本周又在同一方向上刷到两篇文章,可以说,……同学们确实卷啊,要不卷卷开放场域的推理呢?
这两篇都在讲:如何巧妙的利用带有分支能力的token来提高推理性能或效率的。
第一篇叫 Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning 后面简称二八定律
第二篇叫 R2R: Efficiently Navigating Divergent Reasoning Paths with Small-Large Model Token Routing,后面简称R2R
一句话总结两篇文章
两篇文章都发现了
在推理任务上,一个完整的COT中只有少量的token带有【指引推理路径向左或者向右的能力】——我这里简化称为导航功能,其他大部分token的确定性都比较高。
比如二八定律文中的这张图
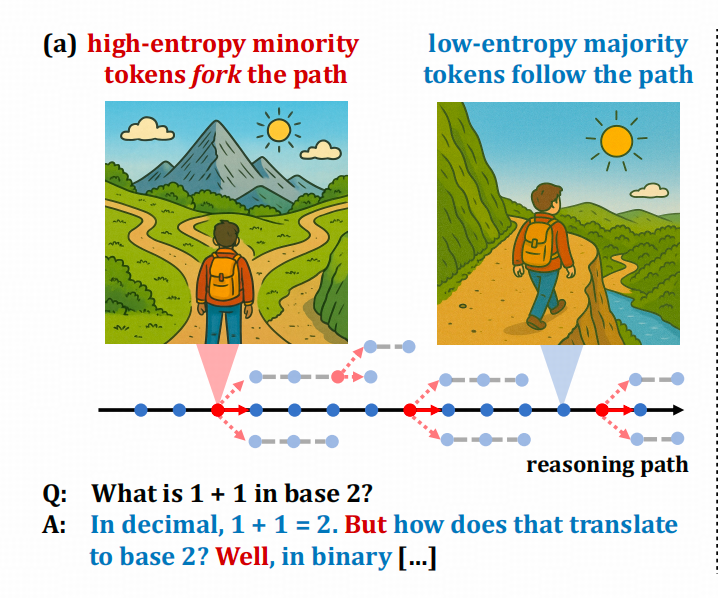
图中的红点和红色词,就是具备导航功能的token。
那怎么利用这个特性呢?
二八定律选择训练的时候专攻这些有导航功能的token,以提升LLM的推理能力;
R2R用这个性质来加速解码→有导航功能的token用大模型来解,其他token用小模型(1.5B)来解。
两篇文章的关键不同
观测角度不同
二八定律是从熵的角度来观测和判别导航token的,token分布中熵top前20的就是导航token;
R2R是通过比较大模型(LLM)和小模型(SLM)在回答同一问题时,从哪个token开始出现差异,再让LLM验证从这个token开始生成的路径是否有本质区别(如思路和答案的正确性)。如果从这个token开始,后续结果确实显著不同,那么这个站在命运的十字路口的token就是导航token。
优化方向不同
二八定律从改进RLVR的训练目标出发,希望直接产出一个更强的模型。
R2R 从改进投机解码的角度出发,希望对同一个模型更快的产出结果。
由于这两篇文章除了【都是研究怎么利用高熵token】以外,实现细节上基本没有什么交集,下面还是分开介绍
关键细节
二八定律的思路
发现现象→验证现象→对症提出优化方案→Ablation验证优化点
发现的现象与分析
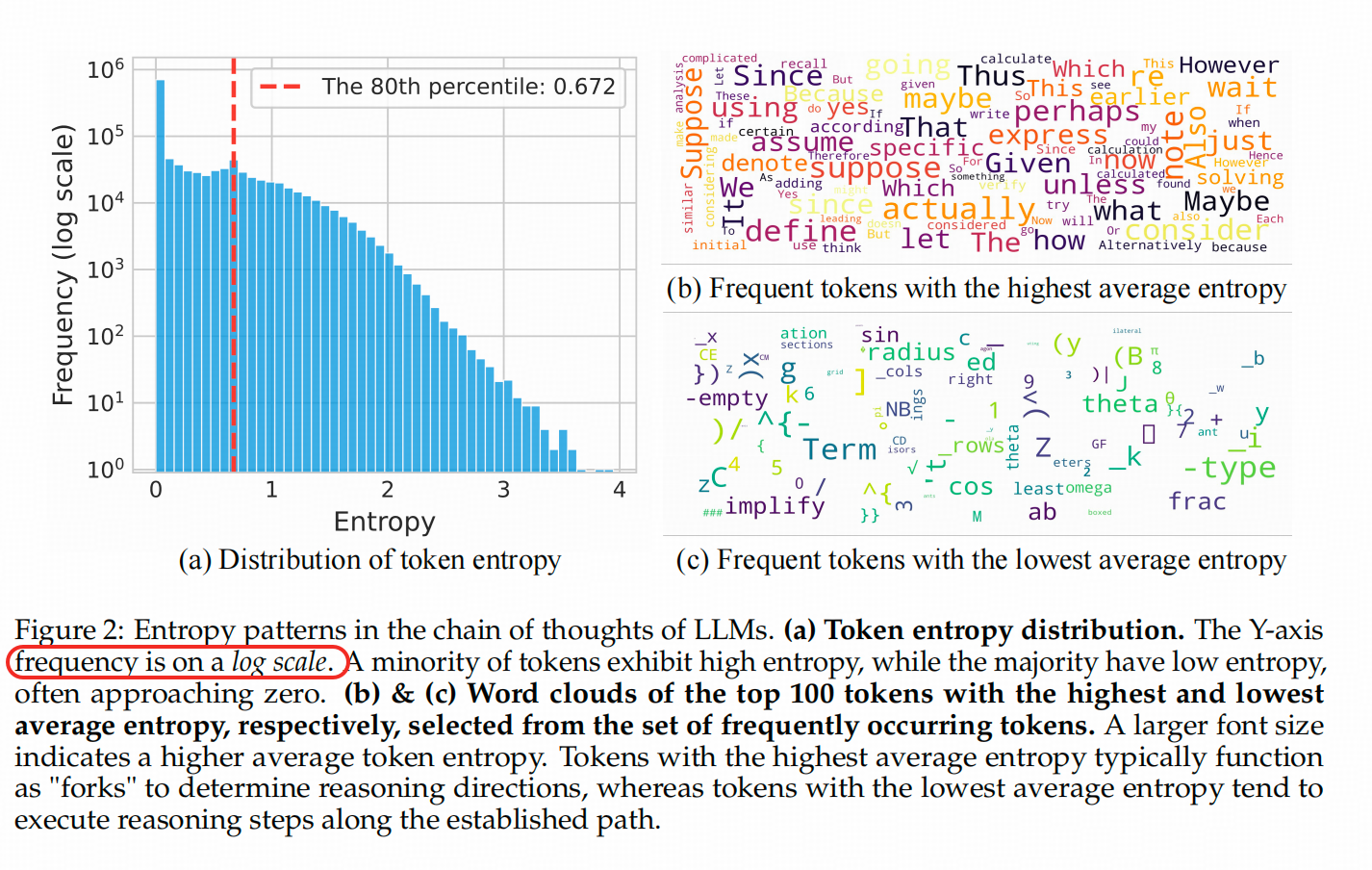
观察上图左侧,这是Qwen3-8B在回答AIME’24和AIME’25问题时,COT中token对应熵的直方图。注意,这个直方图的纵轴是对数缩放的,也就是说,在原始Y轴上,红线左侧的柱子非常高。这个图的目的是为了说明为什么选择2-8分而不是3-7分等其他分法。因为过了红线后,右侧的柱子开始逐渐变短;而红线左侧(80%的token)的分布类似于一个平台。虽然2-8分仍然是一种基于分析的直觉选择,但是咋说呢,作者尝试给你园了一下😁。
倒回来说一下这个熵具体是什么,是生成位last hidden 映射回词表维度,并softmax以后得到的伪概率作为 p ∈ R 1 ∗ V \mathbf{p} \in R^{1*V} p∈R1∗V(即一个词表长度的向量) 算出来的熵 − ∑ p i log ( p i ) -\sum{p_i\log(p_i)} −∑pilog(pi)
上图右侧展示了熵较高的token对应的词,这和我们的认知相似,一方面属于认知行为中比较关键 验证、定义、归因等等,一方面在语言表述中,这些词的出现确实会给后面的子句定个调子。
另外,这个红线位置的熵是0.672,后面有用。
验证现象
熵的分布上有这样的特点,那又能带来什么呢?扰动一下,看看结果?
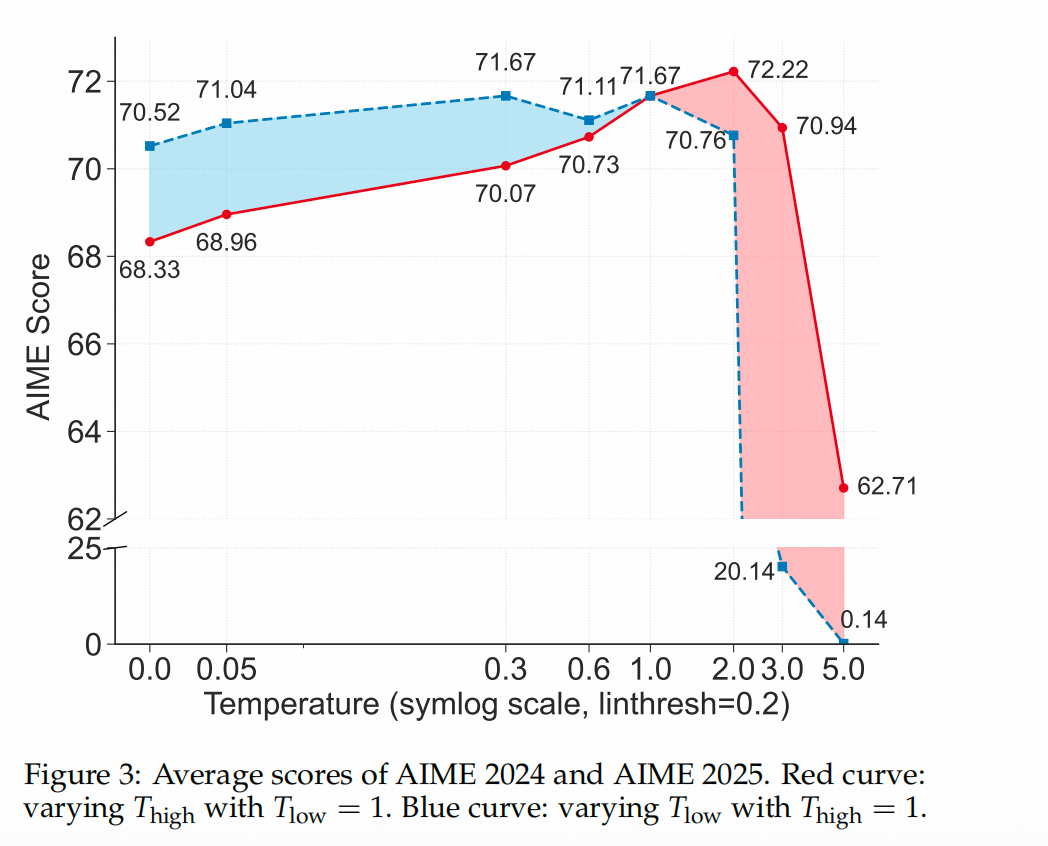
↑上图中,二八定律作者还是用AIME的24和25 数据集作为实验场,扰动了COT的生成过程:他用0.672作为经验阈值,对熵高于这个值的token(导航token)
给予更高的采样温度,增加不确定性;对熵低于阈值的token则不作处理,形成红线。蓝线则相反,对熵低于0.672的token赋予更高的温度。图中红蓝两条线的交点代表了基线,即没有调整采样温度的情况。
结果显示,提高导航token的温度能让模型达到更高的精度(但温度超过2后效果变差),而对非导航token的情况则相反,温度小于1时模型推理效果更好。
既然这种策略在生产时能优化模型,那么在训练阶段能否利用这种性质让模型变得更强呢?
※碎碎念:其实我相信作者在这个阶段应该是试过放大温度以外的方法的,要是成了后面可能不会往训练推。
提出优化方案
文章的这个部分,思路有些断档,因为作者选择的是优化DAPO算法,所以他先分析了DAPO给模型的熵带来的影响。这里先回放一下DAPO的优化目标公式。

公式里面 A A A是advantage,跟GRPO一样,是共享的, r r r跟PPO一样,新旧模型的比值。
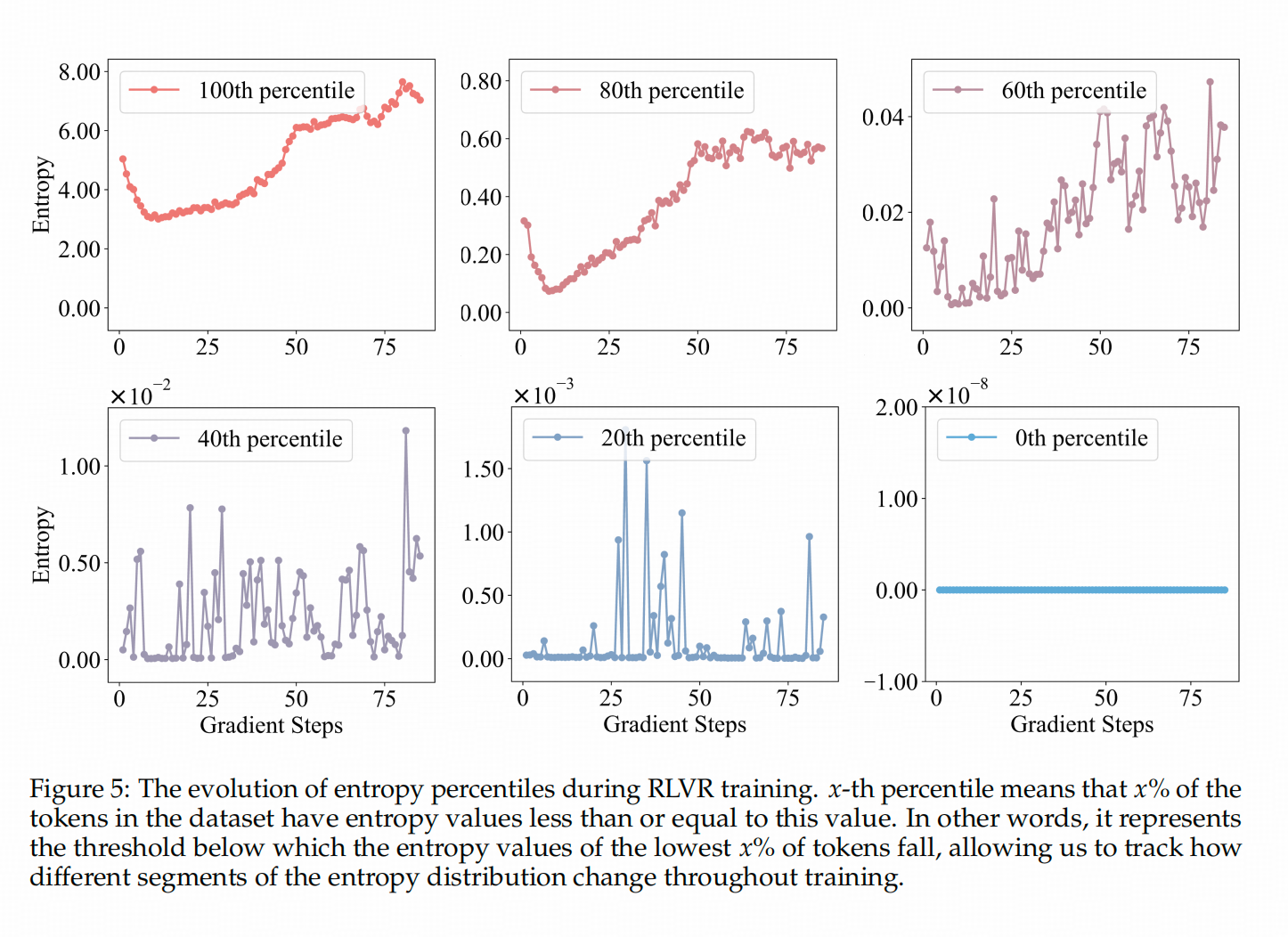
在RL训练前,作者将原模型的token按熵的大小分成0%(熵最小的组)、20%、40%、60%、80%和100%(熵最大的组)这几组,观察训练过程中,
这些token的熵变化趋势。←上图展示了这个变化过程,可以看到,上面一行(熵大小前60%的token)在训练中熵还在增加,而下面一行(熵较高的token)基本没有变化。也就是说,DAPO在训练过程中对熵的影响,确实是「旱的旱死,涝的涝死」。既然如此,猛踩油门(在高熵token上加点)还管用吗?↓
单独优化熵高的token能够继续拉高模型的推理能力
这就是作者给出的RL的优化目标。公式中标红的部分就是二八定律文给出的优化。
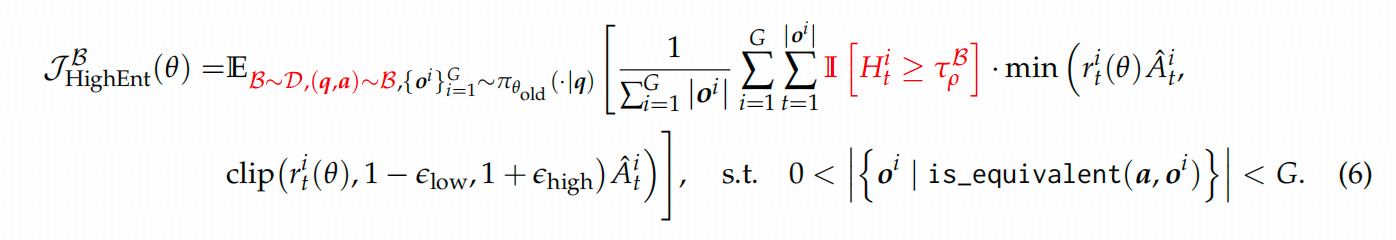
这个优化包含两个点:
- 只优化
导航token:训练中不适用经验阈值来确定导航token,而是由训练中的token的熵分布的前20%percentile决定的。 - 改用一个batch训练:这里必须使用batch,因为计算熵分布时需要足够的数据来确保其可信度。毕竟,如果只对一个QA对的16个样本中的所有token计算分布,结果会有偏差。训练中使用的batch_size为512。
效果如何
跟基线比,涨点了;跟原版DAPO比,也涨点了。
作者训练了Qwen3的三个模型:8B-base、14B-base和32B-base,并在AIME24数据集上进行对比。8B模型在Qwen的tech report中的指标为29.1%,经过DAPO处理后为33.33%,使用作者的改良版DAPO后提升至34.58%。32B模型在Qwen的tech report中的指标为81.4%,经过DAPO处理后为55.83%,使用改良版DAPO后提升至63.54%。尽管这种训练方法提高了32B-base的推理能力,但仍不及开源的32B模型。
当然,这是一篇纯方法论的论文,比较一个把好数据和好方法都堆上的模型也是有点欺负人。
跟DAPO比,scaler能力更强
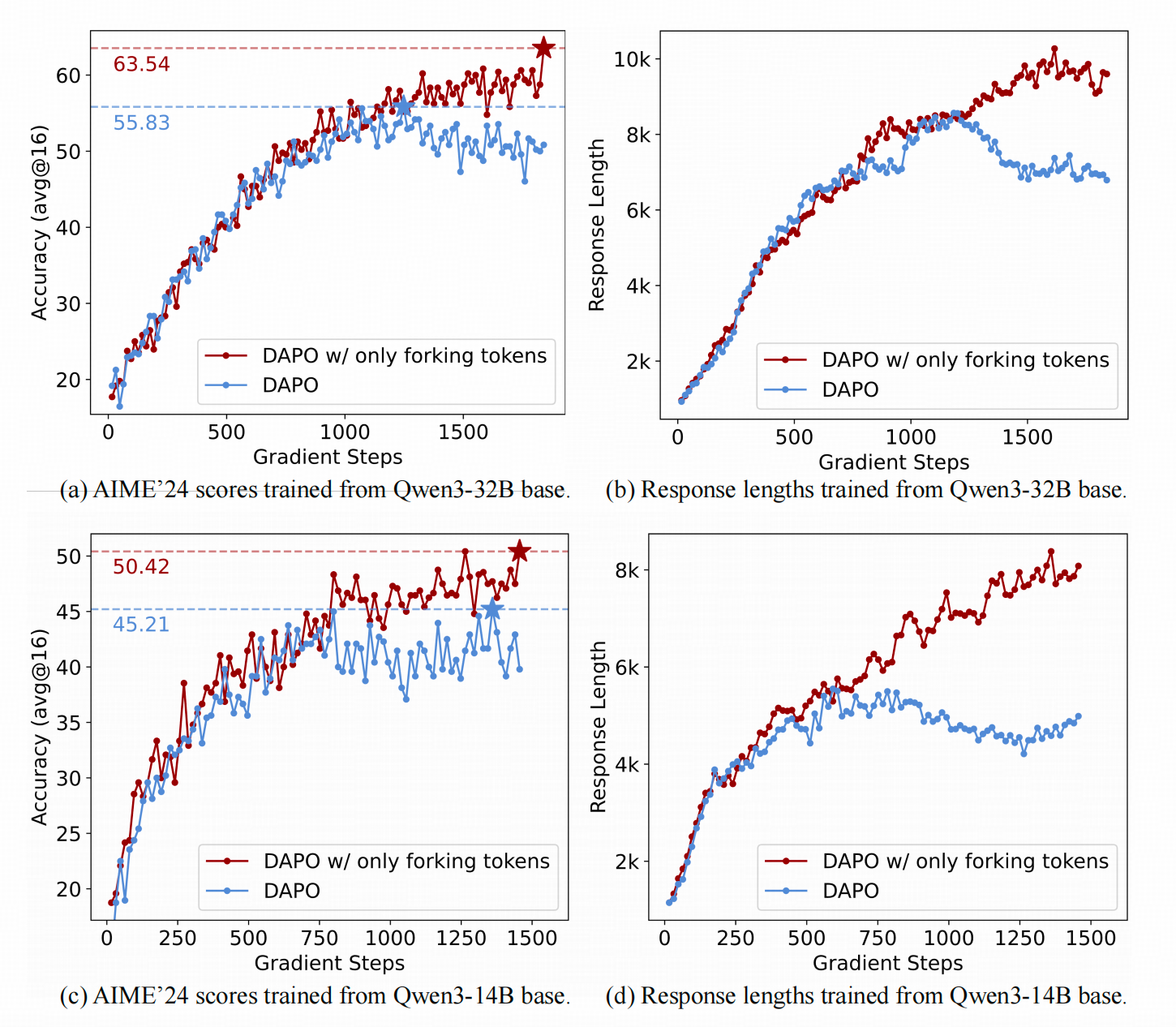
上面两张图展示了用DAPO和改良版DAPO训练Qwen3-32B(上行)和Qwen3-14B(下行)在训练过程中的模型准确率和生成长度的变化。
可以看到,作者的改良版DAPO相比原版具有更高的上限,并且生成长度在训练中后期还在增加(这实际上是好事,因为它给test-time scaling留下了更多空间,但作者没有在后续实验中讨论这一点)。
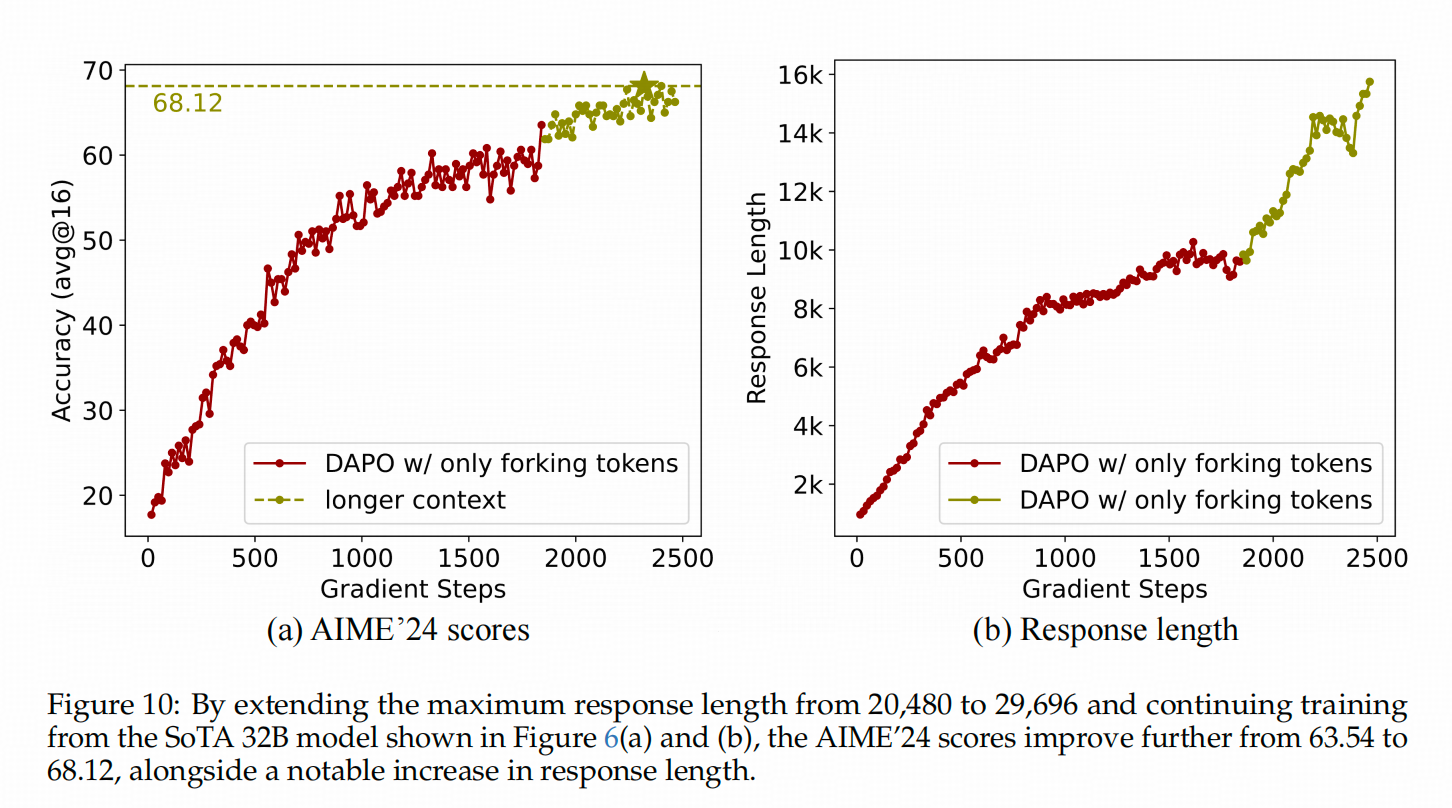
随后,作者将推理长度限制从20K延长到29K,继续训练后,32B模型的性能确实有所提升。下图黄色部分展示了在扩展长度后的模型准确率和生成长度的变化。
R2R 的方法
R2R的思路是,“我有一个假想,我按照这个假想试试”
他的假想是
※1-大模型能力强,小模型能力弱,这两个模型的能力的差异体现到token级别的时候,就是看到同样的问题生成token的不一样。↓
※2-这些不一样的token中,可能有一些是无关紧要的(一个意思的不同表示方法,这个在Softthinking哪篇文章展示的案例中恰恰有体现),有一些token可能决定后面的发展,即我们通篇在提的导航token。这种导航token无疑在解码的时候是不能错的。↓
※3-那解码的时候,怎么保证不用小模型来解导航token呢?得先识别出来。
要识别导航token,离线时固然可以用样本分析然后归因的方法,但生产时候这个套路就玩不转了。最简单的方法就是建个模型来识别哪个是导航token。↓
※4-在生产的时候,这个模型接受小模型的last_hidden等输入,并判断该token是否 就是导航token,是的话用大模型解码,不是的话用小模型解码。
作者画了个图来展示他整体的思路。下图中SLM就是1.5Bd大模型,LLM是32B的大模型

导航token的分析
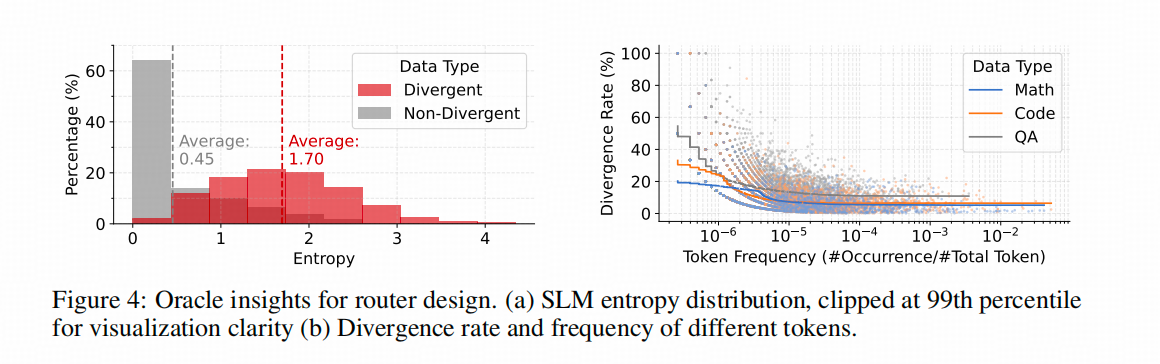
R2R的作者同样分析了token的熵,不过他分析的是小模型的熵分布。他没有使用top-p,不知道是不是因为小模型token熵的top-p没有大模型的对应数值有决定性价值。总之,他先标记了哪些token是大小模型在相同query下不同,且会引发后续推理链路大大不同(用大模型评测)。在上图左侧直方图中,这些token用红色表示,其他token的分布是灰色。
上图右侧图的展示逻辑有些复杂,但结论是,训练语料中出现频率越高的token,其成为导航token的概率越低。
效果如何
确实快,下表中各个数据集的第一列是accuracy,第二列和第三列的逻辑差不多,第二列显示实际计算的平均参数量(包括SLM、导航token识别模型和LLM),第三列显示平均参数量乘以平均长度,所以第三列可以先不看。(因为这个方法对实际生成长度影响不大,可以参考原文表3,我就不展示了)。
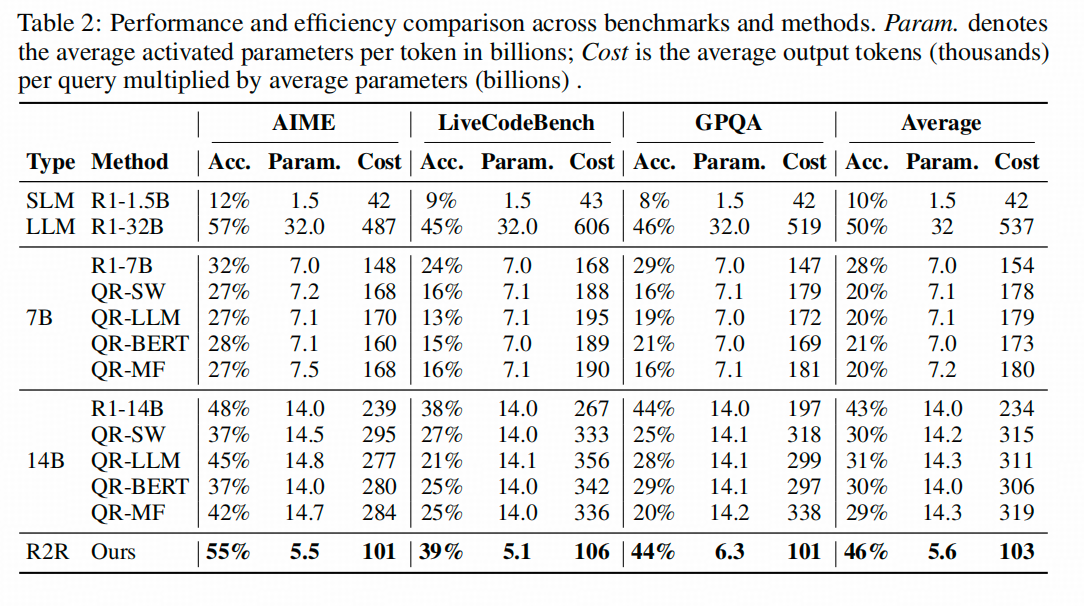
上图显示的结论是,R2R比纯用32B模型推理的准确率低一点点,但比32B模型实际算的参数量小很多很多(我不太理解为啥不用Flop衡量?我本身对decode了解有限,不瞎嘴了)
两篇文章的整体评价
两篇文章的实验分析部分都有遗憾
二八定律的实验分析中,缺少了test-time scale方面的比较,也没有进一步展示导航token的变化趋势—— 比如哪些token会推出top20呢?
R2R 文则一来没有对导航token进行展示和定性的分析(这些对后续研究是有启发性的,但作者没有展示),二来,其比较实验中的比较组也有点奇怪,虽然比较了很多解码方案,但是是在14B的模型下比较的?虽然比了投机解码方法,但是在附录里比的,主要是效率。
二八定律是否能在推理以外的场景中推广,需要更多的验证。
在实验分析部分,二八定律文展示了在数学任务上训练的模型在代码数据集上是否也有优势——答案是肯定的。然而,目前推理任务的研究主要集中在数学和代码任务上,也该考虑move-on了。毕竟到了不能直接验证是否正确的场域,RLVR也要改改。