准备工作
本文不包含部署过程,请自行搜索教程
请确保已经部署好集群并且可正常启动
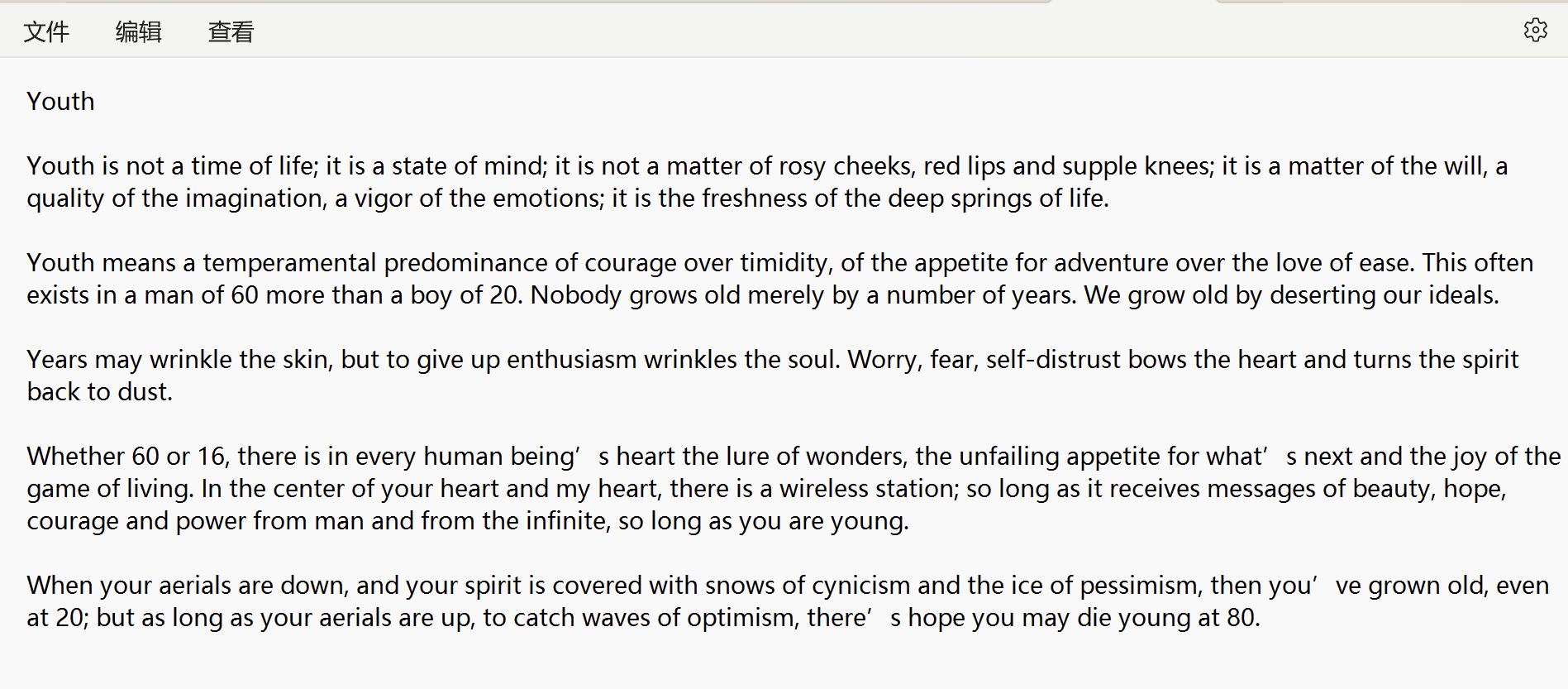
准备一个txt测试文件,例如
一、SSH
1.通过ssh连接集群的主节点
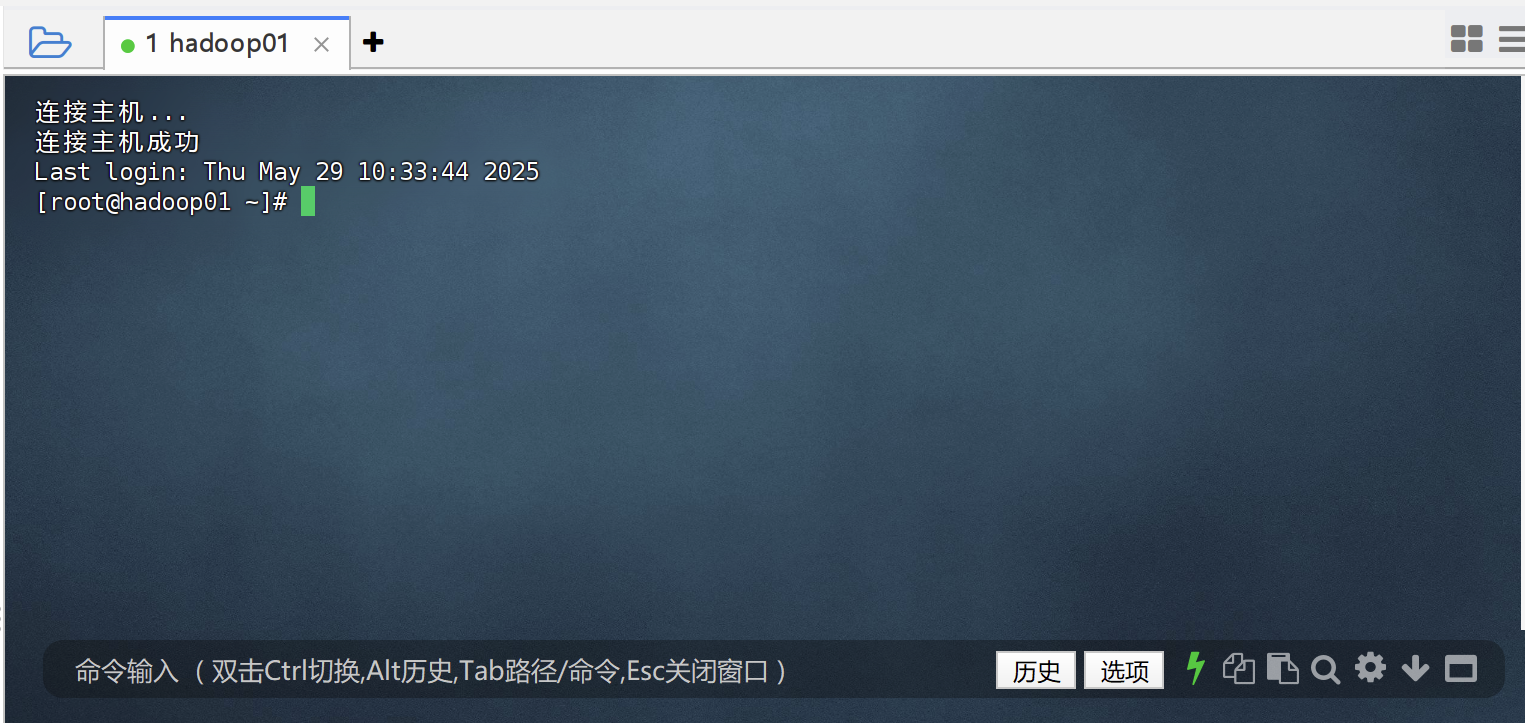
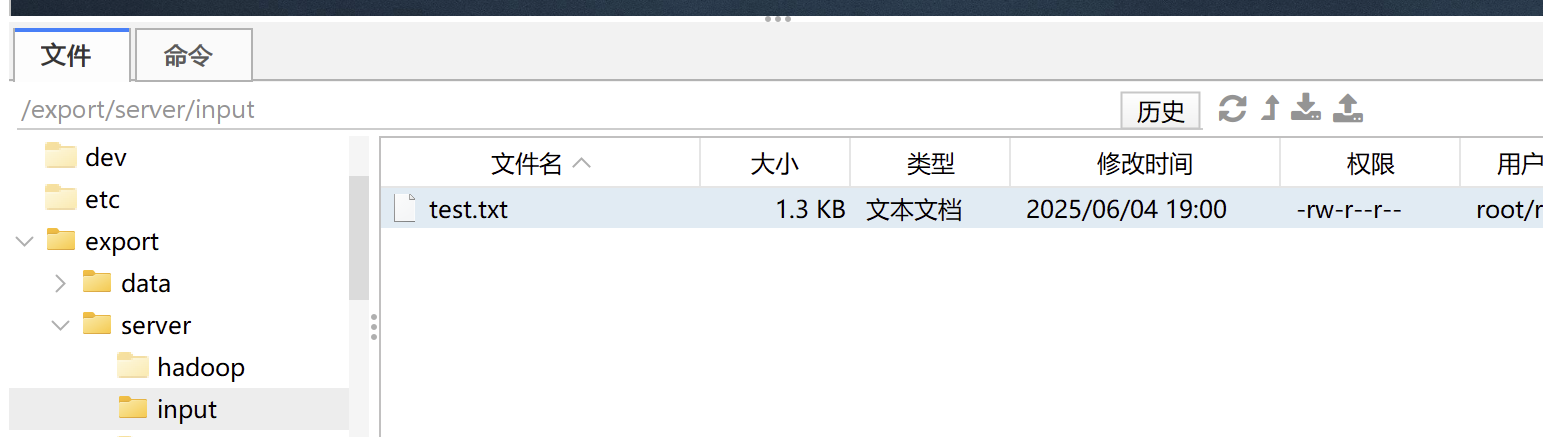
2.将刚才的txt文件上传到主机中
我这个软件是finalshell
3.启动集群
start-all.sh
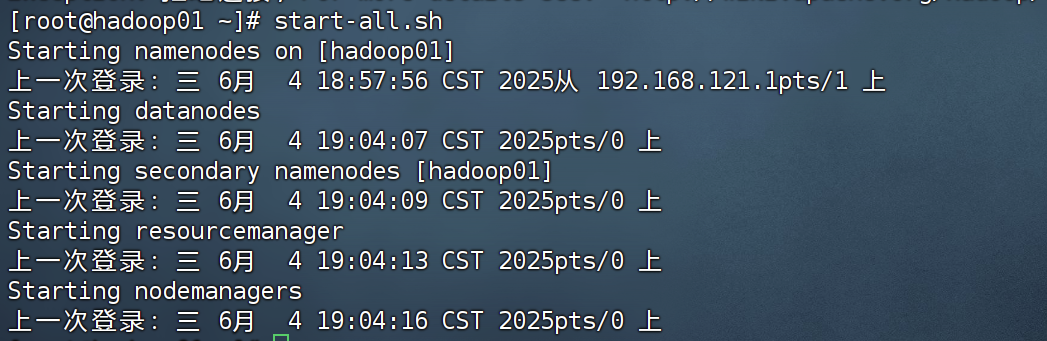
4.上传测试文件
# 创建目录(-p 确保父目录存在)
hdfs dfs -mkdir -p /wordcount/input
# 上传本地文件到 HDFS(假设你的数据在本地 /path/to/local/input)
hdfs dfs -put /path/to/local/input/* /wordcount/input/
注意这个目录是集群上的目录,和你本地目录不是一个意思
5.计算
(1)进入mapreduce的目录
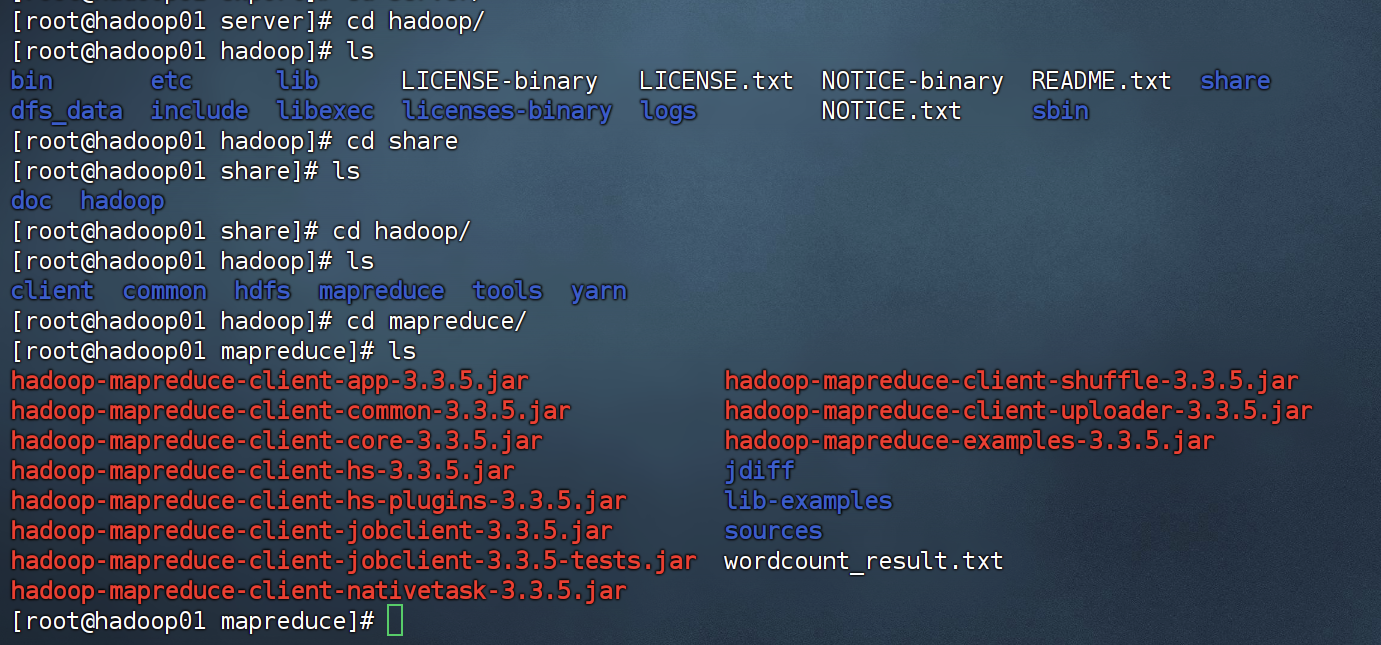
(2)注意你想输出的目录是不能存在的,如果已经有了会报错,删掉

hdfs dfs -rm -r /wordcount/output
(3)运行
hadoop jar hadoop-mapreduce-examples-3.3.5.jar wordcount /wordcount/input /wordcount/output
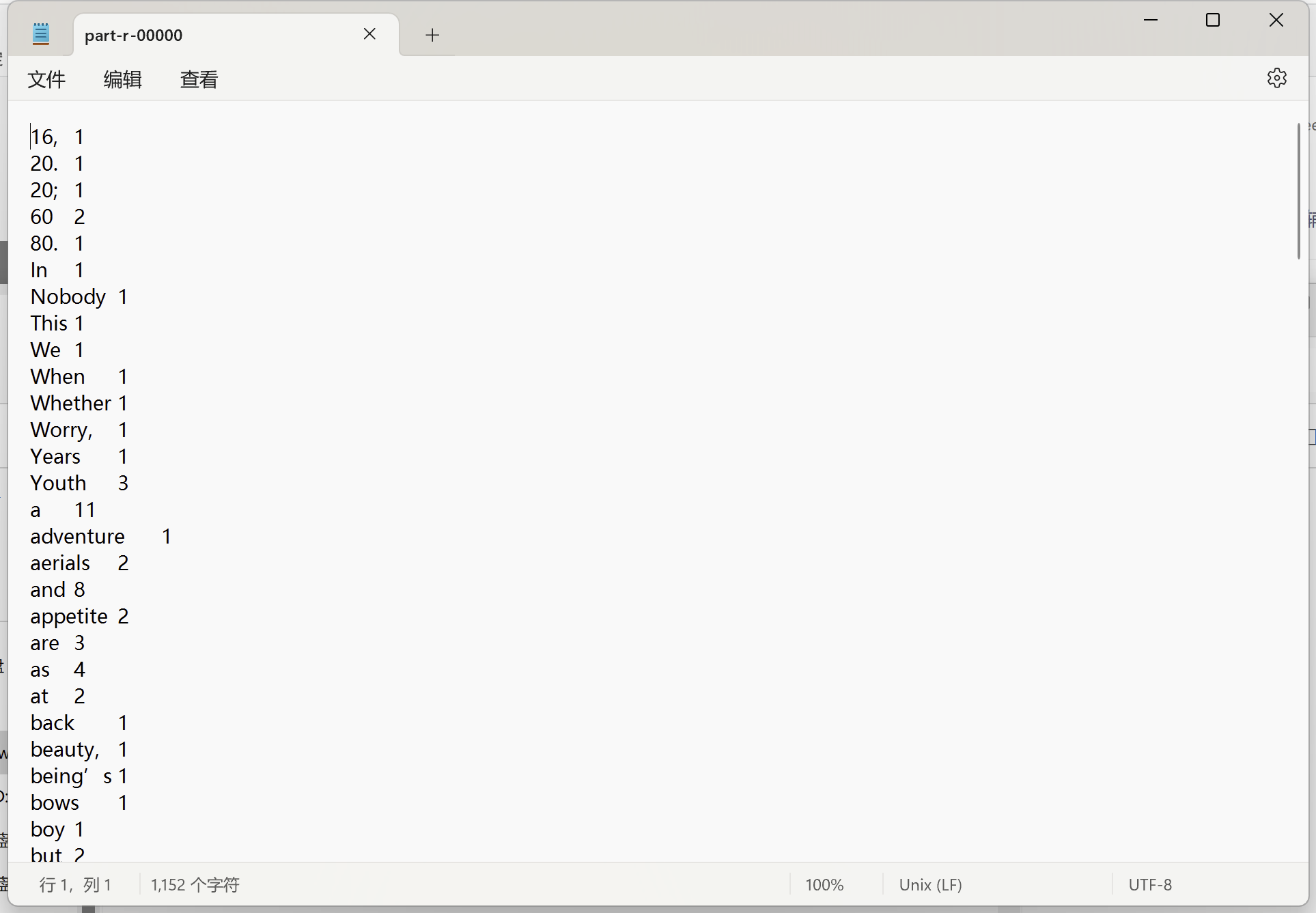
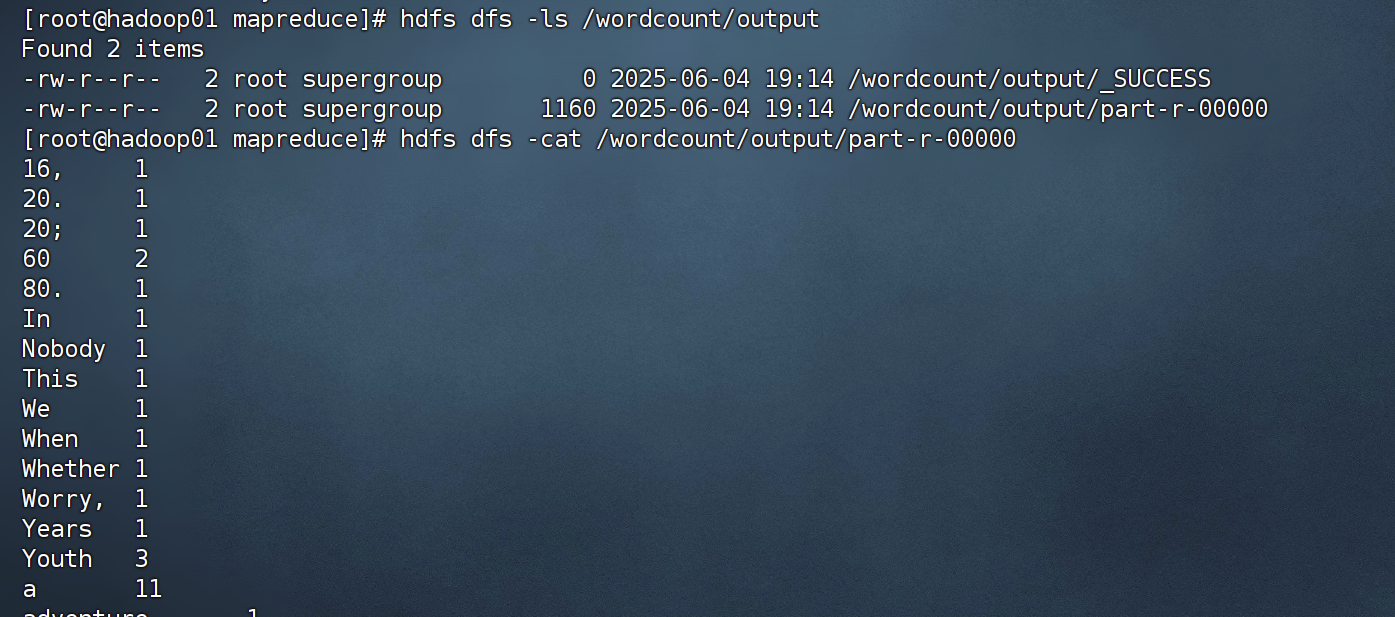
6.结果
hdfs dfs -ls /wordcount/output
hdfs dfs -cat /wordcount/output/part-r-00000
这个part文件你也可以再从集群下载到本地导出
二、web
web就不用ssh连接,都是虚拟机里直接操作
1.启动集群
start-all.sh
2.创建目录并上传文件
(1)打开浏览器,直接进入本地集群
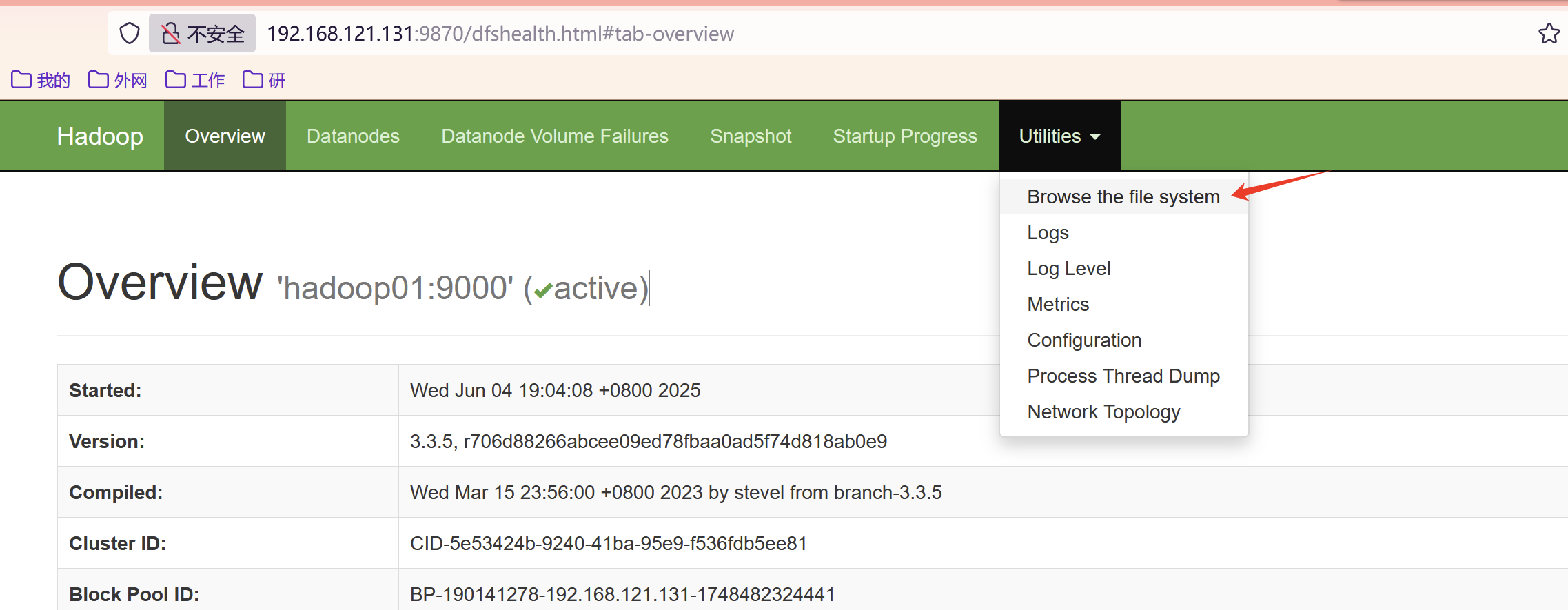
(2)给权限
hdfs dfs -chmod 777 /
(3)创建目录/wordcount/input
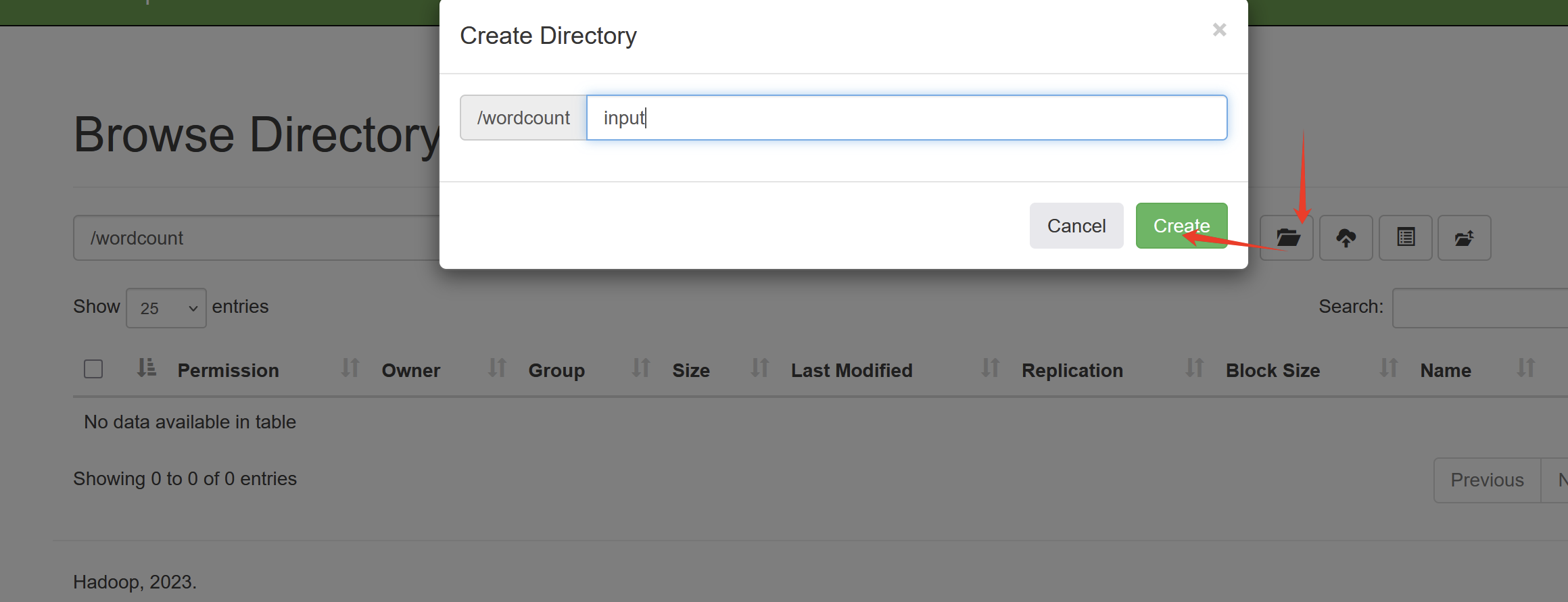
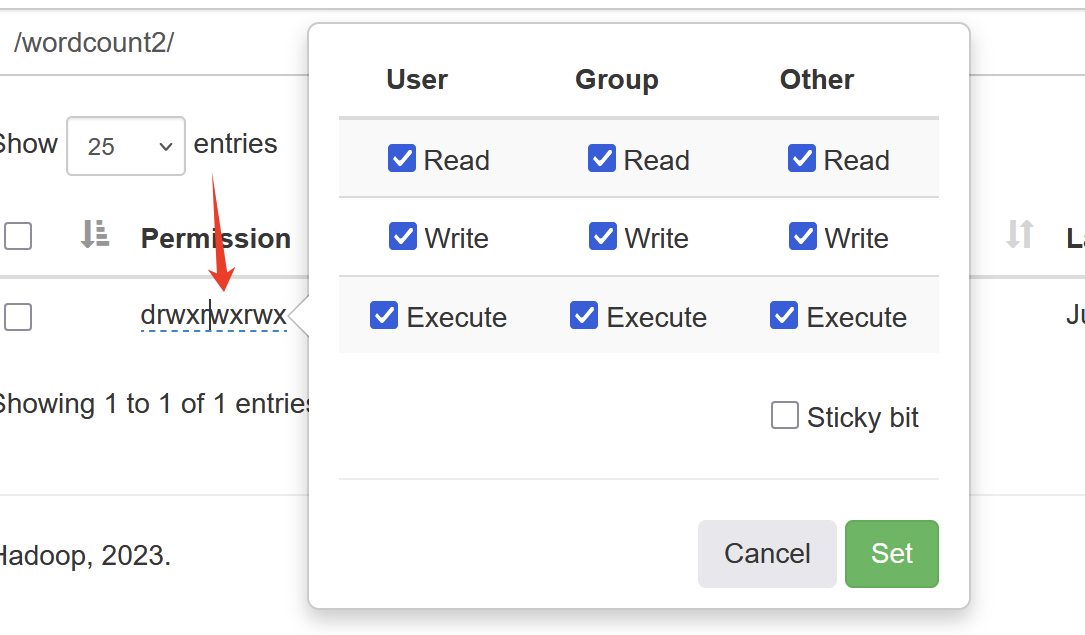
可以直接修改权限
(4)input下上传文件
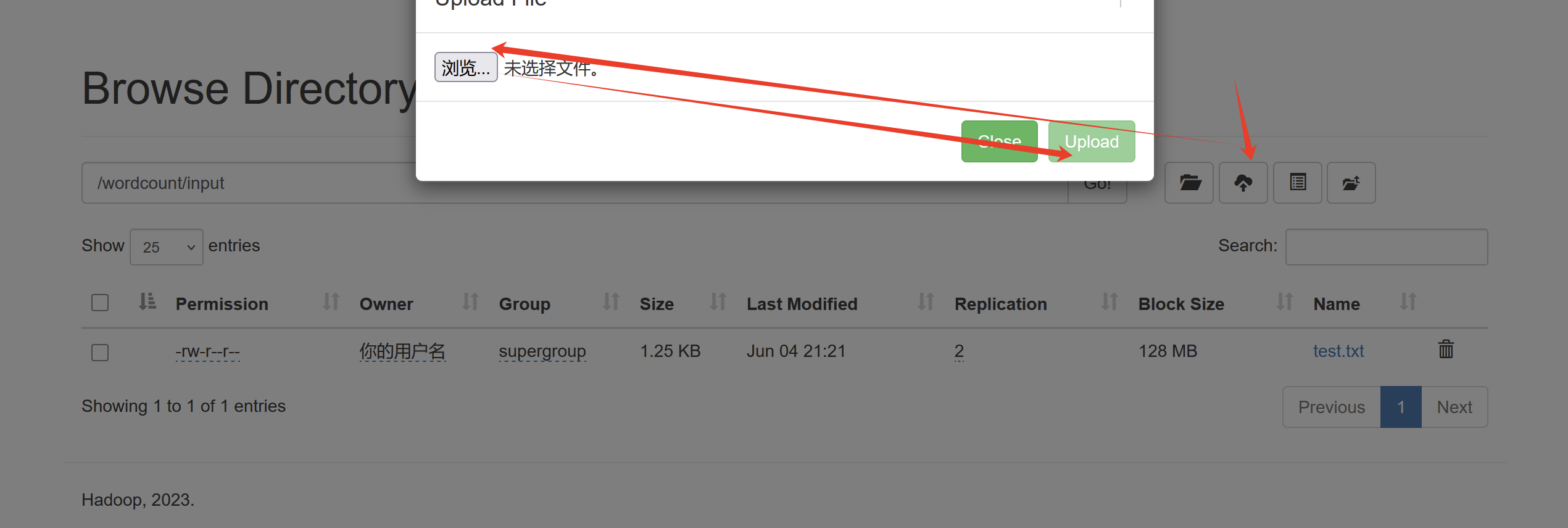
但是可能发现上传失败
看一下记录
这里我们可以看到是想通过2和3节点上传,但是windows不知道这两个节点的ip,所以连接不到,那么给windows系统配置一下

此目录下右键hosts选择属性
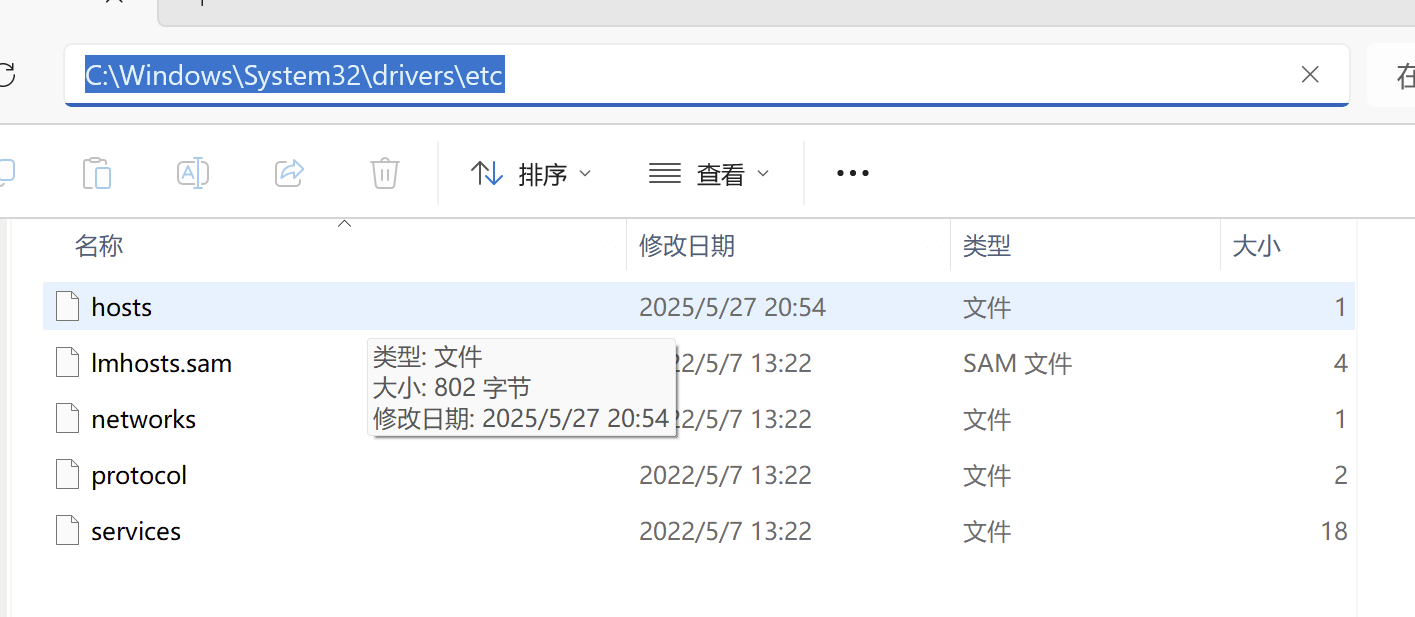
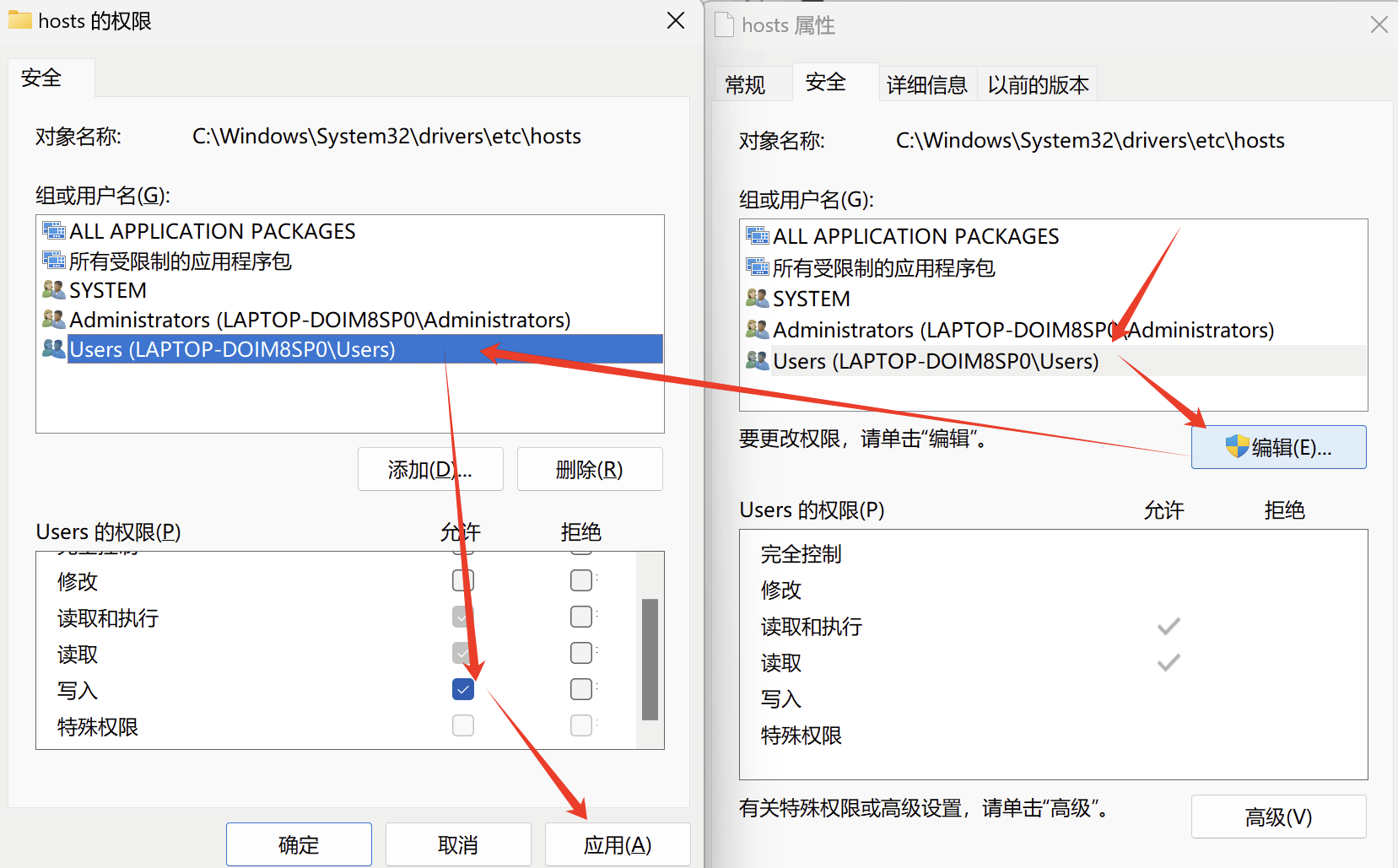
用记事本打开
最后面写上ip和名称对应,保存关闭

3.运行
回虚拟机,从刚才创建的目录执行
(1)进入mapreduce的目录
(2)注意你想输出的目录是不能存在的,如果已经有了会报错,删掉
hdfs dfs -rm -r /wordcount/output
(3)运行
hadoop jar hadoop-mapreduce-examples-3.3.5.jar wordcount /wordcount/input /wordcount/output
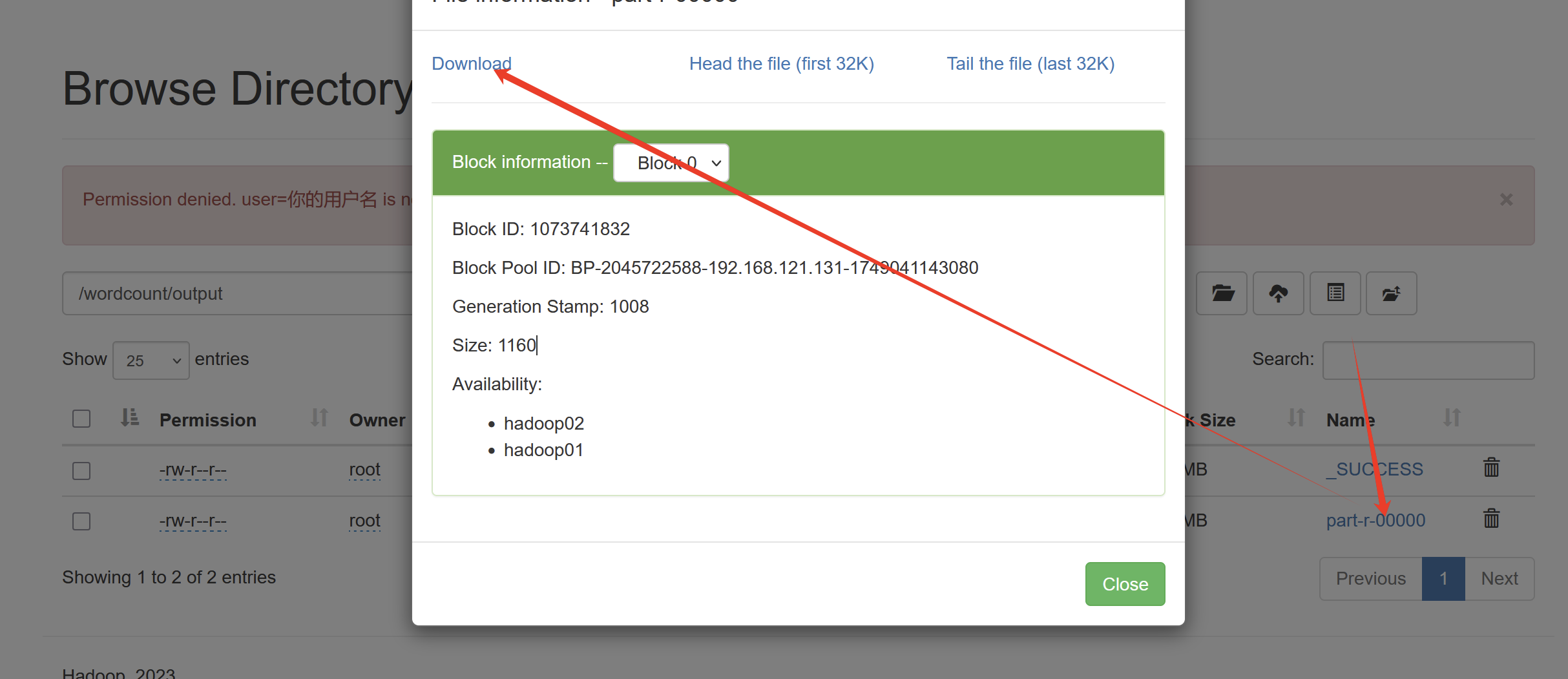
(4)下载
回到web,刷新一下
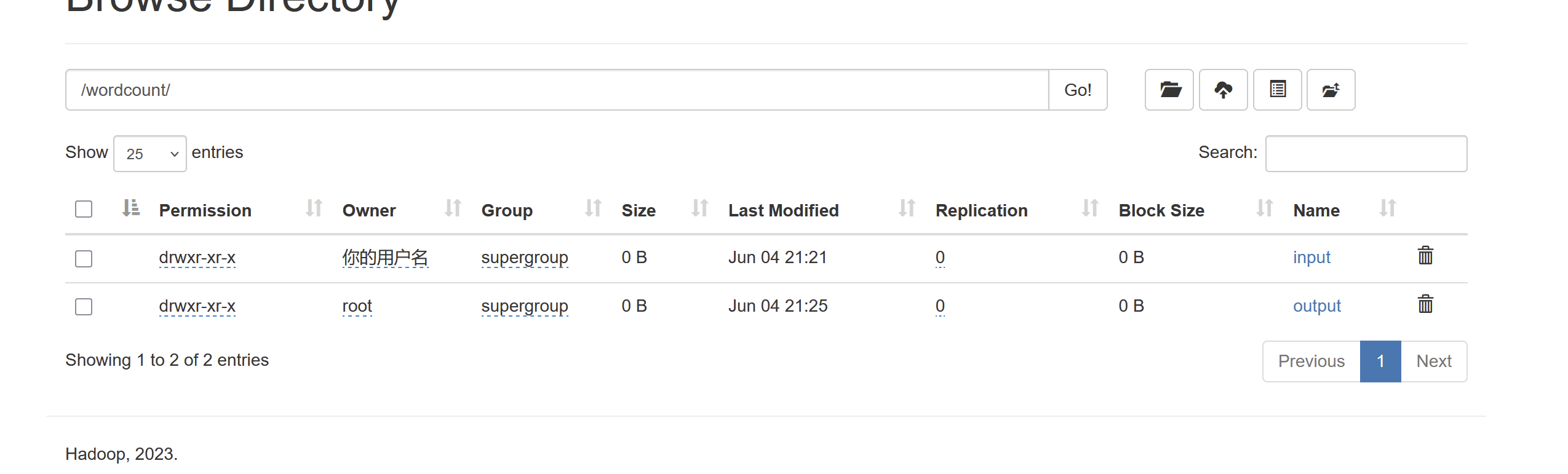 点进新的文件夹
点进新的文件夹
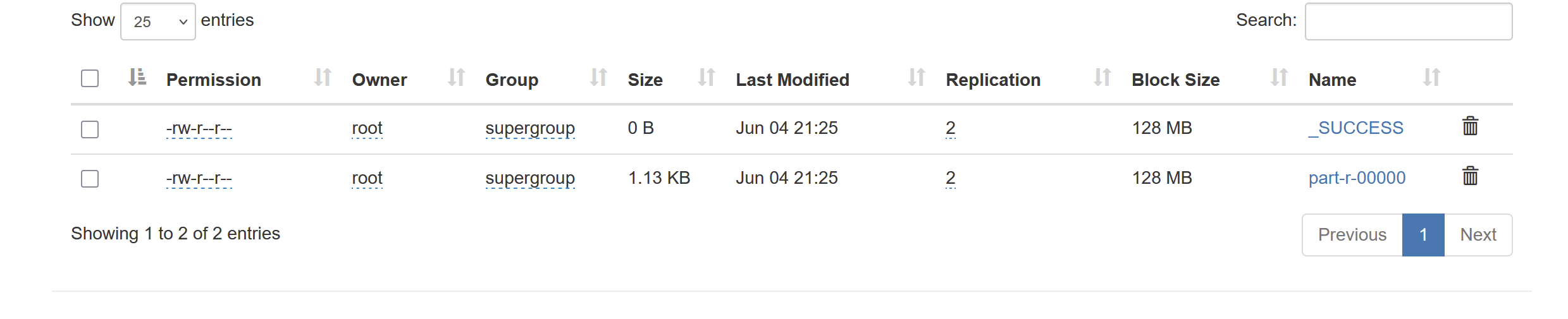
下面那个就是结果,直接点击下载
记事本打开直接看结果