TensorFlow深度学习实战(18)——K-means 聚类详解
0. 前言
K-means 聚类是一种常用的无监督学习算法,用于将数据集划分为若干个互不重叠的簇 (cluster),使得同一簇内的数据点尽可能相似,而不同簇之间的数据点尽可能不同。在本节中,将介绍 K-means 聚类的基本原理与局限性,并使用 TensorFlow 实现 K-means 聚类。
1. K-means 聚类
K-means 聚类是一种数据聚类技术,即将数据划分为指定数量的数据点,是一种无监督学习技术,通过识别给定数据中的模式工作。
有多种聚类技术,如层次聚类、贝叶斯聚类或划分聚类。K-means 聚类属于划分聚类,将数据分成 k 个簇。每个簇有一个中心,称为质心,簇的数量 k 需要自行指定。K-means 算法的工作流程如下:
- 随机选择
k个数据点作为初始质心(簇中心) - 将每个数据点分配给最近的质心;可以使用不同的度量方法来确定接近度,最常见的是欧几里得距离
- 使用当前的簇成员重新计算质心,以使(每个点与其质心)距离的平方之和减少
- 重复步骤
2和3,直到收敛。
接下来,我们将使用 TensorFlow 中提供的高级数学函数实现 K-means 聚类。
2. 实现 K-means 聚类
为了实现 K-means,本节中,我们将使用随机生成的数据。随机生成数据将包含 200 个样本,我们将其分成三个簇。
2.1 算法实现
(1) 首先导入所有所需的库,定义变量,并确定样本点的数量 (points_n)、要形成的簇数量 (clusters_n) 和迭代次数 (iteration_n):
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
points_n = 200
clusters_n = 3
iteration_n = 100
(2) 随机生成数据,并从中随机选择三个质心:
points = np.random.uniform(0, 10, (points_n, 2))
centroids = tf.slice(tf.random.shuffle(points), [0, 0], [clusters_n, -1])
(3) 可视化随机生成的数据:
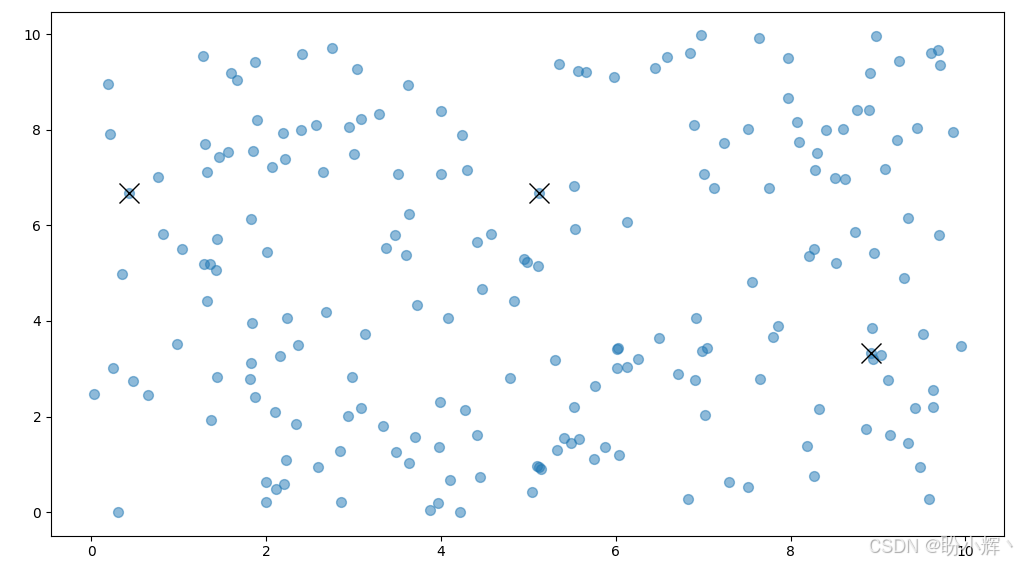
plt.scatter(points[:, 0], points[:, 1], s=50, alpha=0.5)
plt.plot(centroids[:, 0], centroids[:, 1], 'kx', markersize=15)
plt.show()
可以在下图中看到生成数据构成的散点图以及随机选择的三个质心:
(4) 定义 closest_centroids() 函数,用于将每个点分配给离它最近的质心:
def closest_centroids(points, centroids):
distances = tf.reduce_sum(tf.square(tf.subtract(points, centroids[:,None])), 2)
assignments = tf.argmin(distances, 0)
return assignments
(5) 接下来,创建函数 move_centroids(),用于重新计算质心,以减少(每个点与其质心)距离平方之和:
def move_centroids(points, closest, centroids):
return np.array([points[closest==k].mean(axis=0) for k in range(centroids.shape[0])])
(6) 迭代调用以上两个函数 100 次,可以根据实际需要选择的迭代次数,增加或减少迭代次数以查看效果:
for step in range(iteration_n):
closest = closest_centroids(points, centroids)
centroids = move_centroids(points, closest, centroids)
(7) 可视化在 100 次迭代后质心的变化:
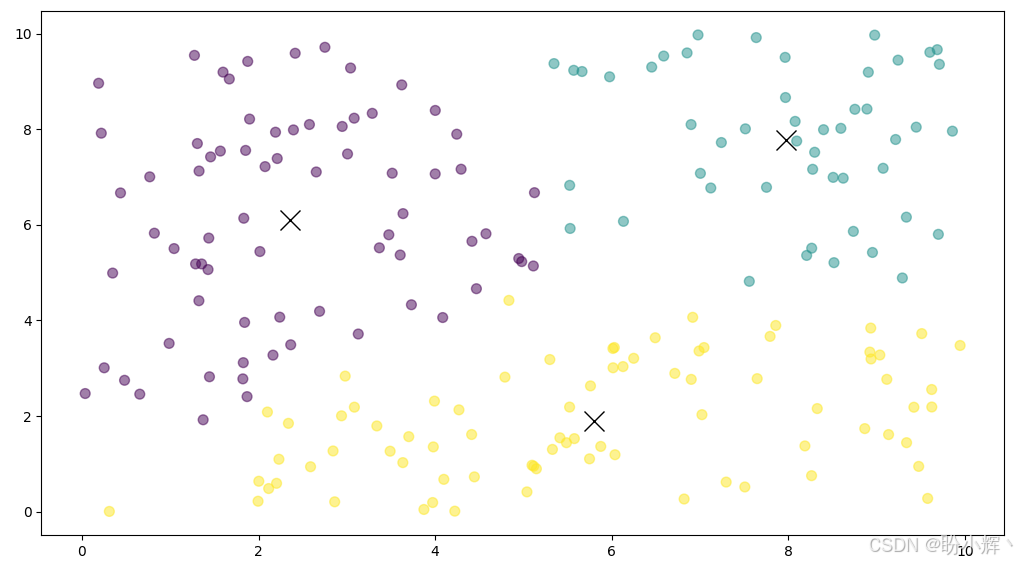
plt.scatter(points[:, 0], points[:, 1], c=closest, s=50, alpha=0.5)
plt.plot(centroids[:, 0], centroids[:, 1], 'kx', markersize=15)
plt.show()
在下图中,可以看到 100 次迭代后的最终质心。根据每个点离哪个质心最近来对点进行着色:
2.2 肘部法则
在本节代码中,我们将簇数量限制为三个,但在大多数情况下,对于无标签的数据,并不确定簇的数量,可以使用肘部法则来确定最佳的簇数量。该方法基于以下原则:选择能够减少距离的平方误差和 (sum of squared error, SSE) 的簇数量。如果 k 是簇的数量,那么随着 k 的增加,SSE 会减少,当 k 等于数据点的数量时,SSE 为 0,此时每个点都是一个簇。显然,我们不希望将此作为簇数量,因此绘制 SSE 与簇数量的关系图时,应该能看到图中的一个拐点,类似于手肘,因此得名肘部法则。使用函数 sse() 计算数据的平方误差和:
def sse(points, centroids):
sse1 = tf.reduce_sum(tf.square(tf.subtract(points, centroids[:,None])), 2).numpy()
s = np.argmin(sse1, 0)
distance = 0
for i in range(len(points)):
distance += sse1[s[i], i]
return distance/len(points)
使用肘部法则寻找数据集的最佳簇数量。从一个簇开始,即所有点属于一个簇,然后逐步增加簇的数量,每次将簇数量增加一个,最多为 11 个簇。对于每个簇值,寻找质心(从而找到簇)并计算 SSE:
w_sse = []
for n in range(1, 11):
centroids = tf.slice(tf.random.shuffle(points), [0, 0], [n, -1])
for step in range(iteration_n):
closest = closest_centroids(points, centroids)
centroids = move_centroids(points, closest, centroids)
#print(sse(points, centroids))
w_sse.append(sse(points, centroids))
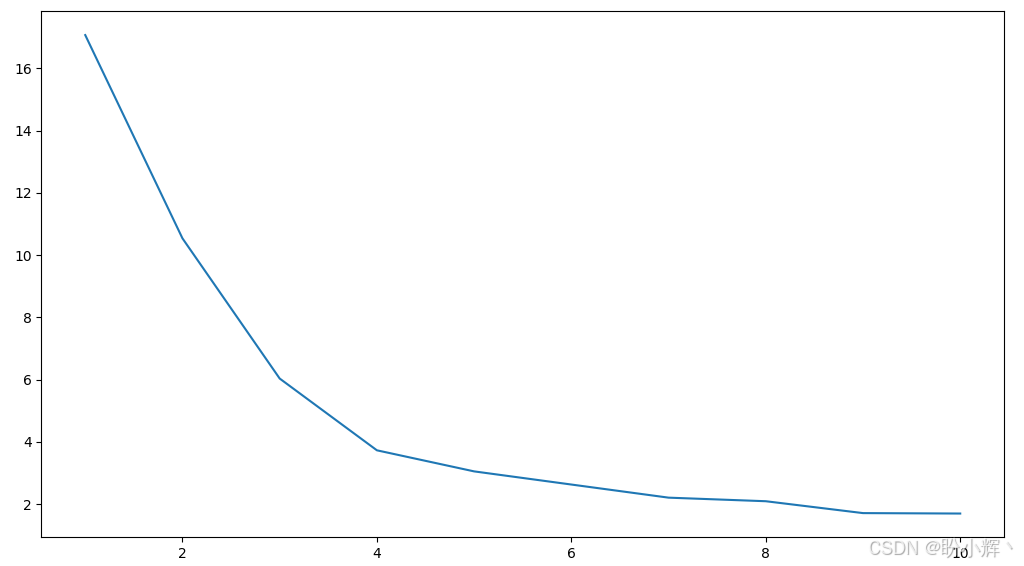
plt.plot(range(1, 11),w_sse)
plt.xlabel('Number of clusters')
plt.show()
下图显示了数据集的不同簇值。当簇数量为 4 时,拐点非常明显:
由于 K-means 聚类快速、简单且稳健,因此非常受欢迎。但它也有一些缺点,最大的问题是必须指定簇的数量;其次,该算法不保证全局最优;如果初始随机选择的质心发生变化,结果也可能会改变;第三,它对异常值非常敏感。
3. K-means 算法变体
在原始的 K-means 算法中,每个点属于一个特定的簇(质心),这类方法称为硬聚类 (hard clustering)。然而,我们也可以让一个点属于所有簇,通过一个隶属函数来定义它对特定聚类(质心)的归属程度,这类方法称为模糊聚类 (fuzzy clustering) 或软聚类 (soft clustering)。
软聚类由 J.C. Dunn 提出,并由 J.C. Bezdek 进一步改进。尽管软聚类收敛较慢,但当一个点属于多个类别或我们想了解一个点与不同集群的相似度时,软聚类方法非常有效。
加速 K-means 算法由 Charles Elkan 创建,该方法利用了三角不等式关系(即直线是两点之间最短的距离)。不仅在每次迭代时计算所有距离,还跟踪点和质心之间距离的上下界。
David Arthur 和 Sergei Vassilvitskii 提出了 K-means++ 算法。主要变化是在质心的初始化上,如果选择相互之间距离较远的质心,K-means 算法不太可能收敛于次优解。
另一种替代方法是,在每次迭代中,不使用整个数据集,而是使用小批量数据,这一修改由 David Sculey 提出。
小结
K-means 聚类是一种基于划分的无监督学习方法,适用于大多数数据集,能够高效地将数据分为 k 个簇。尽管它简单易用,但也有一些局限性,如对初始簇中心选择敏感、对异常值敏感等。因此,在实际应用时,可以通过调整 k 值、与其他算法结合等方法来优化其性能。
系列链接
TensorFlow深度学习实战(1)——神经网络与模型训练过程详解
TensorFlow深度学习实战(2)——使用TensorFlow构建神经网络
TensorFlow深度学习实战(3)——深度学习中常用激活函数详解
TensorFlow深度学习实战(4)——正则化技术详解
TensorFlow深度学习实战(5)——神经网络性能优化技术详解
TensorFlow深度学习实战(6)——回归分析详解
TensorFlow深度学习实战(7)——分类任务详解
TensorFlow深度学习实战(8)——卷积神经网络
TensorFlow深度学习实战(9)——构建VGG模型实现图像分类
TensorFlow深度学习实战(10)——迁移学习详解
TensorFlow深度学习实战(11)——风格迁移详解
TensorFlow深度学习实战(12)——词嵌入技术详解
TensorFlow深度学习实战(13)——神经嵌入详解
TensorFlow深度学习实战(14)——循环神经网络详解
TensorFlow深度学习实战(15)——编码器-解码器架构
TensorFlow深度学习实战(16)——注意力机制详解
TensorFlow深度学习实战(17)——主成分分析详解