大家好,我们昨天是讲解了几个岛屿系列的问题,其实昨天的岛屿问题难度就比较大了,今天的第一道题目我的印象很深刻难度也不小,我们昨天使用的dfs大家应该还记得,我们还使用了一些逆向思维的方法,今天我们继续图论部分,我们的岛屿系列问题还没有讲完,今天我们应该就可以结束岛屿问题了。
第一题对应卡码网编号为110的题目字符串接龙
这道题目的背景似乎并不是岛屿问题,我们就直接看看题目要求:

题目的意思是我们给出一个起始字符串和终止字符串,同时我们字符串字典里面有多个字符串,题目要求我们求从起始字符串变成终止字符串的最少操作次数,当然我们中间的变化过程只能使用字典里面的字符串,这其实不好想,因为情况似乎太复杂了,但是根据我们前面学习过的理论基础我们可以断定这道题目大概率是需要使用广度优先搜索,为什么呢?因为我们知道广度优先搜索其实是一圈一圈搜索,当我们搜索到了终止字符串其实就是最少的操作次数,每一圈其实都是这个字符串经过一次操作可以变成的字符串,很明显我们一旦搜索到了终止字符串就一定是最少的操作数,注意题目要求我们的字典中的每一个字符串都只能使用一次,我们就一起来看看这道题我们如何使用广搜来解决:
其实我们是使用我们以前学过的哈希表的相关数据结构,我们首先需要一个队列,然后需要一个集合和一个映射,这个映射存储的是当前字符串和达到这个字符串的的操作数,这样我们就可以进行广搜的过程,但是大家注意我们其实是我当前字符串里的每一个元素我都会考虑从a到z的26中变化形式,我们还得保证我变换出来的字符串必须在字典中存在,因此我们根据这个思路就可以尝试给出解题代码:
#include <iostream>
#include <string>
#include <vector>
#include <unordered_set>
#include <unordered_map>
#include <queue>
using namespace std;
int main()
{
int n; cin >> n;
string str, beginStr, endStr;
cin >> beginStr >> endStr;
unordered_set<string> strSet;
//把所有的字符串加入到集合中去
//使用集合是考虑到它的查找效率是最快的
for (int i = 0; i < n; ++i)
{
cin >> str;
strSet.insert(str);
}
//记录我当前的字符是否被访问过
unordered_map<string, int> visitMap;
//首先将起始字符串添加到map中
visitMap.insert(pair<string, int>(beginStr, 1));
//广搜需要使用的队列
queue<string> que;
que.push(beginStr);
//广搜的过程
while(!que.empty())
{
string word = que.front();
que.pop();
//我们还需要一个变量来存储所有变换的字符串起始就是当前字符串的每一个位置都用
//所有的小写字母来替换看看有没有在我们给出的字符串里面
int path = visitMap[word]; //存储路径的长度
for (int i = 0; i < word.size(); ++i)
{
string newword = word;
for (int j = 0; j < 26; ++j)
{
newword[i] = j + 'a';
if (newword == endStr)
{
cout << path + 1 << '\n';
return 0;
}
//如果题目给出的字符串有这个字符串并且当前字符串没有被访问过
if (strSet.find(newword) != strSet.end() && visitMap.find(newword) == visitMap.end())
{
visitMap.insert(pair<string,int>(newword, path + 1));
que.push(newword);
}
}
}
}
//如果没找到则输出0
cout << 0 << '\n';
return 0;
}这道题目使用深搜似乎就不可以了,因此我们两种搜索算法还真的都得掌握扎实,这道题希望大家仔细思考,我们使用集合的目的是什么一方面可以避免重复访问,另一方面我们还可以确定我当前变换出来的字符串是否在字典中存在,我一开始应该就把字典里的所有字符串存放到一个集合中去了,我们这道题就分享这么多,我们接着看下一道题目。
第二题对应卡码网编号为105的题目有向图的完全联通
我们来到今天的第二题,这道题相比于上一道题目就简单了不少,其实与我们之前的题目就很相似了,这道题目我就可以使用深搜来解决了,我们还是先看看题目要求:
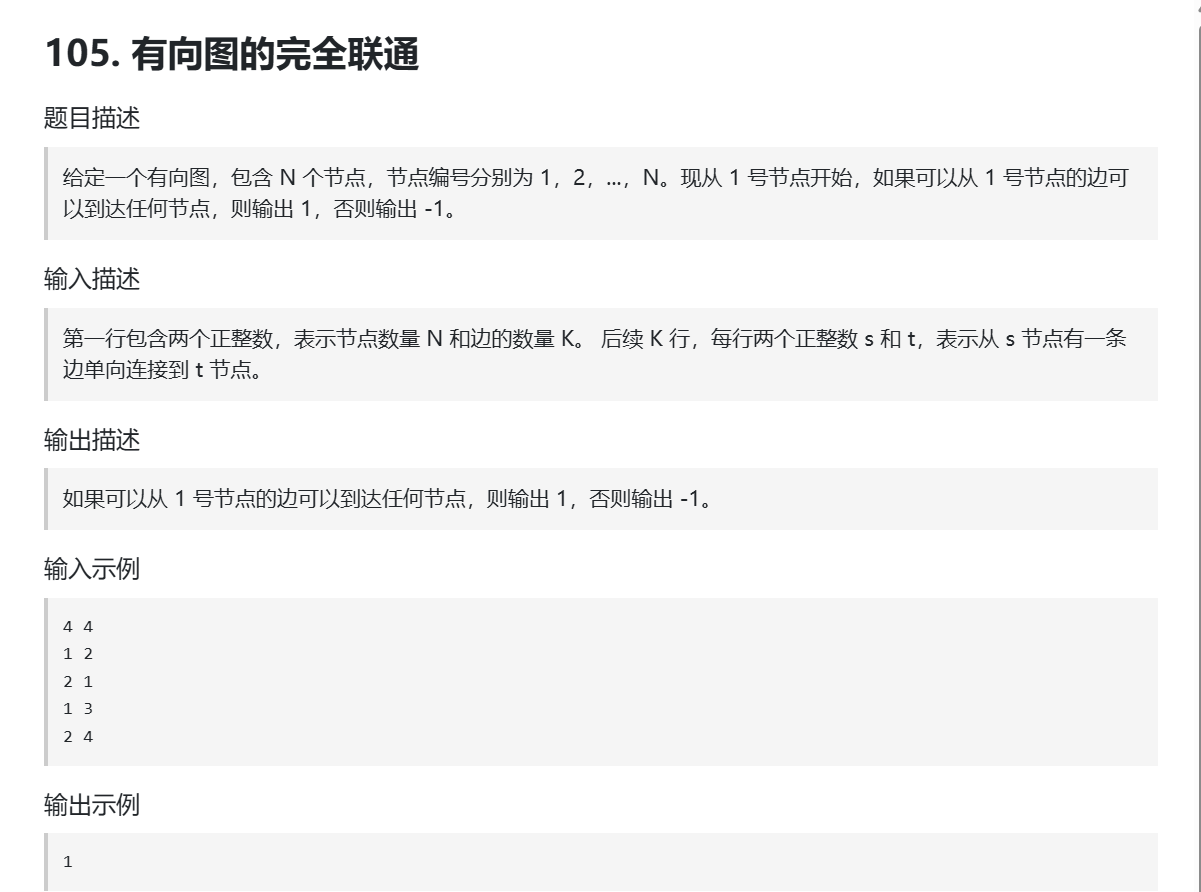
我们其实是给出一个有向图,让我们判断从起点1出发是否可以到达该有向图其他的节点,我们这道题很明显可以使用深搜,我们这道题目既可以使用邻接矩阵来存储图也可以使用邻接表来存储图,这里我们使用邻接表来存储图,当然我们需要一个数组来标记当前节点是否被重复访问,这样我们如果使用邻接表的话其实就类似于映射,如果我找到一个节点我就需要遍历与它相邻的所有节点继续深搜,最后我们是要看看所有的节点是否都被访问到了,如果存在没有被访问到的节点就返回-1,如果都访问到了就返回1,这样我们就可以给出本题的解题代码:
#include <iostream>
#include <vector>
#include <list>
using namespace std;
void dfs(const vector<list<int>>& graph, int key, vector<bool>& visited) {
if (visited[key]) {
return;
}
visited[key] = true;
list<int> keys = graph[key];
for (int key : keys) {
// 深度优先搜索遍历
dfs(graph, key, visited);
}
}
int main() {
int n, m, s, t;
cin >> n >> m;
// 节点编号从1到n,所以申请 n+1 这么大的数组
vector<list<int>> graph(n + 1); // 邻接表
while (m--) {
cin >> s >> t;
// 使用邻接表 ,表示 s -> t 是相连的
graph[s].push_back(t);
}
vector<bool> visited(n + 1, false);
dfs(graph, 1, visited);
//检查是否都访问到了
for (int i = 1; i <= n; i++) {
if (visited[i] == false) {
cout << -1 << endl;
return 0;
}
}
cout << 1 << endl;
}这道题目是不难的,我感觉使用邻接表更合适,当然本题不仅仅可以使用深搜还可以使用广搜,还是我们广搜的普遍逻辑,这样我就只带大家写深搜的解法,其实我也可以给出大家广搜的解题代码:
#include <iostream>
#include <vector>
#include <list>
#include <queue>
using namespace std;
int main() {
int n, m, s, t;
cin >> n >> m;
vector<list<int>> graph(n + 1);
while (m--) {
cin >> s >> t;
graph[s].push_back(t);
}
vector<bool> visited(n + 1, false);
visited[1] = true; // 1 号房间开始
queue<int> que;
que.push(1); // 1 号房间开始
// 广度优先搜索的过程
while (!que.empty()) {
int key = que.front(); que.pop();
list<int> keys = graph[key];
for (int key : keys) {
if (!visited[key]) {
que.push(key);
visited[key] = true;
}
}
}
for (int i = 1; i <= n; i++) {
if (visited[i] == false) {
cout << -1 << endl;
return 0;
}
}
cout << 1 << endl;
}
那这样这道题我们就分享到这里,我们接着进入我们今天的最后一道题目。
第三题对应卡码网编号106的题目岛屿的周长
这是我们岛屿问题的最后一道题目,其实难度很小,甚至不需要我们使用深搜和广搜就可以解决,我们先来看看题目的要求:
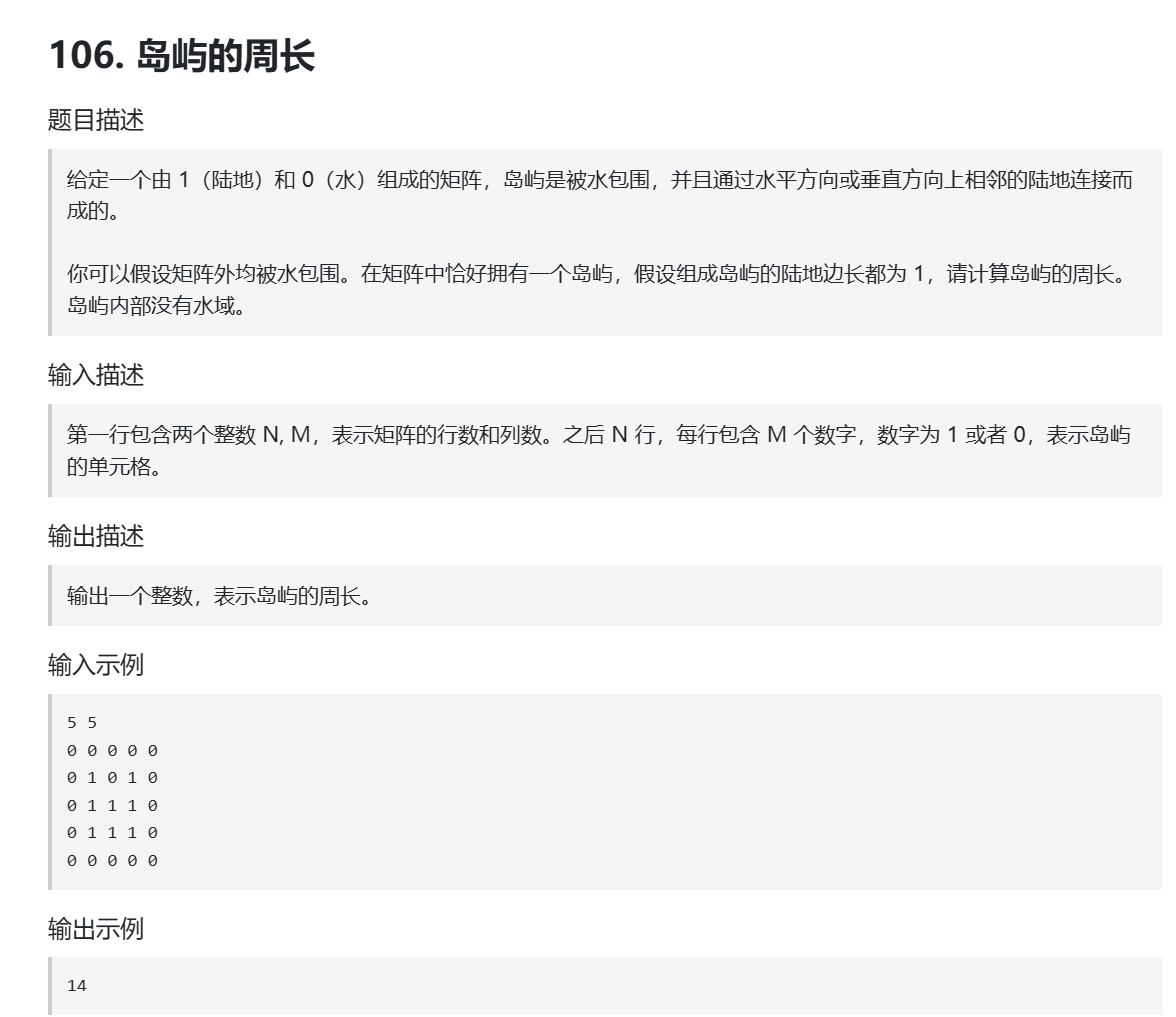
其实这道题我们只需要了解一点,我们什么时候可以统计周长,还有就是周长是如何计算出来的,比如说我们的输入示例,我们其实就是统计边缘,我们只有在当前节点是陆地的时候才需要统计,其实我们去遍历陆地的四个方向,什么情况下会有周长,一个是临近海洋一个是临近边界,只要这些大家意识到了这道题就没问题了,其实这道题应该是图论里面最简单的题目,因为根本没有使用到我们图论的深搜与广搜,这样我们就可以给出解题代码:
#include <iostream>
#include <vector>
using namespace std;
int dir[4][2] = {0, 1, 1, 0, 0, -1, -1, 0};
int main()
{
int n, m; cin >> n >> m;
vector<vector<int>> grid(n + 1, vector<int>(m + 1, 0));
for (int i = 0; i < n; ++i)
{
for (int j = 0; j < m; ++j) cin >> grid[i][j];
}
int result = 0;
for (int i = 0; i < n; ++i)
{
for (int j = 0; j < m; ++j)
{
if (grid[i][j] == 1)
{
//上下左右四个方向去枚举
for (int k = 0; k < 4; ++k)
{
int x = i + dir[k][0];
int y = j + dir[k][1];
//如果四周有边界或者海洋的话周长就加加
if (x < 0 || x >= grid.size() || y < 0 || y >= grid[0].size() || grid[x][y] == 0) result++;
}
}
}
}
cout << result << '\n';
return 0;
}今日总结
其实今天的题目字符串接龙这道题的确比较难,后面这两道题目不难,这样我们的岛屿问题就算结束了,大家应该总结一下这些岛屿问题,这样慢慢就可以形成我们自己的思路,灵活使用搜索算法,明天我们就会接触一种新的数据结构-并查集,我们明天再见!