这是一个基于OpenAI的Whisper模型的语音识别应用程序,使用PyQt5构建了简洁直观的用户界面。该应用支持多语言识别,特别优化了中文识别体验。
项目下载:链接
功能特点
- 简洁现代的深色主题界面
- 支持多语言识别(中文、英语、日语等)
- 中文繁简转换功能,自动将繁体中文转为简体
- 内置音频播放功能
- 异步识别过程,避免界面卡顿
- 实时显示识别进度和状态信息
系统要求
- Ubuntu 18.04 或更高版本
- Python 3.8 或更高版本
- 至少 4GB RAM(使用base模型)
依赖安装 (Ubuntu)
1. 系统依赖
首先安装必要的系统依赖:
# 更新包索引
sudo apt update
# 安装基础依赖
sudo apt install -y python3-pip python3-dev python3-venv
# 安装ffmpeg (Whisper音频处理必需)
sudo apt install -y ffmpeg
# 安装mpv播放器 (用于音频播放功能)
sudo apt install -y mpv
# 安装Qt依赖
sudo apt install -y libqt5widgets5 libqt5gui5 libqt5core5a2. 创建虚拟环境 (推荐)
# 创建虚拟环境
python3 -m venv whisper_env
# 激活环境
source whisper_env/bin/activate3. 安装Python依赖
# 更新pip
pip install --upgrade pip
# 安装必要的Python包
pip install openai-whisper==20230314 # Whisper语音识别模型
pip install torch==2.0.1 # PyTorch (Whisper依赖)
pip install PyQt5==5.15.9 # 图形界面框架
pip install zhconv==1.4.3 # 中文繁简转换
pip install numpy==1.24.3 # 数值计算库 (Whisper依赖)
pip install tqdm==4.65.0 # 进度条显示运行应用
- 下载项目
- 激活虚拟环境(如果你使用了虚拟环境):
source whisper_env/bin/activate- 启动应用程序:
python main.py使用指南
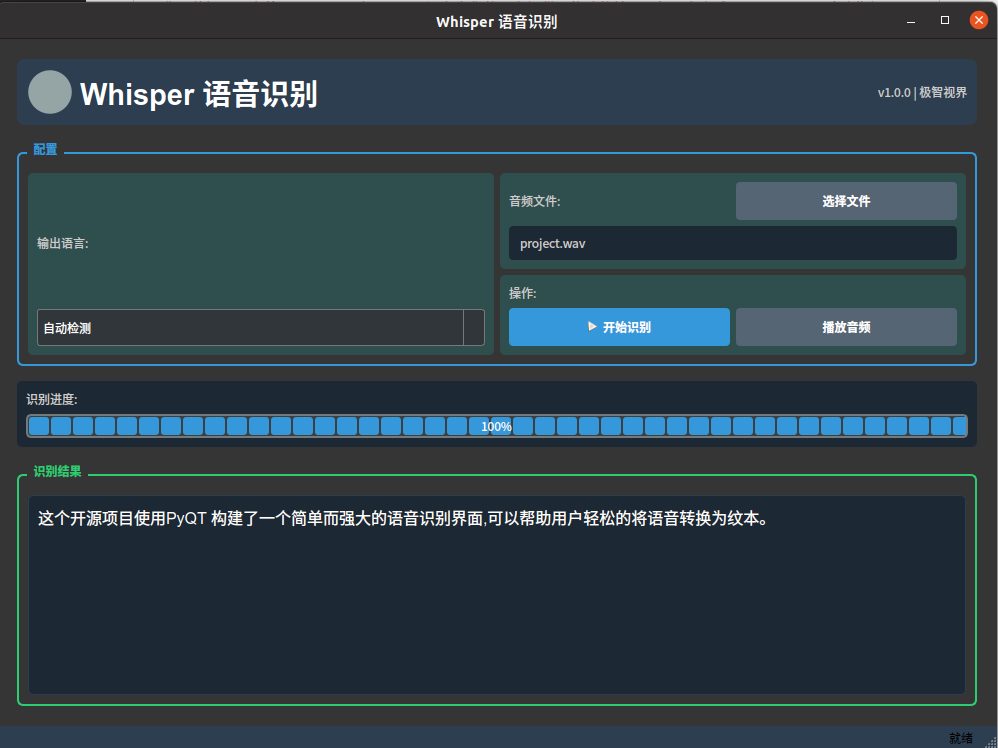
- 选择语言:从下拉菜单中选择输出语言(可选,默认自动检测)
- 选择音频文件:点击"选择文件"按钮,选择要识别的音频文件
- 开始识别:点击"开始识别"按钮开始处理
- 播放音频:可以使用"播放音频"按钮来回放选择的音频文件
- 查看结果:识别完成后,结果将显示在底部的文本区域、
支持的音频格式
- MP3 (.mp3)
- WAV (.wav)
- FLAC (.flac)
- M4A (.m4a)
- OGG (.ogg)
常见问题
- 首次使用较慢:首次运行时,应用会自动下载Whisper模型文件,根据网络速度可能需要几分钟到几十分钟不等。
- 中文识别:应用支持中文识别,并自动将繁体中文转换为简体中文。
- 内存使用:默认使用的"base"模型大小适中,内存消耗约为1GB。
关于Whisper模型
Whisper是OpenAI开发的通用语音识别模型,它在大量多样化的音频数据上进行训练,并能够执行多语种语音识别、语音翻译、语言识别和语音活动检测等任务。
更多信息请参考Whisper GitHub仓库。