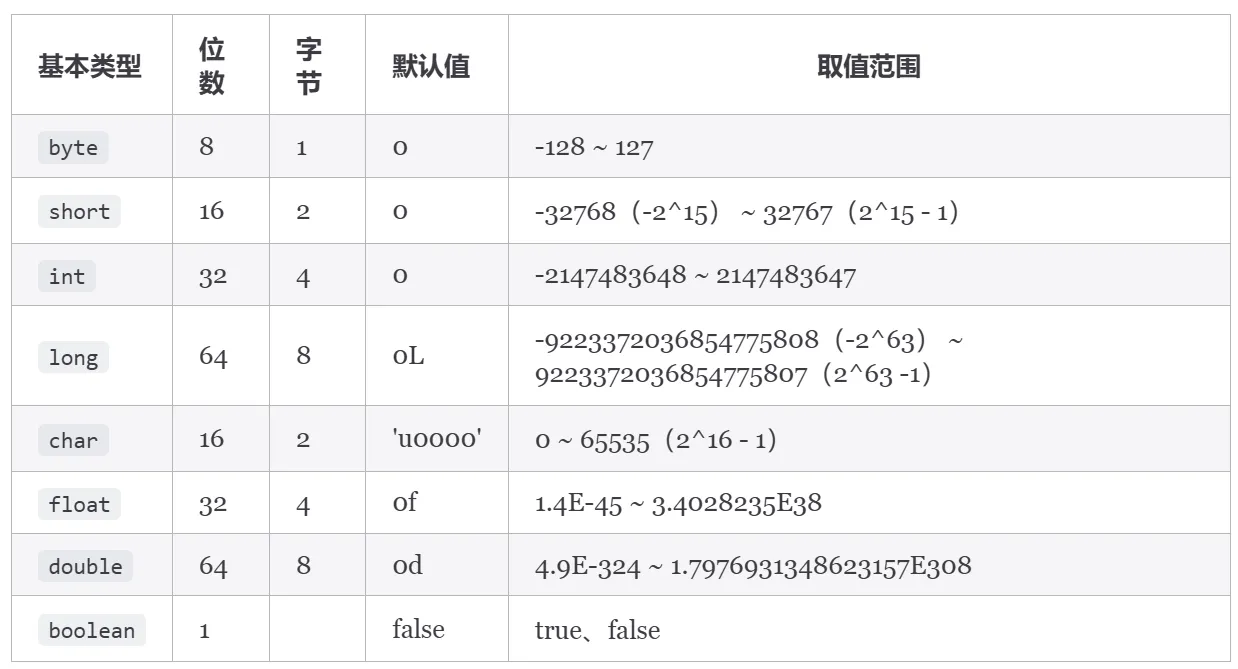
基本数据类型
Java 中基本数据类型?对应的包装类?占多少字节?
Java 中有 8 种基本数据类型:
- 6 种数字类型:
- 4 种整数类型:byte、short、int、long
- 2 种浮点类型:float、double
- 1 种字符类型:char
- 1 种布尔类型:boolean
基本数据类型与包装类型的区别?
Java 是一门面向对象的语言,很多情况下是需要用到对象的。例如:List 集合中存放的元素必须是对象。
为了让基本数据类型有对象的特性,在 JDK 1.5 引入了包装类,相当于把基本数据类型包装成了对象。
区别:
- 存储方式:基本数据类型存放在栈帧中(对象成员跟随对象);包装对象存放在堆中。
- 默认值:基本数据类型有各自的默认值;包装对象默认值为 null。
- 比较方式:基本数据类型用
==比较;包装对象==比较的是地址。
包装类型的缓存机制了解么?
包装类型大部分使用了缓存机制提升性能。 只有超出了缓存的范围才新建对象。
- Byte、Short、Integer、Long 创建了 [-128,127] 对应的缓存数据。
- Character 创建了数值在 [0,127] 范围的缓存数据。
- Boolean 直接返回 True / False。
- Float、Double 没有实现缓存机制。
所有整型包装类对象之间值的比较,全部使用 equals 方法比较。
Integer i1 = 24;
Integer i2 = 24;
System.out.println(i1 == i2);// 输出 true
// ------------------------
Integer t1 = 130;
Integer t2 = 33;
System.out.println(t1 == t2);// 输出 false
// ------------------------
Integer i1 = 40;
Integer i2 = new Integer(40);
System.out.println(i1 == i2); // false
// Integer i1 = 40 这一行代码会发生装箱,也就是说这行代码等价于 Integer i1 = Integer.valueOf(40)。
// 因此,i1 直接使用的是缓存中的对象。而 Integer i2 = new Integer(40) 会直接创建新的对象。因此,答案是 false。
// ------------------------
Integer a = 127;
Integer b = 127;
System.out.println(a == b); // true(因缓存复用)
// ------------------------
// 缓存范围外(错误)
Integer c = 128;
Integer d = 128;
System.out.println(c == d); // false(地址不同)
System.out.println(c.equals(d)); // true(值相等)
自动装箱、拆箱了解么?原理?
- 装箱:将基本数据类型,用对应的包装类型包装起来。
- 拆箱:包装类型转化为基本数据类型。
原理:
- 装箱:装箱其实就是调用了包装类的
valueOf()方法。 - 拆箱:拆箱其实就是调用了
xxxValue()方法。
Integer i = 10; // 装箱 Integer i = Integer.valueOf(10);
int n = i; // 拆箱 int n = i.intValue();
为什么浮点数计算时有丢失精度的风险?
浮点数在计算机中是以类似科学计数法存储的,计算机又是二进制的,计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。
float a = 2.0f - 1.9f;
float b = 1.8f - 1.7f;
System.out.printf("%.9f",a); // 0.100000024
System.out.println(b); // 0.099999905
System.out.println(a == b); // false
如何解决浮点数计算时精度丢失问题?
- BigDecimal 可以实现对浮点数的运算,不会造成精度丢失。
- 通常情况下,大部分需要浮点数精确运算结果的业务场景(涉及到钱的)都是通过 BigDecimal 来做的。
BigDecimal a = new BigDecimal("1.0");
BigDecimal b = new BigDecimal("1.00");
BigDecimal c = new BigDecimal("0.8");
BigDecimal x = a.subtract(c);
BigDecimal y = b.subtract(c);
System.out.println(x); /* 0.2 */
System.out.println(y); /* 0.20 */
// 比较内容,不是比较值
System.out.println(Objects.equals(x, y)); /* false */
// 比较值相等用相等compareTo,相等返回0
System.out.println(0 == x.compareTo(y)); /* true */
变量
局部变量、成员变量区别?
- 存储位置:局部变量存储在栈帧中;成员变量跟随对象存储在堆中。
- 生命周期:
- 局部变量跟随方法,方法调用局部变量生成,方法结束局部变量销毁。
- 成员变量跟随对象,对象回收,成员变量结束。
静态变量有什么用?
静态变量是 static 修饰的变量。
静态变量只有一份存放在堆中,被类的所有实例共享。
静态变量是属于 Class(类) 的,而不属于某个实例。
public class StaticVariableExample {
// 静态变量
public static int staticVar = 0;
}
- 通常情况下,静态变量会被 final 关键字修饰成为常量
public class ConstantVariableExample {
// 常量
public static final int constantVar = 0;
}
方法
重载、重写区别?
- 重载:同一个类中,允许有多个重名的方法,要求参数列表不同(参数的类型、顺序、个数不同)。
- 重写:发生在父类与子类之间,父类的方法无法满足需求时,子类可以重写父类的方法来满足需求。
静态方法为什么不能调用非静态成员?
- 静态方法是属于类的,在类加载的时就会分配内存,通过类名直接访问。
- 非静态成员属于实例对象,对象实例化之后才存在,通过类的实例对象去访问。
初始化时机不同:静态方法初始化时机早于非静态成员。
- 在类的非静态成员不存在的时候静态方法就已经存在了,此时调用在内存中还不存在的非静态成员,属于非法操作。
静态方法、实例方法区别?
- 方法调用:
- 调用静态方法时,使用 类名.方法名 的方式,一般作为工具类来使用。
- 实例方法只有 对象.方法名 的方式。
- 访问成员:
- 静态方法在访问本类的成员时,只允许访问静态成员,不允许访问实例成员,
- 实例方法不存在这个限制。
面向对象基础
面向对象、面向过程区别?
面向过程:把解决问题的过程拆分为一个个方法,依次执行这些方法。
面型对象:抽象出对象,通过对象之间的组合调用解决问题。
浅拷贝、深拷贝了解么?
- 浅拷贝:
- 创建一个新的对象,仅仅复制对象本身,并不会复制对象中引用字段所引用的对象。
- 新对象和原对象的引用类型字段指向同一对象,修改新对象中的引用数据类型会影响原对象。
- 深拷贝:
- 创建一个新的对象,不仅复制对象本身,还会以递归的方式复制对象中引用字段所引用的对象。
- 修改新对象中的引用数据类型不会影响原对象。
面向对象三大特征
- 封装:将类的内部信息隐藏起来,不允许外部程序直接访问,而是提供一些操作内部信息的方法。
- 继承:
- 继承的目的是代码复用
- 子类继承父类,子类就有了父类的属性和方法。
- Java 是单继承的,一个子类只能继承一个父类。
- 多态:
- 同一个行为有着不同的表现形式的能力。 在不改变代码的前提下,可以改变程序运行时绑定的代码。
- 实现多态三要素:继承、重写、父类引用指向子类对象。
- 静态多态性:通过重载实现,相同的方法有着不同的参数列表,可以根据参数的不同,调用不同的方法。
- 动态多态性:子类重写父类方法。运行期间判断对象的实际类型,根据对象的实际类型调用响应的方法。
多态怎么理解?
为了可维护 可扩展。
多态是同一个行为具有多个不同表现形式或形态的能力。
多态就是同一个接口,使用不同的实例而执行不同操作。
前提条件:必须有子父类关系。
多态体现为父类类型指向子类对象。
接口、抽象类区别?
接口和抽象类都不能实例化。
接口为了规范,抽象类为了复用。
接口:对某一行为抽象。
抽象类:对一类事物的抽象。
通用功能:抽象
区别:
Java中是现有的抽象类,再有的接口:
- 接口的设计,可以说是自上而下的,定义一个规范,有多种不同的实现,便于去扩展,并且针对行为。
- 抽象类的设计,可以说是自下而上的,发现有很多类的代码可以复用,就抽象成抽象类,保留了属性,针对属性和可复用。接口则是抽象成只剩方法了。
举个例子:
两个中国人在美国生下了一个孩子,他是哪国人? 一般来说是美国人?为什么?
- 因为他说英文,吃西餐,有着美国人的生活习惯。所以他是美国人。这其实就是实现了接口的类,有一套规范的行为。
- 但是这个人他的基因跟美国人不一样,他是中国人的基因。这就是 抽象类,本质的属性和美国人不一样!
Object
== 和 equals 区别?
- 对于基本数据类型,
==比较值;基本数据没有 equals。 - 对于引用数据类型,
==比较地址;equals 默认比较地址(等价于==),重写了 equals,比较对象内容。
hashCode() 有什么用?
获取哈希码,哈希码作用是确定对象在哈希表中的位置。
如果不重写,根据对象的地址计算的哈希码;如果重写,根据类中的字段来计算的哈希码。
- HashSet 中,存入对象时,计算对象的 hashCode 值(决定了对象在哈希表中的存储位置)。如果 2 个对象的 hashCode 值不同,就认为它们不相同,不在需要比较。
- 如果 hashCode 值相同(发生哈希冲突),进一步使用 equals() 方法判断是否真的相同。
通过这种方式,先比较 hashCode 值可以避免每次都调用 equals(),从而大大提高性能。
- 如果两个对象的 hashCode 值不相等,认为这两个对象不相等。
- 如果两个对象的 hashCode 值相等,那这两个对象不一定相等(哈希碰撞)。
- 如果两个对象的 hashCode 值相等并且 equals()方法也返回 true,我们才认为这两个对象相等。
为什么重写 equals() 时,一定要重写 hashCode() ?
假设对象 obj1 和 对象 obj2** 通过 equal()s 比较相等**,是同一个对象,但 hashCode() 不同。
那么将这两个对象放入 HashSet 中时,由于 hashCode() 不同会被认为不同的对象(即使是同一个对象),可能出现重复存储的情况。
所以,在重写 equals() 时,一定要重写 hashCode() ,确保它们之间的一致性。
hashCode 依赖的字段最好是不变的,如果易变,可能出现这种情况:把一个对象放入 map 中,然后更改这个对象的属性,那么这个对象的 hashCode 也会变,那么再get时,就get不出来了。
String
Java 中 String 为什么不是基本数据类型?
Java 中 String 是引用类型。
因为 String 是一个复杂的对象,提供了许多关于字符串的操作,例如:连接、比较、查找子串等。
与 String 相比,基本数据类型(int,char等)是 Java 语言内置的。占用固定大小内存,直接存储,而不是引用对象。
内存管理:
- 基本数据类型:存放在栈帧中,栈内存分配速度快,空间小。
- 引用数据类型:存放在堆中,堆内存空间较大,可以存储更多的数据。
使用堆内存存储String对象可以更有效地管理内存。
Java 有字符串常量池机制。
String、StringBuffer、StringBuilder 区别?
- 可变性: String 不可变; StringBuffer、StringBuilder 可变。
- 线程安全:
- String 不可变,因此是线程安全的;
- StringBuffer 是线程安全的,内部使用 synchronized 进行同步;
- StringBuilder 不是线程安全的;
- 使用场景:
- 操作少量的数据: 适用 String
- 单线程且操作大量数据: 适用 StringBuilder
- 多线程且操作大量数据: 适用 StringBuffer
String 为什么不可变?
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char[] value;
/** Cache the hash code for the string */
private int hash; // Default to 0
}
- String 类本身是 final 修饰的,防止子类对其修改。
- 字符数组被 final 修饰,这仅仅是引用不可变,数组里面的值是可变的;
- String 类的字符数组是私有的,并且没有对外提供修改字符数组的方法;
- 字符数组被 private 修饰且没有对外提供修改的方法
- String 的不可变性是由于其底层的实现,而不仅是一个final。
String 为什么要设计成不可变的?
- 安全性:String 的用处很广泛,设计成不仅可变的就不用考虑线程安全问题。
- hashCode 值固定:不可变的话,哈希值就固定下来了。(哈希值存放在对象头中),String 类型经常hash,不可变就可以复用哈希值,提高效率。
- **字符串常量池:**创建 String 对象时,先检查字符串常量池中有没有,有的话直接返回该字符串的引用。
- 这种机制依赖 String 的不可变性,因为字符串一旦创建就不能修改,常量池中的字符串可以安全地共享给多个地方使用,节省内存并提高性能。
String str = new String(“abc”) 会创建几个对象?
1 个 或 2 个。
- 字符串常量池中的对象:字面量 “abc”,JVM 会检查字符串常量池中有没有 “abc”,没有的话,创建 “abc” 这个对象,并放入字符串常量池中。
- 堆中的对象:new String(“abc”) 会在堆内存中创建一个新的 String 对象,这个新对象包含了 “abc” 的内容。 即使常量池中已经有了 “abc”,new String() 还是会在堆内存中创建一个新的 String 实例。
注意:此时 str 指向的是堆中的对象。
异常
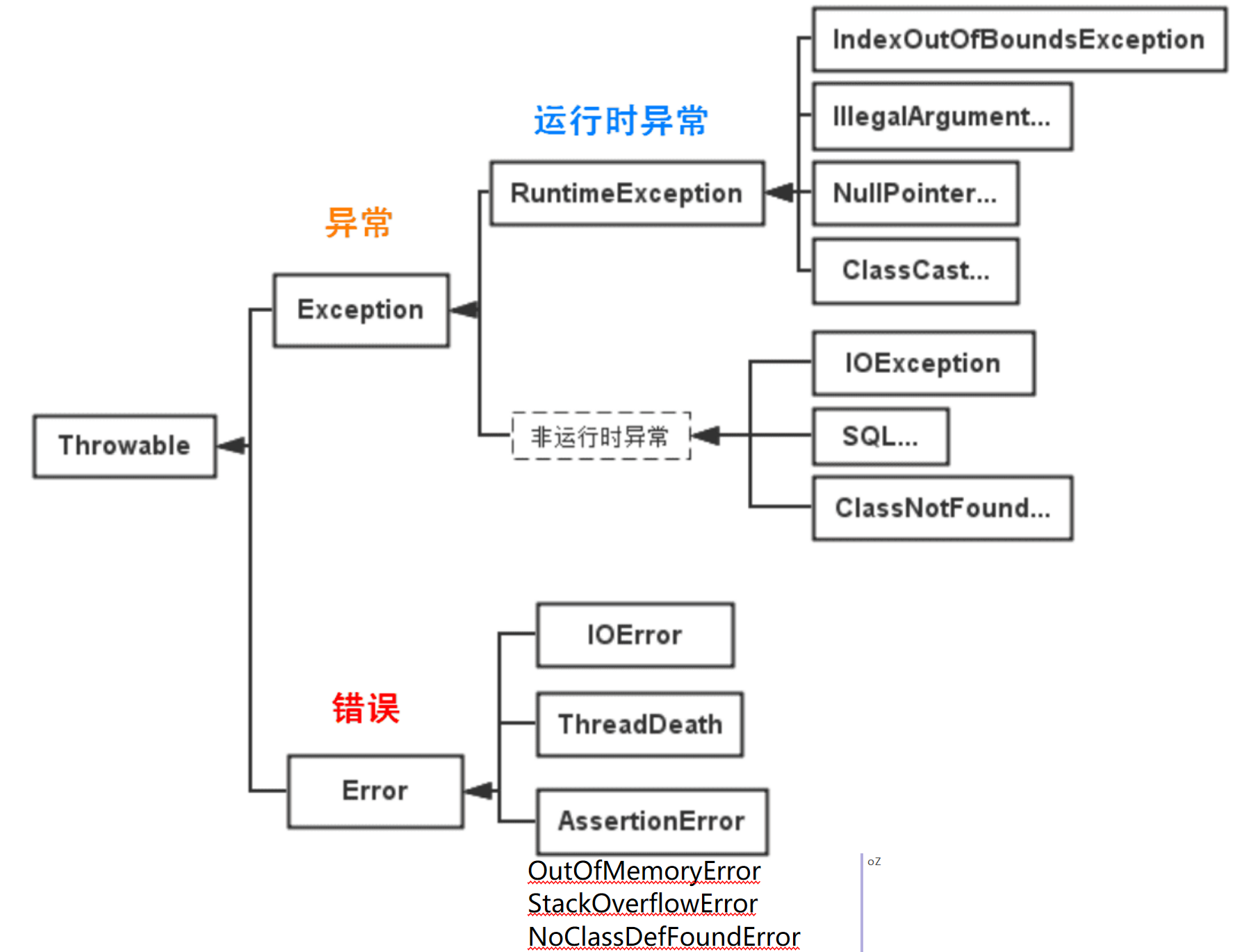
Exception 和 Error 区别?
- Exception:程序自身可以处理的异常,可以使用 try-catch 进行捕捉。
- Exception 分为 Checked Exception (受检查异常,必须处理) 和 Unchecked Exception (不受检查异常,可以不处理)。
- Error:程序无法处理的错误,不建议通过 try-catch 进行捕捉。
- 例如 Java 虚拟机运行错误(Virtual MachineError)、虚拟机内存不够错误(OutOfMemoryError)。
- 这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。
try-catch-finally 中 finally 一定会执行吗?
不一定执行。
- try 或 catch 中死循环
- 虚拟机退出
- 守护线程中可能不走 finally 就被回收了
throw、throws 区别?
- throw:方法内部抛出一个具体的异常。
- throws:指明该方法可能会抛出的异常,由调用的方法处理或继续向上抛。
class Test {
// throws 用于方法头,声明该方法可能会抛出异常
public void methodA() throws Exception {
throw new Exception("抛出异常");
}
public void methodB() {
try {
// throw 用于方法内部,抛出异常
throw new Exception("抛出异常");
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
}
Java 注解的理解?解决了什么问题?
Annotation (注解) 是 Java5 开始引入的新特性,可以看作是一种特殊的注释,主要用于修饰类、方法或者变量,提供某些信息供程序在编译或者运行时使用。
Java 泛型了解么? 什么是泛型擦除? 介绍一下常用的通配符?
泛型允许在定义类和接口时使用类型参数。 声明的类型参数在使用时被具体的类型替换。 增强代码复用性。
Java 中的泛型通过类型擦除来实现。
通俗点理解,就是通过语法糖的形式,在 **.java -> .class** 转换的阶段,将 List 擦除掉转为 List,Java 的泛型只发生在编译期。这么设计是为了兼容 JDK5 之前的代码。
public class Foo<T> {
T bar;
void doSth(T param) {
}
};
Foo<String> f1;
Foo<Integer> f2;
// 在编译后的字节码文件中,会把泛型的信息擦除掉:
public class Foo {
Object bar;
void doSth(Object param) {
}
};
无界通配符(Unbounded Wildcard) - ?
可以表示任何类型
上界通配符(Upper Bounded Wildcard) - ? extends Type
类型必须是Type本身或者子类
下界通配符(Lower Bounded Wildcard) - ? super Type
类型必须是Type本身或者父类
Java 反射?反射有什么缺点?你是怎么理解反射的(为什么框架需要反射)?
反射赋予了程序在运行时分析类以及执行类中方法的能力。
通过反射可以获取任意一个类的属性和方法。
框架: 框架中也大量使用了动态代理,而动态代理的实现也依赖反射。
动态代理有几种实现方式?
2 种:
- JDK 原生动态代理
- CGLIB 动态代理
JDK 原生动态代理是 Java 原生支持的,不需要任何外部依赖,但是它只能基于接口进行代理(需要代理的对象必须实现于某个接口)
CGLIB 通过继承的方式进行代理(让需要代理的类成为 Enhancer 的父类),无论目标对象有没有实现接口都可以代理,但是无法处理 final 的情况。
集合
Java 常见集合?
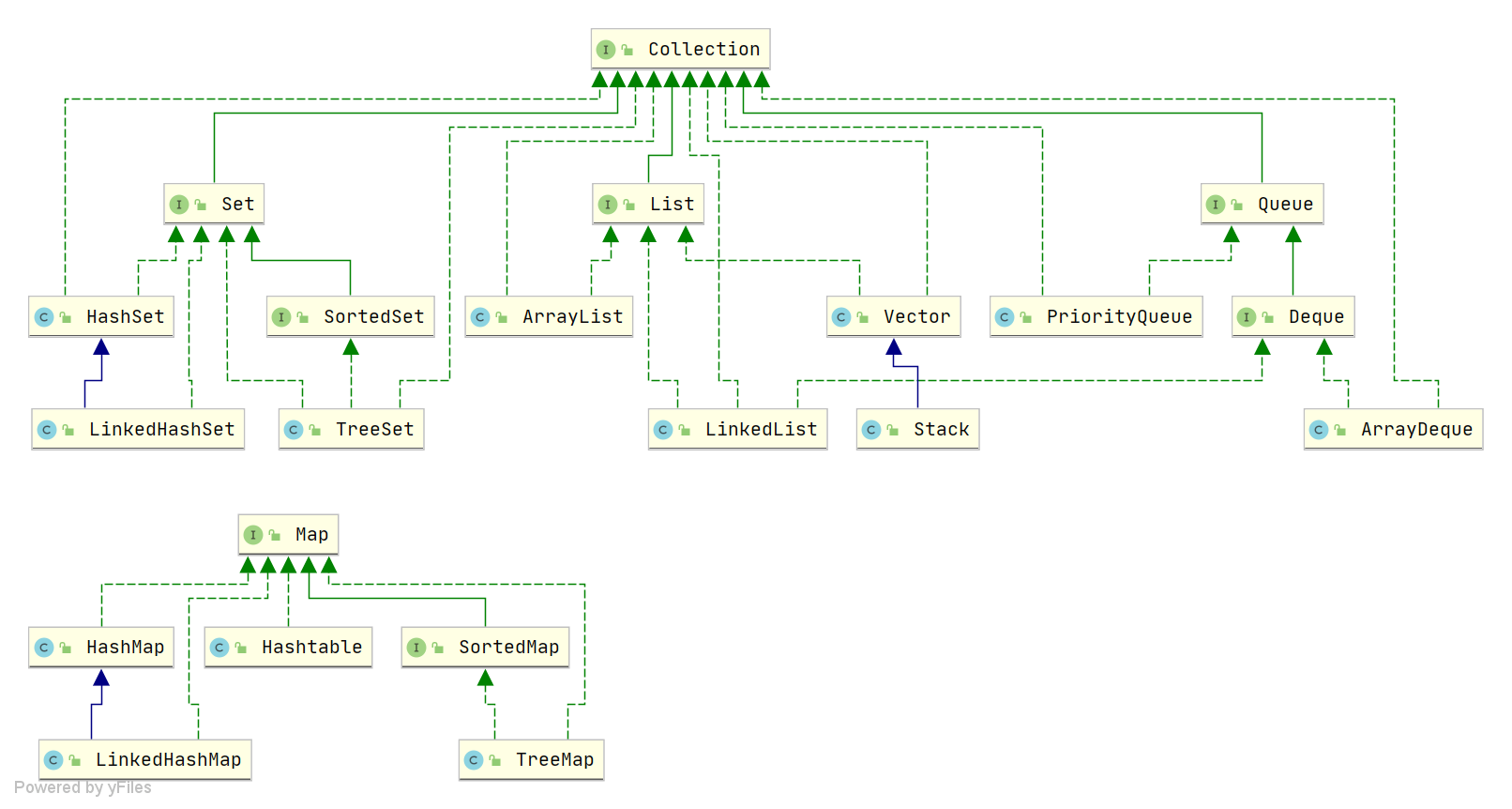
- 单列集合:单列集合有
Set、List、Queue- Set:HashSet
- List:ArrayList
- Queue。
- 双列集合:双列集合主要就是 Map ,常见 Map 有
HashMap ,TreeMap ,ConcurrentHashMap。
List
- 快速失败、快速安全:使用增强 for 循环时,修改集合元素会抛异常。
- foreach 底层是迭代器。迭代器在调用 next() 方法时,会比较
modCount、expectModCount,不同就抛异常。 - 调用集合的修改方法,只更新了 modCount,没有更新 expectModCount。
- foreach 底层是迭代器。迭代器在调用 next() 方法时,会比较
COW(CopyOnWrite)是一种快速安全。
遍历时需要修改:
- 普通for
- 迭代器 用迭代器的修改方法
- COW(CopyOnWrite写时复制)
- 线程安全的CurruentHashMap
- stream流
排序:
- 自然排序 Compareble 实现 compareTo
- 定制排序 Comparetor 实现 compare
- stream流的 sort ,底层基于 compareble
- 判断一致? compareTo 返回值为 0
ArrayList
ArrayList 扩容机制?
- ArrayList 每次扩容是原来的 1.5 倍。
- 扩容时,将原数组的元素重新拷贝一份到新的数组中。
- 扩容时要拷贝,代价是很高的,使用时尽量指定容量,避免扩容数组。
- 创建方式方式不同,容量不同。
| 初始化方式 | 初始容量 | 容量变化 |
|---|---|---|
| List list = new ArrayList(); | 初始容量为 0,add() 添加时,才真正分配 10 容量。 | 10->15->22->33->49->74->… |
| List list = new ArrayList(4); | 4 | 4->6->9->13->19->… |
ArrayList 插入和删除元素时间复杂度?
- 插入:
- 头部插入,所有元素都要往后移,O(n)
- 尾部插入,O(1)
- 指定位置插入,平均需要移动 n/2 ,O(n)
- 删除:
- 头部删除:所有元素都要往前移,O(n)
- 尾部删除,O(1)
- 指定位置删除,平均需要移动 n/2 ,O(n)
ArrayList、数组的区别?
ArrayList 底层是基于数组的,支持插入、删除等操作,还支持动态扩容缩容,比静态数组更加灵活。
ArrayList 可以添加 null 值吗?
可以添加,但添加没有任何意义,还可能出现空指针异常。
ArrayList 指定了泛型为 Integer,可以添加 String 吗?
可以。通过反射添加。
泛型工作在编译期,反射工作在运行阶段。
通过反射获取到 add() 方法,再添加。
LinkedList
LinkedList 添加、删除元素的时间复杂度?
LinkedList 底层基于双向链表。
- 添加:
- 头部、尾部添加均为O(1)
- 指定位置添加,需要遍历,O(n)
- 删除:
- 头部、尾部删除均为O(1)
- 指定位置删除,需要遍历,O(n)
ArrayList、LinkedList 比较?
- 都实现了 List 接口。
- ArrayList 基于数组;LinkedList 基于链表。
- ArrayList
- 查询快,增删慢
- 数组尾部添加快(add(obj)),但还是没有 LinkedList 快。
- LinkedList
- 增删快,只需要改变指针指向。
- 查询平均效率低,需要遍历链表。
CopyOnWriteArrayList
ArrayList 是线程不安全的。
线程安全的 Vector 使用了 sychronized ,性能低下。
CopyOnWriteArrayList 是线程安全的 ArrayList。采用了写时复制(CopyOnWrite)的思想。
当需要进行修改操作,不会直接修改原数组,而是创建一个副本数组,对副本数组进行修改,修改完之后再将指针指向新数组,就可以保证写操作不会影响读操作,实现了只有写写才需要加锁,读写不需要加锁。
适合读多写少的场景。
缺点:需要占用一定内存开销,并且写操作需要复制,写操作频繁情况下性能会有影响。
synchronizedList
线程安全的 List。仅仅是对方法加了 sychronized,并没有优化。
Set
Set 存储的元素是唯一的。
HashSet
底层是 HashMap 的 Key。
可以有一个 null 值。
元素对象需要重写 hashCode 和 equals 方法,确保元素是唯一的。如果没有重写默认根据地址比较。
HashSet 如何检查重复元素?
对象放入 HashSet 时,计算对象的 hashCode 判断放入的位置。
如果 HashSet 中没有相同的 hashCode ,直接放入即可。
如果有,进一步根据 equals 比较是否相等,不相等可以放入。
LinkedHashSet
底层是 LinkedHashMap 的 Key。
保证元素插入的顺序,先进先出。
TreeSet
底层是 TreeMap 的 Key。 不允许有 null 值。
可以对元素进行自定义排序。
Queue
queue 是单向队列,先进先出。 队尾插入数据,队头删除数据。
PriorityQueue
优先队列,基于堆实现。 优先级高的元素先出队列。
BlockingQueue
阻塞队列。
队列中没有元素时,阻塞,不允许取元素;队列满时,阻塞,不允许添加元素。
常用于生产者消费者模型。
- ArrayBlockingQueue 数组实现的有界的阻塞队列
- LinkedBlockingQueue 单向链表实现的无界的阻塞队列
- SynchronousQueue 同步队列,没有容量,插入操作需要阻塞等待删除操作,删除操作也需要阻塞等待插入操作,通常用于高效率的线程传递数据操作
- DelayQueue 延迟的阻塞队列,元素到达指定的延迟时间才能出队
- PriorityBlockingQueue 无界的优先级阻塞队列,需要自然排序或定制排序
Map
通过 Key 快速查找 value。Key 不可重复,value 可重复。
HashMap
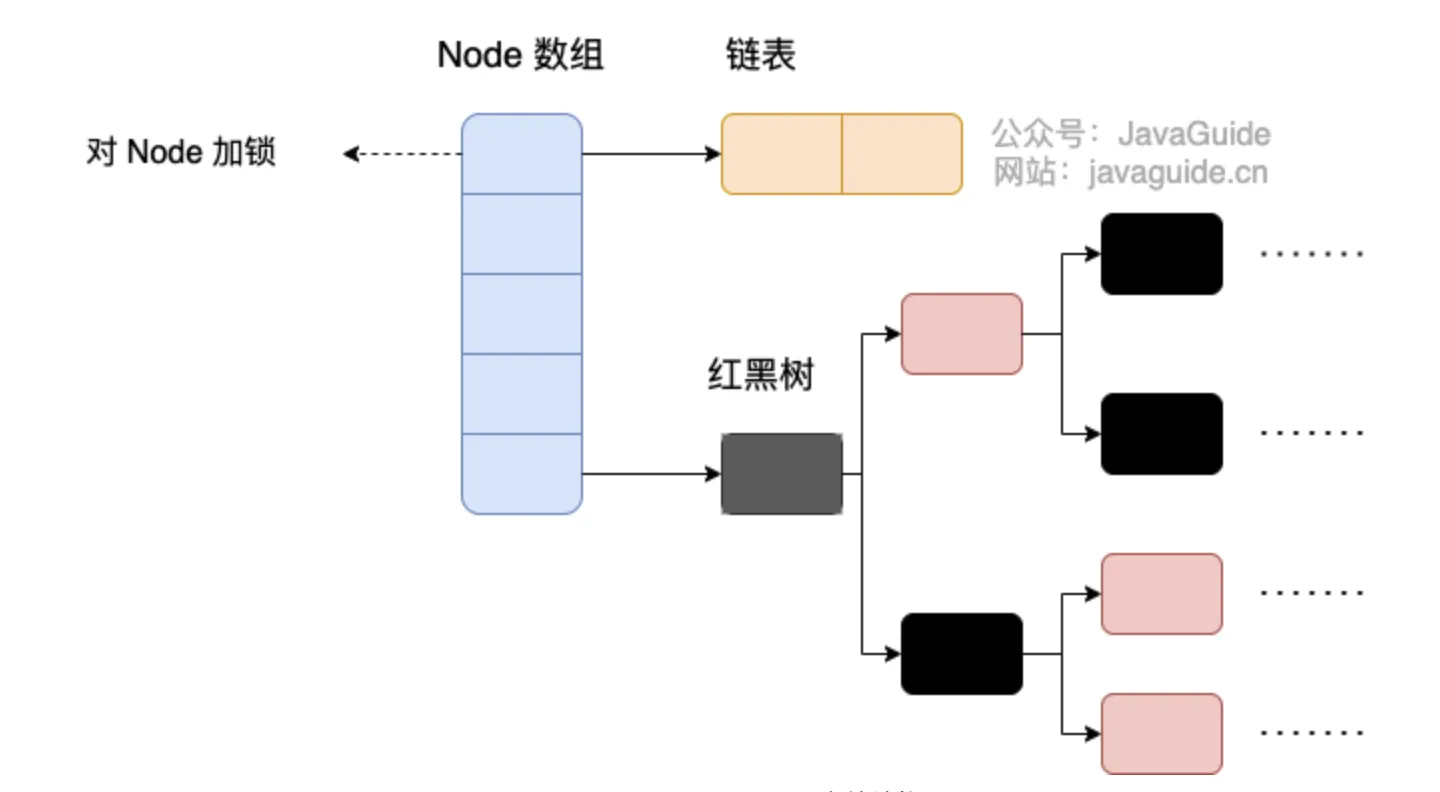
底层数据结构
- 1.7 数组 + 链表
- 1.8 数组 + (链表 | 红黑树)
树化与退化
树化的意义:
- 避免 DDoS 攻击,防止链表过长性能下降,树化应是偶然情况,是保底策略。
- Hash 表查询、修改复杂度为 O(1);红黑树查询、修改复杂度为 O(
log(n))。 - TreeNode 占用空间比 Node 占用空间要大,不是必要情况,尽量使用链表
- hash 值足够随机,则在 Hash 表内按泊松分布。
- 负载因子为 0.75 时,出现链表长度为 8 的概率为 0.00000006,树化阈值选择 8 就是为了让树化几率足够小。
树化应当是极其偶然的情况,链表短的情况下没必要树化,效率不会低,数据结构占用内存也比红黑树要少;
树化规则:
当链表长度超过树化阈值 8 时,先尝试扩容来减少链表长度,如果数组容量已经 >=64,才会进行树化。
退化规则:
- 情况1:在扩容时如果拆分树时,树元素个数 <= 6 则会退化链表
- 情况2:remove 树节点时,若 root、root.left、root.right、root.left.left 有一个为 null ,也会退化为链表
索引计算
- 计算对象的 hashCode()
- 再调用 HashMap 的 hash() 方法进行二次哈希
- 二次哈希是为了综合高位数据,让哈希分布更为均匀
- 最后 &(size - 1)得到索引
hash & (size - 1) ,其实就相当于 hash % size ,只有 size 为 2 的次幂时成立。
数组容量为什么是 2 的 n 次幂?
- 索引计算更高效:2 的 n 次幂的话,取模(%)运算 优化为 位运算(&)
- 扩容时重新索引计算更高效:
hash & oldCap == 0的元素留在原地,否则 新位置 = 旧位置 + oldCap
注意:
- 二次哈希 的前提是 数组的容量是 2 的 n 次幂,如果数组容量不是 2 的 n 次幂,不用进行二次哈希。
- 容量是 2 的 n 次幂 这一设计索引计算效率更好,但 hash 的分散性就不好,需要二次 hash 来作为补偿,没有采用这一设计的典型例子是 Hashtable
put 流程
- HashMap 是懒加载的,首次使用时才创建数组
- 计算索引(桶下标)
- 如果索引位置没有元素占用,创建 Node 占位返回
- 如果索引位置已经被占用
- 位置上是 TreeNode 走红黑树的逻辑
- 位置上是 Node 走链表的逻辑,如果链表长度超过树化阈值,则进行树化。
- 返回前检查容量是否超过阈值,超过就进行扩容
1.7 、1.8 区别?
- 节点插入:1.7 头插法;1.8 尾插法
- 扩容:1.7 是 大于等于阈值且没有空位时才扩容;1.8 是大于阈值就扩容
- 1.8 计算索引时会优化。
扩容因子为什么默认是 0.75?
- 在空间占用与查询时间之间取得较好的权衡
- 大于这个值,空间节省了,但链表就会比较长影响性能
- 小于这个值,冲突减少了,但扩容就会更频繁,空间占用也更多
get 流程
- 计算 hash 值
- 定位桶索引
- 通过 hashCode() 和 equals() 与桶的第一个元素比较
- 相同就返回第一个元素
- 不相同,判断桶的位置上是链表还是红黑树,然后走对应的查找逻辑。
并发问题
- ** 扩容死链(1.7)**
- 1.7 扩容采用头插法。有两个变量,一个是 e ,指向桶的第一个元素,一个是 next ,指向 e 的下一个元素
- 扩容时 next 指向 e 的下一个元素,将 e 头插到新的hash表中, e 指向 next 。 然后继续循环。直到 next 为空
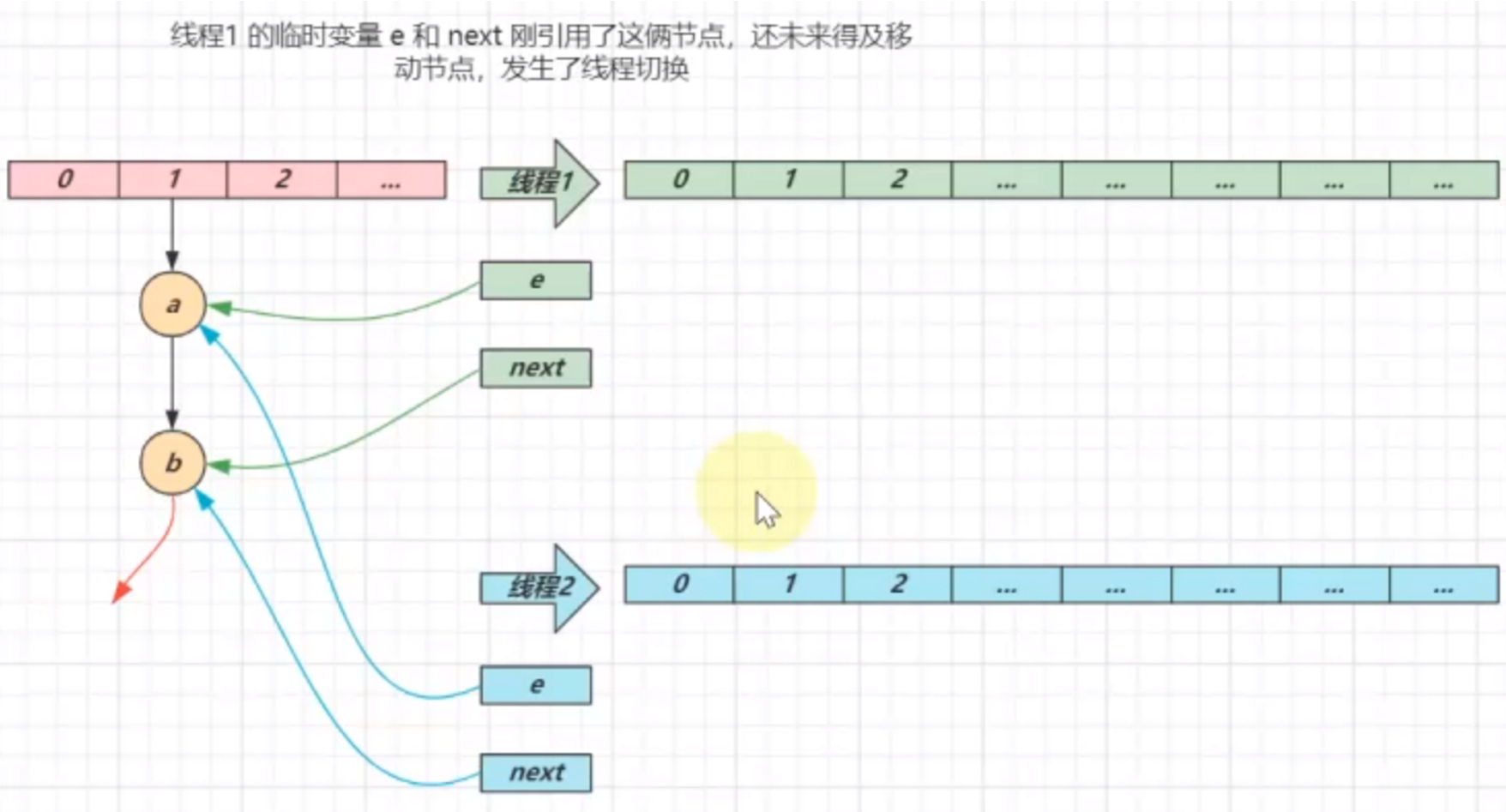
假设 map 中元素为 a -> b -> null
t1 线程中 a[e] -> b[next] -> null 被挂起
t2 线程扩容过程:
a -> null
b -> a -> null
回到 t1 线程中 b[next] -> a[e] -> null,进行扩容
t1 扩容流程:
扩容之后数组 ; 扩容前的数组
a -> null ; b[e] -> a[next] -> null
b -> a -> null ; b -> a[e] -> null[next]
a <-> b (发生死链)
- **数据错乱,覆盖数据(1.7、1.8) **
1. 两个线程同时准备 put 数据到相同桶下标,t1 线程判断发现要放入的桶是 null ,就把自己包装成 Node 节点准备插入,此时还没插入;
2. t2 判断,发现要放入的桶也是 null ,也把自己包装成 Node 节点准备插入,这时就会产生覆盖丢失数据
key 的设计
- HashMap 的 key 可以为 null ,其他 Map 的实现不可以。
- 作为 key 的对象,必须实现 hashCode 和 equals ,并且 key 的内容不可以修改(不可变)。
- key 可变的话,修改 key 之后会查不到(hahsCode 变了)。
- key 的 hashCode 应具有良好的散列性。
哈希冲突解决办法
- 拉链法:哈希冲突时,同一个哈希槽拉成一个链表,HashMap采用该方法
- 开放寻址:寻找其他位置,这就保证了一个哈希槽最多存有一个元素
- 线性探测:哈希冲突时,按顺序往后查找,直到找到第一个为空的槽位,ThreadLocalMap采用该方法
- 二次探测:与线性探测类似,但有规律,比如每次步长是1,2,4,8,16。。。
- 再哈希法:哈希冲突时,换个哈希函数再次哈希
其他 Map
LinkedHashMap
链表代替数组,保证插入顺序。
TreeMap
需要自然排序或定制排序。
HashTable
底层数据结构
数组 + 链表
数组用于存储哈希桶,链表用于解决哈希冲突。
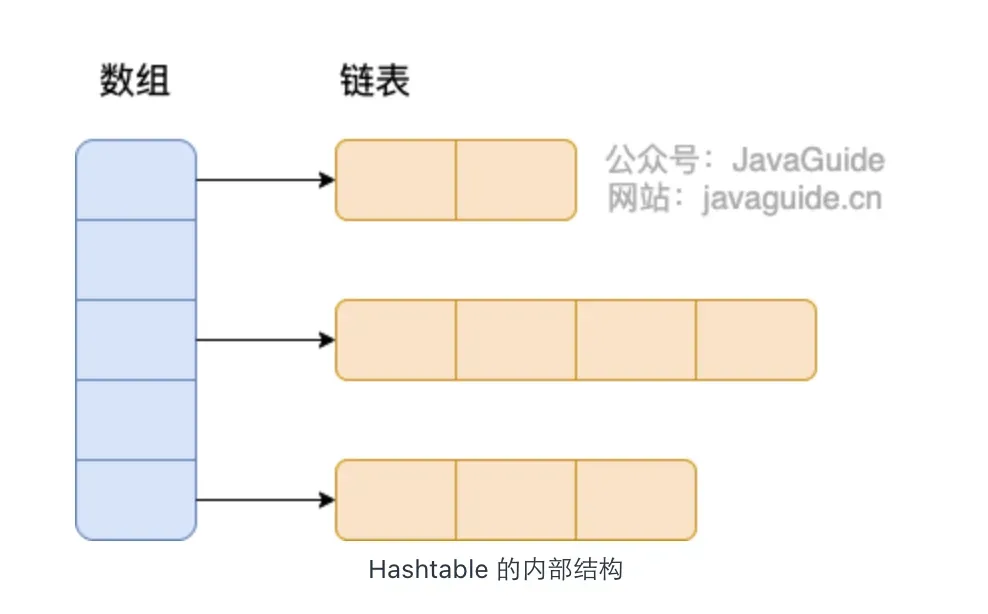
HashTable 保证线程安全的方式?
Hashtable 保证线程安全的方式是使用同一把锁,锁住整个数组。
Hashtable(同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。
当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈,效率越低。
ConcurrentHashMap
HashMap 是线程不安全的,ConcurrentHashMap 和 Hashtable 是线程安全的,推荐使用ConcurrentHashMap。
底层数据结构
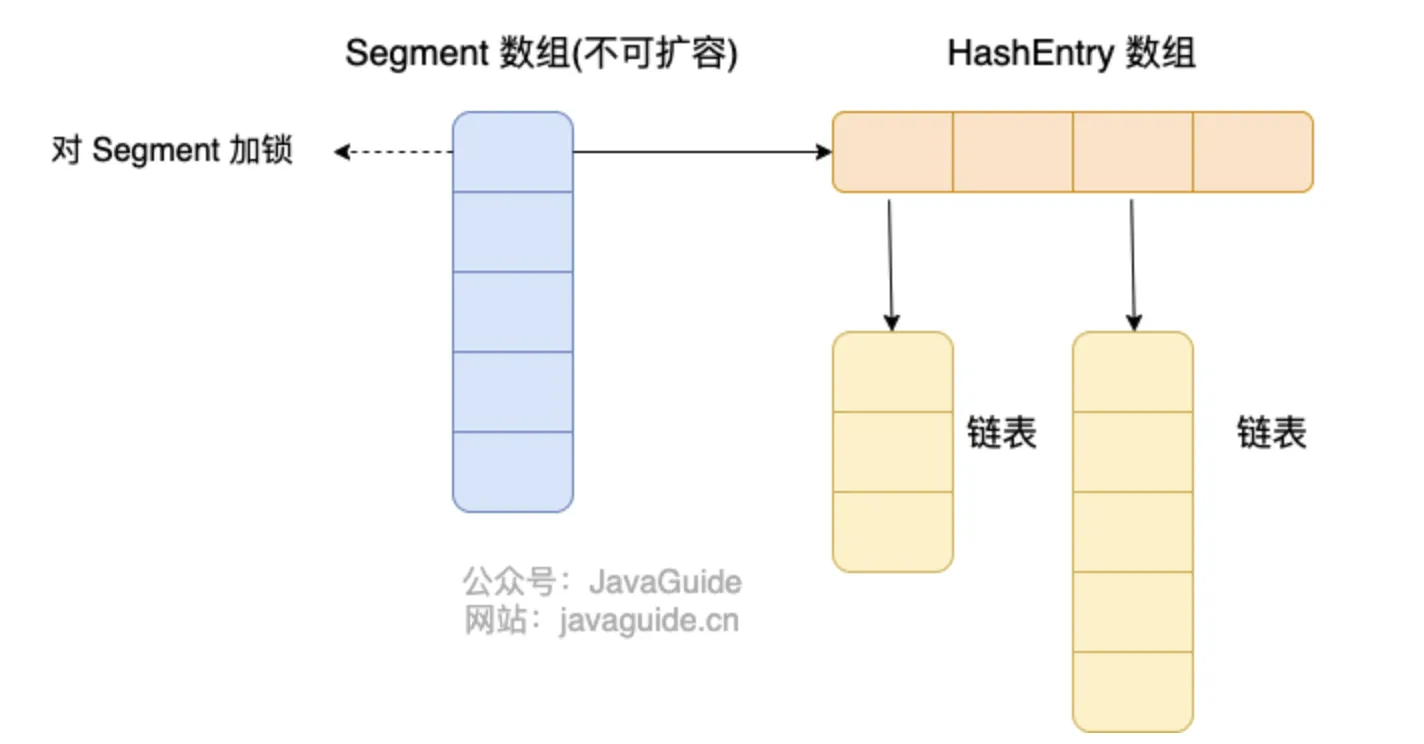
- JDK 1.7 :分段数组 + 链表
- JDK 1.8 :数组 + (链表 | 红黑树) (CAS + Sync)。
ConcurrentHashMap 线程安全的实现方式
- **JDK 1.7 **,ConcurrentHashMap 在对象中保存了一个 Segment 数组。
- 每个Segment元素类似于一个 **Hashtable **;这样,在执行put操作时首先根据hash算法定位到元素属于哪个Segment,然后对该Segment加锁即可,不同的Segment可以并发put。
- Segment 的锁实现其实是 ReentrantLock ,同一个Segment读写可以并发
- JDK 1.8,并发控制使用** synchronized 和 CAS **来操作。
- ConcurrentHashMap 整个看起来就像是优化过且线程安全的 HashMap
- 虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;