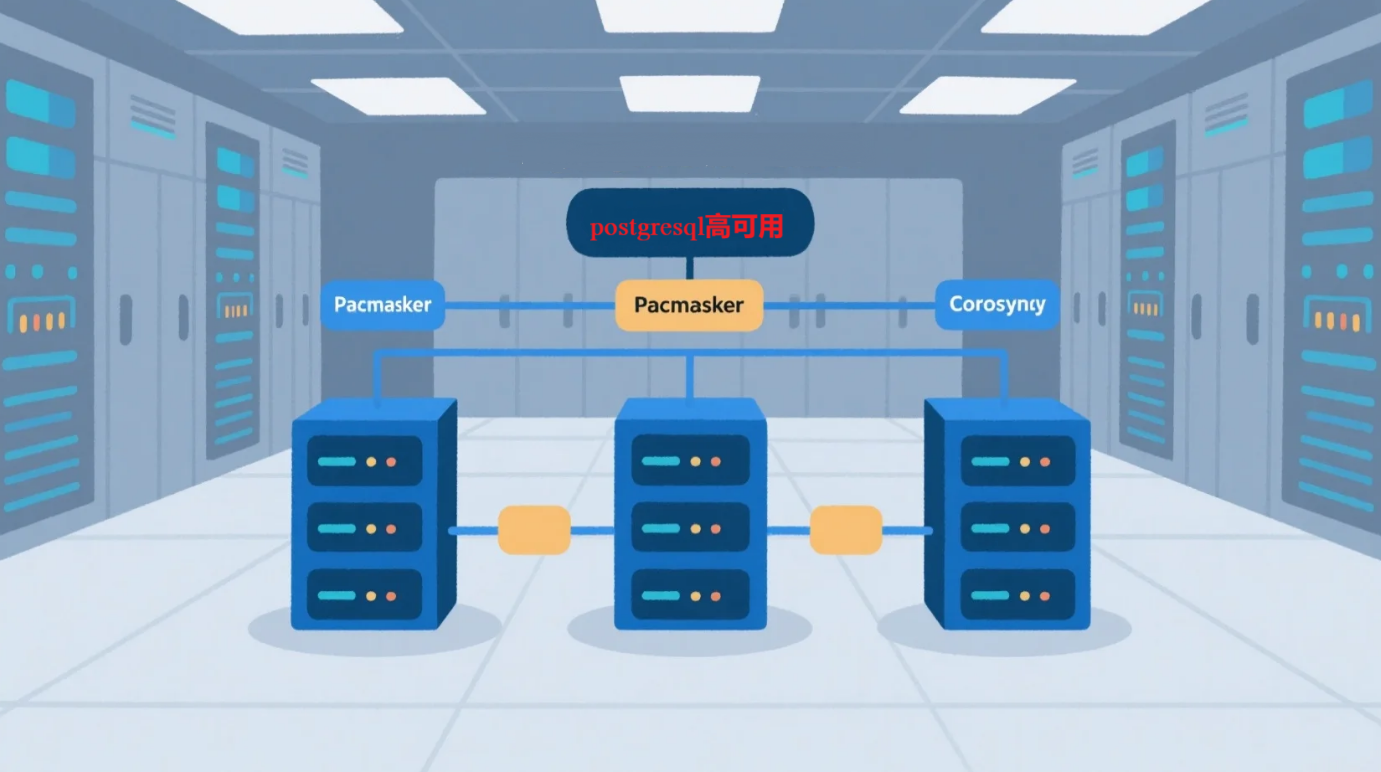
核心架构原理
集群组成(典型三节点结构):
[Node1] PostgreSQL + Pacemaker + Corosync + pcsd
[Node2] PostgreSQL + Pacemaker + Corosync + pcsd
[Node3] PostgreSQL + Pacemaker + Corosync + pcsd
↕ ↕ ↕
← Corosync 多播/单播心跳通信 →
↕ ↕ ↕
Pacemaker 资源调度器决定主从角色、服务状态、VIP绑定位置
组件介绍
组件 |
作用 |
PostgreSQL 14 |
数据库核心,负责数据存储与复制。 |
Pacemaker |
集群资源管理器,负责数据库服务、VIP 等资源的启停与主备切换。 |
Corosync |
集群通信组件,提供节点间心跳和消息广播机制。 |
pcsd |
Web UI + CLI 集群管理组件,简化 pcs 工具使用,提供节点认证与配置同步。 |
系统资源及组件规划
节点名称 |
CPU/内存 |
网卡 |
硬盘 |
IP地址 |
OS |
节点角色 |
pgtest1 |
2c/2g |
ens33 |
60G |
192.168.24.11 |
Centos7.9 |
PostgreSQL、Pacemaker、Corosync |
pgtest2 |
2c/2g |
ens33 |
60G |
192.168.24.12 |
Centos7.9 |
|
pgtest3 |
2c/2g |
ens33 |
60G |
192.168.24.13 |
Centos7.9 |
|
vip-master |
192.168.24.14 |
|||||
vip-slave |
192.168.24.15 |
|||||
数据库版本:
Postgresql14.6
PCS集群版本:
#rpm -qa|grep pacemaker
pacemaker-libs-1.1.23-1.el7_9.1.x86_64
pacemaker-cluster-libs-1.1.23-1.el7_9.1.x86_64
pacemaker-1.1.23-1.el7_9.1.x86_64
pacemaker-cli-1.1.23-1.el7_9.1.x86_64
#rpm -qa|grep pcs
pcsc-lite-libs-1.8.8-8.el7.x86_64
pcs-0.9.169-3.el7.centos.3.x86_64
# rpm -qa|grep corosync
corosync-2.4.5-7.el7_9.2.x86_64
corosynclib-2.4.5-7.el7_9.2.x86_64
一、安装基础软件
1.1 配置hosts文件[all servers]
[root@pgtest1 ~]# cat >> /etc/hosts <<EOF
192.168.24.11 pgtest1
192.168.24.12 pgtest2
192.168.24.13 pgtest3
192.168.24.14 vip-master
192.168.24.15 vip-slave
EOF
1.2 关闭防火墙及selinux [all servers]
# systemctl disable firewalld
# systemctl stop firewalld
#vi /etc/selinux/config
selinux=disabled
# sestatus
SELinux status: disabled
1.3 安装PCS [all servers]
yum -y install libsmb*
yum install -y pacemaker pcs
yum install -y autoconf automake libtool
yum install -y docbook-style-xsl
yum install -y gcc-c++ glib2-devel
1.4 pacemaker resource-agents 更新 [all servers]
注:centos7.9 yum安装集群软件只支持pg9、pg10以下,需要安装新版本resource-agents,如下:
resource-agents-4.12.0下载地址: Release v4.12.0 · ClusterLabs/resource-agents · GitHub
# tar zxvf resource-agents-4.12.0.tar.gz
# cd resource-agents-4.12.0
# ./autogen.sh
# ./configure
# make && make install
确认支持PG12以上版本
[root@pgtest1 ~]# cat /usr/lib/ocf/resource.d/heartbeat/pgsql | grep ocf_version_cmp
ocf_version_cmp "$version" "9.3"
ocf_version_cmp "$version" "12"
ocf_version_cmp "$version" "10"
ocf_version_cmp "$version" "9.4"
ocf_version_cmp "$OCF_RESKEY_crm_feature_set" "3.1.0"
ocf_version_cmp "$OCF_RESKEY_crm_feature_set" "3.2.0"
1.5 pcsd[all servers]
# echo "hacluster"| passwd --stdin hacluster #设置hacluster用户密码
1.6 安装postgresql数据库软件 [all servers]
#使用脚本一键安装,可忽略以下步骤。
--安装依赖包:
yum install -y perl-ExtUtils-Embed readline zlib-devel pam-devel libxml2-devel libxslt-devel openldap-devel python-devel gcc-c++ openssl-devel cmake gcc* readline-devel zlib bison flex bison-devel flex-devel openssl openssl-devel
--创建用户、组
groupadd -g 666 postgres
useradd -g postgres -u 666 postgres
echo "postgres"| passwd --stdin postgres
--创建目录
mkdir -p /postgresql/{pg14,pgdata,arch,soft}
chown -R postgres. /postgresql
chmod -R 700 /postgresql
--上传解压安装包
tar zxvf postgresql-14.6.tar.gz
--编译安装
[root@pgtest1 soft]# su - postgres
Last login: Fri May 5 16:39:55 CST 2023 on pts/2
[postgres@pgtest1 ~]$ cd /postgresql/soft/
[postgres@pgtest1 soft]$ cd postgresql-14.6/
[postgres@pgtest1 postgresql-14.6]$ ls
aclocal.m4 config config.log config.status configure configure.ac contrib COPYRIGHT doc GNUmakefile GNUmakefile.in HISTORY INSTALL Makefile README src
[postgres@pgtest1 postgresql-14.6]$ ./configure --prefix=/postgresql/pg14 --with-pgport=5432
[postgres@pgtest1 postgresql-14.6]$ make world &&make install-world
1.7 service setup [all servers]
systemctl disable corosync
systemctl disable pacemaker
systemctl enable pcsd.service
systemctl start pcsd.service
--查看服务启动状态
systemctl status corosync pacemaker pcsd.service
1.8 cluster auth[any one host]
#pcs cluster auth pgtest1 pgtest2 pgtest3 -u hacluster -p "hacluster"
pgtest2: Authorized
pgtest3: Authorized
pgtest1: Authorized
#在任意节点上启用集群认证
1.9 设置数据库集群[any one host]
#### 配置集群节点 ####
(选择master执行)
#pcs cluster setup --name pgcluster pgtest1 pgtest2 pgtest3
Destroying cluster on nodes: pgtest1, pgtest2, pgtest3...
pgtest1: Stopping Cluster (pacemaker)...
pgtest2: Stopping Cluster (pacemaker)...
pgtest3: Stopping Cluster (pacemaker)...
pgtest3: Successfully destroyed cluster
pgtest1: Successfully destroyed cluster
pgtest2: Successfully destroyed cluster
Sending 'pacemaker_remote authkey' to 'pgtest1', 'pgtest2', 'pgtest3'
pgtest1: successful distribution of the file 'pacemaker_remote authkey'
pgtest2: successful distribution of the file 'pacemaker_remote authkey'
pgtest3: successful distribution of the file 'pacemaker_remote authkey'
Sending cluster config files to the nodes...
pgtest1: Succeeded
pgtest2: Succeeded
pgtest3: Succeeded
Synchronizing pcsd certificates on nodes pgtest1, pgtest2, pgtest3...
pgtest2: Success
pgtest3: Success
pgtest1: Success
Restarting pcsd on the nodes in order to reload the certificates...
pgtest2: Success
pgtest3: Success
pgtest1: Success
#### 启动所有集群节点 ####
(选择master执行)
# pcs cluster start --all
pgtest1: Starting Cluster (corosync)...
pgtest2: Starting Cluster (corosync)...
pgtest3: Starting Cluster (corosync)...
pgtest3: Starting Cluster (pacemaker)...
pgtest1: Starting Cluster (pacemaker)...
pgtest2: Starting Cluster (pacemaker)...
#### 检查集群状态 ####
# pcs status --full
Cluster name: pgcluster
WARNINGS:
No stonith devices and stonith-enabled is not false
Stack: corosync
Current DC: pgtest3 (3) (version 1.1.23-1.el7_9.1-9acf116022) - partition with quorum
Last updated: Mon Oct 9 09:58:45 2023
Last change: Mon Oct 9 09:55:47 2023 by hacluster via crmd on pgtest3
3 nodes configured
0 resource instances configured
Online: [ pgtest1 (1) pgtest2 (2) pgtest3 (3) ]
No resources
Node Attributes:
* Node pgtest1 (1):
* Node pgtest2 (2):
* Node pgtest3 (3):
Migration Summary:
* Node pgtest3 (3):
* Node pgtest1 (1):
* Node pgtest2 (2):
Fencing History:
PCSD Status:
pgtest1: Online
pgtest2: Online
pgtest3: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
1.10 数据库环境变量设置[all servers]
[root@pgtest1 soft]# su - postgres
Last login: Fri May 5 17:18:28 CST 2023 on pts/3
[postgres@pgtest1 ~]$ cat .bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/.local/bin:$HOME/bin
export PATH
export PGHOME=/postgresql/pg14
export PGDATA=/postgresql/pgdata
export PATH=$PGHOME/bin:$PATH
export LD_LIBRARY_PATH=$PGHOME/lib:$LD_LIBRARY_PATH
1.11 primary数据库配置 [pgtest1]
#### pgtest1 ####
1).初始化数据库
# su - postgres
$ initdb -D $PGDATA
2).配置主机访问
修改 pg_hba.conf
sed -i '/^host[[:space:]]\+all[[:space:]]\+all[[:space:]]\+127\.0\.0\.1\/32[[:space:]]\+trust/i host all all 0.0.0.0/0 scram-sha-256' /postgresql/pgdata/pg_hba.conf
sed -i '/^host[[:space:]]\+replication[[:space:]]\+all[[:space:]]\+127\.0\.0\.1\/32[[:space:]]\+trust/i host replication all 0.0.0.0/0 scram-sha-256' /postgresql/pgdata/pg_hba.conf
3).配置数据库参数
cat <<EOF >> /postgresql/pgdata/postgresql.conf
# Custom settings appended by script
listen_addresses = '*'
wal_keep_size = 10240 # 单位MB
log_destination = 'csvlog'
logging_collector = on
archive_mode = on
archive_command = 'cp %p /postgresql/arch/%f'
EOF
4).修改用户默认密码
[postgres@pgtest1 pgdata]$ pg_ctl start
[postgres@pgtest1 pgdata]$ psql -c "alter user postgres password 'postgres'";
1.12 创建secondary数据库 [pgtest2]
[postgres@pgtest2 pgdata]$ pg_basebackup -h pgtest1 -U repl -D /postgresql/pgdata/ -Fp -Pv -Xs
#无需启动
1.13 创建third数据库 [pgtest3]
[postgres@pgtest3 pgdata]$ pg_basebackup -h pgtest1 -U repl -D /postgresql/pgdata/ -Fp -Pv -Xs
#无需启动
1.14 停止primary数据库 [pgtest1]
$ pg_ctl stop
waiting for server to shut down.... done
server stopped
二、配置pacemaker数据库集群 [any one host] (一个节点配置即可,会自动同步到另外一个节点,master节点执行)
2.1 检查集群状态
[root@pgtest1 resource-agents-4.12.0]# pcs status
Cluster name: cluster_pg01
WARNINGS:
No stonith devices and stonith-enabled is not false
Stack: corosync
Current DC: pgtest1 (version 1.1.23-1.el7_9.1-9acf116022) - partition with quorum
Last updated: Fri May 9 12:21:03 2025
Last change: Fri May 9 12:14:30 2025 by hacluster via crmd on pgtest1
3 nodes configured
0 resource instances configured
Online: [ pgtest1 pgtest2 pgtest3 ]
No resources
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
2.2 创建集群文件
[root@pgtest1 resource-agents-4.12.0]# pcs cluster cib cib.xml
2.3 配置数据库资源
-- property: cluster-name --
# pcs -f cib.xml property set cluster-name="pgcluster"
-- property: disable stonith, quorum --
# pcs -f cib.xml property set no-quorum-policy="ignore"
# pcs -f cib.xml property set stonith-enabled="false"
-- resource: vip-master --
# pcs -f cib.xml resource create vip-master ocf:heartbeat:IPaddr2 ip=192.168.24.14 cidr_netmask=24 nic=ens33 iflabel=master op monitor interval=5s
-- resource: vip-slave --
# pcs -f cib.xml resource create vip-slave ocf:heartbeat:IPaddr2 ip=192.168.24.15 cidr_netmask=24 nic=ens33 iflabel=slave op monitor interval=5s
-- resource: pgsql --
# pcs -f cib.xml resource create pgsql ocf:heartbeat:pgsql\
pgctl="/postgresql/pg14/bin/pg_ctl"\
psql="/postgresql/pg14/bin/psql"\
pgdata="/postgresql/pgdata"\
node_list="pgtest1 pgtest2 pgtest3"\
restore_command=""\
master_ip="192.168.24.14"\
repuser="postgres"\
rep_mode="sync"\
primary_conninfo_opt="password=postgres keepalives_idle=60 keepalives_interval=5 keepalives_count=5"\
op monitor interval="11s"\
op monitor interval="10s" role="Master"\
master master-max=1 master-node-max=1 clone-max=3 clone-node-max=1 notify=true target-role='Started'
-- constraint: vip-master, pgsql on master node --
# pcs -f cib.xml constraint colocation add vip-master with master pgsql-master INFINITY
-- constraint: pgsql promote node MasterGroup --
# pcs -f cib.xml constraint order promote pgsql-master then start vip-master symmetrical=false score=INFINITY
-- constraint: pgsql demote node MasterGroup --
# pcs -f cib.xml constraint order demote pgsql-master then stop vip-master symmetrical=false score=0
-- constraint: vip-slave sync standby 、sync standby on master --
# pcs -f cib.xml constraint location vip-slave rule score=200 pgsql-status eq HS:sync
# pcs -f cib.xml constraint location vip-slave rule score=100 pgsql-status eq PRI
# pcs -f cib.xml constraint location vip-slave rule score=-INFINITY not_defined pgsql-status
# pcs -f cib.xml constraint location vip-slave rule score=-INFINITY pgsql-status ne HS:sync and pgsql-status ne PRI
-- cluster: push cib file into cib --
# pcs cluster cib-push cib.xml
2.4 刷新集群状态
# pcs resource refresh --full
Waiting for 1 reply from the CRMd. OK
2.5 查询集群状态
[root@pgtest1 ~]# pcs status --full #需要等待几秒或者多刷新几次
Cluster name: pgcluster
Stack: corosync
Current DC: pgtest3 (3) (version 1.1.23-1.el7_9.1-9acf116022) - partition with quorum
Last updated: Fri May 9 12:35:17 2025
Last change: Fri May 9 12:35:11 2025 by root via crm_attribute on pgtest1
3 nodes configured
5 resource instances configured
Online: [ pgtest1 (1) pgtest2 (2) pgtest3 (3) ]
Full list of resources:
vip-master (ocf::heartbeat:IPaddr2): Started pgtest1
vip-slave (ocf::heartbeat:IPaddr2): Started pgtest2
Master/Slave Set: pgsql-master [pgsql]
pgsql (ocf::heartbeat:pgsql): Slave pgtest2
pgsql (ocf::heartbeat:pgsql): Slave pgtest3
pgsql (ocf::heartbeat:pgsql): Master pgtest1
Masters: [ pgtest1 ]
Slaves: [ pgtest2 pgtest3 ]
Node Attributes:
* Node pgtest1 (1):
+ master-pgsql : 1000
+ pgsql-data-status : LATEST
+ pgsql-master-baseline : 00000000050000A0
+ pgsql-status : PRI
* Node pgtest2 (2):
+ master-pgsql : 100
+ pgsql-data-status : STREAMING|SYNC
+ pgsql-status : HS:sync
* Node pgtest3 (3):
+ master-pgsql : -INFINITY
+ pgsql-data-status : STREAMING|ASYNC
+ pgsql-status : HS:async
Migration Summary:
* Node pgtest2 (2):
* Node pgtest3 (3):
* Node pgtest1 (1):
Fencing History:
PCSD Status:
pgtest1: Online
pgtest3: Online
pgtest2: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
--查看流复制状态
[root@pgtest1 ~]# ps -ajxf|grep postgres

---查看VIP
#master vip (write and read vip)
[root@pgtest1 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:b0:62:cd brd ff:ff:ff:ff:ff:ff
inet 192.168.24.11/24 brd 192.168.24.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.24.14/24 brd 192.168.24.255 scope global secondary ens33:master
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:feb0:62cd/64 scope link
#slave vip (read vip)
[postgres@pgtest2 ~]$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:c8:ee:12 brd ff:ff:ff:ff:ff:ff
inet 192.168.24.12/24 brd 192.168.24.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.24.15/24 brd 192.168.24.255 scope global secondary ens33:slave
valid_lft forever preferred_lft forever
inet6 fe80::15bb:4008:354c:4f0f/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[postgres@pgtest3 ~]$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:c8:ee:12 brd ff:ff:ff:ff:ff:ff
inet 192.168.24.12/24 brd 192.168.24.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.24.15/24 brd 192.168.24.255 scope global secondary ens33:slave
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fec8:ee12/64 scope link
valid_lft forever preferred_lft forever
三、PostgreSQL故障演示
3.1 数据同步验证
--master vip连接测试
[postgres@pgtest3 ~]$ psql -h 192.168.24.14 -p5432
Password for user postgres:
psql (14.6)
Type "help" for help.
postgres=# create table t1 (id int);
CREATE TABLE
postgres=# insert into t1 values(1);
INSERT 0 1
--slave vip连接测试
[postgres@pgtest3 ~]$ psql -h 192.168.24.15 -p5432
Password for user postgres:
psql (14.6)
Type "help" for help.
postgres=# select * from t1;
id
----
1
(1 row)
postgres=# insert into t1 values(2);
ERROR: cannot execute INSERT in a read-only transaction
3.2 模拟主节点故障
[postgres@pgtest1 ~]$ pg_ctl stop
waiting for server to shut down.... done
server stopped
---查看当前节点资源状态
[root@pgtest1 ~]# crm_mon -Afr -1
Stack: corosync
Current DC: pgtest3 (version 1.1.23-1.el7_9.1-9acf116022) - partition with quorum
Last updated: Fri May 9 13:53:14 2025
Last change: Fri May 9 13:52:49 2025 by root via crm_attribute on pgtest2
3 nodes configured
5 resource instances configured
Online: [ pgtest1 pgtest2 pgtest3 ]
Full list of resources:
vip-master (ocf::heartbeat:IPaddr2): Started pgtest2
vip-slave (ocf::heartbeat:IPaddr2): Started pgtest3
Master/Slave Set: pgsql-master [pgsql]
Masters: [ pgtest2 ]
Slaves: [ pgtest3 ]
Stopped: [ pgtest1 ]
Node Attributes:
* Node pgtest1:
+ master-pgsql : -INFINITY
+ pgsql-data-status : DISCONNECT
+ pgsql-status : STOP
* Node pgtest2:
+ master-pgsql : 1000
+ pgsql-data-status : LATEST
+ pgsql-master-baseline : 00000000060000A0
+ pgsql-status : PRI
* Node pgtest3:
+ master-pgsql : 100
+ pgsql-data-status : STREAMING|SYNC
+ pgsql-status : HS:sync
Migration Summary:
* Node pgtest2:
* Node pgtest3:
* Node pgtest1:
pgsql: migration-threshold=1000000 fail-count=1000000 last-failure='Fri May 9 13:52:32 2025'
Failed Resource Actions:
* pgsql_start_0 on pgtest1 'unknown error' (1): call=55, status=complete, exitreason='My data may be inconsistent. You have to remove /var/lib/pgsql/tmp/PGSQL.lock file to force start.',
last-rc-change='Fri May 9 13:52:32 2025', queued=0ms, exec=234ms
---查看集群状态
[root@pgtest1 ~]# pcs status --all
Cluster name: pgcluster
Stack: corosync
Current DC: pgtest3 (3) (version 1.1.23-1.el7_9.1-9acf116022) - partition with quorum
Last updated: Fri May 9 13:55:31 2025
Last change: Fri May 9 13:52:49 2025 by root via crm_attribute on pgtest2
3 nodes configured
5 resource instances configured
Online: [ pgtest1 (1) pgtest2 (2) pgtest3 (3) ]
Full list of resources:
vip-master (ocf::heartbeat:IPaddr2): Started pgtest2
vip-slave (ocf::heartbeat:IPaddr2): Started pgtest3
Master/Slave Set: pgsql-master [pgsql]
pgsql (ocf::heartbeat:pgsql): Master pgtest2
pgsql (ocf::heartbeat:pgsql): Slave pgtest3
pgsql (ocf::heartbeat:pgsql): Stopped
Masters: [ pgtest2 ]
Slaves: [ pgtest3 ]
Stopped: [ pgtest1 ]
Node Attributes:
* Node pgtest1 (1):
+ master-pgsql : -INFINITY
+ pgsql-data-status : DISCONNECT
+ pgsql-status : STOP
* Node pgtest2 (2):
+ master-pgsql : 1000
+ pgsql-data-status : LATEST
+ pgsql-master-baseline : 00000000060000A0
+ pgsql-status : PRI
* Node pgtest3 (3):
+ master-pgsql : 100
+ pgsql-data-status : STREAMING|SYNC
+ pgsql-status : HS:sync
Migration Summary:
* Node pgtest2 (2):
* Node pgtest3 (3):
* Node pgtest1 (1):
pgsql: migration-threshold=1000000 fail-count=1000000 last-failure='Fri May 9 13:52:32 2025'
Failed Resource Actions:
* pgsql_start_0 on pgtest1 'unknown error' (1): call=55, status=complete, exitreason='My data may be inconsistent. You have to remove /var/lib/pgsql/tmp/PGSQL.lock file to force start.',
last-rc-change='Fri May 9 13:52:32 2025', queued=0ms, exec=234ms
Fencing History:
PCSD Status:
pgtest1: Online
pgtest2: Online
pgtest3: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
#此时集群master已自动切换至pgtest2。
--vip发生了漂移
#Master-vip漂移到pgtest2,slave-vip漂移到pgtest3。
[root@pgtest2 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:c8:ee:12 brd ff:ff:ff:ff:ff:ff
inet 192.168.24.12/24 brd 192.168.24.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.24.14/24 brd 192.168.24.255 scope global secondary ens33:master
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fec8:ee12/64 scope link
valid_lft forever preferred_lft forever
[postgres@pgtest3 ~]$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:50:60:1a brd ff:ff:ff:ff:ff:ff
inet 192.168.24.13/24 brd 192.168.24.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.24.15/24 brd 192.168.24.255 scope global secondary ens33:slave
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe50:601a/64 scope link
valid_lft forever preferred_lft forever
---恢复原master节点
注意原master节点挂掉之后,使用 crm_mon -Arf -1命令看到末尾有"You have to remove /var/lib/pgsql/tmp/PGSQL.lock file to force start."字样,master宕机启动时,需要删除临时锁文件方可进行集群角色转换。即执行rm -rf /var/lib/pgsql/tmp/PGSQL.lock
[root@pgtest1 ~]# ls /var/lib/pgsql/tmp/PGSQL.lock
/var/lib/pgsql/tmp/PGSQL.lock
[postgres@pgtest1 ~]$ rm -rf /var/lib/pgsql/tmp/PGSQL.lock
拉起数据库不需要执行pg_ctl start,只需重启服务,软件会自动把数据库拉起。
[root@pgtest1 tmp]# systemctl restart corosync pacemaker pcsd
---查看集群状态
[root@pgtest1 tmp]# pcs status --full
Cluster name: pgcluster
Stack: corosync
Current DC: pgtest3 (3) (version 1.1.23-1.el7_9.1-9acf116022) - partition with quorum
Last updated: Fri May 9 14:00:05 2025
Last change: Fri May 9 13:59:09 2025 by root via crm_attribute on pgtest2
3 nodes configured
5 resource instances configured
Online: [ pgtest1 (1) pgtest2 (2) pgtest3 (3) ]
Full list of resources:
vip-master (ocf::heartbeat:IPaddr2): Started pgtest2
vip-slave (ocf::heartbeat:IPaddr2): Started pgtest3
Master/Slave Set: pgsql-master [pgsql]
pgsql (ocf::heartbeat:pgsql): Master pgtest2
pgsql (ocf::heartbeat:pgsql): Slave pgtest3
pgsql (ocf::heartbeat:pgsql): Slave pgtest1
Masters: [ pgtest2 ]
Slaves: [ pgtest1 pgtest3 ]
Node Attributes:
* Node pgtest1 (1):
+ master-pgsql : -INFINITY
+ pgsql-data-status : STREAMING|ASYNC
+ pgsql-status : HS:async
* Node pgtest2 (2):
+ master-pgsql : 1000
+ pgsql-data-status : LATEST
+ pgsql-master-baseline : 00000000060000A0
+ pgsql-status : PRI
* Node pgtest3 (3):
+ master-pgsql : 100
+ pgsql-data-status : STREAMING|SYNC
+ pgsql-status : HS:sync
Migration Summary:
* Node pgtest2 (2):
* Node pgtest3 (3):
* Node pgtest1 (1):
Fencing History:
PCSD Status:
pgtest1: Online
pgtest2: Online
pgtest3: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
#pgtest1重新加入集群后变成了slave节点。
3.3 二次模拟主节点故障
[postgres@pgtest2 ~]$ pg_ctl stop
waiting for server to shut down.... done
server stopped
--查看资源状态
Stack: corosync
Current DC: pgtest3 (version 1.1.23-1.el7_9.1-9acf116022) - partition with quorum
Last updated: Fri May 9 14:02:47 2025
Last change: Fri May 9 14:02:43 2025 by root via crm_attribute on pgtest3
3 nodes configured
5 resource instances configured
Online: [ pgtest1 pgtest2 pgtest3 ]
Full list of resources:
vip-master (ocf::heartbeat:IPaddr2): Started pgtest3
vip-slave (ocf::heartbeat:IPaddr2): Started pgtest1
Master/Slave Set: pgsql-master [pgsql]
Masters: [ pgtest3 ]
Slaves: [ pgtest1 ]
Stopped: [ pgtest2 ]
Node Attributes:
* Node pgtest1:
+ master-pgsql : 100
+ pgsql-data-status : STREAMING|SYNC
+ pgsql-status : HS:sync
* Node pgtest2:
+ master-pgsql : -INFINITY
+ pgsql-data-status : DISCONNECT
+ pgsql-status : STOP
* Node pgtest3:
+ master-pgsql : 1000
+ pgsql-data-status : LATEST
+ pgsql-master-baseline : 00000000070000A0
+ pgsql-status : PRI
Migration Summary:
* Node pgtest2:
pgsql: migration-threshold=1000000 fail-count=1000000 last-failure='Fri May 9 14:02:26 2025'
* Node pgtest3:
* Node pgtest1:
Failed Resource Actions:
* pgsql_start_0 on pgtest2 'unknown error' (1): call=73, status=complete, exitreason='My data may be inconsistent. You have to remove /var/lib/pgsql/tmp/PGSQL.lock file to force start.',
last-rc-change='Fri May 9 14:02:25 2025', queued=0ms, exec=262ms
--查看集群状态
[root@pgtest2 ~]# pcs status --full
Cluster name: pgcluster
Stack: corosync
Current DC: pgtest3 (3) (version 1.1.23-1.el7_9.1-9acf116022) - partition with quorum
Last updated: Fri May 9 14:02:32 2025
Last change: Fri May 9 14:02:29 2025 by root via crm_attribute on pgtest3
3 nodes configured
5 resource instances configured
Online: [ pgtest1 (1) pgtest2 (2) pgtest3 (3) ]
Full list of resources:
vip-master (ocf::heartbeat:IPaddr2): Started pgtest3
vip-slave (ocf::heartbeat:IPaddr2): Started pgtest3
Master/Slave Set: pgsql-master [pgsql]
pgsql (ocf::heartbeat:pgsql): Master pgtest3
pgsql (ocf::heartbeat:pgsql): Slave pgtest1
pgsql (ocf::heartbeat:pgsql): Stopped
Masters: [ pgtest3 ]
Slaves: [ pgtest1 ]
Stopped: [ pgtest2 ]
Node Attributes:
* Node pgtest1 (1):
+ master-pgsql : -INFINITY
+ pgsql-data-status : DISCONNECT
+ pgsql-status : HS:alone
* Node pgtest2 (2):
+ master-pgsql : -INFINITY
+ pgsql-data-status : DISCONNECT
+ pgsql-status : STOP
* Node pgtest3 (3):
+ master-pgsql : 1000
+ pgsql-data-status : LATEST
+ pgsql-master-baseline : 00000000070000A0
+ pgsql-status : PRI
Migration Summary:
* Node pgtest2 (2):
pgsql: migration-threshold=1000000 fail-count=1000000 last-failure='Fri May 9 14:02:26 2025'
* Node pgtest3 (3):
* Node pgtest1 (1):
Failed Resource Actions:
* pgsql_start_0 on pgtest2 'unknown error' (1): call=73, status=complete, exitreason='My data may be inconsistent. You have to remove /var/lib/pgsql/tmp/PGSQL.lock file to force start.',
last-rc-change='Fri May 9 14:02:25 2025', queued=0ms, exec=262ms
Fencing History:
PCSD Status:
pgtest2: Online
pgtest1: Online
pgtest3: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
集群master已经切换到pgtest3上。
--vip发生漂移
#Master-vip漂移到pgtest3,slave-vip漂移到pgtest1。
[root@pgtest1 tmp]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:b0:62:cd brd ff:ff:ff:ff:ff:ff
inet 192.168.24.11/24 brd 192.168.24.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.24.15/24 brd 192.168.24.255 scope global secondary ens33:slave
valid_lft forever preferred_lft forever
inet6 fe80::a2cc:510c:af40:af87/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[postgres@pgtest3 ~]$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:50:60:1a brd ff:ff:ff:ff:ff:ff
inet 192.168.24.13/24 brd 192.168.24.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.24.14/24 brd 192.168.24.255 scope global secondary ens33:master
valid_lft forever preferred_lft forever
inet6 fe80::6d33:e581:1ad:cc2e/64 scope link noprefixroute
valid_lft forever preferred_lft forever
---恢复原master节点
注意原master节点挂掉之后,使用 crm_mon -Arf -1命令看到末尾有"You have to remove /var/lib/pgsql/tmp/PGSQL.lock file to force start."字样,master宕机启动时,需要删除临时锁文件方可进行集群角色转换。即执行rm -rf /var/lib/pgsql/tmp/PGSQL.lock
[root@pgtest2 ~]# ls /var/lib/pgsql/tmp/PGSQL.lock
/var/lib/pgsql/tmp/PGSQL.lock
[root@pgtest2 ~]# rm -rf /var/lib/pgsql/tmp/PGSQL.lock
拉起数据库不需要执行pg_ctl start,只需重启服务,软件会自动把数据库拉起。
[root@pgtest2 tmp]# systemctl restart corosync pacemaker pcsd
---查看集群状态
[root@pgtest2 tmp]# pcs status --full
Cluster name: pgcluster
Stack: corosync
Current DC: pgtest3 (3) (version 1.1.23-1.el7_9.1-9acf116022) - partition with quorum
Last updated: Fri May 9 14:06:50 2025
Last change: Fri May 9 14:05:22 2025 by root via crm_attribute on pgtest3
3 nodes configured
5 resource instances configured
Online: [ pgtest1 (1) pgtest2 (2) pgtest3 (3) ]
Full list of resources:
vip-master (ocf::heartbeat:IPaddr2): Started pgtest3
vip-slave (ocf::heartbeat:IPaddr2): Started pgtest1
Master/Slave Set: pgsql-master [pgsql]
pgsql (ocf::heartbeat:pgsql): Slave pgtest2
pgsql (ocf::heartbeat:pgsql): Master pgtest3
pgsql (ocf::heartbeat:pgsql): Slave pgtest1
Masters: [ pgtest3 ]
Slaves: [ pgtest1 pgtest2 ]
Node Attributes:
* Node pgtest1 (1):
+ master-pgsql : 100
+ pgsql-data-status : STREAMING|SYNC
+ pgsql-status : HS:sync
* Node pgtest2 (2):
+ master-pgsql : -INFINITY
+ pgsql-data-status : STREAMING|ASYNC
+ pgsql-status : HS:async
* Node pgtest3 (3):
+ master-pgsql : 1000
+ pgsql-data-status : LATEST
+ pgsql-master-baseline : 00000000070000A0
+ pgsql-status : PRI
Migration Summary:
* Node pgtest2 (2):
* Node pgtest3 (3):
* Node pgtest1 (1):
Fencing History:
PCSD Status:
pgtest1: Online
pgtest3: Online
pgtest2: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
pgtest2重新加入集群后,变成了slave节点。
依此操作,执行多次mster切换,master节点会在pgtest1、pgtest2、pgtest3循环切换。