Cox回归
在用医疗数据作分析时,最常见的是去预测某类病的患者的死亡率或预测他们的结局。但是我们得到的病人数据,往往会有很多的协变量,即使我们通过计算来减少指标对结果的影响,我们的数据中依然会有很多的协变量,且其之间还可能存在互相的影响以及合并症对结局的影响,也就是会导致研究的方向歪了。
协变量过多导致的过拟合(在训练数据上表现好但泛化能力差)、多重共线性(变量间高度相关,导致系数估计不稳定)以及统计功效降低(每个变量的效应可能被稀释)等问题,虽然不能直接修改cox的参数来改变,但是我们可以用曲线救国的方式,将风险转移或分割开来。比如针对过拟合问题,我们可以基于临床知识,知道哪些数据对病人的结局影响较大,先单独对这些变量进行cox回归,将p值<0.1的保留下来,应用到后续的模型里;对于合并症不同,其对死亡结局的影响也不同,我们可以对其进行分层处理,明确不同变量的影响力;如果做的再精细些,我们可以通过计算指标,判断病人是否换其他疾病,再将一些连续变量转为因子(通过分成区间等转成分类变量),从而使得模型更精确。
下面我们通过一个例子来理解:
set.seed(123)
# 生成模拟数据集
n_samples <- 500
# 创建预测变量 - 包括10个潜在相关变量
age <- rnorm(n_samples, mean = 65, sd = 10) # 年龄
treatment <- rbinom(n_samples, 1, 0.5) # 治疗组(1)或对照组(0)
severity <- runif(n_samples, 0.1, 1.0) # 疾病严重程度(0.1-1.0)
# 生成7个合并症指标(二元变量)
comorbidities <- matrix(rbinom(n_samples*7, 1, 0.3), ncol=7)
colnames(comorbidities) <- paste0("comorb", 1:7)
# 生成实验室指标(连续变量)
lab_values <- matrix(c(
rnorm(n_samples, mean = 100, sd = 20), # 血红蛋白
rnorm(n_samples, mean = 1.0, sd = 0.3), # 肌酐
rnorm(n_samples, mean = 5.0, sd = 1.5) # 白细胞计数
), ncol=3)
colnames(lab_values) <- c("hemoglobin", "creatinine", "wbc")
# 合并所有协变量
covariates <- cbind(age, treatment, severity, comorbidities, lab_values)
# 生成生存时间(只有age, treatment, severity和comorb1, comorb2, hemoglobin真正有影响)
true_coefs <- c(0.04, -0.7, 0.6, 0.4, 0.3, 0.02, rep(0, 7)) # 最后8个变量无影响
linear_predictor <- covariates %*% true_coefs
risk_score <- exp(linear_predictor)
survival_time <- rexp(n_samples, rate = risk_score) * 30 # 乘以30使时间范围更合理
# 生成删失数据(约25%的观察在事件发生前结束)
censoring_time <- rexp(n_samples, rate = 1/50)
observed <- survival_time < censoring_time
time <- ifelse(observed, survival_time, censoring_time)
# 创建数据框
df <- data.frame(
time = time,
event = as.integer(observed),
covariates
)
# 查看数据结构
head(df)
summary(df)
# 1. 基本Cox模型(只包含主要变量)
cox_model <- coxph(Surv(time, event) ~ age + treatment + severity, data = df)
summary(cox_model)
library(survminer)
# 可视化主要结果
ggforest(cox_model, data = df)
# 2. 包含所有变量的完整模型
full_model <- coxph(Surv(time, event) ~ ., data = df)
summary(full_model)
# 3. 变量选择方法(使用Lasso回归)
# 准备数据
x <- as.matrix(df[, -(1:2)]) # 去除时间和事件列
y <- Surv(df$time, df$event)
# 交叉验证选择最佳lambda
cv_fit <- cv.glmnet(x, y, family = "cox", alpha = 1) # alpha=1表示Lasso
plot(cv_fit)
# 最佳模型
best_lambda <- cv_fit$lambda.min
lasso_model <- glmnet(x, y, family = "cox", alpha = 1, lambda = best_lambda)
# 查看选择的变量
coef(lasso_model)
# 用选择的变量建立最终Cox模型
selected_vars <- which(as.vector(coef(lasso_model)) != 0)
final_formula <- as.formula(
paste("Surv(time, event) ~",
paste(colnames(x)[selected_vars], collapse = " + "))
)
final_model <- coxph(final_formula, data = df)
summary(final_model)
# 检查比例风险假设
cox.zph(final_model)
plot(cox.zph(final_model)[1]) # 示例:绘制第一个变量的Schoenfeld残差图输出:
chisq df p
age 0.000371 1 0.98
treatment 2.256668 1 0.13
comorb1 1.451580 1 0.23
comorb2 0.294485 1 0.59
comorb3 0.075093 1 0.78
comorb6 0.138340 1 0.71
comorb7 0.328857 1 0.57
hemoglobin 0.006359 1 0.94
wbc 0.081378 1 0.78
GLOBAL 5.214219 9 0.82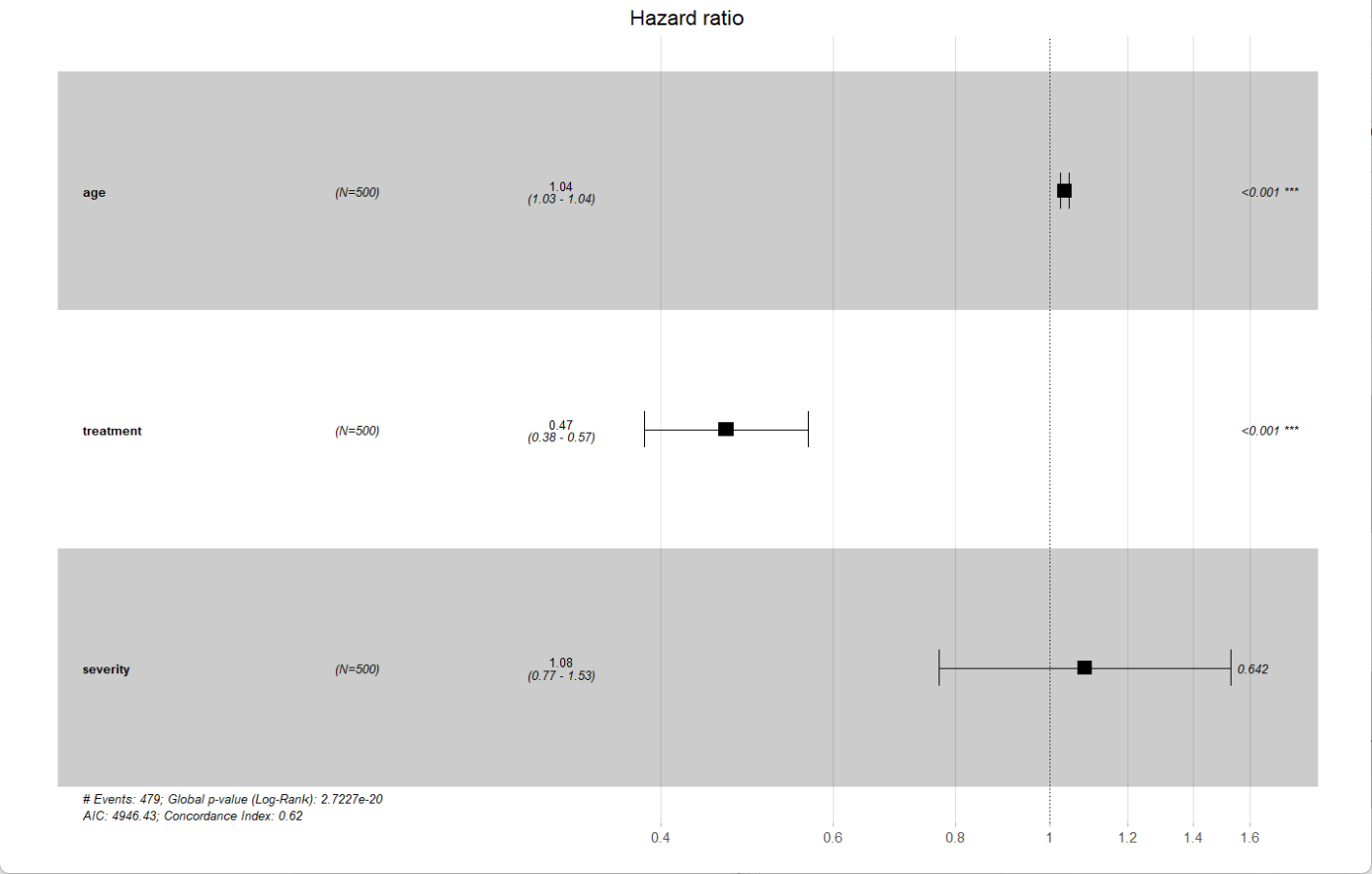
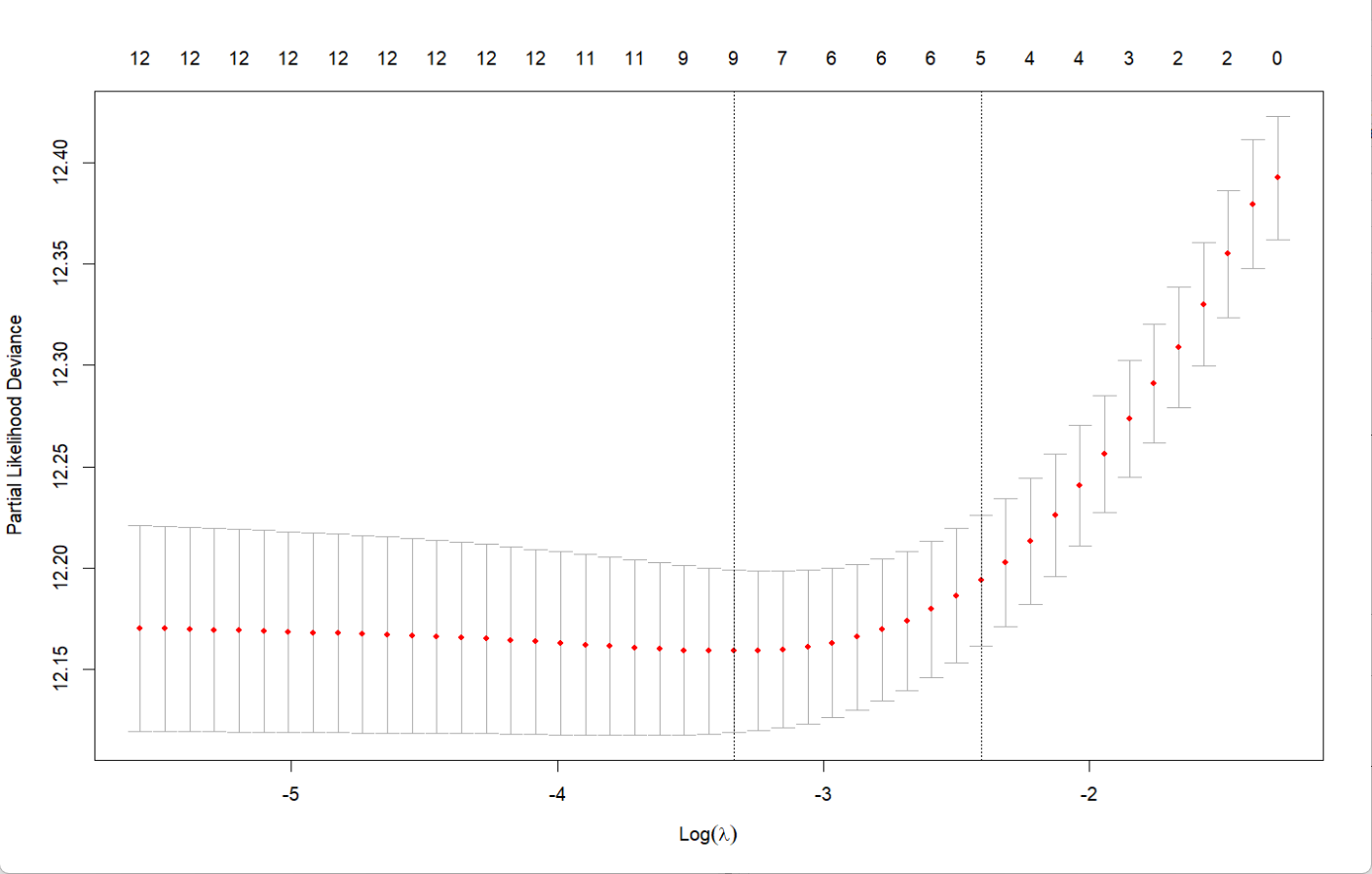
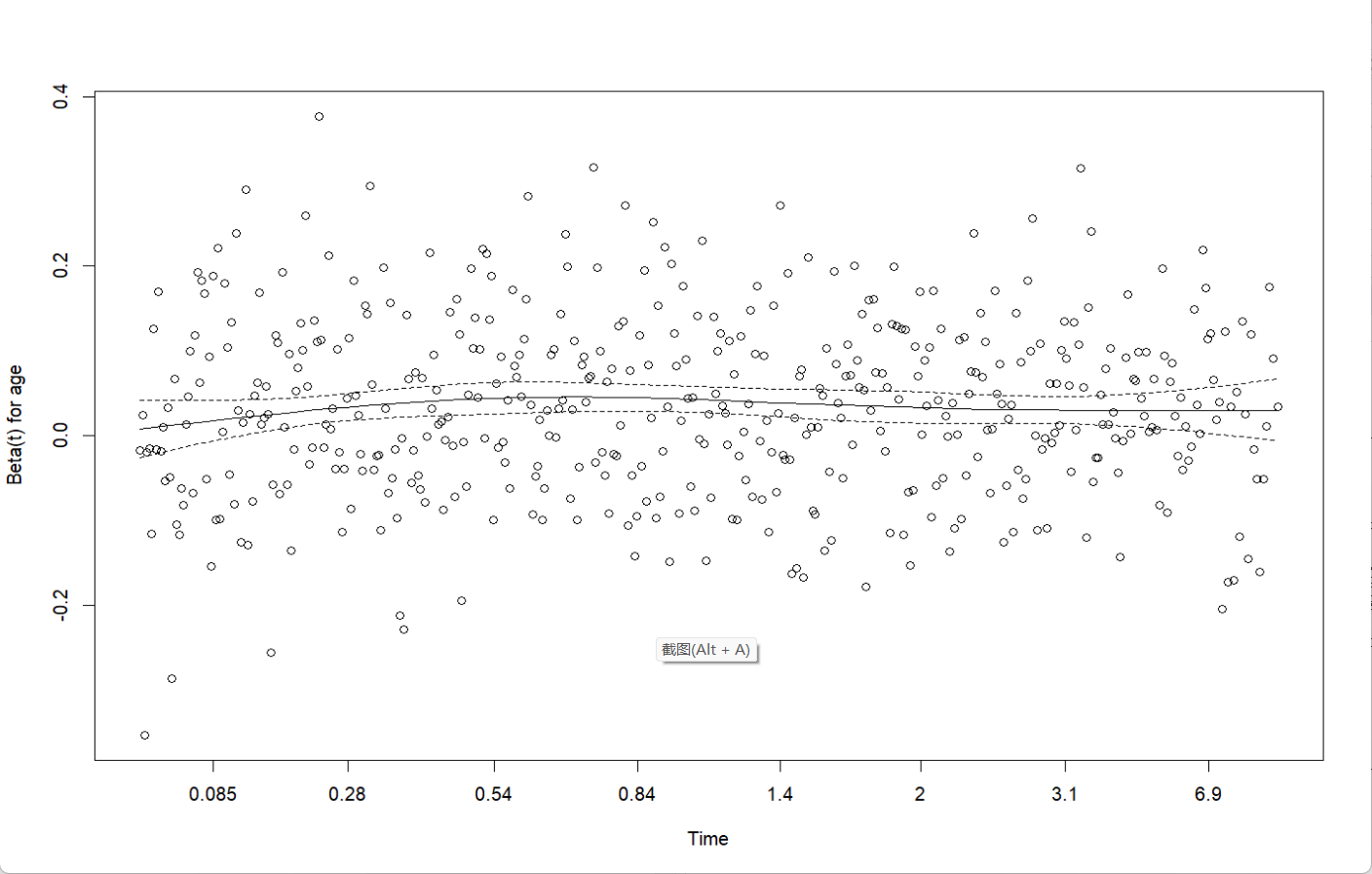
从结果来看,年龄和治疗方案是对结局有显著影响的,而服务这一块的影响很小,可以考虑从模型中去除;而输出结果表示各个变量的p值都大于0.05,且global的检验p也大于0.05,说明各变量的风险比在研究期间保持稳定,结果是可信的。