自认为写了很多,后面会出 仙人掌、最小树形图 学习笔记。
多图警告。
众所周知王老师有一句话:
⼀篇⽂章不宜过⻓,不然之后再修改使⽤的时候,在其中找想找的东⻄就有点麻烦了。当然⽂章也不宜过多,不然想要的⽂章也不容易找。
于是我写了《图论学习笔记 1》之后写了《图论学习笔记 2》,现在又来了《图论学习笔记 3》.
基环树
英文名 Unicyclic Pseudotree,但是我不要求记下来,因为直接叫中文名甚至更简单一些。
上次我们讲到了圆方树,现在就来讲基环树了!
基环树属于知识简单,但是应用难的那种。
基环树的定义很简单,就是在一棵树(无环连通图)上多连一条边得到的图,显然这样就会多出一个环。
所以基环树相比树的最大差别就是那个显眼的环,也是这样比就树复杂了一些。
首先我们先会说怎么找到这个基环树里面的环(有些友善的题可能会直接给你,有些题就需要你自己去找)。以后就会考虑对基环树和仙人掌图进行缩点以将其转换为一个树上动态规划的问题。
前置定义
首先需要了解一些定义。
基环树:直白来讲就是一棵树,然后把其中某两个没有边的点连边,得到了基环树。
而基环树又分有向和无向。
**无向基环树:**就是 n n n 点 n n n 边的连通图。至于为什么 n n n 点 n n n 边的连通图就一定有一个环,而且去掉一条边之后会变成一棵树,可以感性理解。
有向基环树:有好几个条件:
首先这个有向图是弱连通的,而且恰好有一个有向环。
而且有:
- 如果其他点都可以到环,则称为内向基环树。
- 如果其他点都可以被环到,则称为外向基环树。
- 否则就不是有向基环树。
我们可以充分发挥人类智慧简化这些条件:
内向基环树:每一个点出度恰好为 1 1 1,且图弱连通。(这个也很容易想到,图论题做多了就很好理解了)
外向基环树:每一个点入度恰好为 1 1 1,且图弱连通。
而如果图不是弱连通的话,就会形成基环树森林。
基环树找环
既然是基环树,那么找环一定是绝对不可以缺少的(不然基环树就失去了它的精髓)。
显然可以通过 tarjan 找边双连通分量或强连通分量的方法来解决,这样并不难写,而且很现成。
对于内向的基环树,有另一种方法,甚至比 tarjan 还好写!!
考虑搞一个栈,记录每一个点是否在栈的里面,以及每一个点是否已经被访问到。
当发现对于一点 x x x,此时 a x a_x ax 在栈里面,说明 x → a x x \to a_x x→ax 在环的上面!!!这是显然的(当自己要到的点已经到达了自己到时候就一定有一个环)。
所以考虑从 a x a_x ax 再搜一遍,一直走走走,直到走到 x x x 的位置,这时候就得出了环上面所有的点。
P8269 [USACO22OPEN] Visits S
利用前面讲到的东西就可以做这道题目了。
显然可以考虑对于每一个 i i i,连有向边 i → a i i \to a_i i→ai。这样的每一个点的出度都为 1 1 1,最终一定会形成一个内向基环树森林。(题目并没有保证图是弱连通的)
而根据题目可以发现两个基环树之间是完全独立的,所以就可以单独考虑每一个基环树。
考虑单独的一个基环树。
由于这是一个内向基环树,所以一定是以环上点为根的树 + 中间的环得到的结果。
考虑这些到环上点的树,显然这些树除了终点的位置互不相交,所以是相互独立的。
考虑这些树能对答案造成什么影响,显然如果每一次选择走叶结点,就可以得到这些树里面所有的值。
考虑对于环上的点,显然一定会有恰好一个点无法对答案产生贡献,直接把这个走不到的点设成 v v v 值最小的即可。
不妨来观察一下这个基环树:
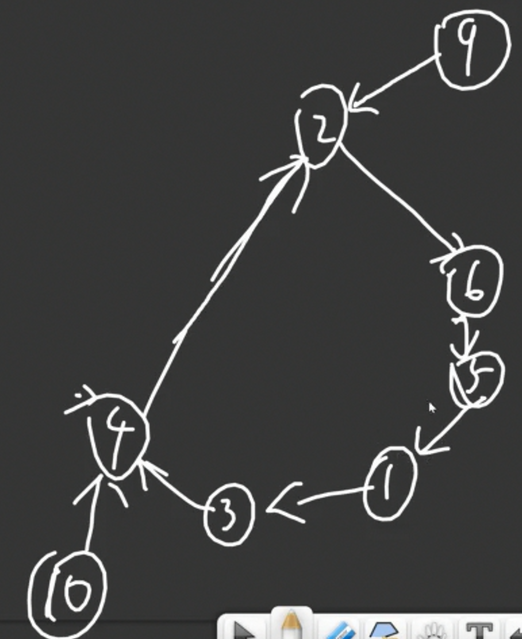
由于我的语文实在不行,所以大家可以借着图理解一下。
对于多棵基环树,可以算出答案之后加起来即可。
这里采用前面介绍过的内向基环树比较好写的方法。因为这里并不需要记录每一个环上面具体由什么点,我们关心的是环上面最小的权值。
在极限卡常之下成功把 317ms 卡到了 92ms,成功跻身最优解第一页。
#include <bits/stdc++.h>
#define int long long
using namespace std;
const int N = 100010;
int n;
int a[N], v[N], sum = 0;
bool vis[N], nw[N];
inline int read() {
char c = getchar();
int x = 0, s = 1;
while (c < '0' || c > '9') {
if (c == '-')
s = -1;
c = getchar();
}
while (c >= '0' && c <= '9') {
x = x * 10 + c - '0';
c = getchar();
}
return x * s;
}
inline void write(int x) {
if (x > 9)
write(x / 10);
putchar(x % 10 | 48);
}
inline void dfs(int u) {
vis[u] = 1, nw[u] = 1;
if (nw[a[u]]) {
int m = v[u];
for (register int i = a[u]; i != u; i = a[i])
m = min(m, v[i]);
sum -= m;
} else if (!vis[a[u]])
dfs(a[u]);
nw[u] = 0;
}
signed main() {
n = read();
for (register int i = 1; i <= n; i++)
a[i] = read(), v[i] = read(), sum += v[i];
for (register int i = 1; i <= n; i++)
if (!vis[i])
dfs(i);
write(sum);
return 0;
}
另外 P9869 [NOIP2023] 三值逻辑 这道题也是不错的。
接下来我们的有向基环树就告一段落。因为有向基环树要么是大部分点入度恰为 1 1 1 要么就是大部分点出度恰为 1 1 1(这样很好做),而无向基环树就不一样了。
比较需要的东西
接下来的题目就没有那么友善了,所以我们需要做好充足的准备。
一般来说,基环树的题目需要存储:
一个点是不是在环上。
环在深搜树上面的最上方和最下方的编号。
对于环上点 x x x,还要存储环上 x x x 的下一个结点。
最好也写上每一个点的深度,有些题要用。
这三个东西都并不是很难求,直接在 dfs 的时候记录一下就可以了。
#include <bits/stdc++.h>
using namespace std;
const int N = 500010;
int n;
vector<int> v[N];
//vis 表示是否访问过,stk 表示是否在搜索栈里面,cir 表示在不在环上
bool vis[N], stk[N], cir[N];
//up 和 dn 表示深搜树的最上方 和 最下方的结点编号。
int up, dn;
//nxt[x] 表示对于环上面的点 x,在环上面的下一个点。
//lvl 表示结点的深度
int nxt[N], lvl[N];
void dfs(int u, int pre, int lv) {
vis[u] = stk[u] = 1, lvl[u] = lv;//记录深度和标记
for (auto i : v[u])
if (!vis[i]) {//目前走到了树边
dfs(i, u, lv + 1);//往下走
if (cir[i] && i != up)//如果一个点 u 的儿子 i 在环上面的话,而且点 u 并不是再走一步就到达了环,而是就在环上
nxt[u] = i, cir[u] = 1;//那么就记录后继,也要标记在环的上面
} else if (i != pre && stk[i])//目前走的是子孙回到祖先的边(祖先关系不是父子关系),也就是找到了环
dn = u, up = i, cir[u] = 1, nxt[u] = i;//显然祖先就是最高的点,自己就是最低的点。记录 + 标记
stk[u] = 0;
}
int main() {
cin >> n;
for (int i = 1; i <= n; i++) {
int x, y;
cin >> x >> y;
v[x].push_back(y);
v[y].push_back(x);//连边
}
dfs(1, 0, 1);//从任意一个点开始搜均可,就是 nxt 和 lvl 可能不太一样
return 0;
}
另外还要注意一个结论:基环树上面任意删除一条环边,得到的一定是一棵树。
P5049 [NOIP 2018 提高组] 旅行 加强版
难度飙升。运用前面所学的内容,做一下这道题。
发现要么 m = n − 1 m=n-1 m=n−1 要么 m = n m=n m=n,显然分别对应树和基环树的情况。
至于树,直接对于邻接表排序即可,然后直接 dfs。可以得到 60pts 的好成绩。
#include <bits/stdc++.h>
using namespace std;
int n, m;
const int N = 5010;
vector<int> v[N], ans;
void dfs(int u, int pre) {
ans.push_back(u);
for (auto i : v[u])
if (i != pre)
dfs(i, u);
}
int main() {
// freopen("travel.in", "r", stdin);
// freopen("travel.out", "w", stdout);
scanf("%d%d", &n, &m);
for (int i = 1; i <= m; i++) {
int x, y;
scanf("%d%d", &x, &y);
v[x].push_back(y);
v[y].push_back(x);
}
for (int i = 1; i <= n; i++)
sort(v[i].begin(), v[i].end());
dfs(1, 0);
for (auto i : ans)
printf("%d ", i);
return 0;
}
但是剩下的 40pts 不是 MLE 就是 TLE,这证明我们这种方法在基环树的时候时行不通的。
考虑图是基环树的情况。
因为所有的边都走的话是不可以的(会产生 MLE 或 TLE 的问题),所以考虑抛弃一条边。这条边显然就是环边。
为什么呢?只需要回想一下前面提过的结论:
另外还要注意一个结论:基环树上面任意删除一条环边,得到的一定是一棵树。
所以我们可以找出来环之后枚举那一条环边被抛弃了,然后对剩下的树跑深搜即可。这样就可以得到 O ( n 2 ) O(n^2) O(n2) 的做法,足以通过简单版。
考虑 100pts 的正解。
发现我们并不需要枚举哪一条边被抛弃了,只需要使用回溯来处理即可。那么就需要考虑什么时候需要回溯。
显然对于某一条环上的边 x → y x \to y x→y,如果 x x x 选择在遍历完其他的子结点子树的时候回溯,则我们需要考虑回溯之后遍历的点 z z z(只需要考虑第一个,因为这是字典序)和 y y y 的关系。
考虑不能回溯或者是回溯更优的情况。
首先 y y y 肯定是没有被访问到的,访问它没有意义,要不然就会疯狂递归直到爆炸。
显然,**当前的这条边 x → y x \to y x→y 一定要在环的上面,也就是两端都是环上面的点。**否则不能回溯。(我们放弃的是一条环边。)
PS:如果 x → y x \to y x→y 不是环边的话,直接走就是了。因为这个时候完全不需要讨论下面的东西,所以把 z z z 设为 + ∞ +\infty +∞ 即可。
也很显然,如果我们已经放弃过了一条环边,则也不可以回溯。(不能放弃多条环边。)
考虑 y y y 在 x x x 的邻点列表中的位置。显然, y y y 必须是 x x x 的最后一个邻点,要不然回溯之后就访问不了其他的邻点了。(如果 y y y 是 x x x 最后一个邻点的话还可以通过环的另一边回来)
但是,即使是最后一个邻点,也要担心字典序的问题。所以还要判断 y y y 和 z z z 的关系是否是 y > z y>z y>z,如果满足这个关系,就可以放弃这条环边,回溯了。否则不能回溯。
上面已经把怎么判断讲得很清楚了。如果不懂的话也可以看代码注释。
#include <bits/stdc++.h>
using namespace std;
int n, m;
const int N = 500010;
vector<int> v[N];
bool vis[N], nw[N], cir[N];
int up;//去除了一些不需要的东西
void dfs(int u, int pre) {//就是模板,原封不动的,就是删了一些没用的东西
vis[u] = nw[u] = 1;
for (auto i : v[u])
if (!vis[i]) {
dfs(i, u);
if (cir[i] && i != up)
cir[u] = 1;
} else if (i != pre && nw[i])
up = i, cir[u] = 1;
nw[u] = 0;
}
bool f;
void get(int u, int pre, int z) {
vis[u] = 1;//记录
cout << u << " ";
for (int i = 0; i < (int)v[u].size(); i++) {
int to = v[u][i];
if (vis[to])//显然访问过的点不能走
continue;
if (cir[u] && cir[to] && !f) {//如果这条边在环的上面,而且没有抛弃其他的环边
if (i < (int)v[u].size() - 1 - (pre > to))//如果这个点不是 u 最后一个邻点
get(to, u, v[u][i + 1] == pre ? v[u][i + 2] : v[u][i + 1]);//只能乖乖地继续走
else if (z > to)//虽然是最后一个邻点,但是抛弃了这条边并不优
get(to, u, z);//继续走,注意这里和上面的差别
else//可以走
f = 1;//直接抛弃环边
} else
get(to, u, 1e9);
}
}
int main() {
cin >> n >> m;
for (int i = 1; i <= m; i++) {
int x, y;
cin >> x >> y;
v[x].push_back(y), v[y].push_back(x);//建边
}
for (int i = 1; i <= n; i++)
sort(v[i].begin(), v[i].end());//为了最小化字典序,需要对它排序
dfs(1, 0);//找环
memset(vis, 0, sizeof vis);//清空重新利用
get(1, 0, 1e9);//获取答案
return 0;
}
显然这个代码也可以通过简单版,这样就白嫖了一个双倍经验!
基环树上尝试递推
递推也可以说是动态规划,实际上动态规划是包含递推的。
目前我们学过两个不是线性结构上面的 dp:一个是在无向无环图上面的 dp,一个是在有向无环图上面的 dp。
而我们知道 dp 是不支持环形结构的:这样就会无法转移。
但是这并不意味着基环树上面就无法 dp。为了处理这个特殊的环,还是延伸出了若干个科技的。
观察基环树的形态,容易发现它一定是一个环,周围带上很多棵很小的树。
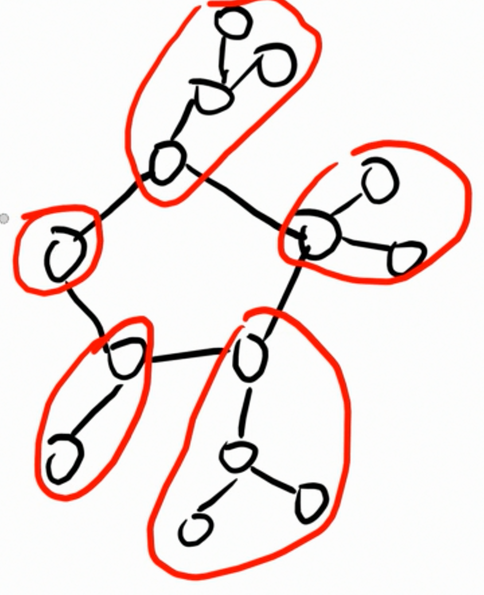
于是我们可以把环上的点视作根。 而且,对于这些小的树,有一种特殊的叫法叫做环点树。
于是我们可以对这几棵环点树进行树形 dp,存储在环点上面。于是基环树就变成了简单的一个环。
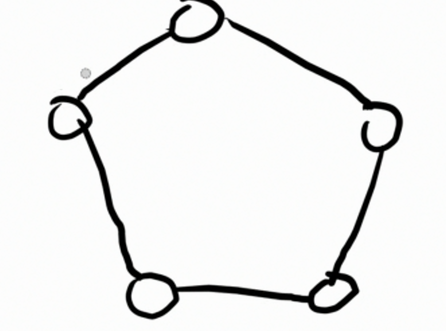
但是这样的 dp 还是无法进行。虽然结构简单了许多,但是那个环仍然存在。
于是我们考虑断环为链。
试图将某一条边切开,那么就变成了一条线性的链。我们可以在上面跑某些东西以得到答案。
但是切开的那条边仍然不可以忽略。所以可以对这条边特别考虑,分类讨论以得出答案。
这种方法完全可行。但是还有其他的方法,来看看另一种方法。
另一种方法
那么还有什么处理基环树的环的方法呢?因为基环树和深搜树有诸多相同点,所以考虑在深搜树上面处理这个问题。
这种方法里面,我们不会尝试断环为链破坏深搜树的结构,而是会尝试在深搜树上面就地解决问题。
这种方法更多的是为了铺垫后面的仙人掌图,如果只是基环树的话也可以使用上面提到的做法。
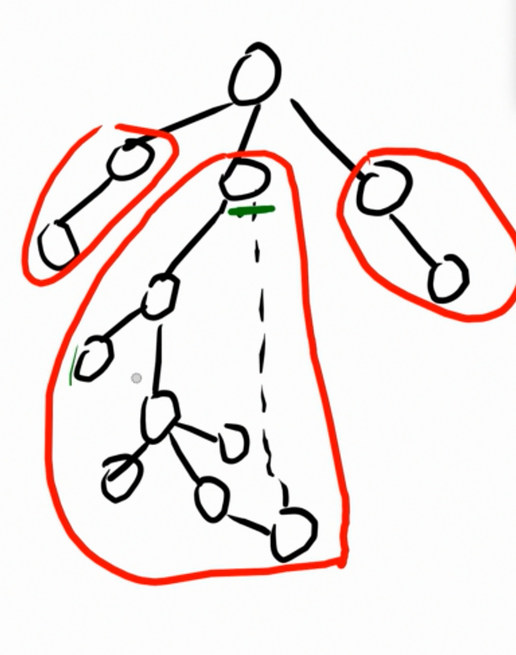
首先,尝试在深搜树上面找到所有的环点树。
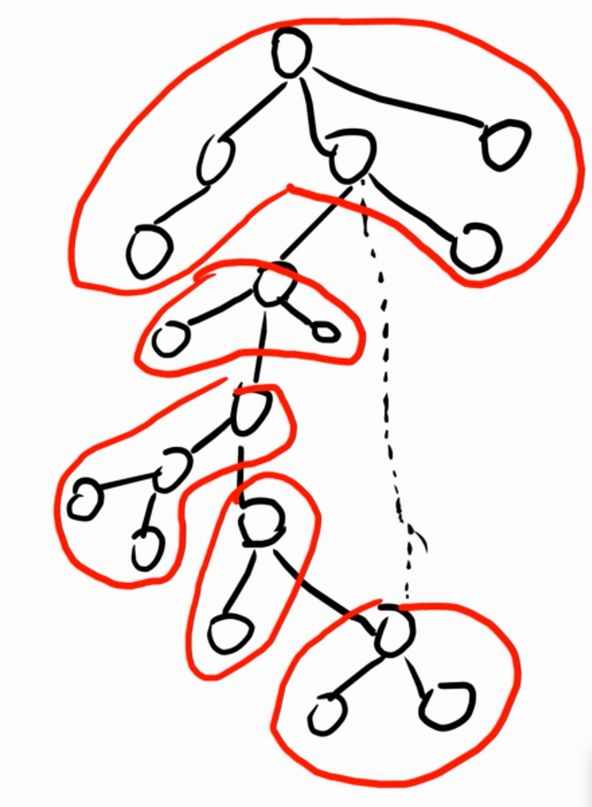
被圈出来的就是环点树。
在深搜树上面找环点树其实并不难,唯一的特殊点就是环上最高点的环点树。
因为最高点的环点树不止需要其不在环上面的子树,还需要其父亲的子树,这需要做一个类似换根的操作。当然,这有些困难。
所以我们有一种转换方式:将环和最高结点看成一个子树,然后交给父结点来处理。类似这样:
P4381 [IOI 2008] Island
很容易发现给出的图是一个基环树森林。而基环树之间可以任意从一个点到另外一个点,所以我们的目标就是求出所有基环树的直径,再相加即可。
很容易联想到求出树的直径(加权),可以两次 dfs,也可以使用树形 dp 来求(枚举 lca)。
那么如果这棵树变成了一棵基环树,区别又在那里呢?
考虑一颗基环树。
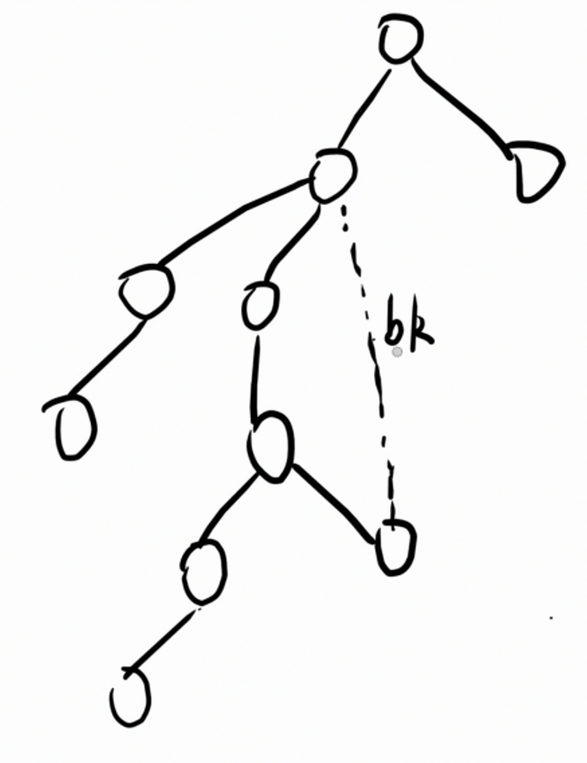
将其中的一条构成环的回边称作 b k bk bk。显然 b k bk bk 是环上最高点 u p up up 和最低点 d n dn dn 连的一条边。
此时考虑分类讨论:考虑基环树直径经过/不经过 b k bk bk 得到的答案。
直径不过 b k bk bk 这条边。
显然这个时候就相当于求去除 b k bk bk 这条边之后的树的直径。所以直接按照上面交代的树上求直径的方法做就即可。
直径过 b k bk bk 这条边。
很容易发现,当直径走到了环的外面,在以后也不会回到环上。(要不然就和走到环的外面矛盾了)
所以, u p up up 和 d n dn dn 周围的结点也同样比较重要。因为 u p up up 和 d n dn dn 要使用它们走出环。
例如这两个结点:
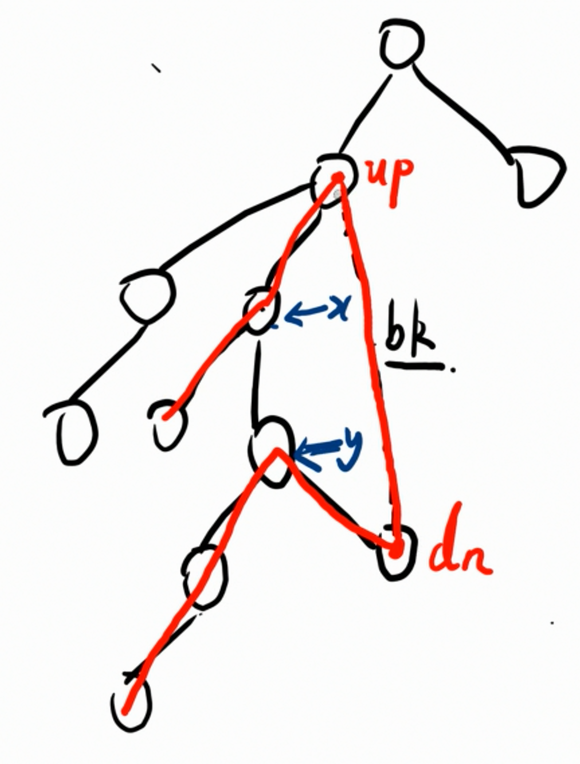
最终的答案显然就是 x x x 的环点树的根到结点的最大距离 + y y y 的环点树的根到结点的最大距离 + x → u p x \to up x→up 的路径的边权 + y → d n y \to dn y→dn 的路径的边权 + b k bk bk 的边权。
如果使用 l v l lvl lvl 来表示结点到根结点的距离,那么就可以说答案为 b k + l v l x − l v l u p + l v l d n − l v l y bk + lvl_x - lvl_{up}+lvl_{dn}-lvl_{y} bk+lvlx−lvlup+lvldn−lvly。发现 l v l x − l v l u p lvl_x - lvl_{up} lvlx−lvlup 和 l v l d n − l v l y lvl_{dn} - lvl_y lvldn−lvly 可以简化一下,不妨设 l v l x − l v l u p = d p 1 x lvl_x - lvl_{up}=dp1_x lvlx−lvlup=dp1x, l v l d n − l v l y = d p 2 x lvl_{dn}-lvl_y = dp2_x lvldn−lvly=dp2x。
注意如果 x = y x=y x=y 那么环点树的根到结点的最大距离只能计算一次。
所以我们可以 O ( n 2 ) O(n^2) O(n2) 枚举 x x x 和 y y y。如果嫌慢的话,也可以预处理达到 O ( n ) O(n) O(n) 的。
那么 O ( n ) O(n) O(n) 怎么做到呢?考虑枚举 x x x,根据 d p 1 x dp1_x dp1x 的取值来取 y y y(显然要取可以取的数中最大的)。
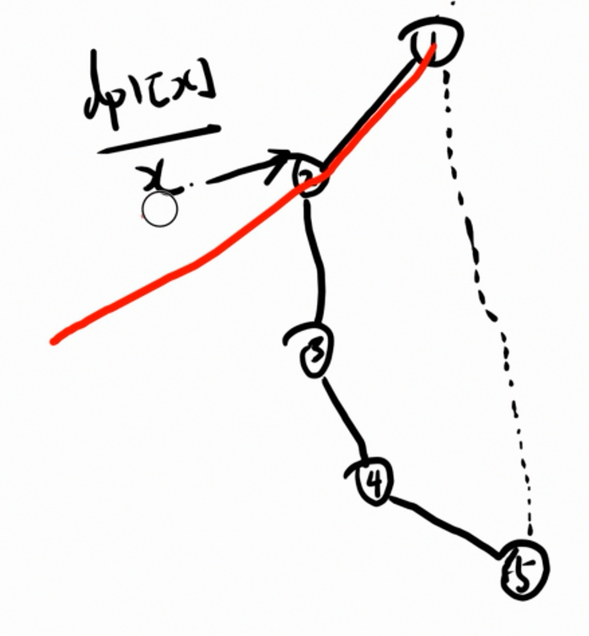
这里,如果 x = 2 x=2 x=2,我们的答案就是 d p 1 2 + max { d p 2 3 , d p 2 4 , d p 2 5 } dp1_2 + \max\{dp2_3,dp2_4,dp2_5\} dp12+max{dp23,dp24,dp25}。这样仍然需要 O ( n ) O(n) O(n) 才能确定,所以考虑优化。
思考,如果这个时候我们预处理出来 m x 3 = max { d p 2 3 , d p 2 4 , d p 2 5 } mx_3 = \max\{dp2_3,dp2_4,dp2_5\} mx3=max{dp23,dp24,dp25},那么就可以直接取值 d p 1 2 + m x 3 dp1_2 + mx_3 dp12+mx3,就可以 O ( 1 ) O(1) O(1) 计算答案了。
考虑一般的情况。这个时候就设 m x i mx_i mxi 为在环上从 i i i 到 d n dn dn 的 d p 2 dp2 dp2 最大值( i i i 必须是环上面的点),则对于一般的环上点 x x x,答案为 d p 1 x + m x n x t x dp1_x + mx_{nxt_x} dp1x+mxnxtx。
那么问题就转换为了如何计算 d p 1 dp1 dp1 和 d p 2 dp2 dp2 和 m x mx mx。前两者很容易计算,后面的只需要在深搜树回溯的时候记录一下就可以了。
然后你开心的一交,发现并不能得到满分。
为什么?
注意,我们前面说的 x , y x,y x,y 一直都是环上面的点。但是还忽略了一种情况:还可以从 u p up up 向上面走 u p up up 的祖先,也就是 u p up up 是向上走出环的。
Q:为什么向上走出环是不正确的?
A:因为 u p up up 只记录了其非环子树的最大向下距离,而没有记录向上的距离。 例如这样:
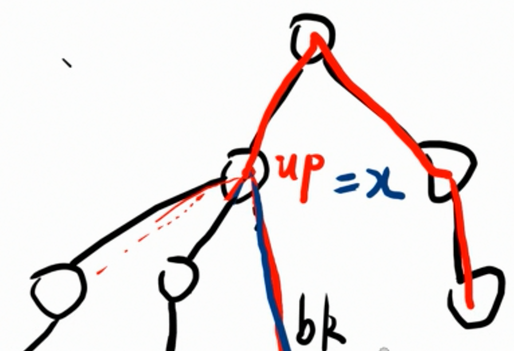
ps:你可能会想到 y = d n y = dn y=dn 的方法也不可以。但是仔细考虑一下, d n dn dn 还是从它的子树里面找一条最长路径,再不济也是 d p 2 y = 0 dp2_y = 0 dp2y=0,而这样并不会使求出来的直径变小。
考虑如何避免这种情况。显然可以换根,但是这里不采用这种方法。这里我们采用上面讲过的另一种方法,把 u p up up 下面的环也当作 u p up up 子树的一部分。
考虑将每一个路径的处理放在路径中所达到的最高的点。
然后我们就可以发现,从 u p up up 向上面走祖先的路径实际上可以不归 u p up up 管,而可以归 u p up up 的祖先管。而 u p up up 的祖先就和环没有任何关系了,可以直接取子树内的点到自己的路径长度的最大和次大值,这是一个完全 normal 的树上动态规划。
而 u p up up 要回溯的时候,也直接汇报一个到自己路径长度最大值即可。而这个路径长度最大值可以由 m x mx mx 数组的值和环点树的最大长度联合得出。
P4381 代码实现
观察样例,发现有一点点细节:有时候这个环是重边环。这个时候可以直接取较大权的边即可。具体地,对每一个点的边的权值从大到小排序。
#include <bits/stdc++.h>
#define int long long
using namespace std;
int n;
const int N = 1000010;
vector<pair<int, int> > v[N];
bool cmp(pair<int, int> x, pair<int, int> y) {
return x.second > y.second;
}
int d, up, dn;
int bk, mx;
bool vis[N], stk[N], cir[N];
int lv[N], dep[N];
void dfs(int u, int pre, int l) {
vis[u] = stk[u] = 1, lv[u] = l;
int mx1 = 0, mx2 = 0, siz = 0;
for (auto [x, y] : v[u])
if (!vis[x]) {
dfs(x, u, l + y);
if (dep[x] + y > mx1)
mx2 = mx1, mx1 = dep[x] + y;
else if (dep[x] + y > mx2)
mx2 = dep[x] + y;
if (cir[x] && x != up)
cir[u] = 1;
else
siz = max(siz, dep[x] + y);
} else if (stk[x] && x != pre)
up = x, dn = u, bk = y, cir[u] = 1;
dep[u] = mx1, d = max(d, mx1 + mx2);
if (cir[u]) {
d = max(d, bk + mx + lv[u] - lv[up] + siz);
if (u == up)
dep[u] = max(dep[u], mx + bk);
else
mx = max(mx, lv[dn] - lv[u] + siz);
}
stk[u] = 0;
}
signed main() {
cin >> n;
for (int i = 1; i <= n; i++) {
int x, w;
cin >> x >> w;
v[i].push_back({x, w});
v[x].push_back({i, w});
}
for (int i = 1; i <= n; i++)
sort(v[i].begin(), v[i].end(), cmp);
int ans = 0;
for (int i = 1; i <= n; i++)
if (!vis[i])
d = 0, up = -1, bk = 0, mx = -9e18, dfs(i, 0, 0), ans += d;//这里的初始化一定要写全(差点被误导了)
cout << ans << endl;
return 0;
}