持续更新中
一、LORA篇
1、介绍一下Lora的原理
LoRA 是一种参数高效微调方法,其核心思想是将原始权重矩阵的更新限制在一个低秩空间内,从而显著减少训练参数量。
不同于传统微调,LoRA 将权重的更新项 Δ W \Delta W ΔW 表示为两个低秩矩阵 A ∈ R r × d A \in \mathbb{R}^{r \times d} A∈Rr×d 和 B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r 的乘积:
W ′ = W + Δ W = W + B A W' = W + \Delta W = W + BA W′=W+ΔW=W+BA
训练阶段只更新两个低秩矩阵 A A A 和 B B B ,原始模型权重 W W W 保持不变;
2、LoRA 是为了解决什么问题提出的?哪些模型适合用 LoRA 微调?什么是低秩分解?
- LoRA 的核心目标:降低大模型微调成本 参数量从 O ( d 2 ) O(d^2) O(d2) → O ( r d ) O(rd) O(rd)
- 适合含大量线性层的 Transformer 架构模型 比如注意力模块的
Q/K/V投影矩阵、FFN前馈神经网络等
低秩分解:用小矩阵逼近大矩阵
定义:低秩分解是将高维矩阵近似为两个低维矩阵的乘积,以降低表示复杂度。
数学形式:对于 d × d d \times d d×d 的高维矩阵 W W W,找到两个低维矩阵 A ∈ R r × d A \in \mathbb{R}^{r \times d} A∈Rr×d 和 B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r 的乘积,使得:
W ≈ B A W \approx BA W≈BA
- (A) 是 降维矩阵:将原始 d d d 维空间映射到 r r r 维子空间(提取关键特征)。
- (B) 是 升维矩阵:将 $r$ 维特征恢复到 d d d 维空间(重构原始空间的更新)。
- 优势:通过仅优化 (A) 和 (B) 的 2 r d 2rd 2rd 个参数(远小于 d 2 d^2 d2),即可近似表达 (W) 的主要变化,大幅减少计算量。
3、LoRA初始化
LoRA 的初始化通常遵循以下原则:
原始模型权重 W 不变
LoRA 的矩阵:
- A A A 通常使用正态分布初始化:
nn.Linear(..., bias=False)默认初始化- B B B 通常初始化为 全零矩阵,这样一开始 Δ W = B A = 0 \Delta W = B A = 0 ΔW=BA=0,模型输出不会被扰动,保证收敛稳定性
如果A也初始化成0,这样都没法更新了。对于
对于 y = B A x y = B A x y=BAx:
- 对 B 的梯度: ∂ L ∂ B = ∂ L ∂ y ⋅ ( A x ) T \displaystyle \frac{\partial L}{\partial B} = \frac{\partial L}{\partial y} \cdot (A x)^T ∂B∂L=∂y∂L⋅(Ax)T
- 对 A 的梯度: ∂ L ∂ A = B T ⋅ ( ∂ L ∂ y ) ⋅ x T \displaystyle \frac{\partial L}{\partial A} = B^T \cdot \left( \frac{\partial L}{\partial y} \right) \cdot x^T ∂A∂L=BT⋅(∂y∂L)⋅xT
向量对矩阵求导规则:
如果:
- y = B z y = B z y=Bz
- B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r
- z ∈ R r z \in \mathbb{R}^{r} z∈Rr
则有:
∂ L ∂ B = ∂ L ∂ y ⋅ z T \frac{\partial L}{\partial B} = \frac{\partial L}{\partial y} \cdot z^T ∂B∂L=∂y∂L⋅zT
📌 这是矩阵微积分中经典的链式法则: - ∂ L ∂ y \frac{\partial L}{\partial y} ∂y∂L 是 d d d 维行向量(外层loss对每个输出的导数)
- z T z^T zT 是 1 × r 1 \times r 1×r 行向量
- 所以它们的乘积是一个 d × r d \times r d×r 的矩阵(和 B 同型)
4、LoRA初始化秩 r 是怎么选的?为什么不选其他值?
LoRA 中的秩 $r$ 是一个超参数,控制低秩矩阵的维度,通常选取值为 4、8、16、32、64,具体视模型规模和任务而定。
- 太小(如 r = 1 r=1 r=1):表达能力太弱,模型性能下降
- 太大(如 r = 512 r=512 r=512):虽然逼近能力强,但和原始 full fine-tune 差别不大,丧失了 LoRA 节省资源的意义
📌 一般经验:
| 模型规模 | 推荐 LoRA 秩 r |
|---|---|
| <100M 参数 | 4-8 |
| 100M-1B | 16 |
| >1B 模型 | 32 或 64 |
5、LoRA家族
参考:LoRA及衍生
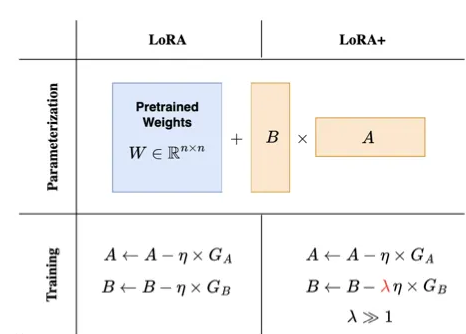
5.1 LoRA+
将矩阵 B 的学习率设置得比矩阵 A 的学习率高得多
4.2 VeRA
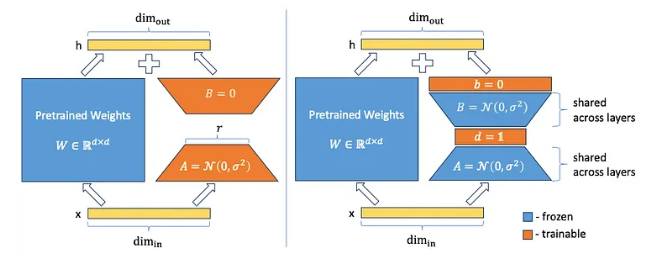
VeRA(Very Efficient Rank Adaptation)是一种改进版 LoRA 微调方法,它固定低秩矩阵 A 和 B(随机初始化后冻结,在所有层之间共享;),仅训练缩放向量 d 和 b,实现参数更少、适配性更强的微调。
等等
4.3 QLoRA
对LoRA进行量化
模型参数精度格式
| 类型 | 位数 | 作用 | 优缺点 |
|---|---|---|---|
FP32(float32) |
32 bits | 默认精度,训练常用 | 精度高,速度慢,占内存大 |
FP16(float16) |
16 bits | 常用于推理、混合精度训练 | 精度适中,速度快,容易溢出 |
bfloat16 |
16 bits | Google 开发的 float16 变体 | 精度比 FP16 更稳,适合训练 |
INT8 |
8 bits | 整数,常用于推理时量化 | 占用小但训练难,精度可能下降 |
NF4(4-bit量化) |
4 bits | 近似表示浮点,QLoRA 中用 | 占用极小,速度快,精度较低 |
QLoRA 是一种面向大语言模型的参数高效微调方法,它结合了 4-bit 权重量化和 LoRA adapter 插入,其关键技术点包括三方面:
第一,4-bit量化 NF4 量化(Normalized Float 4)。 相比传统的对称 int4 量化,QLoRA 使用非对称、数据分布感知的 NF4 量化格式,它通过查表(lookup table)方式实现非均匀分桶,可以更好地保留模型参数的数值分布特性。同时配合 double quantization 技术,连 lookup 表都量化,显著降低显存开销。
第二,LoRA
第三,内存调度优化。 QLoRA 使用 bitsandbytes 库的 4bit Linear 替代标准
nn.Linear,并结合 Hugging Face 的 paged optimizer,在训练时自动进行参数分页加载和 offloading,从而有效避免 CUDA OOM,支持在单张 A100 上训练 65B 模型。