目录
7.2 注意力机制(Attention Mechanisms)

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 神经网络架构
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
一、引言:神经网络的演进脉络
深度学习的发展历程中,神经网络架构从基础的线性模型逐步演变为复杂的混合系统。本文将系统解析13大核心模型架构,涵盖基础原理、专项任务、生成模型、现代架构及前沿扩展,并结合大模型案例说明其混合应用,帮助读者构建完整的技术认知图谱。
二、基础架构:深度学习的基石
2.1 人工神经网络(ANN)
- 核心原理:由输入层、隐藏层、输出层组成的层级结构,通过权重矩阵和激活函数实现非线性映射。
- 代表模型:感知器(单层)、多层感知器(MLP,多层全连接)。
- 优劣点:
- 优点:结构简单,适合线性可分问题(如二分类)。
- 缺点:无法捕捉复杂特征交互,泛化能力有限。
- 应用场景:早期手写数字识别(如MNIST)、简单逻辑回归。
2.2 深度神经网络(DNN)
- 核心原理:ANN的深层扩展(≥3隐藏层),通过堆叠非线性层学习数据的分层特征。
- 代表模型:AlexNet(2012 ImageNet冠军)、ResNet(残差连接解决梯度消失)。
- 优劣点:
- 优点:适合高维数据(如图像、语音),可提取深层语义特征。
- 缺点:参数量庞大(如ResNet-152含6000万参数),需大量标注数据。
- 应用场景:图像分类(如ResNet)、语音识别(如DeepSpeech)。
三、专项任务架构:领域定制化突破
3.1 卷积神经网络(CNN)
- 核心原理:通过卷积层(局部感知)、池化层(降维)和全连接层提取空间特征,权值共享减少参数。
- 代表模型:
- 经典:LeNet-5(手写识别)、YOLO(实时目标检测)。
- 创新:ViT(Vision Transformer,纯Transformer图像分类)。
- 优劣点:
- 优点:平移不变性,计算效率高,适合图像/视频任务。
- 缺点:对文本等非网格数据处理能力弱。
- 应用场景:医学影像分析(如肿瘤检测)、卫星遥感图像解译。
3.2 循环神经网络(RNN)
- 核心原理:通过循环连接(隐藏层自反馈)捕捉序列时序依赖,处理动态数据(如文本、语音)。
- 代表模型:
- 基础:Vanilla RNN(易梯度消失)。
- 改进:LSTM(门控机制)、GRU(轻量化门控)。
- 优劣点:
- 优点:天然适合序列建模,LSTM可处理长距离依赖(如2000字文本)。
- 缺点:串行计算导致训练低效,长序列下仍有信息丢失。
- 应用场景:机器翻译(如Seq2Seq)、股票价格预测。
3.3 图神经网络(GNN)
- 核心原理:针对图结构数据(节点+边),通过消息传递机制(如聚合邻居特征)更新节点表示。
- 代表模型:
- GCN(图卷积,社交网络分析)。
- GAT(图注意力,动态权重调整)。
- GraphSAGE(归纳学习,处理动态图)。
- 优劣点:
- 优点:擅长捕捉节点关系(如社交影响力、分子键),支持异构图。
- 缺点:计算复杂度高(O(N²)),大规模图需采样优化。
- 应用场景:推荐系统(如抖音兴趣网络)、药物研发(分子活性预测)。
四、生成模型:从数据到创造
4.1 生成对抗网络(GAN)
- 核心原理:生成器(G)与判别器(D)对抗博弈:G生成逼真样本,D区分真伪,最终逼近数据分布。
- 代表模型:
- 图像生成:StyleGAN(高清人脸,1024x1024分辨率)。
- 跨域转换:CycleGAN(马→斑马,无需成对数据)。
- 优劣点:
- 优点:生成样本视觉逼真,支持风格迁移、数据增强。
- 缺点:训练不稳定(模式崩溃),需精心设计损失函数。
- 应用场景:虚拟人驱动(如Meta Avatars)、影视特效(如DeepFake)。
4.2 变分自编码器(VAE)
- 核心原理:编码器将输入映射到潜在空间(概率分布),解码器从分布中采样重构数据,实现生成与压缩。
- 代表模型:
- Beta-VAE(平衡多样性与重构精度)。
- VQ-VAE(向量量化,提升生成图像清晰度)。
- 优劣点:
- 优点:支持无监督学习,生成样本多样性高,可用于异常检测。
- 缺点:生成图像分辨率低于GAN(通常≤256x256)。
- 应用场景:3D模型生成(如DreamFusion)、医学图像合成(稀有病例模拟)。
4.3 扩散模型(Diffusion Models)
- 核心原理:正向扩散(逐步加噪)→ 逆向去噪(逐步还原),通过U-Net等网络学习噪声分布。
- 代表模型:
- DDPM(基础扩散,生成512x512图像)。
- Stable Diffusion(潜在扩散,结合Transformer实现文本引导)。
- 优劣点:
- 优点:训练稳定,生成样本多样性优于GAN,支持多模态(文本+图像)。
- 缺点:生成速度慢(需50-500步迭代),计算成本高。
- 应用场景:艺术创作(如MidJourney)、工业设计(产品原型生成)。
五、现代架构:大模型的核心引擎
5.1 Transformer
- 核心原理:自注意力机制替代循环/卷积,并行计算序列全局依赖,支持长文本(如128k token)。
- 代表模型:
- 双向编码:BERT(NLP预训练,如中文问答)。
- 自回归生成:GPT-4(文本生成,代码编写)。
- 多模态:CLIP(图文对齐,零样本分类)。
- 优劣点:
- 优点:长距离依赖建模强,计算效率高(并行性),支持迁移学习。
- 缺点:内存占用大(如GPT-4推理需数百GB显存),硬件门槛高。
- 应用场景:大语言模型(如ChatGPT)、多模态生成(如DALL·E)。
5.2 混合专家模型(MoE)
- 核心原理:将模型参数划分为多个专家网络,动态路由输入至相关专家,实现“大模型+低计算”。
- 代表模型:
- Switch Transformer(1.6万亿参数,稀疏激活)。
- DeepSeekMoE(国内开源,支持128k上下文,激活参数减少91%)。
- 优劣点:
- 优点:相同计算成本下提升模型容量,适合垂直领域多任务(如金融+医疗)。
- 缺点:路由算法复杂,需平衡专家负载均衡。
- 应用场景:长文本推理(如法律文书分析)、多语言实时翻译。
六、强化学习与决策模型
6.1 深度强化学习(DRL)
- 核心原理:结合深度学习(近似值函数/策略)与强化学习(奖励驱动优化),解决复杂决策问题。
- 代表模型:
- 价值基:DQN(Atari游戏,如打砖块)。
- 策略基:PPO(机器人控制,如四足行走)。
- 异步框架:A3C(多线程加速,降低方差)。
- 优劣点:
- 优点:无需规则,自主学习策略,适合高维状态空间(如自动驾驶)。
- 缺点:训练需大量试错,样本效率低(如AlphaGo需数百万局对弈)。
- 应用场景:游戏AI(如AlphaStar)、智能电网调度。
七、前沿扩展:突破传统边界
7.1 胶囊网络(Capsule Network)
- 核心原理:用向量“胶囊”表示特征的存在性与姿态(如旋转、缩放),动态路由机制替代池化。
- 代表模型:CapsNet(MNIST识别,抗旋转能力提升)。
- 优劣点:
- 优点:保留空间层次信息,适合3D物体识别(如医学器官定位)。
- 缺点:计算复杂度高,训练难度大,尚未大规模应用。
- 应用场景:工业质检(零件姿态检测)、虚拟现实(3D场景理解)。
7.2 注意力机制(Attention Mechanisms)
- 核心原理:显式计算输入序列的关键权重,聚焦重要信息(如“代词-名词”关联)。
- 代表模型:
- 通道注意力:SE-Net(挤压-激励,提升ResNet分类精度)。
- 空间注意力:CBAM(卷积块注意力,增强目标检测定位)。
- 优劣点:
- 优点:轻量化设计(增加<5%参数),可嵌入CNN/Transformer。
- 缺点:过度注意力可能引入噪声,需超参数调优。
- 应用场景:图像分类(如ImageNet)、视频动作识别(如SlowFast Networks)。
八、混合创新:大模型的架构融合实践
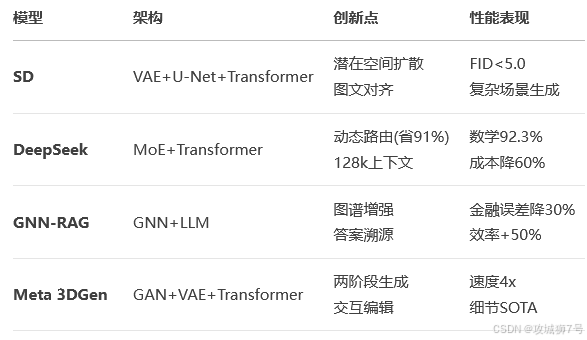
九、未来趋势:从单一架构到生态融合
(1)多模态大一统:如GPT-4o整合视觉Transformer与语言Decoder,实现图文联合生成。
(2)高效化路径:MoE与扩散模型结合(如MoE-Diffusion),通过专家分工加速去噪。
(3)生物启发架构:胶囊网络与神经科学结合,模拟大脑皮层的层次化特征处理。
(4)边缘端部署:轻量化Transformer(如MobileBERT)与注意力蒸馏,推动AI在手机、IoT设备的应用。
十、总结:架构选择的三维法则
(1)任务维度:
- 图像分类 → CNN(如ResNet)或ViT;
- 文本生成 → Transformer(如GPT);
- 图数据 → GNN(如GCN)。
(2)数据维度:
- 小规模 → 浅层网络(如MLP、简单CNN);
- 大规模 → 深层架构(如ResNet、GPT)或MoE(参数高效)。
(3)资源维度:
- 低算力 → 轻量化模型(如MobileNet、DistilBERT);
- 高算力 → 扩散模型、MoE大模型。
深度学习的魅力在于架构的不断迭代与融合,从早期的单一模型到如今的混合系统,每一次创新都推动着AI向通用智能迈进。理解这些架构的核心逻辑与适用场景,是驾驭深度学习技术的关键。未来,跨领域的架构融合(如GNN+扩散模型、胶囊网络+Transformer)将成为突破复杂任务瓶颈的核心路径。
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!