TaskAlignedAssigner 原理和代码
原理主要是结合预测的分类分数和边界框与真实标注的信息,找出与真实目标最匹配的锚点,为这些锚点分配对应的目标标签、边界框和分数。
TaskAlignedAssigner 是目标检测中用于对齐分类和定位任务的样本分配器。其核心思想是通过综合分类得分和预测框与真实框的 IoU,动态选择最合适的锚点作为正样本。具体步骤如下:
计算 IoU:预测框与真实框之间的 IoU。
提取分类得分:根据真实框的类别,提取对应类别的分类得分。
任务对齐指标:计算每个锚点的任务对齐指标,公式为:
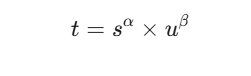
其中, α \alpha α 和 β \beta β 是超参数,用于平衡分类和定位的重要性。
中心约束:过滤掉锚点中心不在真实框内的候选。
动态 Top-k 选择:对每个真实框,选择任务对齐指标最高的前 k k k 个锚点作为正样本。
冲突处理:若一个锚点被多个真实框选中,保留指标最高的分配。
import torch
import torch.nn as nn
def pairwise_iou(boxes1, boxes2):
"""
计算两组框之间的 IoU。
Args:
boxes1 (Tensor): (N, 4) 格式为 xyxy
boxes2 (Tensor): (M, 4) 格式为 xyxy
Returns:
iou (Tensor): (N, M)
"""
lt = torch.max(boxes1[:, None, :2], boxes2[:, :2])
rb = torch.min(boxes1[:, None, 2:], boxes2[:, 2:])
wh = (rb - lt).clamp(min=0)
inter = wh[:, :, 0] * wh[:, :, 1]
area1 = (boxes1[:, 2] - boxes1[:, 0]) * (boxes1[:, 3] - boxes1[:, 1])
area2 = (boxes2[:, 2] - boxes2[:, 0]) * (boxes2[:, 3] - boxes2[:, 1])
union = area1[:, None] + area2 - inter
return inter / (union + 1e-9)
class TaskAlignedAssigner(nn.Module):
def __init__(self, topk=13, alpha=1.0, beta=6.0):
super().__init__()
# 初始化超参数
self.topk = topk # 每个真实框(GT)最多选择的正样本锚点数量,默认13
self.alpha = alpha # 分类得分的指数权重,用于平衡分类任务的重要性,默认1.0
self.beta = beta # IoU的指数权重,用于平衡定位任务的重要性,默认6.0
@torch.no_grad()
def forward(self, cls_scores, bbox_preds, gt_bboxes, gt_labels):
"""
输入:
cls_scores : (B, num_anchors, num_classes) 模型输出的分类得分(未归一化)
bbox_preds : (B, num_anchors, 4) 模型输出的预测框坐标(xyxy格式)
gt_bboxes : (B, num_gts, 4) 真实框坐标(xyxy格式)
gt_labels : (B, num_gts) 真实框的类别标签(0~num_classes-1)
输出:
pos_anchor_indices : (batch_idx, anchor_idx) 正样本锚点的批次索引和锚点索引
pos_gt_indices : (gt_idx,) 对应的真实框索引
pos_labels : (label,) 正样本的类别标签
"""
# 获取输入张量的维度信息
batch_size, num_anchors, _ = cls_scores.shape # B=批次大小, num_anchors=锚点总数
device = cls_scores.device # 设备信息(CPU/GPU)
# 初始化分配结果张量(记录每个锚点分配的GT索引和类别)
assigned_gt_inds = torch.zeros(
(batch_size, num_anchors),
dtype=torch.long,
device=device
) # Shape: (B, num_anchors),0表示未分配,非零值表示分配的GT索引+1(避免与0冲突)
assigned_labels = torch.zeros(
(batch_size, num_anchors),
dtype=torch.long,
device=device
) # Shape: (B, num_anchors),记录分配的类别标签
# 逐样本处理(每个批次独立处理)
for b in range(batch_size):
# 提取当前样本的预测框、真实框和类别标签
bbox_pred = bbox_preds[b] # (num_anchors,4) 当前批次的所有锚点预测框
gt_bbox = gt_bboxes[b] # (num_gts,4) 当前批次的所有真实框
gt_label = gt_labels[b] # (num_gts) 当前批次的所有真实框类别
num_gts = gt_bbox.size(0) # 当前样本的真实框数量
# 若当前样本没有真实框,跳过处理
if num_gts == 0:
continue
###################################################################
# Step 1: 计算预测框与真实框的 IoU
###################################################################
# 输入: bbox_pred (num_anchors,4), gt_bbox (num_gts,4)
# 输出: iou (num_anchors, num_gts),每个元素为锚点与GT的IoU
iou = pairwise_iou(bbox_pred, gt_bbox)
###################################################################
# Step 2: 提取对应真实框类别的分类得分
###################################################################
# cls_scores[b]的shape为 (num_anchors, num_classes)
# gt_label的shape为 (num_gts),每个元素是对应GT的类别索引
# 通过高级索引提取每个锚点在对应GT类别上的得分
# 结果scores的shape为 (num_anchors, num_gts)
scores = cls_scores[b][:, gt_label]
###################################################################
# Step 3: 计算任务对齐指标(分类得分^α * IoU^β)
###################################################################
alignment_metrics = scores.pow(self.alpha) * iou.pow(self.beta)
# alignment_metrics的shape: (num_anchors, num_gts)
###################################################################
# Step 4: 中心点约束(过滤锚点中心不在GT内部的候选)
###################################################################
# 计算锚点中心坐标
cx = (bbox_pred[:, 0] + bbox_pred[:, 2]) / 2 # (num_anchors,)
cy = (bbox_pred[:, 1] + bbox_pred[:, 3]) / 2 # (num_anchors,)
# 判断锚点中心是否在GT框内(利用广播机制)
# cx[:, None]的shape: (num_anchors,1)
# gt_bbox[None, :, 0]的shape: (1, num_gts)
# 比较操作后,in_gt的shape为 (num_anchors, num_gts)
in_gt = (cx[:, None] >= gt_bbox[None, :, 0]) & \
(cx[:, None] <= gt_bbox[None, :, 2]) & \
(cy[:, None] >= gt_bbox[None, :, 1]) & \
(cy[:, None] <= gt_bbox[None, :, 3])
# 将不在GT内的锚点指标置零
alignment_metrics *= in_gt.float() # (num_anchors, num_gts)
###################################################################
# Step 5: 动态选择每个GT的Top-k锚点
###################################################################
candidate_metrics = [] # 保存所有候选锚点的指标值(多个张量)
candidate_gt_indices = [] # 保存候选锚点对应的GT索引(平铺列表)
candidate_anchor_indices = [] # 保存候选锚点的索引(多个张量)
# 遍历每个真实框(GT)
for gt_idx in range(num_gts):
# 提取当前GT对应的所有锚点指标
metrics = alignment_metrics[:, gt_idx] # (num_anchors,)
# 筛选有效锚点(指标>0表示中心在GT内且指标非零)
valid = metrics > 0 # (num_anchors,)
if not valid.any(): # 若没有有效锚点,跳过该GT
continue
# 确定实际选择的Top-k数量(不超过有效锚点数和预设topk)
k = min(self.topk, valid.sum().item())
# 选择当前GT的Top-k锚点(指标值和索引)
topk_metrics, topk_anchors = metrics.topk(k)
# 保存结果
candidate_metrics.append(topk_metrics) # 添加一个形状为(k,)的张量
candidate_gt_indices.extend([gt_idx] * k) # 扩展k个gt_idx元素
candidate_anchor_indices.append(topk_anchors) # 添加形状为(k,)的锚点索引
# 若当前样本无候选锚点,跳过后续处理
if not candidate_metrics:
continue
###################################################################
# Step 6: 合并候选并排序
###################################################################
# 合并所有候选指标
candidate_metrics = torch.cat(candidate_metrics) # (total_candidates,)
# 转换GT索引为张量(total_candidates,)
candidate_gt_indices = torch.tensor(
candidate_gt_indices,
dtype=torch.long,
device=device
)
# 合并所有候选锚点索引
candidate_anchor_indices = torch.cat(candidate_anchor_indices) # (total_candidates,)
# 按指标降序排序(从高到低)
sorted_idx = candidate_metrics.argsort(descending=True) # (total_candidates,)
candidate_gt_indices = candidate_gt_indices[sorted_idx] # 按排序调整GT索引
candidate_anchor_indices = candidate_anchor_indices[sorted_idx] # 按排序调整锚点索引
###################################################################
# Step 7: 分配正样本(解决冲突,高优先级指标优先)
###################################################################
assigned_mask = torch.zeros(
num_anchors,
dtype=torch.bool,
device=device
) # 标记锚点是否已被分配
# 按排序后的顺序遍历候选锚点
for anchor_idx, gt_idx in zip(candidate_anchor_indices, candidate_gt_indices):
if not assigned_mask[anchor_idx]:
# 记录分配的GT索引(+1避免与0冲突)
assigned_gt_inds[b, anchor_idx] = gt_idx + 1
# 记录分配的类别标签
assigned_labels[b, anchor_idx] = gt_label[gt_idx]
# 标记该锚点已分配
assigned_mask[anchor_idx] = True
###################################################################
# Step 8: 提取最终正样本信息
###################################################################
# 生成正样本的掩码(assigned_gt_inds > 0表示已分配)
pos_mask = assigned_gt_inds > 0 # (B, num_anchors)
# 获取正样本的批次索引和锚点索引(非零元素的坐标)
pos_anchor_indices = pos_mask.nonzero(as_tuple=True)
# 格式为 (batch_indices, anchor_indices),例如:(tensor([0,0,1]), tensor([5,8,3]))
# 获取对应的GT索引(需减去1恢复原始索引)
pos_gt_indices = assigned_gt_inds[pos_mask] - 1 # (num_pos_samples,)
# 获取正样本的类别标签
pos_labels = assigned_labels[pos_mask] # (num_pos_samples,)
return pos_anchor_indices, pos_gt_indices, pos_labels
使用示例
if __name__ == "__main__":
# 参数设置
batch_size = 2
num_anchors = 100 # 锚点数量
num_classes = 20 # 类别数
num_gts = 3 # 每个样本的 GT 数量
# 模拟数据
cls_scores = torch.rand(batch_size, num_anchors, num_classes) # 随机分类得分
bbox_preds = torch.rand(batch_size, num_anchors, 4) * 100 # 随机预测框(xyxy)
gt_bboxes = torch.rand(batch_size, num_gts, 4) * 100 # 随机真实框(xyxy)
gt_labels = torch.randint(0, num_classes, (batch_size, num_gts)) # 随机 GT 类别标签
# 初始化分配器
assigner = TaskAlignedAssigner(topk=5, alpha=1.0, beta=6.0)
# 分配正样本
pos_anchors, pos_gts, pos_labels = assigner(cls_scores, bbox_preds, gt_bboxes, gt_labels)
# 输出结果
print("正样本锚点索引:", pos_anchors) # 格式为 (batch_idx, anchor_idx) 的元组
print("对应真实框索引:", pos_gts) # 每个正样本锚点对应的 GT 索引
print("正样本标签:", pos_labels) # 每个正样本锚点的类别标签