User Diverse Preference Modeling by Multimodal Attentive Metric Learning
题目翻译:基于多模态注意度量学习的用户不同偏好建模
摘要
提出一个**多模态注意力度量学习(MAML, Multimodal Attentive Metric Learning)**方法,
核心思路:针对每一个用户-物品对,设计了一个注意力神经网络,利用物品的多模态信息来估计用户对物品不同方面的特别关注。
引言
在当时虽然有新的研究通过评论、神经网络等方式建模用户对不同方面的关注如(ALFM、A3NCF、DIN),但是这些方法基于MF的点积,点积不是度量(不满足三角不等式),表达能力有限。
Hsieh等人[20]提出了一种度量协同过滤(CML)方法,该方法通过最小化用户和项目向量(即||pu - qi ||)之间的距离来学习偏好。
纯度量学习(如CML)虽然克服了点积问题,但又面临“所有正交互的用户-物品需映射到同一点,几何表达受限”等新问题。
我们提出了一种新的多模态注意度量学习(MAML)方法,该方法利用物品的多模态信息来模拟用户对不同物品的不同偏好。
我们的MAML模型通过向每个用户-项目对引入权重向量来增强CML方法,通过设计一个注意力神经网络来实现的,该网络通过利用目标物品的文本和视觉特征来分析用户对目标物品的注意力。
MAML的优点:
- 1)由于采用了基于度量的学习方法,满足了不等式性质,从而避免了点积相似度预测方法的问题;
- 2)解决了CML中的几何限制问题。
MAML model
符号说明
| 符号 | 含义说明 |
|---|---|
| U U U | 用户集合(所有用户的集合) |
| I I I | 物品集合(所有物品的集合) |
| R R R | 用户-物品交互矩阵 |
| r u , i r_{u,i} ru,i | 用户 u u u 与物品 i i i 之间的交互值,属于矩阵 R R R |
| 隐式反馈 | 若用户 u u u 与物品 i i i 有交互, r u , i = 1 r_{u,i}=1 ru,i=1;否则为0 |
| 显式反馈 | r u , i r_{u,i} ru,i 通常为用户 u u u 对物品 i i i 的评分 |
| R R R(集合) | 所有值不为零的用户-物品对 ( u , i ) (u, i) (u,i) 的集合 |
| R u R_u Ru | 用户 u u u 已交互过的物品集合 |
| p u p_u pu | 用户 u u u 的潜在特征向量,维度为 f f f |
| q i q_i qi | 物品 i i i 的潜在特征向量,维度为 f f f |
| r ^ u , j \hat{r}_{u,j} r^u,j | 用户 u u u 对物品 j j j 的推荐得分(由特征向量计算得到) |
背景
矩阵分解(Matrix Factorization,MF)方法将用户和物品映射到一个共享的潜在特征空间中,并通过用户和物品特征向量之间的点积来估计未观测到的交互,即
r ^ u , i = p u T q i \hat{r}_{u,i} = p_u^T q_i r^u,i=puTqi
对于所有的用户 u ∈ U u \in U u∈U 和物品 i ∈ I i \in I i∈I, p u p_u pu 和 q i q_i qi 的学习目标是最小化预测得分 r ^ u , i \hat{r}_{u,i} r^u,i 与实际交互值 r u , i r_{u,i} ru,i 之间的误差,即:
∑ ( u , i ) ∈ R ∥ r ^ u , i − r u , i ∥ \sum_{(u,i) \in R} \| \hat{r}_{u,i} - r_{u,i} \| (u,i)∈R∑∥r^u,i−ru,i∥
(注:这里省略了正则项,仅保留了预测误差部分。)
最初的矩阵分解(MF)模型是为了评分预测而设计的【19, 27】,后来被扩展为带权正则化矩阵分解(WRMF),以用于隐式反馈的预测【21】。由于推荐系统的目标是为目标用户提供一份最有可能被其喜欢的物品的排名列表,因此,推荐本质上是一个排序问题,而非简单的评分预测问题。基于这一点,MF方法逐渐发展为建模不同物品之间的相对偏好,并广泛采用了*成对学习(pairwise learning)*的方法来实现这一目标【35, 54】。
在成对学习中,用户和物品的特征向量通过设定如下约束来学习:
对于任意满足 ( u , i ) ∈ R (u, i) \in R (u,i)∈R 且 ( u , k ) ∉ R (u, k) \notin R (u,k)∈/R 的两个物品对,应有
r ^ u , i > r ^ u , k \hat{r}_{u,i} > \hat{r}_{u,k} r^u,i>r^u,k
其中,典型的例子是**贝叶斯个性化排序(BPR)**方法【35】。BPR 是一种基于MF的方法,其中
r ^ u , i = p u T q i , r ^ u , k = p u T q k \hat{r}_{u,i} = p_u^T q_i, \quad \hat{r}_{u,k} = p_u^T q_k r^u,i=puTqi,r^u,k=puTqk
因此,优化目标就是保证 p u T q i > p u T q k p_u^T q_i > p_u^T q_k puTqi>puTqk(其中 ( u , i ) ∈ R (u, i) \in R (u,i)∈R, ( u , k ) ∉ R (u, k) \notin R (u,k)∈/R)。
尽管矩阵分解(MF)方法取得了成功,但它并不是一种基于度量的学习方法,因为其采用的点积相似度并不满足三角不等式这一性质,而这一性质对于刻画用户的细粒度偏好非常关键,这一点在相关研究【20, 53】中已经有所证明。从度量学习的角度来看,既然用户和物品都被表示为共享空间中的潜在向量,那么用户与物品之间的相似度可以通过它们向量之间的欧氏距离来衡量,如下所示:
d ( u , i ) = ∥ p u − q i ∥ d(u, i) = \|p_u - q_i\| d(u,i)=∥pu−qi∥
数学定义
对于两个 f f f 维空间中的点(向量) a = ( a 1 , a 2 , . . . , a f ) \mathbf{a} = (a_1, a_2, ..., a_f) a=(a1,a2,...,af) 和 b = ( b 1 , b 2 , . . . , b f ) \mathbf{b} = (b_1, b_2, ..., b_f) b=(b1,b2,...,bf),它们之间的欧氏距离定义为:
∥ a − b ∥ = ( a 1 − b 1 ) 2 + ( a 2 − b 2 ) 2 + ⋯ + ( a f − b f ) 2 \|\mathbf{a} - \mathbf{b}\| = \sqrt{(a_1 - b_1)^2 + (a_2 - b_2)^2 + \cdots + (a_f - b_f)^2} ∥a−b∥=(a1−b1)2+(a2−b2)2+⋯+(af−bf)2
考虑到成对学习(pairwise learning),很自然地可以得到这样的推论:对于满足 ( u , i ) ∈ R (u, i) \in R (u,i)∈R 且 ( u , k ) ∉ R (u, k) \notin R (u,k)∈/R 的情况,有
d ( u , i ) < d ( u , k ) d(u, i) < d(u, k) d(u,i)<d(u,k)
其中, i i i 表示用户 u u u 喜欢的物品, k k k 表示用户 u u u 不喜欢的物品。**协同度量学习(CML)**方法【20】正是基于这个简单的思想设计的。由于这种方法是一种基于度量的学习方式,它天然地避免了点积的局限性,并且在性能上优于传统的MF模型【20】。因此,在本研究中,我们也基于这种思想来推导用户多样化偏好建模方法,而不是采用传统的MF方法。
MAML
用户对物品的各个部分的专注度是不一样的,比如他在意的某个部分,就往往决定了他会不会选择这个物品。
基于上述考虑,我们提出了一种多模态注意力度量学习(MAML)模型。对于每一个用户-物品 ( u , i ) (u, i) (u,i) 对,我们的模型都会计算一个权重向量 a u , i ∈ R f a_{u,i} \in \mathbb{R}^f au,i∈Rf,用以表示物品 i i i 的各个方面对用户 u u u 的重要性。
此外,模型还利用物品的侧信息来估计这个权重向量,因为侧信息(如文本评论和商品图片)能够反映物品在不同方面的丰富特征,这些特征往往是显著且互补的【9, 54】。我们采用了最新的注意力机制【6, 10】来估算注意力(权重)向量。
在引入注意力(权重)向量后,我们模型中用户 u u u 与物品 i i i 之间的欧氏距离定义为:
d ( u , i ) = ∥ a u , i ⊙ p u − a u , i ⊙ q i ∥ d(u, i) = \|a_{u,i} \odot p_u - a_{u,i} \odot q_i\| d(u,i)=∥au,i⊙pu−au,i⊙qi∥
其中, ⊙ \odot ⊙ 表示向量的按元素乘积。
读到这里,我很想知道他是怎么把注意力干进去的,好难猜啊
直观比喻
你可以理解成:
普通的MF或者CML,用户和物品就是静静地摆在空间里的点;
而MAML,每遇到一个用户和物品,都会用“注意力放大镜”针对这对组合“重新定制”一套权重,让你关注的地方和我关注的不一样,然后在加权后的空间里比距离。具体来说,他是这样“把注意力机制加进去的”:
1. 为每个用户-物品对单独计算一个“注意力向量”
- 不是只为用户算一组注意力,也不是只为物品算一组注意力,而是每对用户-物品都重新算一次注意力向量 a u , i a_{u,i} au,i。
- 这个向量的每一维,其实就代表了“用户对这个物品在第 l l l 个特征/方面上的关注度”。
- 关注度不一样,后续距离计算时的权重就不一样。
2. 注意力怎么计算出来?
作者用一个两层神经网络,输入信息包括:
- 用户特征向量 p u p_u pu
- 物品特征向量 q i q_i qi
- 物品的多模态侧信息(文本+图片特征,合并后记作 F t v , i F_{tv,i} Ftv,i)
把它们拼接起来后,先用Tanh激活,后用ReLU激活,再线性变换,得到注意力“初值”。
然后对每一维做“归一化”,让它像一个权重分布(这一步细节作者有改进,见下说明)。
3. 注意力机制怎么和距离结合?
普通欧氏距离是 ∥ p u − q i ∥ \|p_u - q_i\| ∥pu−qi∥。
MAML变成:
d ( u , i ) = ∥ a u , i ⊙ p u − a u , i ⊙ q i ∥ d(u, i) = \| a_{u,i} \odot p_u - a_{u,i} \odot q_i \| d(u,i)=∥au,i⊙pu−au,i⊙qi∥
也就是:对每一维都乘上这个注意力权重,然后再做距离计算。
这样一来,“用户对不同物品、不同方面的关注度不同”就体现在距离计算里了。
4. 注意力的归一化方法
- 论文特别提到:如果用标准softmax归一化,权重太小,会导致距离区分能力减弱。所以作者把归一化后的权重整体放大了(乘以特征维数f),这样每一维的贡献更显著,模型区分力更强。
5. 用神经网络动态学习注意力
- 这个权重 a u , i a_{u,i} au,i不是靠人工规则算的,而是用训练数据,通过反向传播、自动微调神经网络参数学出来的。
值得一提的是,通过引入注意力向量,我们的模型不仅能够准确捕捉用户对不同物品的多样化偏好,还能够解决CML方法中存在的几何限制问题【41】。从公式1可以看出,CML方法试图将一个用户和其所有交互过的物品都拟合到潜在空间中的同一个点上,然而,每个物品又同时有许多交互过的用户。因此,从几何上来看,实现这个目标是不可能的。
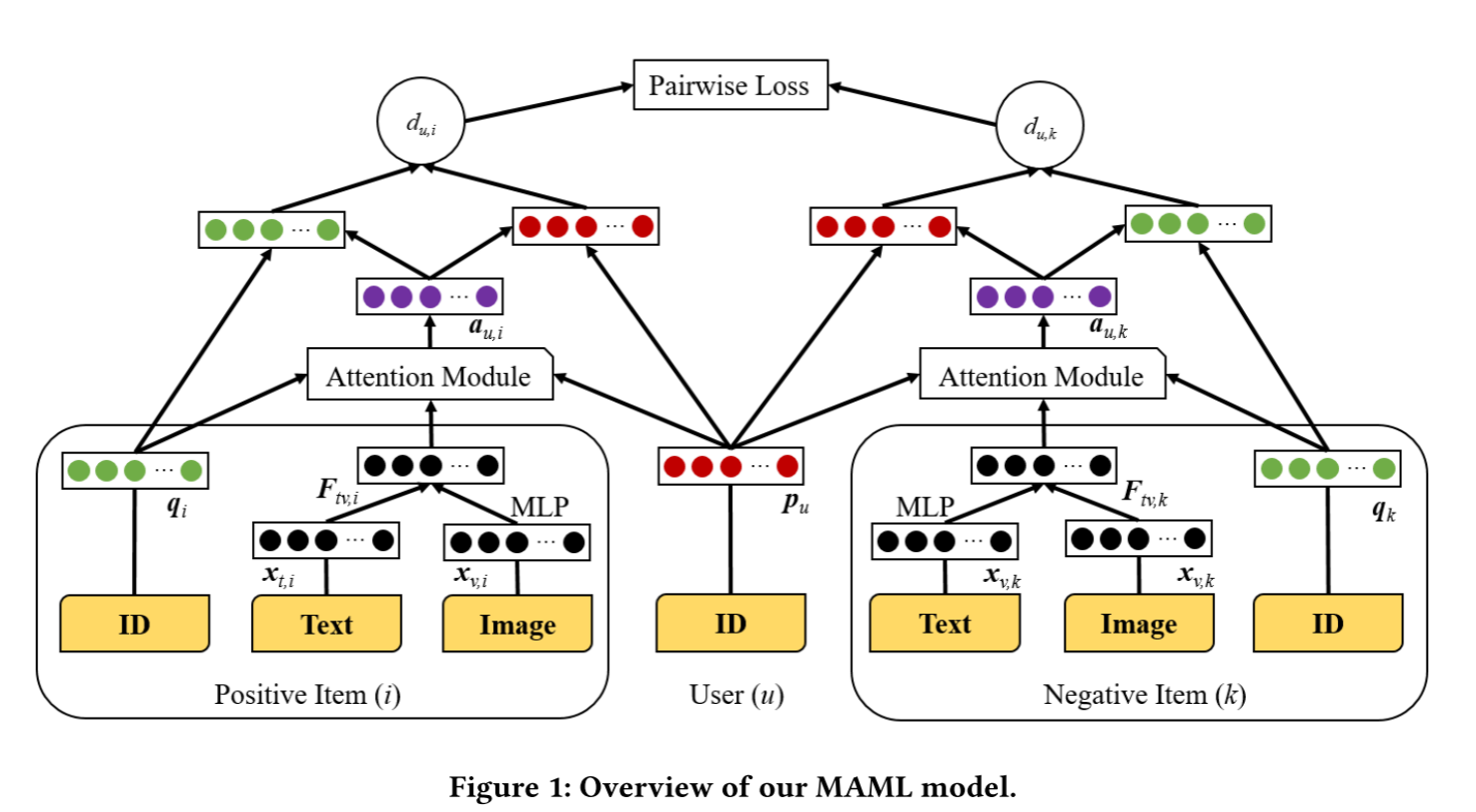
而在我们的方法中,由于 a u , i a_{u,i} au,i 是针对每个用户-物品对唯一生成的,它就像一个变换向量,将目标用户和物品“投影”到一个新的空间中进行距离计算。因此,我们的方法能够自然而然地避免CML中的几何限制问题。我们所提出的MAML模型的整体框架如图1所示。
我们采用成对学习(pairwise learning)的方法进行优化,其损失函数定义如下:
L m ( d ) = ∑ ( u , i ) ∈ R ∑ ( u , k ) ∉ R ω u i [ m + d ( u , i ) 2 − d ( u , k ) 2 ] + L_m(d) = \sum_{(u,i)\in R} \sum_{(u,k)\notin R} \omega_{ui} \left[ m + d(u, i)^2 - d(u, k)^2 \right]_+ Lm(d)=(u,i)∈R∑(u,k)∈/R∑ωui[m+d(u,i)2−d(u,k)2]+
其中, i i i 表示用户 u u u 喜欢的物品, k k k 表示用户 u u u 不喜欢的物品; [ z ] + = max ( z , 0 ) [z]_+ = \max(z, 0) [z]+=max(z,0) 表示标准的合页损失函数(hinge loss)。
ω u i \omega_{ui} ωui 是排名损失权重(详见3.2.3节), m > 0 m > 0 m>0 是安全间隔(margin)大小。
d ( u , i ) d(u, i) d(u,i) 和 d ( u , k ) d(u, k) d(u,k) 按照公式2计算。
接下来,我们将介绍如何为每个用户-物品对计算注意力向量 a u , i a_{u,i} au,i。
好难坚持啊,真不想继续阅读了,但是这是注意力机制啊!
3.2.2 注意力机制
在本节中,我们介绍MAML模型中用于捕捉用户 u u u 对物品 i i i 的特定注意力 a u , i a_{u,i} au,i 的注意力机制。由于文本评论和图片包含了丰富的用户偏好和物品特征信息,因此我们利用这些多模态信息来刻画用户对物品不同方面的关注。
我们采用了一个两层神经网络来计算注意力向量,具体如下:
e u , i = tanh ( W 1 [ p u ; q i ; F t v , i ] + b 1 ) , e_{u,i} = \tanh\left(W_1 \left[ p_u; q_i; F_{tv,i} \right] + b_1\right), eu,i=tanh(W1[pu;qi;Ftv,i]+b1),
a ^ u , i = v T R e L U ( W 2 e u , i + b 2 ) , \hat{a}_{u,i} = v^T \mathrm{ReLU}\left(W_2 e_{u,i} + b_2\right), a^u,i=vTReLU(W2eu,i+b2),
其中, W 1 , W 2 W_1, W_2 W1,W2 分别为两层的权重矩阵, b 1 , b 2 b_1, b_2 b1,b2 为偏置向量, v v v 是将隐藏层投影到输出注意力权重向量的参数向量。 F t v , i F_{tv,i} Ftv,i 表示物品 i i i 的特征向量,是该物品文本特征和图像特征融合后的结果(后文会详细描述)。 [ p u ; q i ; F t v , i ] [p_u; q_i; F_{tv,i}] [pu;qi;Ftv,i] 表示将用户向量、物品向量和物品多模态特征进行拼接。第一层激活函数使用Tanh,第二层使用ReLU【29, 30, 36】。
这篇论文多模态融合的实现思路
1. 多模态特征指哪些?
- 文本特征:商品描述、评论、标题等
- 图像特征:商品图片(通常用CNN提特征)
2. 具体怎么融合?
根据论文原文的表达(后文会详细介绍),通常流程是这样的:
(1) 提取文本特征
- 把商品的文本描述或评论经过文本编码器(如Word2Vec、LSTM、BERT、甚至MLP),得到一个定长向量,记为 F t e x t , i F_{text, i} Ftext,i。
(2) 提取图片特征
- 把商品图片输入到预训练的卷积神经网络(CNN)(如ResNet、VGG、Inception等),提取图片的深层向量特征,记为 F v i s , i F_{vis, i} Fvis,i。
(3) 拼接融合
最直接的方法:把文本向量和图片向量直接拼接(concatenate)起来,得到多模态融合特征
F t v , i = [ F t e x t , i ; F v i s , i ] F_{tv, i} = [F_{text, i}; F_{vis, i}] Ftv,i=[Ftext,i;Fvis,i]
这样融合后的 F t v , i F_{tv, i} Ftv,i 既包含了文本的信息,也包含了图片的信息,作为物品i的多模态特征输入到后续的注意力网络中。
3. 融合方式的常见变体(扩展理解)
- 有些工作会用加权融合、MLP进一步融合、或用注意力机制动态融合,但在这篇论文的原文里,最核心的是直接拼接。
- 这种方式简单直接,信息保留完整,也便于神经网络后续学习每种模态的权重。
4. 总结一句话
- 这篇论文的多模态融合方法是:把文本特征和图像特征提出来后直接拼接,形成一个更大的融合向量,然后作为物品的特征输入到注意力机制中。
3. 融合方式的常见变体(扩展理解)
- 有些工作会用加权融合、MLP进一步融合、或用注意力机制动态融合,但在这篇论文的原文里,最核心的是直接拼接。
- 这种方式简单直接,信息保留完整,也便于神经网络后续学习每种模态的权重。
4. 总结一句话
- 这篇论文的多模态融合方法是:把文本特征和图像特征提出来后直接拼接,形成一个更大的融合向量,然后作为物品的特征输入到注意力机制中。