高效推理大型语言模型(LLMs)而设计的,它是llama.cpp生态系统的一部分。它将权重、分词器和元数据整合到一个单一的量化友好文件中。

gguf文件的内部结构[[来源
关键特性:
- 支持多种量化级别:提供Q4、Q5等多种量化级别,能够根据实际需求对模型进行量化,有效减少模型的内存占用和计算需求,提高模型在资源受限环境下的运行效率。
- 适合在资源受限的环境中部署:在CPU/GPU等计算资源有限的设备上,.gguf格式能够充分发挥其优势,使得大型语言模型能够在这些设备上高效运行,为边缘计算和移动设备等应用场景提供了有力支持。
- 在开源LLM社区中广泛使用:得到了Mistral、LLaMA等开源大型语言模型项目的广泛采用,推动了开源LLM社区的发展和繁荣。
注意事项:
- 专为
llama.cpp和类似推理引擎设计:.gguf格式主要针对llama.cpp等特定的推理引擎进行优化,对于其他类型的模型或框架,可能无法充分发挥其优势,适用范围相对较窄。 - 不适合训练:该格式主要用于模型的推理阶段,不支持模型的训练过程,因此在模型开发和训练阶段需要使用其他格式进行保存和加载。
5.7.tflite(TensorFlow Lite)
.tflite是Google开发的一种FlatBuffer格式,用于优化TensorFlow模型以在边缘和移动设备上运行。它提供了一种高度压缩的模型结构,非常适合在设备上进行推理。

TensorFlow Lite的.tflite文件格式
关键特性:
- 低延迟执行:.tflite格式能够提供低延迟的执行性能,并且支持硬件加速(如NNAPI、GPU、Edge TPU等),使得模型能够在移动设备和嵌入式系统上快速运行,满足实时性要求较高的应用场景。
- 适用于Android和嵌入式系统:针对Android操作系统和嵌入式设备进行了优化,提供了良好的兼容性和支持,使得开发者能够方便地将TensorFlow模型部署到这些平台上。
- 支持后训练量化:通过后训练量化技术,可以在不显著影响模型精度的前提下,进一步减小模型的大小,提高模型的运行效率,降低对设备硬件资源的需求。
注意事项:
- 并非所有TensorFlow操作都受支持:由于.tflite格式对模型进行了优化和转换,部分TensorFlow操作可能无法直接在.tflite模型中使用,需要对模型进行简化或转换,这可能会增加模型部署的复杂性。
- 调试和检查困难:由于.tflite文件采用了紧凑的二进制结构,对模型的调试和检查相对困难,开发者可能需要借助专门的工具或方法来进行模型的调试和优化。
5.8.engine(TensorRT)
TensorRT是NVIDIA的高性能深度学习推理库,.engine是其优化的运行时格式。模型通常从.onnx或.pb等格式导出,然后编译成.engine文件,以在NVIDIA GPU上实现超快速推理。
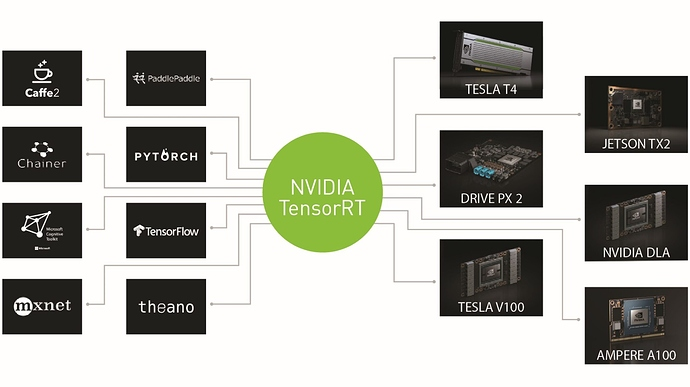
TensorRT的.engine工作流程
关键特性:
- 高性能:TensorRT能够将预训练模型转换为高度优化的执行图,充分发挥NVIDIA GPU的计算能力,显著提高模型的推理速度和性能,满足高吞吐量和低延迟的应用需求。
- 支持多种精度模式:提供FP32、FP16和INT8等多种精度模式,开发者可以根据实际需求选择合适的精度模式,在性能和精度之间进行权衡,以达到最佳的推理效果。
- 适合生产部署:专为生产环境中的GPU加速部署而设计,能够有效提高模型的稳定性和可靠性,降低推理延迟,提高系统的整体性能和效率。
常见用例:
- 实时目标检测:在Jetson设备等边缘计算平台上,利用TensorRT的高性能推理能力,可以实现对实时视频流的快速目标检测和识别,满足安防监控、智能交通等领域的实时性要求。
- 云环境中的高吞吐量AI推理:在具有GPU的云环境中,TensorRT能够充分发挥GPU的并行计算优势,实现高吞吐量的AI推理服务,满足大规模数据处理和实时响应的需求。
- 机器人技术、汽车AI和其他对延迟敏感的任务:在这些对延迟要求极高的应用场景中,TensorRT的低延迟推理能力能够为系统提供快速的决策支持,提高系统的响应速度和效率。
注意事项:
- 硬件和版本依赖性:.engine文件是针对特定的GPU架构和TensorRT版本生成的,具有较强的硬件和版本依赖性。如果在不同的GPU架构或TensorRT版本上使用,需要重新生成相应的.engine文件,这可能会增加模型部署的复杂性和工作量。
- 仅适用于训练后的部署:TensorRT主要用于模型的推理阶段,不支持模型的训练过程。因此,在模型开发和训练阶段需要使用其他框架和工具进行训练,然后将训练好的模型转换为TensorRT支持的格式进行部署。
5.8.mlmodel(Core ML)
Apple的.mlmodel格式是为在Apple生态系统内部署ML模型而设计的,包括iOS、macOS和watchOS。它允许使用Xcode和Swift无缝集成到应用程序中。
Apple Core ML的.mlmodel格式
关键特性:
- 苹果原生支持:作为Apple生态系统的一部分,.mlmodel格式得到了苹果公司的原生支持,能够与iOS、macOS和watchOS等平台无缝集成,为开发者提供了一种便捷、高效的方式来将机器学习模型集成到苹果设备的应用程序中。
- 针对Apple Silicon性能优化:针对苹果的M1芯片等Apple Silicon进行了专门的性能优化,能够充分发挥苹果设备的硬件性能,提高模型的推理速度和效率,为用户提供更好的使用体验。
- 与Core ML工具兼容:与Core ML工具(如coremltools)紧密集成,提供了丰富的模型转换、验证和优化功能,使得开发者能够方便地将不同框架训练好的模型转换为.mlmodel格式,并进行进一步的优化和调试。
注意事项:
- 仅限于Apple平台:.mlmodel格式是专门为苹果生态系统设计的,仅适用于iOS、macOS和watchOS等苹果平台,无法在其他操作系统或平台上使用,限制了其应用范围。
- 需要使用转换工具进行模型准备:虽然Core ML工具提供了强大的模型转换功能,但在将模型转换为.mlmodel格式之前,可能需要对模型进行一定的预处理和优化,以确保模型能够在苹果设备上正确运行,这可能会增加模型部署的复杂性。
六、 选择正确的格式
您选择的模型权重文件格式应取决于:
- 框架和训练流程:不同的机器学习框架具有各自的特点和优势,选择与框架兼容的权重文件格式能够确保模型的正确保存和加载,提高开发效率。例如,如果您使用PyTorch进行模型训练,则可以选择
.pt或.pth格式;而如果您使用TensorFlow,则可以选择.ckpt或.h5格式。 - 目标部署平台:根据模型的部署目标平台(如移动设备、边缘计算设备、服务器等),选择适合该平台的权重文件格式。例如,对于移动设备和边缘计算设备,可以选择
.tflite或.engine等轻量级格式;而对于服务器端的部署,则可以选择.onnx或.pb等格式。 - 安全性和可移植性要求:如果模型需要在不同的用户或组织之间共享,或者需要在不同的框架之间迁移,则需要考虑权重文件格式的安全性和可移植性。例如,.safetensors格式能够提供较高的安全性,而ONNX格式则具有良好的跨框架兼容性。
- 性能限制:根据模型的性能要求(如推理速度、内存占用等),选择能够满足性能需求的权重文件格式。例如,对于对推理速度要求较高的应用场景,可以选择TensorRT的
.engine格式或针对特定硬件优化的格式(如.mlmodel格式针对Apple Silicon的优化)。
以下是一些常见场景的推荐格式:
| 场景 | 推荐格式 |
|---|---|
| 使用PyTorch进行训练 | .pt / .safetensors |
| TensorFlow模型检查点 | .ckpt |
| 在Keras中共享模型 | .h5 |
| 跨框架部署 | .onnx |
| 边缘推理(Android) | .tflite |
| 通过Hugging Face安全共享 | .safetensors |
| 在CPU/GPU上进行量化的LLMs | .gguf |
| GPU加速部署 | .engine |
| iOS/macOS应用 | .mlmodel |
结论
了解模型权重文件格式对于高效地进行模型训练、共享和部署至关重要。每种格式都针对特定的用例和环境进行了优化,具有各自的优势和局限性。在实际应用中,开发者需要根据项目的具体需求和目标,综合考虑框架兼容性、目标部署平台、安全性和性能等因素,选择最适合的模型权重文件格式。只有选择正确的格式,才能确保模型在训练、共享和部署过程中的高效性、可移植性和安全性,充分发挥模型的价值,推动机器学习和人工智能技术在各个领域的广泛应用。