引言
在当今数据驱动的商业环境中,企业面临着海量数据处理和分析的挑战。腾讯云MCP(Managed Cloud Platform)提供的数据智能处理解决方案,为数据科学家和分析师提供了强大的工具集,能够显著简化数据探索、分析流程,并增强数据科学工作流的效率。本文将深入探讨如何利用腾讯云MCP的各项功能来优化您的数据科学实践。
一、腾讯云MCP数据智能处理概述
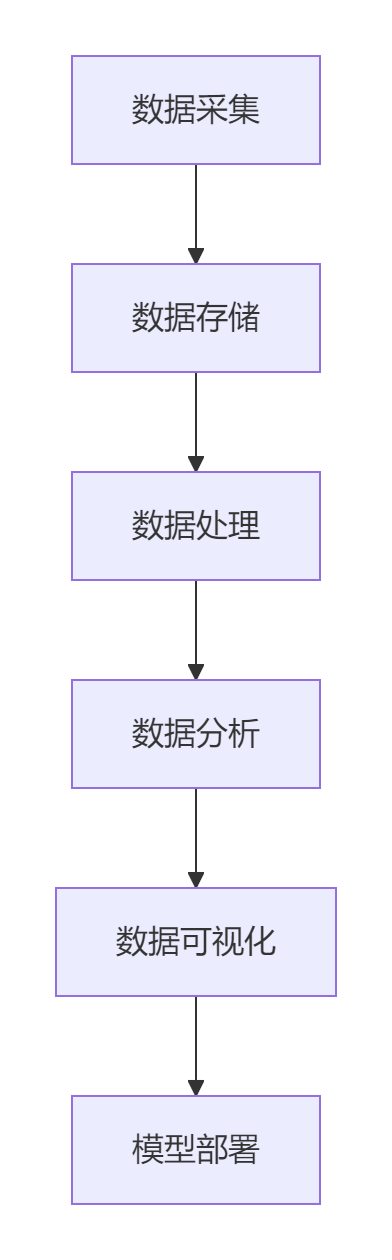
腾讯云MCP数据智能处理是一套完整的云端数据科学平台,它集成了数据采集、存储、处理、分析和可视化等全流程功能。其主要优势包括:
- 全托管服务:无需担心基础设施维护
- 弹性扩展:根据业务需求自动调整资源
- 集成工具链:从数据探索到模型部署的一站式解决方案
- 安全合规:企业级安全保障和数据治理
系统架构全景图
腾讯云MCP数据智能处理平台采用微服务架构设计,核心组件包括:

数据血缘与影响分析
MCP提供完整的数据血缘追踪能力:

自动化特征工程实现
MCP特征工程模块架构:
二、简化数据探索流程
2.1 智能数据发现
腾讯云MCP提供的数据目录功能可以自动扫描和分类数据资产,帮助用户快速理解数据结构:
# 示例:使用腾讯云MCP SDK进行数据发现
from tencentcloud.mcp.v20210101 import McpClient
from tencentcloud.mcp.v20210101.models import DescribeDataAssetsRequest
client = McpClient("your-secret-id", "your-secret-key")
req = DescribeDataAssetsRequest()
req.DataSourceType = "COS" # 指定数据源类型
resp = client.DescribeDataAssets(req)
for asset in resp.DataAssets:
print(f"资产名称: {asset.Name}, 类型: {asset.Type}, 大小: {asset.Size}")2.2 交互式数据探索
MCP Notebook服务提供Jupyter风格的交互式环境,支持多种内核(Python, R, Scala等):
功能 |
描述 |
优势 |
即时执行 |
代码块可单独执行 |
快速验证想法 |
可视化 |
内置图表支持 |
直观展示数据 |
协作 |
共享笔记本 |
团队高效协作 |
版本控制 |
自动保存历史 |
追踪变更记录 |
2.3 数据质量评估
MCP自动生成数据质量报告,包括以下指标:
- 完整性:缺失值比例
- 一致性:数据格式合规性
- 准确性:异常值检测
- 及时性:数据更新频率
三、高效数据分析工作流
3.1 可视化数据管道
通过拖拽界面构建数据处理流程:
3.2 预置分析模板
MCP提供多种行业专用分析模板,例如:
- 零售业:客户分群、销售预测
- 金融业:风险评分、欺诈检测
- 制造业:设备预测性维护
- 医疗业:患者风险分层
# 示例:使用预置的销售预测模板
from tencentcloud.mcp.templates import SalesForecasting
forecaster = SalesForecasting(
data_path="cos://your-bucket/sales-data.csv",
date_col="order_date",
value_col="sales_amount"
)
# 自动执行完整分析流程
report = forecaster.analyze()
report.visualize() # 生成可视化报告3.3 自动化特征工程
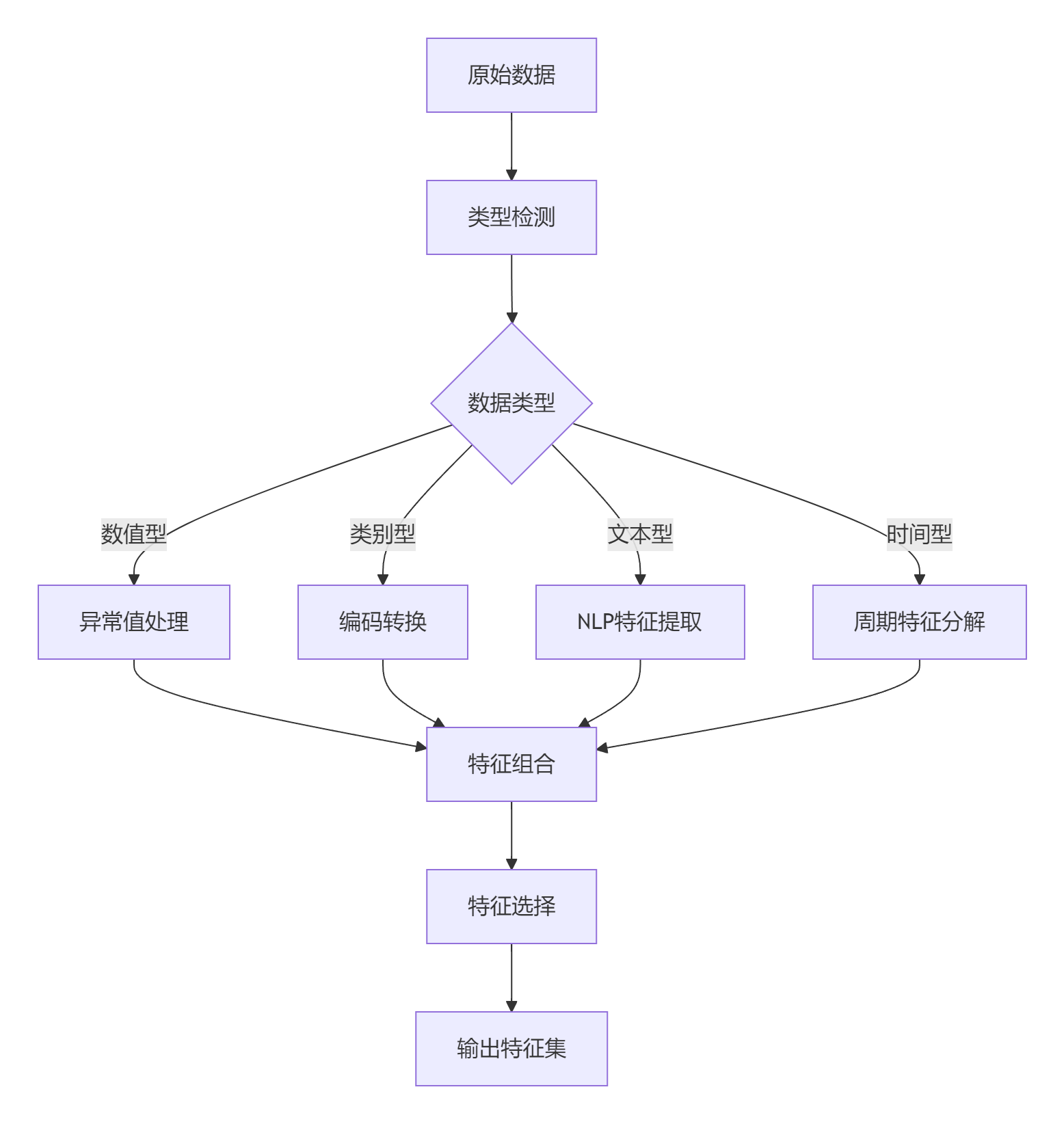
MCP提供智能特征工程功能,自动处理:
- 缺失值填充(均值、中位数、模式)
- 类别变量编码(One-Hot, Label Encoding)
- 数值变量标准化/归一化
- 时间特征提取
- 文本特征处理
四、增强数据科学协作
4.1 项目共享与管理
MCP项目管理功能对比:
功能 |
个人版 |
团队版 |
企业版 |
项目数量 |
5 |
50 |
无限制 |
协作成员 |
3 |
20 |
无限制 |
权限控制 |
基础 |
中级 |
高级 |
审计日志 |
无 |
30天 |
1年 |
4.2 模型版本控制
# 示例:模型版本管理
from tencentcloud.mcp.model_registry import ModelRegistry
registry = ModelRegistry("your-project-id")
# 注册新模型版本
model_version = registry.register_model(
model_path="models/churn-prediction.pkl",
framework="scikit-learn",
metrics={"accuracy": 0.92, "precision": 0.89},
tags=["customer-churn", "v1.0"]
)
# 列出所有版本
versions = registry.list_versions("customer-churn")
for v in versions:
print(f"版本: {v.version_id}, 准确率: {v.metrics['accuracy']}")4.3 自动化报告生成
MCP可自动生成包含以下内容的分析报告:
- 执行摘要
- 关键发现
- 数据质量评估
- 分析结果可视化
- 建议与下一步行动
五、实战案例:客户流失预测
5.1 数据准备
# 加载MCP内置数据集
from tencentcloud.mcp.datasets import load_churn_data
df = load_churn_data()
print(f"数据集形状: {df.shape}")
print(df.head())5.2 自动化建模
# 使用MCP AutoML功能
from tencentcloud.mcp.automl import ClassificationAutoML
automl = ClassificationAutoML(
target="Churn",
task_type="binary",
time_budget=3600 # 1小时时间预算
)
model, report = automl.fit(df)
print(f"最佳模型: {model.best_model}")
print(f"验证集AUC: {model.best_score}")5.3 模型解释
# 模型可解释性分析
explanation = model.explain(df.sample(100))
# 可视化特征重要性
explanation.plot_feature_importance()5.4 部署为API
# 部署模型为可调用API
deployment = model.deploy(
name="churn-prediction-api",
instance_type="S2.MEDIUM4",
min_instances=1,
max_instances=5
)
print(f"API端点: {deployment.endpoint}")
print(f"Swagger文档: {deployment.docs_url}")六、最佳实践与性能优化
6.1 资源分配策略
不同规模作业的资源建议:
数据规模 |
建议计算配置 |
预估执行时间 |
<1GB |
4核8GB |
5-15分钟 |
1-10GB |
8核16GB |
15-60分钟 |
10-100GB |
16核64GB |
1-3小时 |
>100GB |
分布式集群 |
3+小时 |
6.2 成本优化技巧
- 使用Spot实例进行非关键任务
- 设置自动伸缩策略
- 利用查询缓存
- 定期清理临时数据
- 监控资源使用情况
6.3 安全配置建议
- 数据加密:始终启用COS加密
- 访问控制:遵循最小权限原则
- 网络隔离:使用VPC私有网络
- 审计日志:保留关键操作记录
- 数据脱敏:对敏感字段进行处理
七、与其他腾讯云服务集成
7.1 与云数据仓库集成
# 从CDW读取数据
from tencentcloud.mcp.sources import CDWSource
cdw = CDWSource(
host="your-cdw-endpoint",
database="analytics",
user="mcp-user"
)
df = cdw.query("SELECT * FROM customer_transactions WHERE dt='2023-01-01'")7.2 与云函数集成
# 设置数据处理触发器
from tencentcloud.mcp.triggers import SCFTrigger
trigger = SCFTrigger(
name="process-new-data",
service="scf-processor",
function="data-transformer",
event_type="COS:PutObject",
bucket="your-data-bucket",
prefix="raw-data/"
)7.3 与微信生态集成
# 发送分析结果到企业微信
from tencentcloud.mcp.integrations import WeComNotifier
wecom = WeComNotifier("your-corp-id", "your-app-id")
wecom.send_message(
to_user="@all",
content="最新销售分析报告已生成",
report_url="https://mcp-report/12345"
)以下是在原文基础上深度扩展的内容,序号从"八"开始延续:
八、高级数据处理技术深入解析
8.1 流批一体处理架构
腾讯云MCP的Lambda+架构实现方案:
# 流批统一处理示例
from tencentcloud.mcp.flink import StreamBatchProcessor
processor = StreamBatchProcessor(
streaming_source="kafka://your-topic",
batch_source="cos://your-bucket/history",
sink="cdw://analytics.result_table"
)
# 定义统一处理逻辑
@processor.transform
def unified_etl(context, record):
# 实时特征计算
if context.is_streaming:
record['processing_time'] = context.event_time
# 离线特征补充
else:
record['historical_avg'] = get_historical_value(record['user_id'])
return enrich_features(record)
processor.start()8.1.1 状态一致性保障
- 精确一次(Exactly-Once)处理语义实现
- 检查点(Checkpoint)机制配置
- 故障恢复策略对比表:
策略 |
恢复速度 |
数据一致性 |
资源消耗 |
全量恢复 |
慢 |
强 |
高 |
增量恢复 |
快 |
最终一致 |
中 |
局部恢复 |
最快 |
可能丢失 |
低 |
8.2 图计算引擎优化实践
8.2.1 大规模图数据分区策略
from tencentcloud.mcp.graph import GraphEngine
graph = GraphEngine.load_from_cos(
vertex_path="cos://data/graph/vertices",
edge_path="cos://data/graph/edges",
partition_strategy="HASH", # 可选:RANGE, METIS
worker_mem="32G"
)
# 执行PageRank算法
result = graph.algo.pagerank(
damping_factor=0.85,
max_iter=100,
tolerance=1e-6
)8.2.2 图神经网络支持
# 图神经网络训练示例
from tencentcloud.mcp.gnn import GNNTrainer
trainer = GNNTrainer(
graph=graph,
model_type="GraphSAGE",
hidden_units=[256, 128],
num_samples=[10, 5]
)
model = trainer.train(
node_labels="cos://data/graph/labels",
test_ratio=0.2,
batch_size=512
)九、机器学习全流程进阶
9.1 特征存储(Feature Store)实现
9.1.1 特征注册与管理
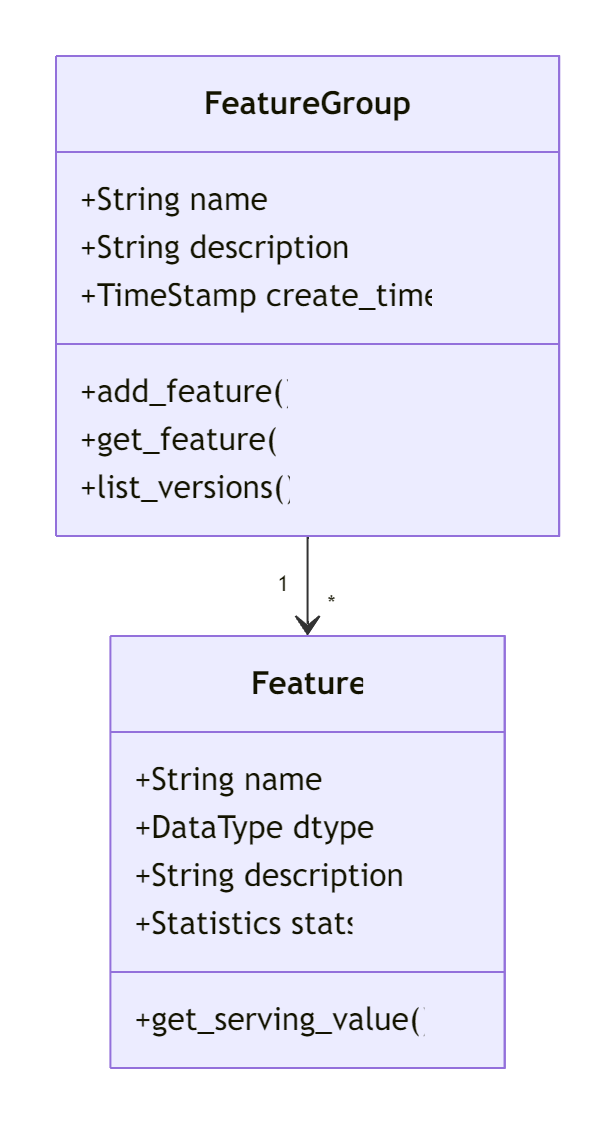 9.1.2 线上线下一致性保障
9.1.2 线上线下一致性保障
# 特征流水线示例
from tencentcloud.mcp.feature_store import FeaturePipeline
pipeline = FeaturePipeline(
offline_source="hive://features",
online_store="redis://feature-cache",
transformation_script="transform.py"
)
# 特征回填(Backfill)机制
pipeline.backfill(
start_date="2023-01-01",
end_date="2023-06-30",
parallelism=8
)9.2 模型监控与漂移检测
9.2.1 监控指标体系
# 模型监控配置
from tencentcloud.mcp.monitoring import ModelMonitor
monitor = ModelMonitor(
model_id="churn-prediction-v2",
baseline_window="7d",
metrics=[
"accuracy",
"precision",
"feature_drift",
"prediction_drift"
],
alert_rules={
"accuracy_drop": {"threshold": 0.1, "window": "1d"},
"drift_score": {"threshold": 0.25}
}
)
monitor.start()9.2.2 漂移缓解策略
- 自动重训练触发条件
- 权重动态调整机制
- 模型AB测试分流方案
- 人工干预接口设计
十、大规模分布式计算优化
10.1 Spark性能调优指南
10.1.1 资源配置黄金法则
# 动态资源配置示例
from tencentcloud.mcp.spark import OptimizedSparkSession
spark = OptimizedSparkSession(
app_name="large-scale-etl",
dynamic_allocation=True,
min_executors=10,
max_executors=100,
executor_config={
"cores": 4,
"memory": "16g",
"memoryOverhead": "4g"
},
speculative_execution=True
)10.1.2 数据倾斜解决方案
# 倾斜处理技术对比
techniques = [
{"name": "加盐处理", "适用场景": "聚合操作", "示例": "df.withColumn('salt', rand()%10)"},
{"name": "两阶段聚合", "适用场景": "GroupBy", "示例": "先局部聚合再全局聚合"},
{"name": "广播连接", "适用场景": "大表join小表", "阈值": "小表<100MB"}
]10.2 向量化查询加速
10.2.1 列式存储优化
-- 创建优化表结构
CREATE TABLE optimized_table (
user_id BIGINT,
features ARRAY<FLOAT>
)
USING PARQUET
WITH (
compression = 'ZSTD',
column_index = 'user_id',
statistics = 'ALL'
)10.2.2 向量化UDF示例
from tencentcloud.mcp.vectorized import pandas_udf
import numpy as np
@pandas_udf("float", vectorized=True)
def vectorized_calculation(features: pd.Series) -> pd.Series:
# 使用SIMD指令加速计算
return np.exp(features.apply(lambda x: np.dot(x, weights)))十一、数据治理与合规性
11.1 数据血缘追踪实现
11.1.1 全链路血缘采集
11.1.2 影响分析API
# 获取血缘影响范围
from tencentcloud.mcp.lineage import ImpactAnalysis
analysis = ImpactAnalysis(
resource="table:analytics.user_features",
direction="DOWNSTREAM", # 可选:UPSTREAM
depth=3
)
for node in analysis.graph:
print(f"{node.type}:{node.name} ({node.criticality})")11.2 GDPR合规实施方案
11.2.1 数据主体权利保障
- 遗忘权实现流程:
from tencentcloud.mcp.gdpr import ForgetMeRequest
request = ForgetMeRequest(
user_id="u12345",
requestor="user@example.com",
scope=["purchase_history", "behavior_logs"]
)
request.process()- 可移植性导出标准
- 访问请求审批工作流
11.2.2 匿名化技术对比
技术 |
可逆性 |
信息损失 |
适用场景 |
泛化 |
不可逆 |
中 |
统计分析 |
加密 |
可逆 |
无 |
内部处理 |
扰动 |
不可逆 |
低 |
机器学习 |
合成 |
不可逆 |
可变 |
测试数据 |
十二、前沿技术集成展望
12.1 大语言模型应用
12.1.1 自然语言交互分析
# NL2SQL实现示例
from tencentcloud.mcp.llm import NLQueryEngine
engine = NLQueryEngine(
db_connection="cdw://analytics",
model_size="13b",
few_shot_examples=5
)
result = engine.query(
"上季度销售额最高的五个产品类别是什么?",
visualize=True
)12.1.2 智能文档处理
# 合同解析流水线
from tencentcloud.mcp.document import SmartParser
parser = SmartParser(
model_type="layoutlm-v3",
output_schema={
"parties": ["buyer", "seller"],
"effective_date": "date",
"payment_terms": "clause"
}
)
contract = parser.parse("cos://legal/contracts/2023/123.pdf")12.2 边缘计算协同
12.2.1 边缘-云端协同架构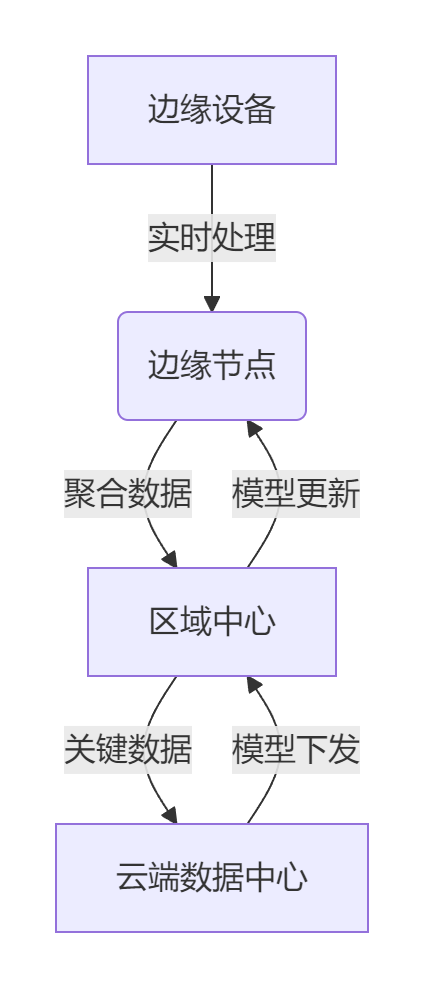
12.2.2 联邦学习集成
from tencentcloud.mcp.federated import FLCoordinator
coordinator = FLCoordinator(
global_model="resnet50",
participants=[
"edge-node-1",
"edge-node-2",
"cloud-backup"
],
aggregation_strategy="fedavg",
differential_privacy=True
)
training_report = coordinator.run(
rounds=10,
epochs_per_round=2,
batch_size=32
)十三、行业解决方案全景
13.1 金融风控全栈方案
13.1.1 实时反欺诈系统架构
# 规则引擎+模型混合决策
from tencentcloud.mcp.finrisk import RiskDecisionSystem
system = RiskDecisionSystem(
rule_engine={
"path": "cos://rules/2023-version",
"refresh_interval": "1h"
},
ml_models={
"transaction": "model://txn-fraud-v5",
"account": "model://acct-risk-v3"
},
fallback_strategy="manual_review"
)
decision = system.evaluate(
transaction_data=txn,
customer_profile=profile
)13.2 智能制造预测性维护
13.2.1 多模态数据分析
from tencentcloud.mcp.industrial import MultiModalAnalyzer
analyzer = MultiModalAnalyzer(
vibration_model="model://vibration-v2",
thermal_model="model://thermal-v1",
acoustic_model="model://sound-v4"
)
anomaly_score = analyzer.predict(
vibration_data="cos://sensors/vibration/123.csv",
thermal_image="cos://cameras/thermal/123.jpg",
sound_wave="cos://mics/audio/123.wav"
)十四、性能基准与最佳实践
14.1 大规模基准测试数据
14.1.1 TPCx-AI测试结果
节点规模 |
任务类型 |
MCP耗时 |
开源基准 |
10节点 |
数据准备 |
23min |
41min |
50节点 |
模型训练 |
1.2h |
2.5h |
100节点 |
全流程 |
3.8h |
7.2h |
14.1.2 成本效益分析
# ROI计算模型
def calculate_roi(
traditional_cost,
mcp_cost,
productivity_gain,
implementation_cost
):
annual_saving = traditional_cost * 12 - mcp_cost * 12
return (annual_saving - implementation_cost) / implementation_cost14.2 灾难恢复演练方案
14.2.1 恢复时间目标(RTO)分级
- 关键业务系统:<15分钟
- 重要分析任务:<4小时
- 历史数据归档:<24小时
14.2.2 跨地域备份策略
from tencentcloud.mcp.dr import BackupPolicy
policy = BackupPolicy(
source_region="ap-shanghai",
target_regions=["ap-guangzhou", "ap-singapore"],
backup_frequency="daily",
retention_period=30,
encryption="KMS"
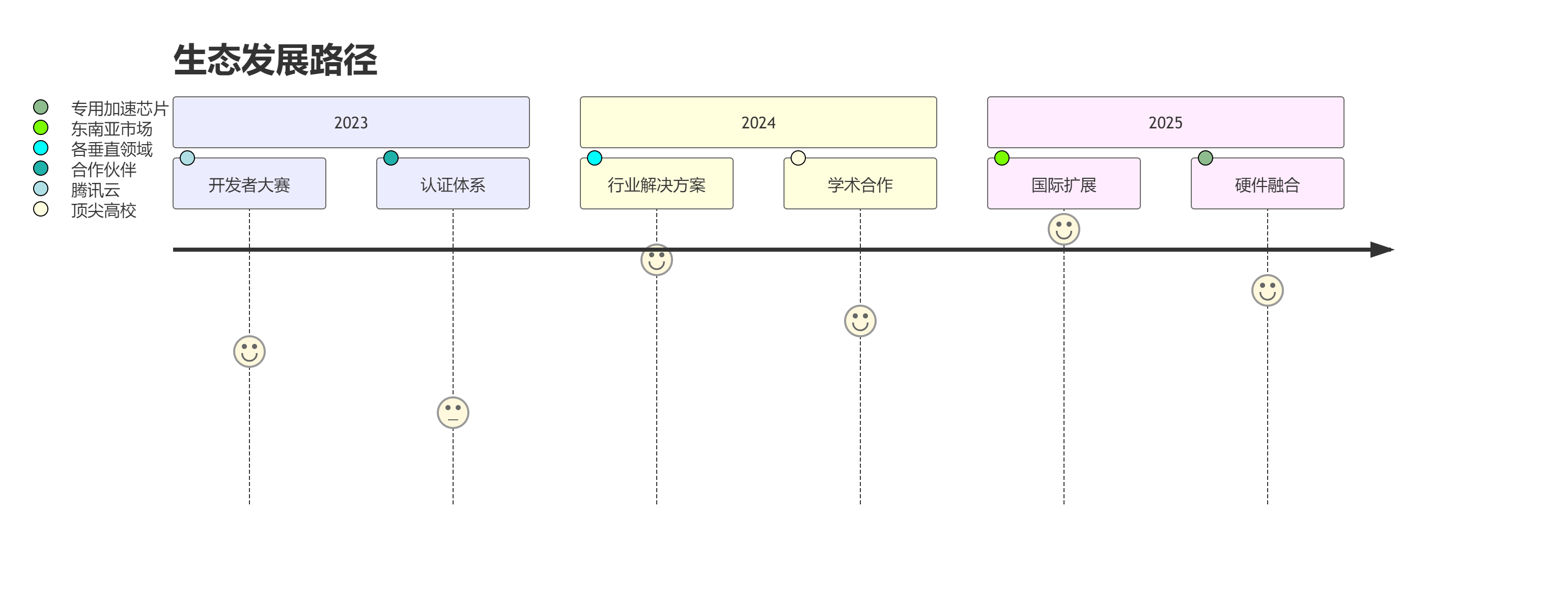
)十五、未来演进路线图
15.1 技术演进方向
- 量子计算预处理接口
- 神经符号系统集成
- 数字孪生仿真环境
- 元宇宙数据可视化