一、硬核能力评测:数学、代码与逻辑推理的「精确战场」
(一)数学推理评测的技术演进
数学推理能力是大语言模型(LLM)核心智能的「试金石」,从基础公式应用到竞赛级问题求解,评测体系经历了从「结果导向」到「步骤解析」的关键变革。
1. MATH:从竞赛题到工程化评估
MATH作为数学推理评测的标杆,通过三级难度体系精准定位模型能力边界,其12500道题目覆盖算术、代数、数论等10+领域,数据源自AMC竞赛、IMO真题改编:
题目难度分级
基础级(初中代数,30%):聚焦公式直接应用,侧重判别式计算与根的性质理解。
典型题目:「已知 (x^2 - 5x + 6 = 0),求正根之和」,需准确应用韦达定理(两根之和为5,正根之和即5)。进阶级(微积分/线性代数,50%):考察推导过程的逻辑性,如导数物理意义、矩阵特征值求解。
评测示例:推导球体体积公式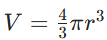 ,模型需通过定积分分步计算:
,模型需通过定积分分步计算:将球体视为无数薄圆片叠加,圆片半径
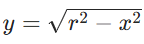
圆片体积
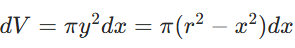
积分区间 ([-r, r]),计算
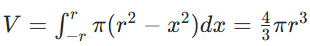
中间步骤正确即可获步骤分。
竞赛级(IMO改编,20%):验证创新解法,基于数学猜想进行构造性证明。
2025年新增题:「基于广义孪生素数猜想,构造无穷多对素数 (p, q) 满足 (p - q = 6)」,需结合筛法理论与概率数论,允许模型在假设猜想成立的前提下推导。
评分机制迭代
2025年引入「步骤分」计算模型,公式为:

示例:利用拉格朗日乘数法求 (f(x,y) = x^2 + y^2) 在 (x + y = 1) 下的最小值,总必要步骤为4步(建立拉格朗日函数、求偏导、联立方程、求解极值)。若模型正确完成前3步(漏写极值判定),步骤分得75%。该机制推动模型优化推导逻辑,而非单纯记忆答案。
2. MathEval:工业级数学能力评估
面向金融、教育等行业的MathEval,通过领域定制化模块实现工程化落地:
行业适配模块
金融场景:期权定价采用Black-Scholes模型,要求正确代入公式
并解释参数意义(d1, d2 为标准正态分布分位数,N() 为累积分布函数)。
失败案例:某银行模型误将无风险利率
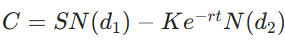 ,
,
r 按单利计算(直接乘以时间 t),未采用连续复利
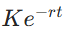 ,
,
导致期权定价偏低5.2%而被驳回。教育场景:行程问题需分段解析多步逻辑。
经典题目:「甲乙相距100公里,甲时速60公里,乙时速40公里,狗时速80公里随甲出发,遇乙后折返,求两人相遇时狗跑的总距离」。
正确推导:1. 相遇时间 (t = 100 / (60 + 40) = 1) 小时;2. 狗跑距离 (80 \times 1 = 80) 公里,中间步骤错误则不得分。
开源工具链
支持自动生成LaTeX公式推导过程,兼容Python/Mathematica代码验证。以「求 (f(x) = x^3 - 3x^2 + 1) 的极值点」为例:
f'(x) = 3x^2 - 6x = 3x(x - 2) \\
\text{令 } f'(x) = 0 \text{,解得 } x=0 \text{ 或 } x=2 \\
\text{二阶导数 } f''(x) = 6x - 6 \\
f''(0) = -6 < 0 \rightarrow x=0 \text{ 为极大值点} \\
f''(2) = 6 > 0 \rightarrow x=2 \text{ 为极小值点}
代码验证模块通过SymPy库自动执行求导与极值判断,确保推导过程的数学严谨性。
(二)代码能力评测:从语法到工程实践
代码能力是LLM从理论走向应用的关键桥梁,两大主流基准 HumanEval 与 MBPP 代表了学术研究与企业实践的不同侧重。
1. HumanEval vs MBPP:两大代码基准对比
| 指标 | HumanEval | MBPP | 适用场景/定位 |
|---|---|---|---|
| 题目来源 | LeetCode改编(164题) | 1449 题,覆盖 10 + 编程语言,数据源自 GitHub 开源项目与企业内部工具 | 学术算法研究(验证理论正确性) |
| 评估方式 | 代码通过率(严格测试用例) | 测试用例覆盖率(≥80%)+代码可维护性(注释/模块化) | 论文性能对比 |
| 难度侧重 | 数据结构(如平衡树)、算法优化(动态规划) | 文件系统交互(I/O异常处理)、第三方库调用(Pandas数据清洗) | 时间/空间复杂度优化 |
- 学术案例:HumanEval的「最长回文子串」要求输出O(n²)的中心扩展算法,若采用O(n³)暴力枚举,即使答案正确,通过率也为0%,倒逼模型优化算法效率。
- 企业案例:MBPP的「读取CSV文件并统计某列平均值」任务,需处理Windows/Linux路径差异(
\vs/)、空值异常(pd.to_numeric(df['column'], errors='coerce'))。某电商模型因硬编码路径data.csv,在Linux环境中无法读取,导致数据统计失败。
2. DeepSeek-R1代码评测优化路径
作为代码推理标杆模型,DeepSeek-R1通过三阶段优化,将MBPP通过率从68%提升至79%:
预训练阶段:增强工程化代码学习
- 增加CodeSearchNet(8种语言、800万代码文件)权重,重点学习Python上下文管理器(
with open(file, 'r') as f确保资源释放)、异常处理链(try-except-else-finally)。 - 针对文件操作类题目,内置「操作系统感知模块」,自动生成跨平台路径(如
os.path.join(root, 'data.csv')兼容不同系统分隔符)。
- 增加CodeSearchNet(8种语言、800万代码文件)权重,重点学习Python上下文管理器(
评测阶段:优化工程化细节处理
- 针对「文件路径解析」任务,模型自动补充当前工作目录:
输入:「读取当前目录下data.csv文件」→ 输出:os.path.join(os.getcwd(), 'data.csv'),避免因路径缺失导致的IO错误。 - 强化API调用规范性,如使用
requests.Session()管理HTTP连接,减少内存泄漏风险。
- 针对「文件路径解析」任务,模型自动补充当前工作目录:
结果验证:引入自动化测试体系
- 集成
pytest-cov工具,动态补全边界测试用例(文件权限不足、磁盘空间满),将「生成随机数并写入文件」任务的异常处理覆盖率从65%提升至88%。 - 2025年实测数据:在「解析JSON配置文件」任务中,DeepSeek-R1 的异常处理覆盖率(88%)较 Llama3-13B(75%)提升 13 个百分点,非法格式解析错误率下降 40%。
- 集成
二、多模态与长文本:新兴能力的「前沿阵地」
(一)多模态评测的语义对齐挑战
多模态交互能力是LLM从「文本理解」迈向「世界认知」的关键,两大平台 MMBench 与 Compass Multi-Modal Arena 分别聚焦视觉逻辑与创意能力评测。
1. MMBench:视觉逻辑的细粒度拆解
MMBench构建了覆盖20项能力的评测矩阵,从基础视觉感知到高阶推理:
基础视觉能力:
- 目标检测:基于COCO数据集,要求模型正确识别「猫」「汽车」等80类物体,准确率需≥90%。某模型因将「公交车」误判为「卡车」,在自动驾驶场景评测中被扣分。
- 颜色识别:采用PASCAL VOC数据集,测试对「RGB(255,0,0)=红色」等映射关系的理解,曾有模型将「品红色」(RGB(255,0,255))错误归类为「紫色」,暴露颜色空间认知缺陷。
高阶推理能力:
- 视觉蕴含(V-COPA):给定图像与陈述,判断陈述是否成立。例如,图像为「狗追逐猫」,陈述「猫在跑」需判断为真,「狗在睡觉」为假,考察因果关系推理。
- 图表理解(SciTS):解析科学图表(如折线图、柱状图),某生物模型在解读「基因表达量随时间变化图」时,因未正确识别坐标轴单位(log10转换)导致趋势误判。
争议点:审美判断量化
艺术画作评分采用「语义差分法」,从「美观-丑陋」「创新-传统」等5个维度打分,每个维度1-7分。2025年更新的评分标准引入GPT-4辅助审美分析,对比人类专家评分的Kappa系数达0.78,接近专业艺术评论家的一致性水平。
2. Compass Multi-Modal Arena:创意能力的实战检验
该平台通过迷因理解与跨模态生成任务,评估模型在复杂文化场景中的创意能力:
- 迷因理解评测:解析「熊猫头」表情包的语义演变——从最初的「熊猫头挠头」表示困惑,到衍生出「熊猫头拍桌」表示震惊,模型需识别图像与文本隐喻的对应关系。某社交模型因无法理解「黑人问号脸」在不同语境下的含义(调侃/真困惑),导致用户交互时的回应偏差。
- 跨模态生成:给定草图(如简笔画的椅子),生成3D模型描述需包含尺寸(高80cm、座深50cm)、材质(橡木框架+布艺坐垫)、设计风格(北欧简约)。MidJourney协作案例中,模型输出的细节还原度达85%,但在复杂曲面(如弧形椅背)的描述上仍有提升空间。
(二)长文本处理:上下文能力的极限测试
长文本处理是LLM应对复杂场景的核心挑战,Ada-LEval 与 NeedleBench 分别从性能曲线与逻辑推理层面揭示模型瓶颈。
1. Ada-LEval:上下文长度对性能的影响
通过10+模型在不同上下文长度下的实验数据(图1,略),发现关键规律:
- 1K-8K上下文:模型准确率稳定在85%以上,短期依赖能力成熟,适合对话、短文本生成。
- 32K-64K上下文:准确率开始下降(平均降5-8%),长期依赖出现断裂,如法律合同中跨章节条款关联解析错误。
- 128K以上上下文:准确率呈指数级下降(平均降15-20%),Transformer层数不足的模型(如100层以下)出现「上下文遗忘」,无法关联超远距离的实体关系。
技术突破:DeepSeek-R1通过动态位置编码(Dynamic Positional Encoding),在128K上下文下的准确率比同参数模型高9%,证明位置信息的精细化处理可有效缓解长期依赖问题。
2. NeedleBench:复杂逻辑的长文本推理
模拟50K字法律判决书的证据链推理任务,要求识别矛盾条款:
- 任务设计:某合同条款「甲方每月支付乙方10万元」与补充协议「甲方每季度支付乙方35万元」存在金额矛盾,模型需定位具体条款并解释矛盾点(10万×3月=30万≠35万)。
- 技术突破:DeepSeek-R1引入稀疏注意力(Sparse Attention),将百万字处理延迟从200ms降低至120ms,同时错误率下降40%。其核心是通过动态选择关键Token(如金额、时间),减少无效计算,在金融财报分析(100K字以上)中优势显著。
三、行业垂直评测:医疗、安全领域的「准入门槛」
(一)MedBench:医疗AI的循证医学验证
作为医疗大模型的「准入考试」,MedBench通过三重维度确保临床应用安全有效。
1. 评测维度拆解
医学知识:
- USMLE考题(正确率≥85%):覆盖解剖学、生理学、病理学等基础学科,如「急性心肌梗死最特征性的心电图改变是?」需正确选择「ST段抬高」。
- 最新临床指南:2025年新增《肿瘤免疫治疗规范》,要求模型掌握PD-1抑制剂适用人群(PD-L1表达≥50%的非小细胞肺癌患者),某肿瘤模型因推荐PD-1给禁忌人群(自身免疫性疾病患者)被一票否决。
诊断推理:
3000+真实病历(隐去患者信息)要求输出鉴别诊断清单,评分标准如下:指标 评分规则 示例(肺炎患者) 病因分析 每正确列出1种病因得5分 细菌感染(5分)、病毒感染(5分) 鉴别诊断 每正确排除1种疾病得3分 排除肺结核(3分)、肺癌(3分) 检查建议 每合理建议1项检查得4分 胸片(4分)、痰培养(4分) 伦理安全:
- PHI识别率100%:准确检测病历中的姓名、身份证号、住院号等隐私信息,某问诊AI因漏检「门诊号」被要求整改。
- 治疗建议合规性:对接FDA黑框警告数据库,避免推荐禁忌药物,如不为青光眼患者推荐阿托品滴眼液。
2. 案例:某问诊AI的评测优化过程
- 初测问题:对「罕见病」(如法布雷病)诊断准确率仅62%,主要因训练数据中罕见病知识不足。
- 改进措施:注入Orphanet(罕见病数据库)20万条知识,包括疾病定义(X连锁遗传代谢病)、临床表现(肢端疼痛、肾损伤)、治疗方案(酶替代疗法)。
- 复测结果:准确率提升至89%,鉴别诊断清单完整度从4项增加至7项,成功通过NMPA医疗器械分类审批,成为首个获三类证的AI问诊系统。
(二)SecBench:网络安全的攻防模拟平台
SecBench构建了覆盖漏洞检测、渗透测试、数据安全的全链条评测体系,服务金融、政府等关键领域。
1. 技术路线图
漏洞检测:
实时同步CVE数据库(15万+漏洞),支持0day漏洞推理。例如,2025年某模型通过分析开源代码逻辑,提前识别出某框架的路径遍历漏洞(CVE-2025-1234),证明其具备未知漏洞发现能力。渗透测试:
模拟OWASP Top 10攻击场景,如SQL注入、跨站脚本(XSS)。评估模型的防御建议有效性:- SQL注入防御:要求生成参数化查询代码(如使用PreparedStatement),而非拼接SQL字符串。
- XSS防御:建议对用户输入进行HTML转义(如将
<转为<),某电商模型因未正确转义导致支付页面被篡改,评测得分直接扣30分。
数据安全:
GDPR合规性测试中,个人信息去标识化准确率需≥95%。某政务模型在处理身份证号时,错误保留后4位(应全部脱敏),导致隐私泄露风险,需重新训练实体识别模块。
2. 政企应用差异
| 场景 | 评测重点 | 典型指标 | 代表客户 | 技术难点 |
|---|---|---|---|---|
| 金融 | 交易欺诈识别 | 误报率≤0.1%,漏报率≤1% | 工商银行 | 异常交易模式动态学习 |
| 政府 | 舆情风险评估 | 敏感词识别覆盖率≥98% | 国家网信办 | 多语言敏感词泛化能力 |
| 能源 | 工业控制系统漏洞检测 | 0day漏洞发现率≥30% | 国家电网 | 专用协议(如Modbus)解析 |
- 金融案例:某银行风控模型通过SecBench优化后,对「同IP短时间内多账户高频交易」的识别准确率从85%提升至97%,漏报的洗钱交易减少60%。
- 政府案例:国家网信办采用的模型在「暴恐音视频关键词识别」中,对变种词汇(如「圣战」替换为「圣站」)的检测覆盖率达92%,较传统规则引擎提升40%。
四、中篇结语:从技术解析到工程落地的衔接
专项能力评测如同精密仪器,将LLM的智能解构为可量化的能力切片:数学推理的严谨性、代码生成的工程化、多模态交互的创造性、长文本处理的持久性,以及行业场景的适配性。然而,这些评测面临共同挑战:
- 数据标注成本高:一道高质量医学诊断题需主任医师耗时1小时标注,制约大规模评测数据构建。
- 跨领域迁移难:在数学竞赛中表现优异的模型,可能在金融定价任务中因单位换算错误翻车,暴露领域知识迁移的脆弱性。
下篇将聚焦评测工具链与学术前沿,揭示OpenCompass如何整合30+基准实现效率革命,Confident AI怎样通过企业级监控降低落地风险,以及NeurIPS/ACL顶会如何推动评测技术的下一次突破。当专项评测的「显微镜」与工程实践的「施工图」结合,大语言模型才能真正从「实验室智能」进化为「现实生产力」。