一 namespeace(命名空间)
namespace是一个自定义的空间,这个空间相当于一个总文件夹,总文件可以有好多个,里面的小文件夹或者其他文件,也可以有其他各种各样的文件,
定义:命名空间是程序员自定义的代码容器,用于封装标识符(变量、函数、类等),解决命名冲突问题。
您的比喻 技术实现 自定义空间 使用 namespace 名称 { ... }语法创建作用域边界文件夹 编译器在符号表中为每个命名空间创建独立的分支 文件夹内文件相同 不同命名空间内可定义同名标识符(如 A::func()和B::func()共存)内外引用 通过 空间名::成员访问(外部),或通过using声明简化访问(内部)
namespace MathLib {
class Matrix { /*...*/ }; // MathLib::Matrix
}
namespace GraphicsLib {
class Matrix { /*...*/ }; // GraphicsLib::Matrix
}
// 用户代码
MathLib::Matrix mat1; // 明确使用数学矩阵
GraphicsLib::Matrix mat2; // 明确使用图形矩阵1. 嵌套命名空间(C++17支持简洁语法)
namespace fs = std::filesystem; // 简化长命名空间
fs::path p = fs::current_path();2. 匿名命名空间(替代C的static)
namespace { // 仅当前文件可见
int internalCounter;
}
// 等价于 static int internalCounter;3. 命名空间的别名 (简化代码)
namespace fs = std::filesystem; // 简化长命名空间
fs::path p = fs::current_path();二 动态内存分配
动态内存分配:在程序运行时向堆区申请内存空间
类型 分配方式 生命周期 存储位置
静态分配 编译时确定大小 随函数作用域结束 栈
动态分配 运行时申请内存 手动释放或自动回收、程序结束 堆
void f01() {
//C++动态内存分配
//分配一个int并初始化为10;
//new 新建内存空间
int* p = new int(10);//c++ 类和对象
cout << *p << endl;
//C++释放内存,如果new没有释放 内存泄露,释放delete
delete p;
//内存释放错误:双重释放,可能崩溃
//delete p;
//错误:使用未初始化,野指针访问
/*int* p2;
*p2 = 5;*/
//分配数组
int* arr = new int[5];//分配5int元素的数组
for (int i = 0; i < 5; i++)
{
//赋值
arr[i] = i * 10;
}
//遍历
for (int i = 0; i < 5; i++)
{
cout<<arr[i]<<" ";
}
//换行
cout << endl;
//数组新建 new [],释放delete[]而不是delete
delete[] arr;
}
int main() {
f01();
f02();
}2. 智能指针
//现代C++推荐使用智能指针
#include <memory>
void f02() {
//自动释放,无需手动delete
auto p = make_unique<int>(100);//新建一个int 赋值为100 new int(100)类似
cout << *p << endl;
//完了
}
三 常量(const)
1.符号常量:指在程序中用一个名字来代表一个常量值,这个值在编译时是已知且不会改变
const int MAX=100;//MAX是一个符号常量
#define PAI 3.17 //PAI是一个符号常量(宏的写法)
它们的作用:用名字代替字面值,使程序更易读,更易维护
2.符号常量表:是编译器维护的一个表,用于记录程序中所有的标识符(变量名、函数名、常量名等)及其相关信息。
比如:名字(如MAX)、数据类型(如 int)、存储位置(是否分配内存)、是否可修改、是变量还是常量、所属作用域等;
就像编译器有一个“字典”,记录了你程序中所有命名的东西及其含义,这个字典就是符号表,符号常量就是这个表中的“只读项”
3.符号常量表并不是程序的一个显式的数据结构,它是编译器内部的一个概念,用于记录程序中所有标识符(变量、常量、函数、类型等)
以及这些标识符的相关信息。它是编译过程的一部分,通常在编译器的前端阶段创建,并且只对编译器可见。
4.符号常量表的存在与作用:
a.编译器内部表格:符号常量表是编译器用来存储程序中标识符信息的地方。它通常在编译器间构建,并且在链接期间使用。
这个表会保存变量、常量、函数等符号的类型、内存位置、作用域等信息。
b.符号常量表包含常量的名称和值:对于符号常量来说,它的名字和常量的值会被记录在符号常量表中,方便编译器在编译时进行符号替换(例如:常量表达式)
c.只读:符号常量表中的项是不可修改的,因为它们代表的常量在程序执行期间的值是不可变的
总结:
1.符号常量表是编译器用于管理和替换程序中的标识符的一个内部数据结构
2.它记录了程序中所有常量的名称、值、类型、作用域等信息,并且保证编译器进行符号替换和类型检查
3.程序员不能直接访问符号常量表,它是编译器的一部分,通常通过调试工具间接查看其中的信息。
1. 常量 (Constants)
定义:程序运行期间值不可变的实体
类型:
字面常量:
42,3.14,'A'(直接嵌入代码的值)符号常量:
const int MAX = 100;(命名常量)constexpr常量:编译期计算的常量(C++11)
2. 符号常量 (Symbolic Constants)
本质:给常量值赋予名称的编程实践
声明方式:
const int BUFFER_SIZE = 1024; // C++ 风格 #define MAX_USERS 100 // C 风格(不推荐)优点:
提高代码可读性
避免魔法数字
单点修改
3. 符号常量表 (Constant Symbol Table)
本质:编译器内部的优化数据结构
存储位置:编译器内存(非运行时内存)
工作原理:
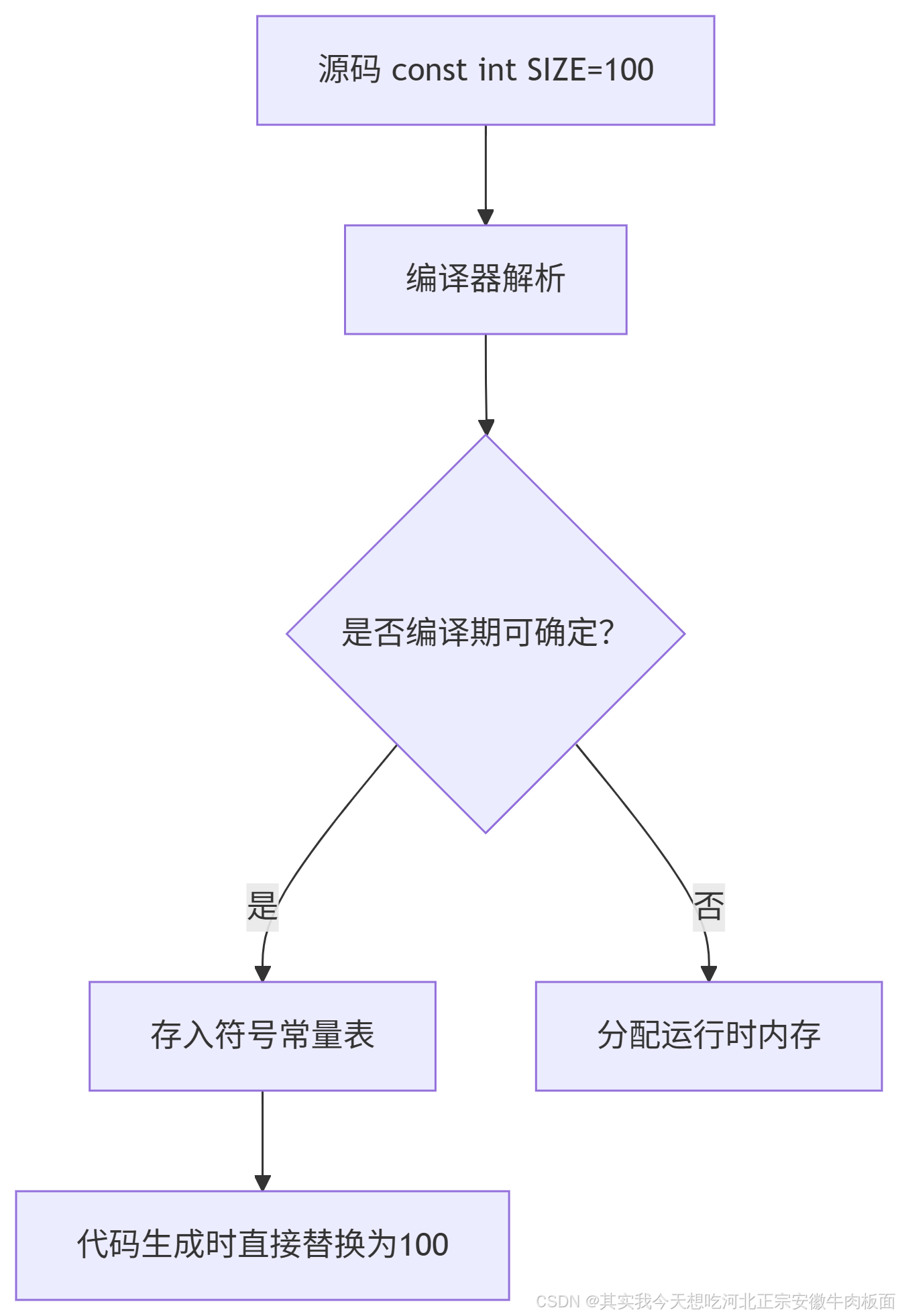
特性:
仅存储编译时可确定的常量
触发常量传播优化 (Constant Propagation)
可能不为常量分配物理内存地址
4. 指针修改常量的底层原理
场景分析:
const int a = 10; // 编译时常量
int* p = (int*)&a; // 强制类型转换
*p = 20; // 尝试修改底层过程:
编译器处理:
将
a存入符号常量表(值=10)代码中所有
a替换为字面量10可能不为
a分配真实内存地址
指针操作:
&a获取的是编译器临时分配的伪地址*p = 20修改的是栈上的临时位置符号常量表中的值保持不变
内存映射示例:
+-------------------+-----------------+ | 概念区域 | 示例值 | +-------------------+-----------------+ | 符号常量表 | a: 10 (只读) | | 编译器生成的伪地址 | 0x7ffd1234: 10 | | 指针修改后 | 0x7ffd1234: 20 | +-------------------+-----------------+输出矛盾解释:
printf("a = %d\n", a); // 输出10(直接使用常量表值) printf("*p = %d\n", *p); // 输出20(访问修改后的内存地址)
底层汇编对比:
; 未优化情况(可能分配内存)
mov DWORD PTR [rbp-4], 10 ; 栈地址存储10
lea rax, [rbp-4]
mov QWORD PTR [rbp-16], rax ; p = &a
; 优化情况(O2以上)
mov esi, 10 ; 直接传递字面量10
call printf ; printf("a=%d\n", 10)5. 成功修改的特殊情况
#include <atomic>
void test2()
{
int b = 20;
// 用变量b初始化const a,常量a会分配内存
const int a = b;
int *p = (int *)&a;
// printf("a = %d\n", a);
*p = 99;
// std::atomic_thread_fence(std::memory_order_seq_cst);
printf("a = %d\n", a);
printf("*P = %d\n", *p);
}
底层原因:
值在编译期无法确定 → 不存入符号常量表
编译器必须在栈上分配真实内存
const修饰仅保证编译器级保护物理内存位置可被指针访问修改
6. 核心差异总结
| 特性 | 编译时常量 (const int a=10) |
运行时常量 (const int a=b) |
|---|---|---|
| 符号常量表 | 是 | 否 |
| 内存分配 | 可能无真实地址 | 栈上分配真实地址 |
| 指针修改效果 | 修改临时位置,常量表不变 | 修改真实内存位置 |
| 后续访问行为 | 仍使用常量表值 | 读取被修改的内存 |
| 标准符合性 | 未定义行为 (UB) | 未定义行为 (UB) |
四 inline(内联函数,整体代码块)
内联函数的核心思想:当函数A(如
main函数)调用另一个函数B时,编译器会将函数B的完整代码直接插入到函数A的调用位置,而不是生成传统的函数调用指令。
这就像把被调用的函数B"溶解"到函数A的代码体中,形成一个连续执行的代码块。
准确描述 内联关注的是调用过程的处理方式,而非函数定义本身 任何函数调用点都可能发生内联(如func1调用func2时) 编译器将函数体代码复制到调用处,消除调用开销 1. 内联的本质特征
空间换时间
✅ 减少函数调用开销(无需跳转/保存上下文)
❌ 增加代码体积(每处调用都复制函数体)
编译期行为
由编译器决定是否内联(
inline关键字只是建议)递归函数/大型函数通常不会被内联
调试影响
内联函数没有独立的调用栈帧
调试时可能无法在函数内设置断点
2. 内联函数声名
// 内联函数声明
inline int add(int x, int y)
{
return x + y;
}
int main()
{
int a = add(5, 3); // 此处发生内联展开
}
作用就是,把多个函数,连在一起,高效开发
int main() {
// 内联展开后的等效代码
int aa = 5;
int bb = 3;
int a = aa + bb; // 直接插入函数体
}
3. 与宏的区别
宏:预处理器替换,无类型检查
内联:编译器处理,保留类型安全
// 宏文本替换
#define ADD(x,y) ((x)+(y))
// 内联函数
inline int add(int x, int y) { return x+y; }五 函数重载
C++中函数重载 是一种基于参数特征区分多个同名函数的能力,是C++区别于c的重要特征之一;
函数重载:在统一作用域中定义多个同名函数,但是参数(类型\顺序\个数)不同区别函数,
(前提同名函数)编译器根据参数列表不同自动选择合适的函数调用。
是C++面向对象的基础能力之一,适用于接口设计、函数扩展等场景。
函数名+参数列表=函数签名;
C++调用函数是通过函数签名调用。
#include <iostream>
#include <string>
using namespace std;
//函数重载 --同名不同参
//参数列表类型不同
void myPrint(int x) {
cout << "x=" << x << endl;
}
void myPrint(double y) {
cout << "y=" << y << endl;
}
//参数列表个数不同
void myPrint() {
cout << "无参数 列表.." << endl;
}
//参数列表顺序不同
void myPrint(double y,int x) {
cout << "y=" << y <<",x=" << x << endl;
}
void myPrint(int x, double y) {
cout << "x=" << x << ",y=" << y << endl;
}
//和返回值无关
//int myPrint() {
// cout << "无参数 列表.." << endl;
// return 0;
//}
int main() {
//无参
myPrint();
myPrint(8);
myPrint(7.7);
myPrint(7.7,7);
myPrint(6, 6.6);
return 0;
}
六 参数默认值
函数在声明或定义时,可以为某些参数指定默认值,如果调用函数时未传入这些参数,就使用默认值;
PS:参数默认值像一串多米诺骨牌,只能从右向左以次倒下
1.只能从右往左默认
2.声明或定义时只能写一次默认参数
3.默认参数值在函数声明或定义处确定
4.默认参数可用于构造函数、模板函数、成员函数
//声明时指定默认值
void greet(string name="杨幂") {
cout << "Hello,刺杀小说家 " << name << endl;
}
//PS:参数默认值像一串多米诺骨牌,只能从右向左以次倒下
//void errorTest(int a=1,int b,int c=3) {
// cout << a << endl;
//}
void info(int id,string name="tom",int age=18) {
cout << name << endl;
}
int main() {
greet("雷佳音");
greet();//没写默认值
/*errorTest(7);*/
info(5);
return 0;
}七 占位参数(java中类似,留有余地,为了拓展,占位符参数)
占位参数(占位符参数)
函数参数表中使用占位参数,虽然不使用它,但为了报错函数参数列表结构,必须写上(一般在C++中保留用途)
格式: int func(int,int=0);
1.早期用途:C++早期为了兼容C编译器或接口 保留参数
2.现在多用与保留就恶口扩展空间(预留未来版本功能)
PS:
1.占位参数没有变量名,不能在函数体内使用
2.函数种子很或函数重载时可能用到占位参数来保持统一接口
void demo(int a ,int) {
cout << "a=" << a << endl;
}
int main() {
demo(5,10);
return 0;
}