一、初始索引
索引的核心工作是提高数据库性能的,MySQL的服务器,本质是在内存中的,所有数据库的CURD操作,全部都是在内存中进行的,索引也是如此。影响算法效率的因素有两个:组织数据的方式和算法本身。索引就是更改数据组织的方式,从而提高算法效率。
索引是物美价廉的东西了。不用加内存,不用改程序,不用调sql,只要执行正确的
create index ,查询速度就可能提高成百上千倍。但是天下没有免费的午餐,查询速度的提高是以插入、更新、删除的速度为代价的,这些写操作,增加了大量的IO。所以它的价值,在于提高一个海量数据的检索速度。
二、MySQL与储存
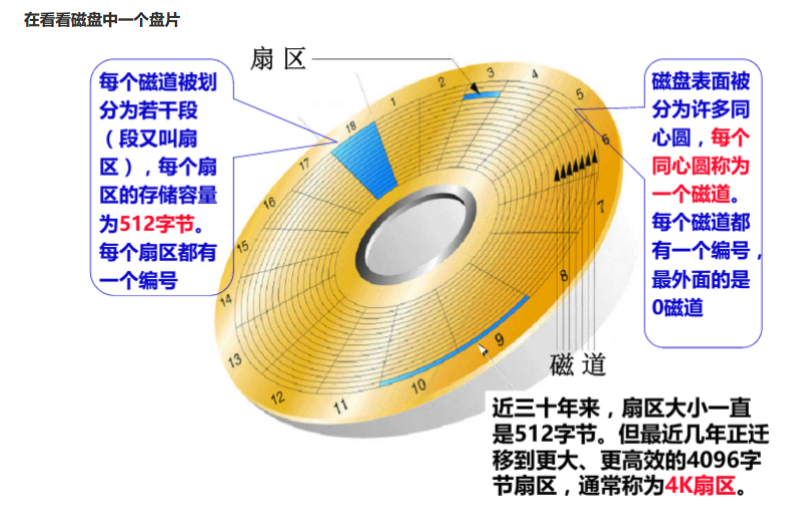
数据库文件,本质就是保存在磁盘的盘片中,也就是上面的一个个扇区中,数据库文件很大,因此会占据多个扇区。定位一个扇区需要知道柱面-磁头-扇区,系统读取磁盘,是以块为单位的,而不是扇区,基本单位是4KB。磁盘随机访问是本次IO给出的扇区地址和上次的扇区地址不连续,磁头需要较大移动动作才能重新开始读写,尽管相邻的两次IO操作在同一时刻发出,但如果它们的请求的扇区地址相差很大的话也只能称为随机访问,而非连续访问。
三、软件理解
MySQL作为一个应用级软件,可以想象成一种特殊的文件系统,它有着更高的IO场景,为了提高IO效率,MySQL进行IO的基本单位是16KB,这个基本数据单元,在MySQL里叫做page。
MySQL 将数据以页(page)为单位存储在磁盘中。在执行增删改查(CURD)操作时,系统需要通过计算来定位数据插入位置,或查找待修改、查询的具体数据。
而只要涉及计算,就需要CPU参与,而为了便于CPU参与,一定要能够先将数据移动到内存当中。所以在特定时间内,数据一定是磁盘中有,内存中也有。后续操作完内存数据之后,以特定的刷新策略,刷新到磁盘。而这时,就涉及到磁盘和内存的数据交互,也就是IO了。而此时IO的基本单位就是Page。
为了更好的进行上面的操作, MySQL 服务器在内存中运行的时候,在服务器内部,就申请了被称为 Buffer Pool 的的大内存空间,来进行各种缓存。其实就是很大的内存空间,来和磁盘数据进行IO交互。总之就是一句话:为了更高的效率,一定要尽可能的减少系统和磁盘IO的次数。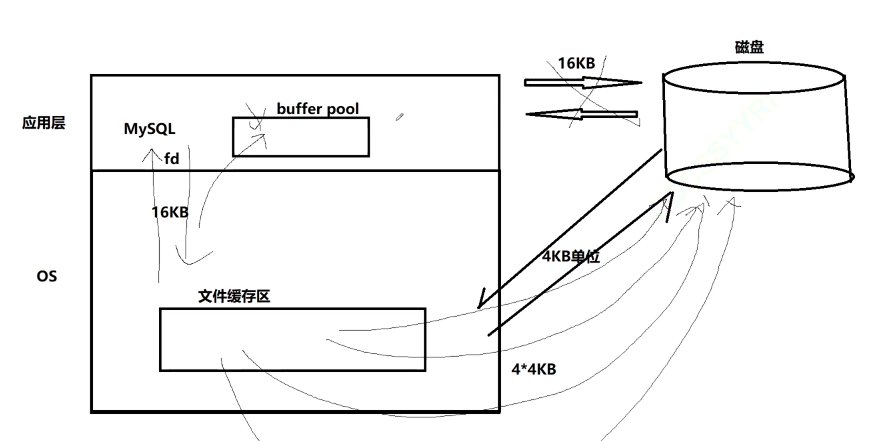
四、Page
当我们向一个具有主键的表中乱序插入数据后,我们会发现数据会自动排序。理解这个现象前,我们先重谈一下page。在MySQL内部一定会同时存在大量的page,因此MySQL会对其进行管理,这样一来page就不仅仅是一个大一点的内存块了,page内部也必须写入对应的管理信息struct page,就像:
struct page
{
struct page* next;
struct page* prev;
char buffer[NUM];
};
//---16KB
申请page其实就是new page(),将所有page用“链表”(或其他结构)管理起来,这就是在buffer pool内部,对MySQL中的page进行了一个建模。
MySQL 采用 Page 方案进行磁盘 IO 交互,主要基于以下考虑:
假设需要查找 id=2 的记录,如果采用逐条加载的方式,第一次加载 id=1,第二次加载 id=2,需要 2 次 IO。若查找id=5,则需要 5 次 IO。这种逐条加载的方式会导致 IO 次数显著增加。
而采用 Page 方案时,假设这 5 条记录(或更多)都存储在一个 16KB 的 Page 中,查找 id=2 时,整个 Page会被一次性加载到 MySQL 的 Buffer Pool 中,仅需 1 次 IO。后续查找 id=1、3、4、5等记录时,可以直接在内存中完成,无需额外 IO。这种方式显著减少了 IO 次数。
你可能会问:如何确保用户下次查找的数据就在这个 Page 中?虽然无法严格保证,但根据局部性原理,这种可能性很大。程序在执行时往往具有空间局部性和时间局部性,即相邻的数据很可能被连续访问。 此外,IO 效率低下的主要瓶颈通常不是单次 IO 的数据量大小,而是 IO 的次数。通过 Page 方案,可以有效减少 IO次数,从而提升整体性能。
因为有主键,MySQL 会默认按照主键给我们的数据进行排序,从Page内数据记录可以看出,数据是有序且彼此关联的,但是如果page间按照下图的链表结构,查找特定的一条记录就是线性遍历,这样的话效率就太低了:
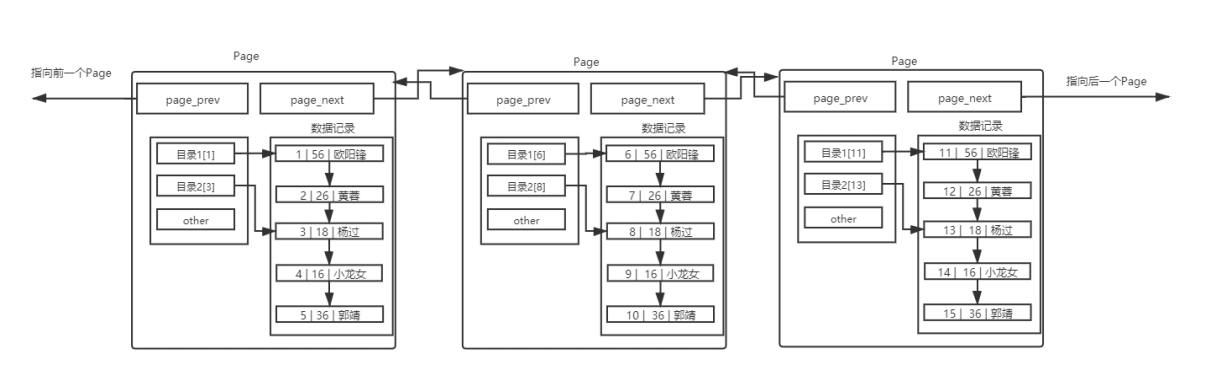
此时就要引入页目录这一概念了,一本书拥有目录,便于在一本书中进行快速查找。针对上述的单页Page,我们也可以引入目录:
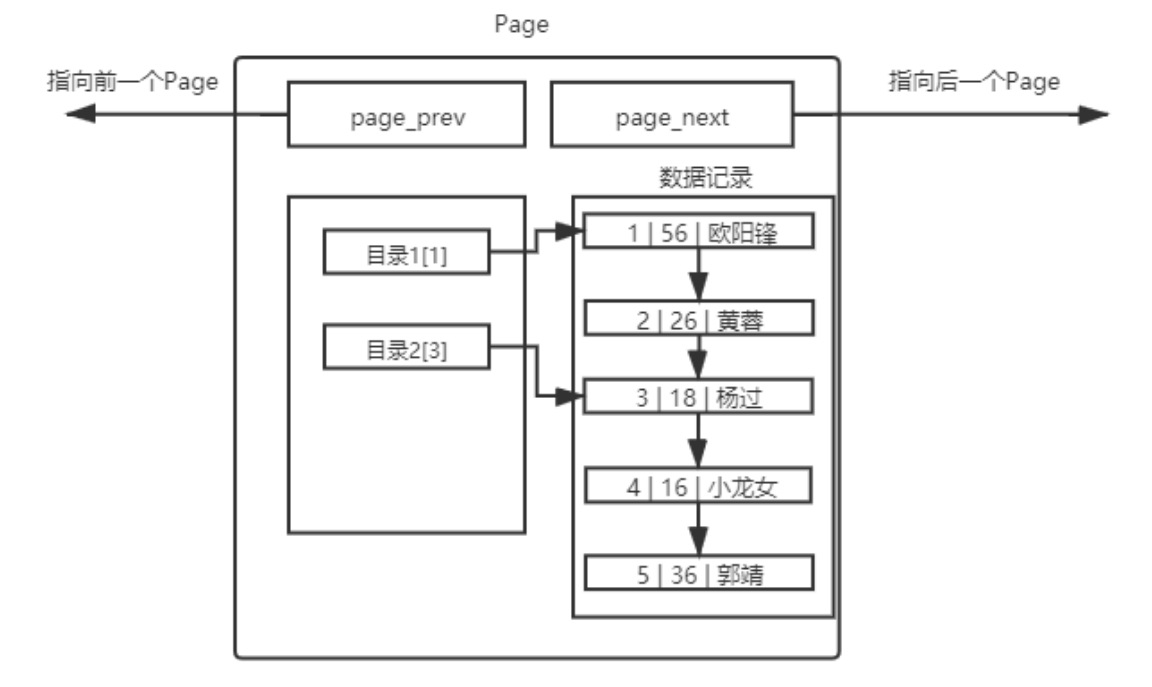
从这里我们就明白为什么MySQL会通过键值来自动排序了,就是为了更方便地引入目录。
但这里只是解决了Page内部查询的问题,而Page之间仍然是线性的,若Page很多的情况下效率仍然是存在问题的,按照之前解决问题的思路,我们可以也给Page带上目录。

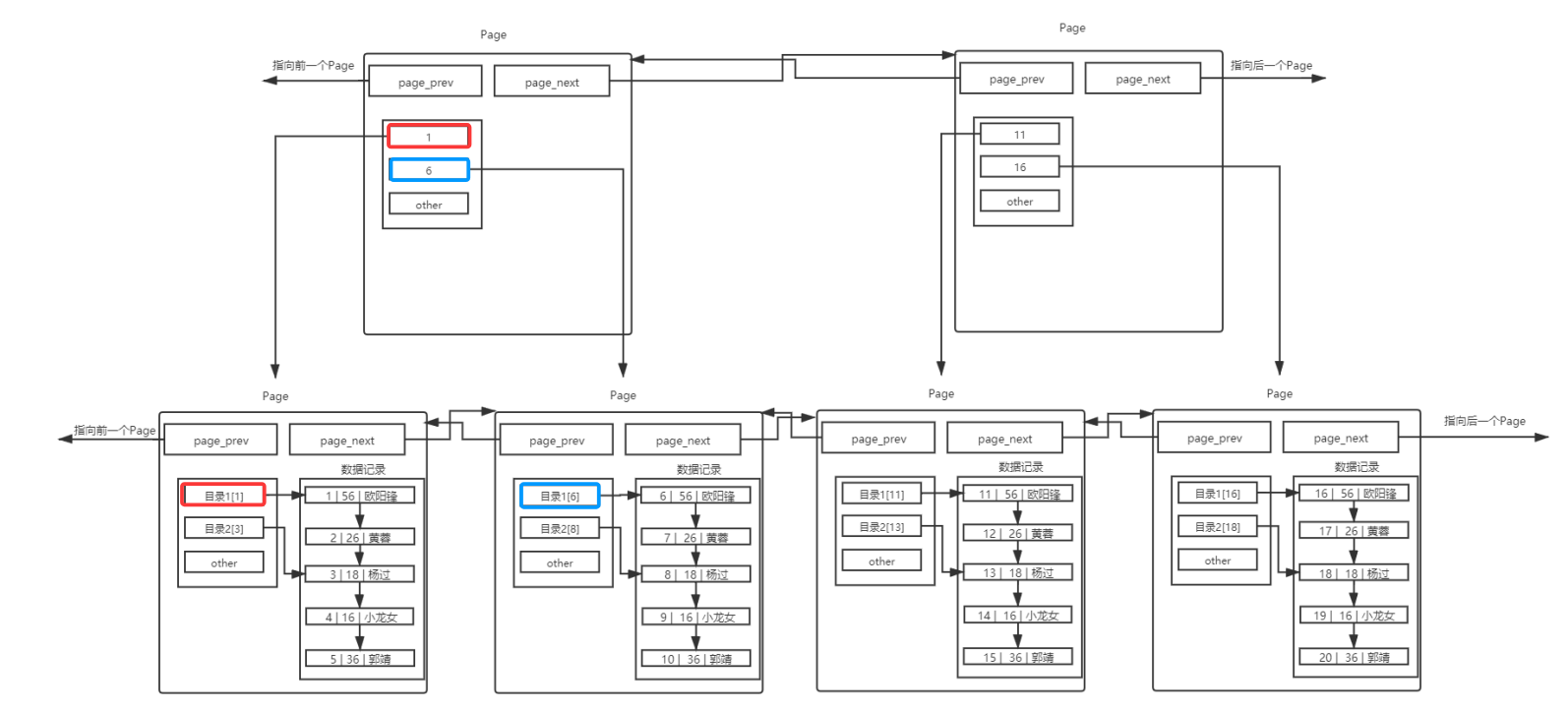
当然我们还能给页目录再向上加一个页目录,如下图所示,这个结构其实就是B+树。叶子节点保存数据,而非叶子节点不存数据,因此可以存储更多的目录项,这样就能管理更多的page,宏观上看这颗树就是一个矮胖型的树,这样的形状意味着从顶到底路径上的节点是很少的,找到目标数据只需要更少的Page,从而IO次数也减少,提高了效率。
同时叶子节点是用链表级联起来的,这是B+树的特点,这么设计的原因就是为了进行范围查找,这样就不用每次查找都从顶开始。
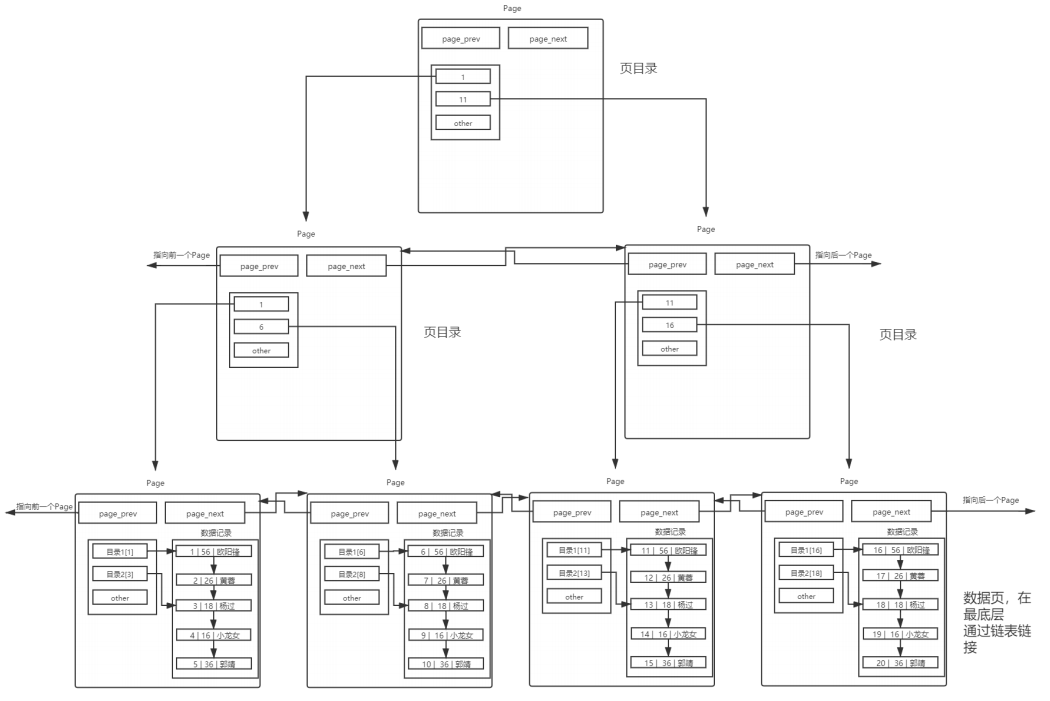 这整个结构叫做MySQL InnoDB下的索引结构,我们已经完成了主键索引。一般我们建表插入数据的时候,就是在该结构下进行增删查改,就算我们的表没有主键,MySQL也会自动生成一个隐藏列来充当主键。
这整个结构叫做MySQL InnoDB下的索引结构,我们已经完成了主键索引。一般我们建表插入数据的时候,就是在该结构下进行增删查改,就算我们的表没有主键,MySQL也会自动生成一个隐藏列来充当主键。
其他数据结构为什么不适合?
1.链表:线性遍历,效率低
2.二叉搜索树:“瘦高状”,从顶到底遇到的节点(IO次数)较多,而且极端情况下会退化为线性结构
3.AVL&红黑树:虽然是近似平衡,但形状仍然不变,层数是比B+树高的,B+树更加适合
4.Hash:?官方的索引实现方式中, MySQL 是支持HASH的,不过 InnoDB 和 MyISAM 并不支持,Hash跟进其算法特征,决定了虽然有时候也很快(O(1)),不过,在面对范围查找就明显不行
5.B树:B树的非叶子节点存了数据,意味着整体形状更高瘦,IO效率较低,并且非叶子节点是没有级联的,范围查找也不方便
五、聚簇/非聚簇索引
MyISAM存储引擎同样也是使用B+树作为搜索结果,但叶节点存放的是数据的地址,这就是MyISAM的最大特点,索引Page和数据Page分离,即叶节点也没有数据,只有数据对应的地址,这种用户数据和索引分离的索引方案叫做非聚簇索引:
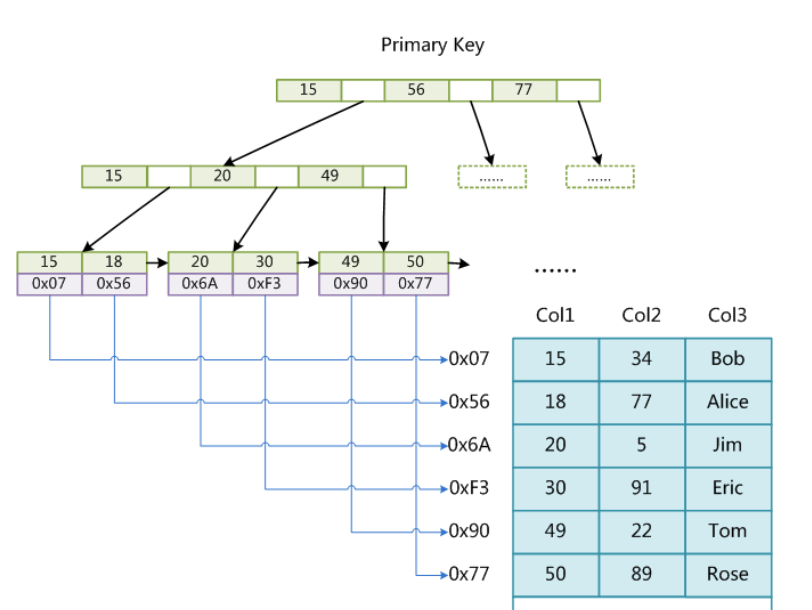
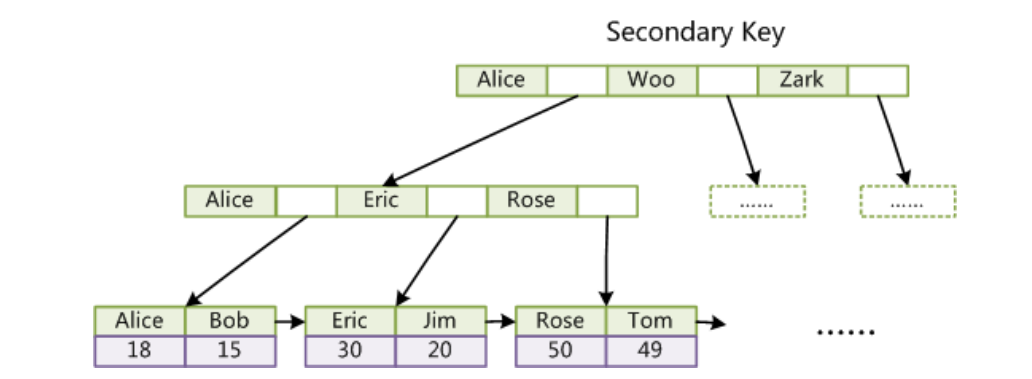
而InnoDB这种用户数据和索引数据放在一起的的索引方案叫做聚簇索引,当然MySQL除了默认会建立主键索引外,我们用户有可能建立其他列信息建立的索引,一般这种索引可以叫做辅助索引,对于MyISAM而言辅助索引和主键索引没有区别,无非是主键不能重复而非主键可以重复而已。而对于InnoDB而言,非主键索引的叶子节点中并没有数据,只有对应记录的Key值,所以通过辅助索引,找到目标记录,需要两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。这种过程,就叫做回表查询,为什么不给辅助索引的叶子节点也给上数据呢?原因就是太浪费空间了。
六、索引操作
索引创建规则:
1.比较频繁作为查询条件的字段应该创建索引
2.唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件,如性别
3.更新非常频繁的字段不适合创建索引
4.不会出现在where子句中的字段不该创建索引
1.创建主键索引
#方法一
create table user1(id int primary key,name varchar(30));
#方法二
create table user2(id int,name varchar(30),primary key(id));
#方法三
create table user3(id int,name varchar(30));
alter table user3 add primary key(id);
主键索引的特点:
1.一个表中最多只有一个主键索引
2.主键索引效率高,因为主键不可重复
2.创建唯一索引
#方法一
create table user4(id int primary key,name varchar(30) unique);
#方法二
create table user5(id int primary key,name varchar(30),unique(name));
#方法三
create table user6(id int primary key, name varchar(30));
alter table user6 add unique(name);
唯一索引的特点:
1.一个表中可以有多个唯一索引
2.查询效率高
3.创建普通索引
#方法一
create table user8(id int primary key,
name varchar(20),
email varchar(30),
index(name) --在表的定义最后,指定某列为索引
);
#方法二
create table user9(id int primary key, name varchar(20), email varchar(30));
alter table user9 add index(name); --创建完表以后指定某列为普通索引
#方法三
create table user10(id int primary key, name varchar(20), email varchar(30));
-- 创建一个索引名为 idx_name 的索引
create index idx_name on user10(name);
普通索引的特点:
1.一个表中可以有多个普通索引,在实际开发中用的比较多
2.如果某些列需要创建索引,同时该列有重复的值,那么就该使用普通索引
4.查询索引
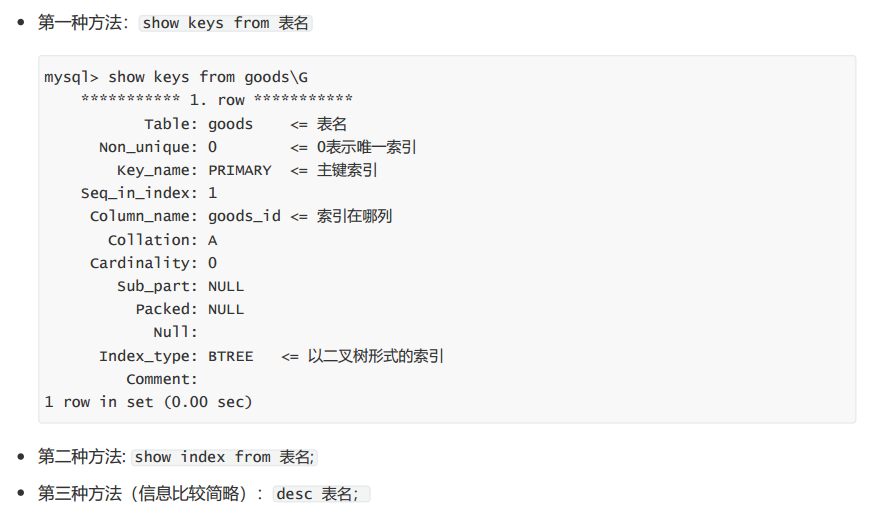
5.删除索引
