一、数据湖的起源与演进
数据湖(Data Lake)概念的诞生标志着大数据管理范式的重大转变。2010年Pentaho公司CTO James Dixon首次提出该术语,旨在解决传统数据仓库面临的三大痛点: 结构化数据主导的局限性、 Schema-on-Write的僵化设计以及 高昂的存储处理成本。
随着AWS S3、Azure Data Lake Storage等云存储服务的普及,数据湖在2015年后进入快速发展期。其核心价值在于支持 原始数据原生存储(Raw Data at Scale),允许企业存储结构化、半结构化(JSON/XML)、非结构化(图片/视频)等全量数据,典型案例如Netflix每日PB级的视频元数据存储。

二、数据湖与数据仓库的本质差异
|
维度
|
数据仓库
|
数据湖
|
|
数据存储
|
高度结构化
|
原始多类型数据
|
|
Schema处理
|
写入时定义(Schema-on-Write)
|
读取时定义(Schema-on-Read)
|
|
存储成本
|
高(需预处理)
|
低(原生存储)
|
|
适用场景
|
标准化报表/BI分析
|
数据探索/机器学习
|
|
处理延迟
|
批量处理(T+1)
|
支持实时流处理
|
典型应用对比:
- 电商用户行为分析:数据仓库处理订单交易(结构化),数据湖存储点击流日志(半结构化)
- 医疗影像管理:数据仓库存储患者基本信息,数据湖管理CT/MRI原始影像文件
三、数据湖架构的三次革命
1. Hadoop时代(2010-2015)
- 核心组件:HDFS+YARN+Hive
- 架构特点:批处理主导,MapReduce计算模型
- 局限性:运维复杂,缺乏ACID事务支持
2. 云原生阶段(2015-2020)
- 技术突破:对象存储(S3/OSS)+Serverless计算
- 代表方案:AWS Lake Formation架构
- 核心优势:存储计算分离,弹性扩展
3. 湖仓一体化(2020至今)
- 创新技术:Delta Lake/Hudi/Iceberg事务层
- 核心能力:支持UPSERT/Time Travel
- 典型案例:Uber用Hudi管理实时司机轨迹数据
4. 智能湖仓(Emerging)
- AI融合:Databricks MLflow+Delta Engine
- 自动优化:基于机器学习的存储分层策略
- 实践案例:特斯拉自动驾驶数据湖实现模型训练闭环
四、主流技术实现方案
数据湖应具备的能力
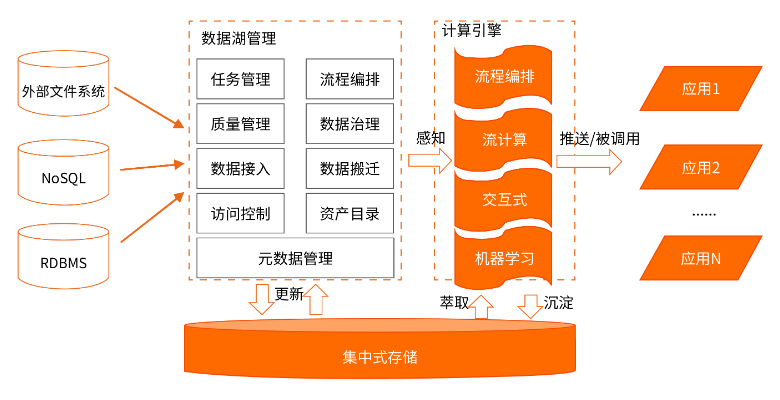
数据存储
- 统一存储系统
- 支持海量数据
- 任意类型数据原
- 始数据不变
数据分析
- 支持多种分析引擎
- 计算可扩展性
- 存储与计算解耦(云上)
数据管理
- 多数据源数据入湖
- 元数据管理
- 数据安全
- 数据质量
- 数据探索
云厂商解决方案
|
平台
|
核心服务
|
差异化能力
|
|
AWS
|
S3+Glue+Athena
|
跨账号数据共享(RAM)
|
|
Azure
|
ADLS+Synapse
|
与Power BI深度集成
|
|
阿里云
|
OSS+DataWorks
|
MaxCompute混合计算引擎
|
开源技术栈
数据湖格式
DELTA LAKE
Delta Lake is an open source project that enables building a Lakehouse architecture on top of data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing on top of existing data lakes, such as S3, ADLS, GCS, and HDFS.
定位在已有存储(S3, OSS,ADLS, GCS, HDFS)基础上构建湖仓架构。整体是围绕Spark,很多Feature是强绑定Spark。
ICEBERG
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to compute engines including Spark, Trino, PrestoDB, Flink and Hive using a high-performance table format that works just like a SQL table.
定位大数据集分析格式,分析引擎支持Spark,Flink,Trino,Hive。以数据格式角度出发,强调开放被集成,希望做成框架。
HUDI
Hudi is a rich platform to build streaming data lakes with incremental data pipelines on a self-managing database layer, while being optimized for lake engines and regular batch processing.
定位流式数据湖平台,基于增量数据管道和数据管理层构建实时数据湖。支持流式和批式数据处理。引擎支持Spark,Flink等,偏重于平台的建设。
建设思路
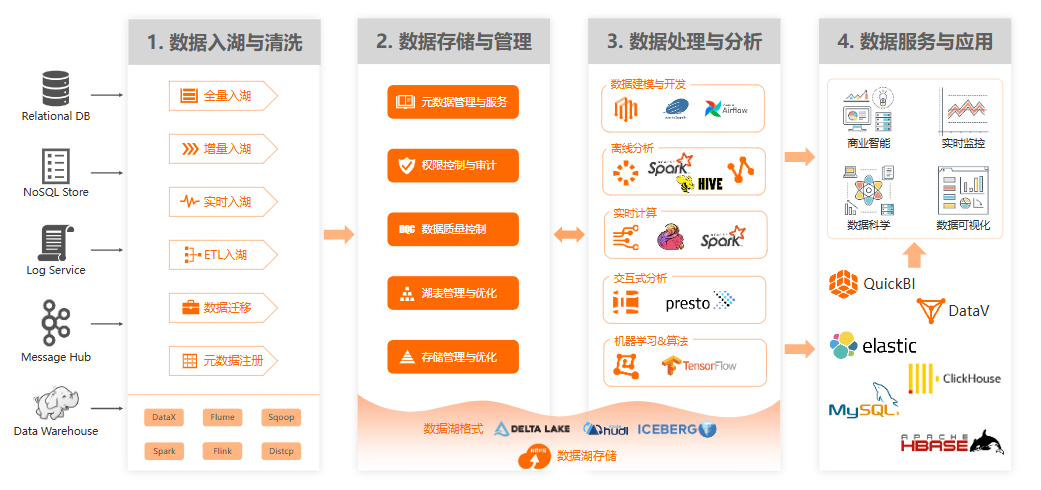
混合架构实践
- 金融行业:S3+EMR+Redshift构建HTAP系统
- 物联网:MinIO+TimeScaleDB+Apache Druid
- 内容平台:Ceph存储+OpenSearch分析
五、数据湖的未来发展方向
1. 实时化能力突破
- 流式数据湖:Apache Pulsar+Iceberg实现秒级可见
- 统一批流接口:Flink CDC直写数据湖
- 应用场景:抖音实时推荐系统更新用户画像
2. 智能化数据治理
- AI驱动的元数据管理:
- 自动数据分类(NLP识别敏感信息)
- 智能数据血缘分析(图神经网络)
- 增强数据质量:
- 异常模式自动检测(AutoML)
- 数据漂移预警系统
3. 开放格式标准化
- 跨引擎兼容:Delta/Iceberg/Hudi格式互操作
- 开放查询层:Substrait统一SQL执行计划
- 行业影响:打破厂商锁定,降低迁移成本
4. 安全架构升级
- 隐私增强技术:
- 同态加密直查(Microsoft SEAL)
- 差分隐私保护(Google DP)
- 细粒度权限:
- 列级+行级动态脱敏
- 数据水印追踪
5. 边缘协同创新
- 边缘数据湖:
- 智能终端本地预处理(TensorFlow Lite)
- 5G网络边缘节点缓存
- 应用场景:智能制造现场质检数据实时归档
六、关键挑战与应对策略
- 数据沼泽预防
- 实施数据目录(Alation Data Catalog)
- 建立数据质量SLA
- 案例:某车企通过自动标签系统提升数据发现效率60%
- 成本优化
- 智能分层存储(AWS S3 Intelligent-Tiering)
- 冷热数据自动迁移策略
- 实践:字节跳动ZSTD压缩算法节省30%存储空间
- 生态整合
- 统一服务层(OneData Service)
- 标准化数据产品接口
- 美团数据中台建设经验