对关键名词的学习——大白话观念
1. 梯度下降的思想
想象你在一座大山上,目标是找到山的最低点。梯度下降就像是你找下山路径的方法。在数学里,梯度表示函数增长最快的方向,那梯度下降就是朝着函数值下降最快的方向走。在机器学习里,很多时候我们要找一个能让损失函数值最小的参数组合 ,就通过不断按照梯度下降的方向去调整参数,一步步接近最优解,就像一步步往山下走到最低点。
2. 激活函数的作用
神经网络里神经元之间传递信息,就像电路里信号传递。但如果只是简单传递,很多复杂情况就处理不了。激活函数就像一个特殊开关,它能把神经元接收到的信号做个加工转换。比如,让信号变得非线性,这样神经网络就能处理像图像识别、语音识别这种复杂的非线性问题了。要是没有激活函数,神经网络就只能处理简单的线性关系,能力就大打折扣。
3. 损失函数的作用
损失函数用来衡量模型预测结果和真实结果之间的差距。比如你用模型预测明天股票价格,预测值和实际值肯定可能不一样,差距大小就用损失函数算出来。模型训练的目的就是让损失函数值越小越好。就像射箭,真实结果是靶心,预测结果是箭落点,损失函数就是衡量箭离靶心有多远,训练模型就是不断调整让箭更靠近靶心。
4. 优化器
优化器是帮我们调整模型参数的工具。前面说要让损失函数值变小,怎么变呢?优化器就负责具体操作。它根据损失函数计算出的结果,决定怎么调整参数,用什么方式、多大步长去调整。就像开车调整方向盘,优化器就是那个手,根据和目标路线的差距,决定怎么打方向盘,让车往正确方向走,对应到模型里就是让参数调整到能让损失函数最小。
5. 神经网络的概念
神经网络是模仿人脑神经元结构和工作方式的一种算法模型。人脑里神经元互相连接传递信息,神经网络里就是一个个节点(类似神经元),这些节点按层组织起来,有输入层接收数据,中间层(隐藏层)处理数据,输出层给出结果。数据在这些层里流动,经过各种计算和转换,就能实现像图像分类、语言翻译这些复杂功能。
最后说神经网络封装浅,是说它不像有些简单机器学习算法,就固定那几步操作。神经网络内部结构灵活,你可以调整层数、节点数,换激活函数、优化器等等,能从很多方面去改进它,让它更适应不同任务和数据。
下面配置新环境
出现小插曲,由于之前挂梯子开的代理,然后昨天电脑关机了,梯子今天没开,导致此原因,然后进入到电脑中的网络中将代理关掉即可进行下载。
下载成功。
安装期间不能将示例代码打开,否则将阻断pytorch的下载
以下为一个神经网络的训练代码,该代码纯手敲,看着示例代码敲的,初见端倪,在训练结果中发现训练效果有些许变化,且每一次都不一样。
# ------------------- 数据准备部分 -------------------
# 我们使用有 4 个特征、3 个类别的鸢尾花数据集作为本次训练的数据
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
# 加载鸢尾花数据集
# load_iris() 是 sklearn 提供的函数,用于加载鸢尾花数据集
iris = load_iris()
# 提取数据集中的特征数据
X = iris.data
# 提取数据集中的标签数据
y = iris.target
# 将数据集划分为训练集和测试集
# test_size=0.2 表示将 20% 的数据作为测试集,random_state=42 用于保证结果可重复
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 打印训练集和测试集的特征和标签的尺寸,方便我们确认数据划分是否正确
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
# 对数据进行归一化处理
# 神经网络对输入数据的尺度比较敏感,归一化是常见的处理方法
from sklearn.preprocessing import MinMaxScaler
# 创建 MinMaxScaler 实例,用于将数据缩放到 [0, 1] 区间
scaler = MinMaxScaler()
# 对训练集进行拟合和转换
X_train = scaler.fit_transform(X_train)
# 使用训练集的缩放规则对测试集进行转换
X_test = scaler.transform(X_test)
# 将数据转换为 PyTorch 张量,因为 PyTorch 模型使用张量进行训练
# y_train 和 y_test 是整数标签,需要转换为 long 类型
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.LongTensor(y_test)
# ------------------- 模型架构定义部分 -------------------
# 定义一个简单的全连接神经网络模型(Multi-Layer Perceptron,多层感知机)
# 包含一个输入层、一个隐藏层和一个输出层
class MLP(nn.Module):
def __init__(self):
# 调用父类 nn.Module 的构造函数
super(MLP, self).__init__()
# 定义输入层到隐藏层的线性变换
# 输入特征有 4 个,隐藏层有 10 个神经元
self.fc1 = nn.Linear(4, 10)
# 定义激活函数 ReLU,增加模型的非线性能力
self.relu = nn.ReLU()
# 定义隐藏层到输出层的线性变换
# 隐藏层有 10 个神经元,输出有 3 个类别
self.fc2 = nn.Linear(10,3)
# 输出层不需要激活函数,因为后续使用的交叉熵损失函数内部包含了 softmax 函数
def forward(self, x):
# 输入数据经过输入层到隐藏层的线性变换
out = self.fc1(x)
# 经过 ReLU 激活函数处理
out = self.relu(out)
# 经过隐藏层到输出层的线性变换
out = self.fc2(out)
return out
# ------------------- 模型训练部分 -------------------
# 实例化模型
model = MLP()
# 定义损失函数和优化器
# 对于分类问题,我们使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 使用随机梯度下降(SGD)优化器,学习率设置为 0.01
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 开始训练模型
# 定义训练的轮数
num_epochs = 20000
# 用于存储每一轮训练的损失值
losses = []
for epoch in range(num_epochs):
# 前向传播
# 调用模型的 forward 方法,计算模型的输出
outputs = model.forward(X_train)
# 计算损失值,outputs 是模型的输出,y_train 是真实标签
loss = criterion(outputs, y_train)
# 反向传播和优化
# 清空优化器中的梯度信息,因为 PyTorch 会累加梯度
optimizer.zero_grad()
# 反向传播计算梯度
loss.backward()
# 根据计算得到的梯度更新模型的参数
optimizer.step()
# 记录当前轮的损失值
# loss.item() 用于将损失值从张量转换为 Python 标量
losses.append(loss.item())
# 每训练 10000 轮,打印一次训练信息
if (epoch + 1) % 10000 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
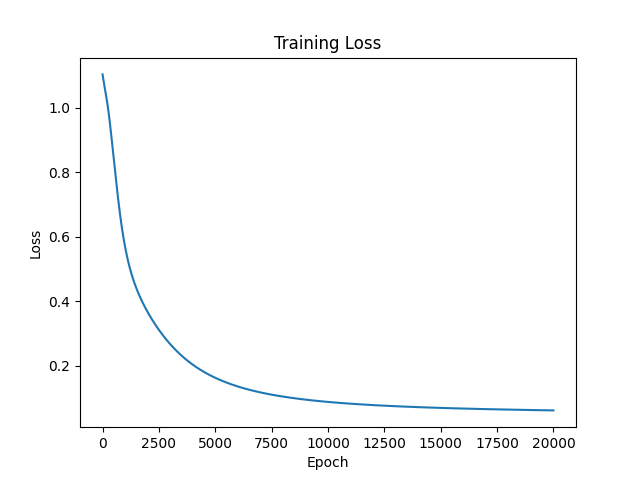
# ------------------- 可视化结果部分 -------------------
# 导入 matplotlib 库用于可视化
import matplotlib.pyplot as plt
# 绘制训练损失曲线
plt.plot(range(num_epochs), losses)
# 设置 x 轴标签
plt.xlabel('Epoch')
# 设置 y 轴标签
plt.ylabel('Loss')
# 设置图表标题
plt.title('Training Loss')
# 显示图表
plt.show()
(120, 4)
(120,)
(30, 4)
(30,)
Epoch [10000/20000], Loss: 0.0884
Epoch [20000/20000], Loss: 0.0622
PS C:\Users\I.Love.I\Desktop\Python_code> & c:/Users/I.Love.I/.conda/envs/DL/python.exe c:/Users/I.Love.I/Desktop/Python_code/python60-days-challenge/python-learning-library/Day33.py
(120, 4)
(120,)
(30, 4)
(30,)
Epoch [10000/20000], Loss: 0.0876
Epoch [20000/20000], Loss: 0.0623