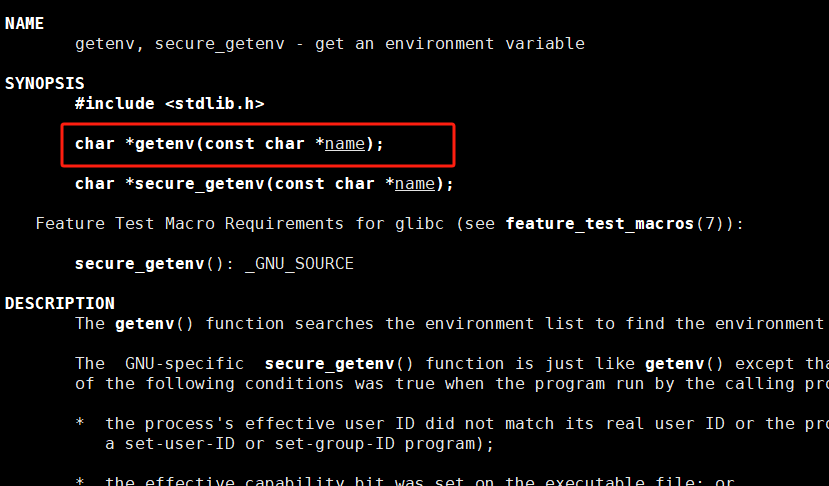
在上一篇博客结束的时候,我们了解了僵尸进程,现在我们接着僵尸进程继续往下探索,所谓的僵尸进程就是当子进程退出时,父进程如果一直不对子进程进行回收,子进程的状态就会一直变成僵尸状态(Z状态),这就好比你的女朋友给你分享了一个很有意思的视频,希望可以和你得到情绪共鸣。但是你呢,经常打游戏打的什么都顾不上,而在那边你女朋友一直等待你回复一下这个视频好不好看,但是迟迟等不到你的回复。此时,你女朋友的状态就属于僵尸状态,一直等待你的回复。
但是有的比较勇的兄弟,可能会说,我有时候就是不想看,我女朋友一天给我发上百个视频,太多了,根本看不过来,索性我就不看了,直接不回,而在操作系统中也有这种情况,这种情况就会导致进程变为孤儿进程。
孤儿进程
#include <iostream>
#include <cstdio>
#include <unistd.h>
#include <cstdlib>
int main()
{
pid_t id = fork();
if (id == 0)
{
while (1)
{
printf("I am child,pid:%d,ppid:%d\n", getpid(), getppid());
sleep(1);
}
}
else if (id > 0)
{
int count = 3;
while (count--)
{
printf("I am father,pid:%d,ppid:%d\n", getpid(), getppid());
sleep(1);
}
exit(0);
}
return 0;
}看到这个代码中子进程就是相当于你女朋友一直给你发消息,而父进程就是你,即使打完游戏,也不想看你女朋友给你发的视频,直接忽视。接下来我们可以看一看这个孤儿进程。
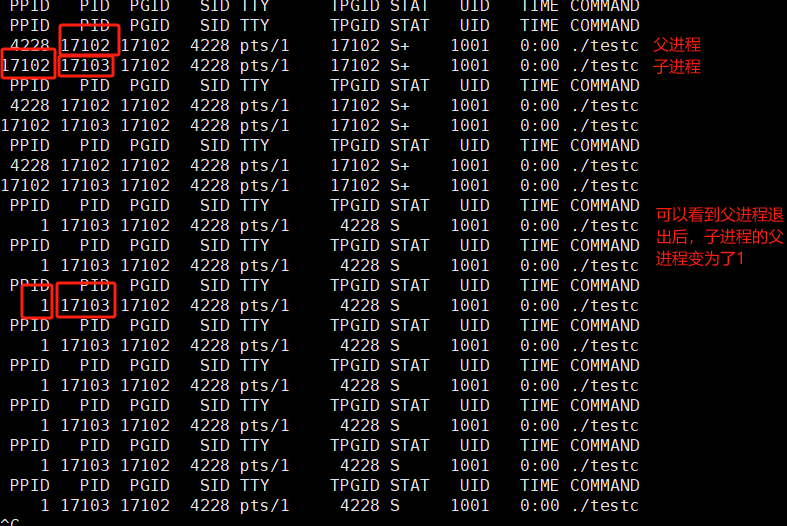
通过上图观察到,当父进程退出后,子进程的父进程变为了1号进程,相信聪明的大家一定能猜到,这个1号进程就是我们的操作系统

Linux系统中的1号进程是init(或systemd),它是所有用户空间进程的父进程(祖先进程)。内核启动后,1号进程由内核直接启动,负责初始化用户空间环境、启动其他系统服务和管理进程生命周期。
所以,如果父进程不回收子进程的退出信息并且直接退出,这就会让我们的操作系统对其进行领养,进而让操作系统对孤儿进程进行回收,这也就是说,如果你进场不回你女朋友给你发的消息的话,你女朋友就可能会被其他人拐跑了,所以无论如何我们都要回复女朋友的消息,也就是我们的父进程一定要对子进程退出时做出响应,不能对其置之不理,不然就要失去你的女朋友了。
其实,大家看到这里其实就可以感觉到一点,就是进程组织结构有点像多叉树一样,一个父进程可以创建多个子进程,那就有点奇怪了,之前你不是说进程不是通过链表组织起来的么,这怎么又变成多叉树了,其实在操作系统中的设计是十分复杂的,咱们现在学的都是链表就是链表,多叉树就是多叉树,但是linux操作系统那是天才设计的,它们在设计linux时,都是多种结构共同使用,这就好比,我们现在学功夫一样,咱们都是一招一招的使,而高手都是直接将各个招数行云流水一般的使用。
其实,我们只需要将所有信息填充到PCB中,再通过访问PCB的成员,就可以达到这样的效果,接下来,我们简单了解一下linux是怎么实现的
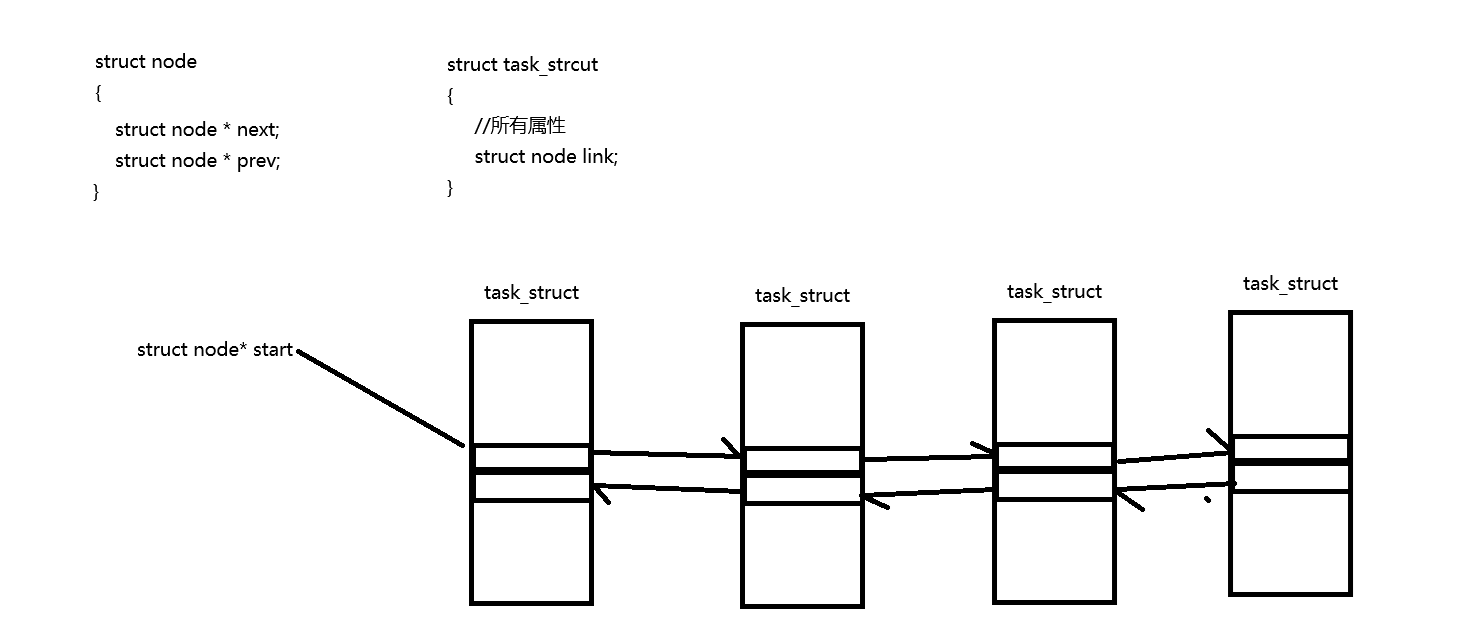
&(task_struct*)0->link,这个就相当于我将0号地址看作task_struct的地址,然后访问它当中的link对象,取地址就获得了link在task_struct中的偏移量。
(task_struct*)(start - &(task_struct*)0->link),这个start是运行队列的首元素地址,这个真实分配的地址减去link在task_struct中的偏移量,这样就可以获得该结构体的首元素地址,这样就可以根据这个指针访问其他的PCB成员,获得了PCB,这样就可以对所有的结构进行访问了。
在linux中经常会有这样的偏移量操作进行对PCB的访问,进而控制进程的执行,所以说能设计出这样操作系统的,确实厉害。
优先级
首先,为什么要有优先级这个概念呢?用我们的生活中的例子,大家在上完课一般都会去食堂吃饭,在食堂吃饭时,大家都会依次排好队进行打饭,排队的过程就是确定优先级,那么为什么进行排队呢(优先级)?这时因为我们所在学校的食堂即使再多,也不会有人多,学校是不可能为我们每个人分配一个厨师的,如果真的有这样的学校,这学校就要连厨师的工资都要付不起了,所以为了在有限的资源中,大家都可以吃上饭,我们就有了优先级这样的概念,在操作系统中,能用的资源肯定是有限的,为了让这些进程(我们去食堂吃饭的人)都可以获得资源,就必须进行排队,从而确定优先级,如果没有优先级(不进行排队的话),大家那都开始通过实力进行吃饭了,一些柔弱的女孩子就会抢不过,从而一直吃不上饭,那就坏了,所以这就是为什么要有优先级,因为操作系统要保证各个进程可以良性竞争,不然就会导致操作系统扛不住大量进程的恶心竞争,从而导致操作系统挂掉,那就坏了。
了解了概念,我们就来看看linux中的优先级
首先,我们执行一段代码,通过观察这个进程的优先级,对优先级进行深层次的理解。
#include <iostream>
#include <unistd.h>
int main()
{
while (1)
{
std::cout << "I am a process , pid : " << getpid() << std::endl;
sleep(1);
}
return 0;
}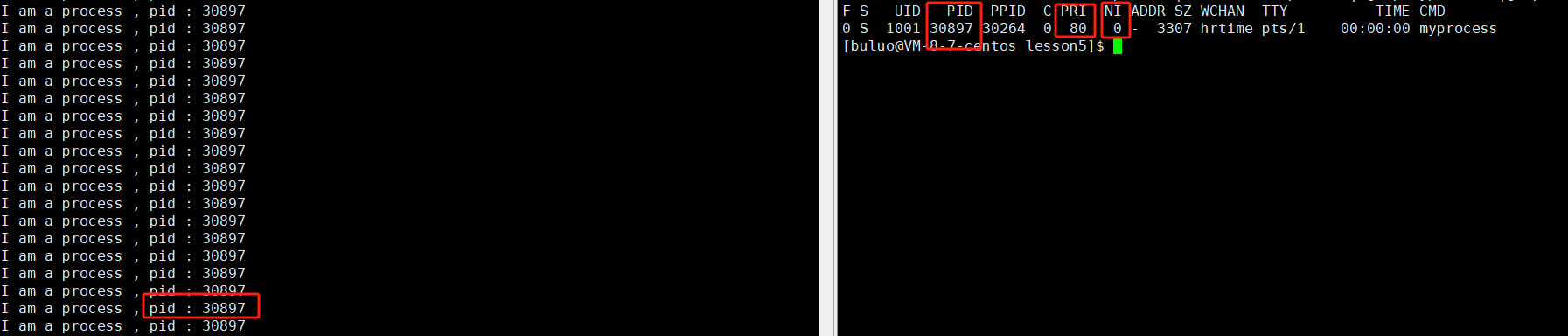
从上面的结果图我们可以注意到这些信息:
- PID:代表整个进程的代号
- PPID:代表该进程的父进程代号
- PRI:代表这个进程被执行的优先级,它的值越小越快被执行
- NI:代表这个进程的nice值
PRI 和 NI
- PRI还是很好理解的,就是进程的优先级,通俗讲就是程序被cpu执行的先后顺序,值越小优先级别越高
- NI是什么呢?就是所谓的nice值,其代表的就是进程可被执行的优先级的修改数值
- PRI越小越快被执行,那么加入nice值之后,PRI(新) = PRI(旧) + nice
- 这样当nice值为负数时,该进程的优先级就会被增大,优先级就会被提高,就会越快被执行
- 所以,linux下调整进程的优先级就是调整进程的nice值。
- nice值的范围为-20至19,一共40个级别。
- 注意nice值不是进程的优先级,而仅仅只是能够影响进程优先级变化的值。
看到这,大家一下子就可以算出来,上面我们启动的进程初始PRI为80,我们通过修改nice值的话,就只能将它的范围改为60至99,但是呢,大家都是比较反骨的人,偏偏我就不信这个邪,我就要超出这个范围修改一下,那会怎么样,那我们操作一下试试看
具体操作为:
- top
- 进入top后按‘r’ ->输入进程PID->输入ncie值
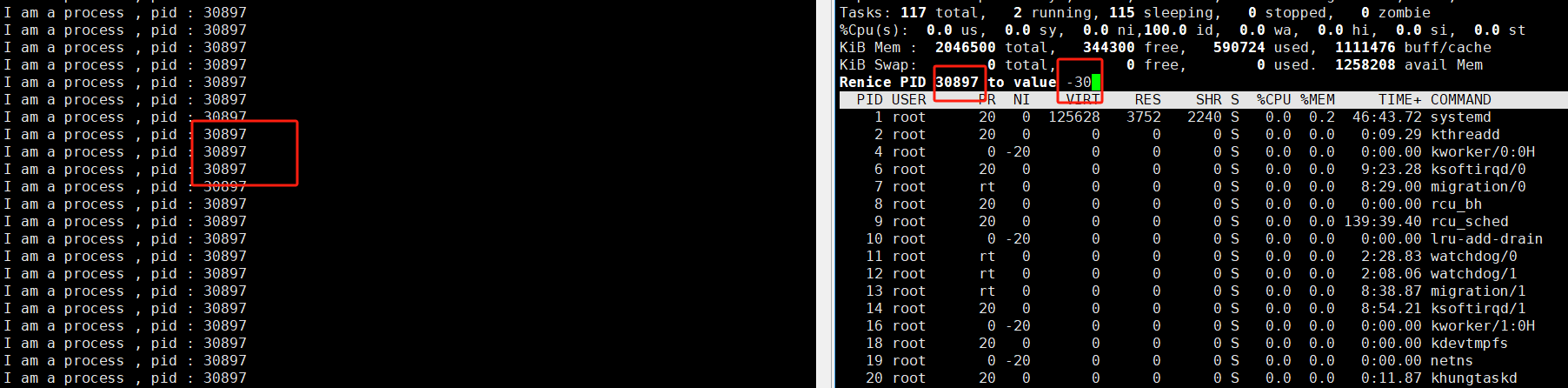

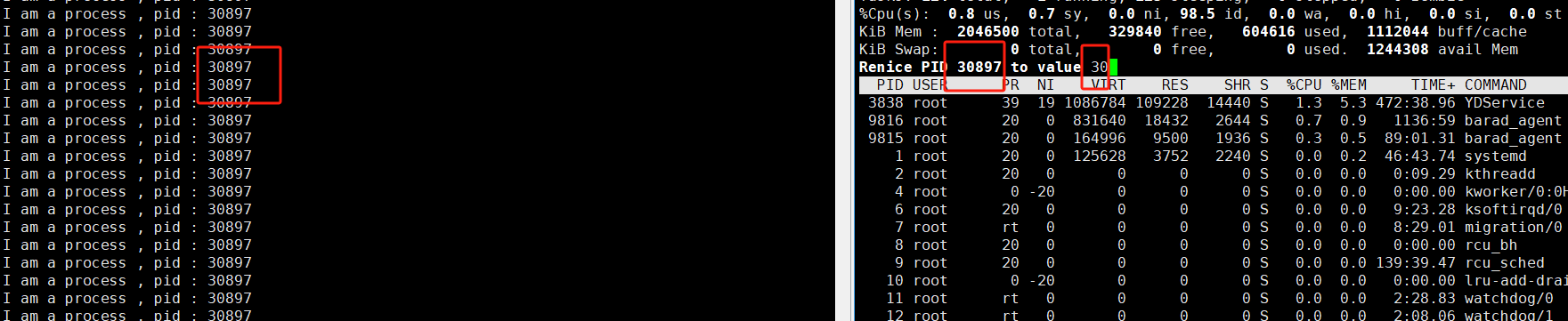

可以看到我们如果输入的值超过约定的范围的话它就会使用它默认的边界值进行设定,那么大家可以设置吗?老实讲,是可以的,毕竟linux是开源的,如果你想做这个操作,你就得去改liunx的内核代码,博主比较无能,没有这个能力,剩下的就交给大家去实现了 。
注意:可能有人发现,我第一次不是将他的优先级设置为60了么,怎么在第二次修改时,不是改为90呢?那是因为PRI(新) = PRI(旧) + nice,PRI(旧)一直都是系统默认的,我们只能通过修改nice值来对它的优先级进行修改,但是每次都是从系统默认的值开始。
那么大家又有点好奇了为什么nice值只能是-20到19这40个级别呢?
在Linux系统中,每个进程都有一个优先级(Priority),用于决定CPU调度时资源的分配顺序。优先级数值越低,进程的优先级越高。Linux优先级范围通常为0(最高)到139(最低),其中0-99属于实时优先级(Real-Time Priority),100-139属于普通优先级(Nice Value)。而我们现在讨论的就是普通优先级,所以这40个级别对应的就是100-139这40个普通优先级。
那么操作系统是如何根据优先级进行调度的呢?看下面这张图
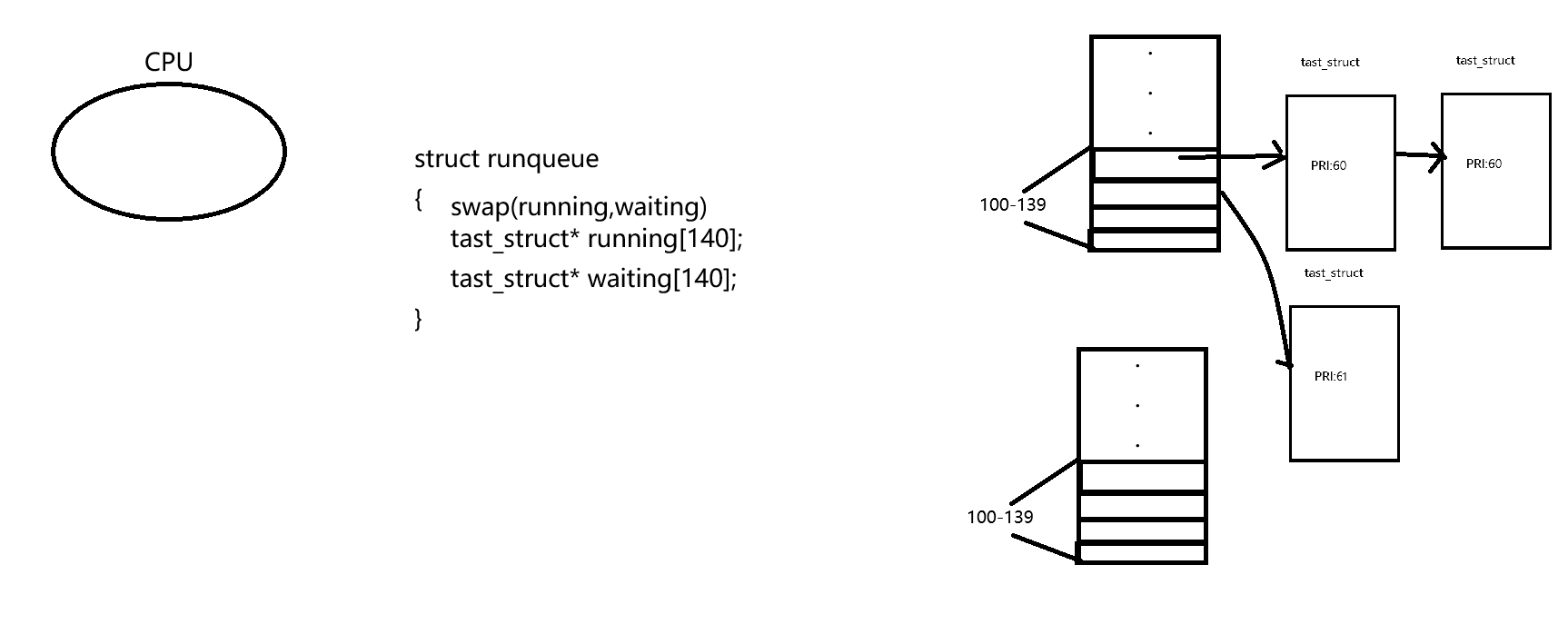
之前我们说过CPU在执行调度的时候,会有一个运行队列,在运行队列中就会有两个指针数组,这两个指针数组就是用来进行优先级调度的,每当有进程来的时候,操作系统会根据它的PRI值进行对其的划分,如果是PRI是60,就将这个进程放在running[100]的位置,而如果还有PRI是60的进程,继续将其链接在后面,有点像哈希桶一样的结构,如果PRI是61的话,就将其放在running[101]的位置,这样操作系统就可以根据这个指针数组快速确定我应该有限访问哪一个进程,至于为什么要多放一张waiting表呢,这时因为,当一个进程在执行的时候,还会有新的进程继续来,这个时候不能即访问又修改,所以需要额外的指针数组进行对其的保留,直到进程执行结束后,通过swap对两张表的内容交换,这样就可以做到实时更新了。这就是CPU如何根据优先级进行调度的。注意,这里的变量名不同的操作系统不一样,这里只是为了让大家更好的理解,至于变量名大家可以查看linux源码。
进程的上下文
首先,大家应该知道,CPU是基于时间片轮转运行的,一个进程如果在规定的时间内没有执行完,就会被切换,但是大家可能没有感觉,说我经常玩电脑的时候,无论执行哪个进程,我都没有感觉到它有切换的感觉,这是因为CPU的执行速度是非常快的,快到人的反应速度是无法跟上的,人的速度在快也是以s(秒)为单位的,而CPU是以ns级别的速度执行的,所以我们是无法感知的。而进程在CPU中执行的时候,是由CPU中的控制单元,联和在CPU中的各个寄存器,进行对进程程序的控制,这个时候,如果进程由于时间片轮转被调离CPU后,这各个寄存器中的数据需不需要保存呢?
在回答这个问题之前,我们先简单举一个例子感受一下,相信大家在大一的时候都会有大学生征兵的申请,假如现在有一个同学申请了大学生征兵并且通过了,这个同学非常的高兴,直接什么都不管就直接去了,高高兴兴的去征兵一年,征兵结束回到直接的宿舍之后发现舍友都已经不是当初的舍友了,而自己之前的床铺什么的信息随之不见了,在教务系统里查看自己发现自己已经被开除了,这是因为当年你去征兵的时候并没有和学校说明情况,你直接就去当兵去了,而学校看到你这个人莫名其妙消失了,考试上课也没有去,结果挂了20来门课,学校就直接将你的学籍开除了,这个时候你只能去参加即将举行的高考重新考试了,这对吗?当然不对了,我不能为我们的国家做贡献去了,回来家被偷了,连学籍都没有了,所以,我们在去征兵的同时要和学校进行打招呼,让学校了解清楚,我要去当兵,把我的学籍保留一下,不要我回来的时候我被开除了。
所以同理,我们在CPU进行被切换的时候,需要将CPU中各个寄存器的值进行保留,不然下次回来数据没有了,总不能回头再运行吧,把这个进程让小日子整呢,所以我们要进行保留,那么我们应该保留在哪里呢,保留在CPU吗?当然不能了,这就好比我们去图书馆了,我们学完就应该把我们的东西带走,总不能我们把我们的东西放那,下一个人来了继续在那里学习吧,过不了多久,那可怜的一点点书桌就堆叠如山了,所以进程也是如此,我们要将数据保存到进程中,这就是进程的上下文,这样下次继续在CPU执行时,只需要将相关信息填入到进程中,这样就可以继续向后执行,也就不用回头再参加高考了。
环境变量
基本概念
- 环境变量一般是指在操作系统中用来指定操作系统运行环境的一些参数。
- 我们在编写一些C/C++代码的时候,在链接的时候,从来不知道我们所链接的动态静态库在哪里,但是我们照样链接成功了,生成可执行程序了,原因就是有相关的环境变量帮助编译器进行查找。
- 环境变量在系统中通常具有全局属性。
#include<iostream>
int main()
{
printf("hello world\n");
return 0;
}就这么一段简单的代码,接下来我们将其生成可执行文件并执行。
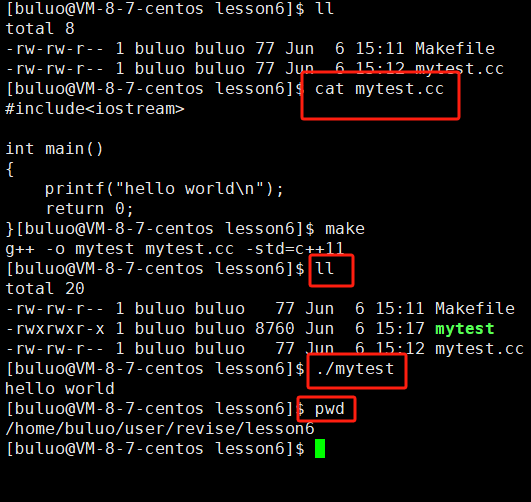
不知道大家有没有发现,为什么我们在执行自己写的可执行程序时是需要通过(./+我们写的可执行文件 )才能运行,而系统中的ls,pwd,cat等命令是不需要通过./就可以直接执行的,这是为什么呢?凭什么系统中的就不用,我们自己写的就需要./呢,大家都是可执行文件,谁又比谁高贵呢,我怎么就得增加一个./,而系统的就不需要呢?
这就是因为有环境变量的原因,在window下也有相关的环境变量
而在linux中也是有这样的环境变量的
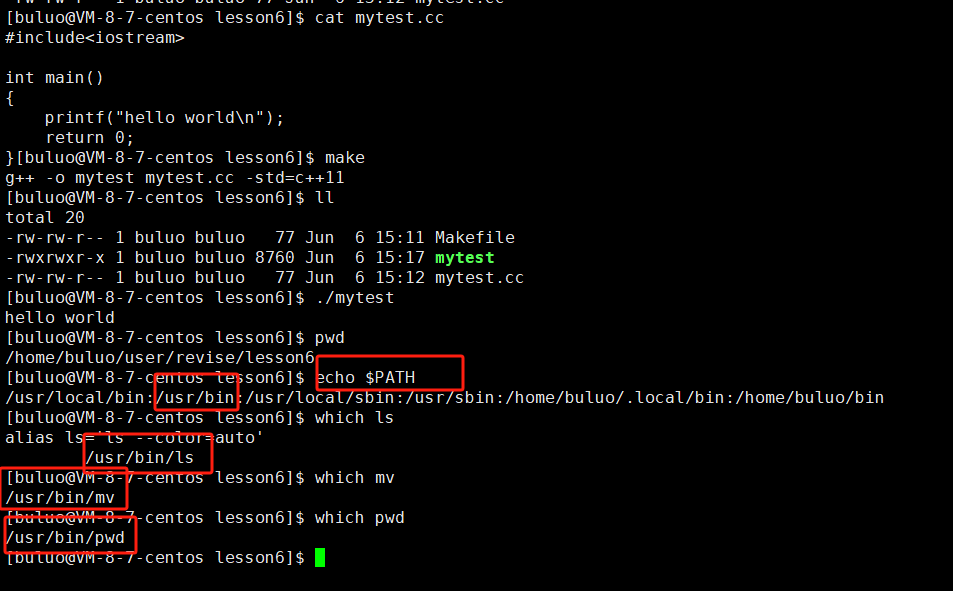
可以明显看到系统中的可执行文件都是在/usr/bin路径下的,而在linux的环境变量中刚刚好有 /usr/bin这个路径,所以在执行系统中的可执行文件时,操作系统会首先通过环境变量相关的路径一个一个的找,找到就执行,没有找到就无法执行。那么我们如何做到可以和系统中的可执行文件一样,不用加./就可以执行呢,办法就是,就我们的当前路径也添加到环境变量就可以了,接下来我们就操作一下。指令就是:PATH=$PATH:你可执行文件的路径名
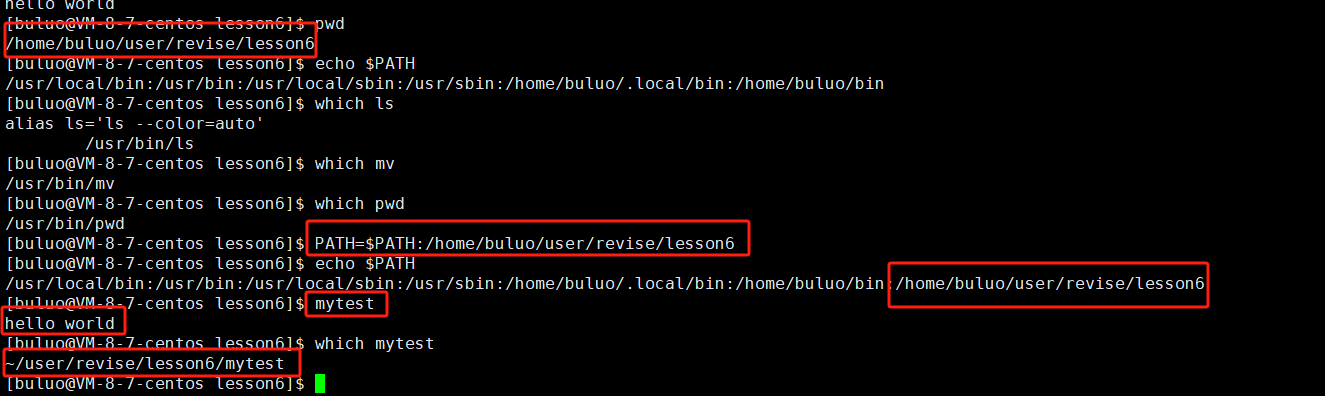
这样就可以明显的观察到,我们写的可执行文件就可以和系统中的文件一样,不需要通过./,也就可以执行了,让我们写的可执行文件和系统的可执行文件可以平起平坐了。
常见的环境变量
- PATH:指定命令的搜索路径。
- HOME:当前用户的主工作目录。
- SHELL :当前的SHELL,它的值通常是/bin/bash。
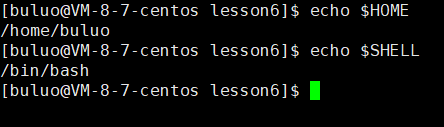
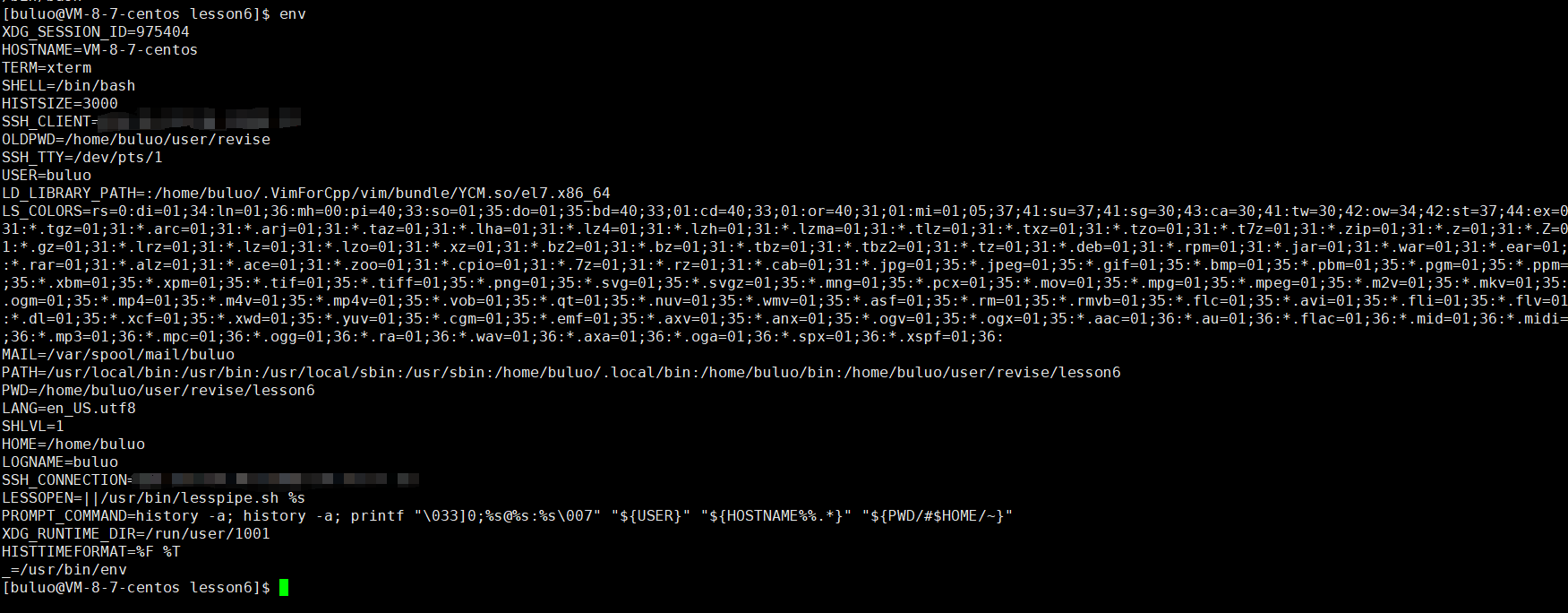
除了这些,linux中还有很多的环境变量,我们可以通过env指令(environment)进行查看
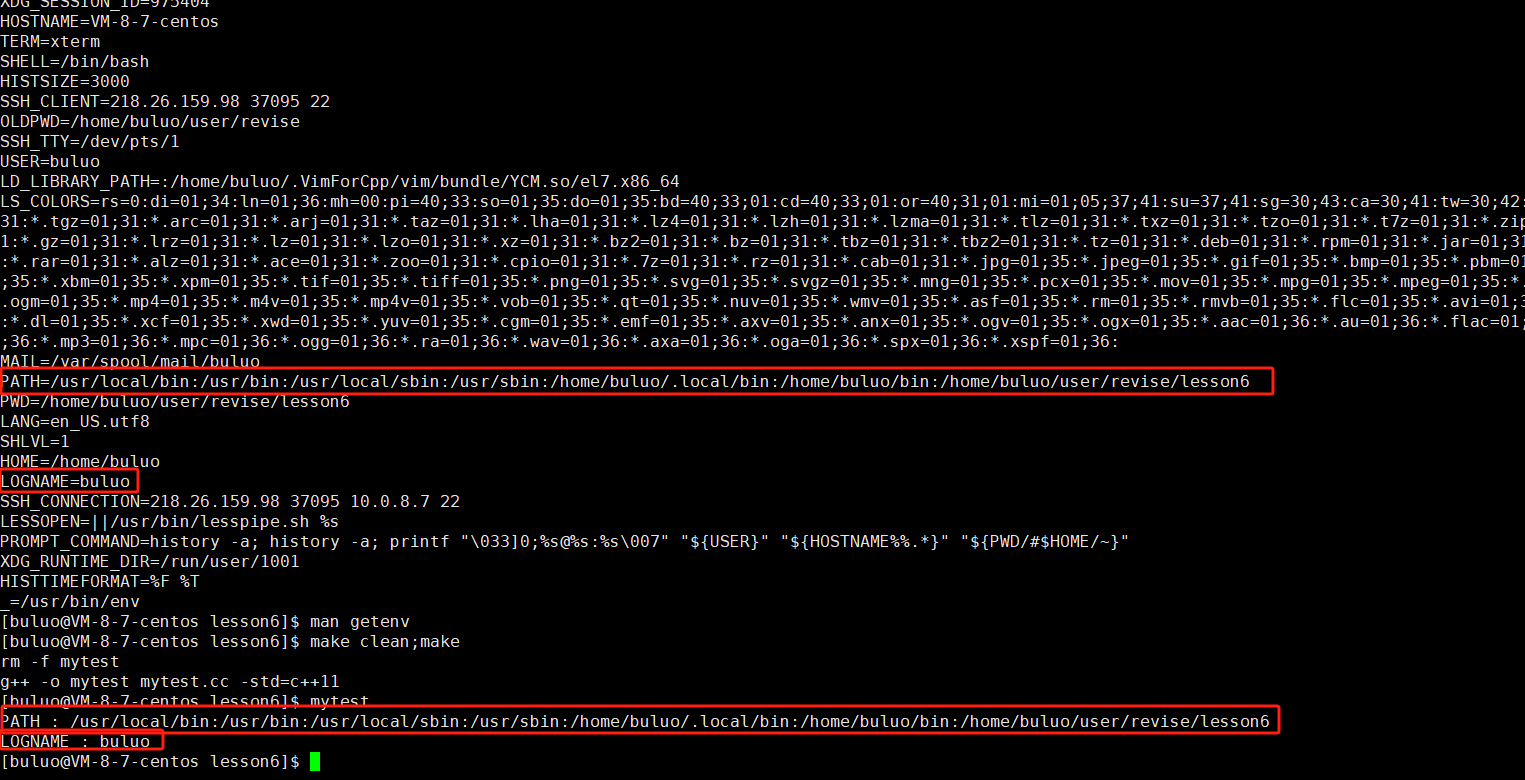
而在我们的程序中如果想要获得相应的环境变量,我们可以调用系统接口getenv进行获取。
#include <iostream>
#include <stdlib.h>
int main()
{
std::cout << "PATH : " << getenv("PATH") << std::endl;
std::cout << "LOGNAME : " << getenv("LOGNAME") << std::endl;
// printf("hello world\n");
return 0;
}
命令行参数
大家可以想一想,在写了这么多的C语言程序,我们的main函数可以带参数吗,如果可以带参的话能带几个呢?
大家一般在windows中写的话,一般是不要带命令行参数的,因为大家在windows中一般都是用的集成开发工具,写完代码直接运行就结束了,但是实际上main函数也是函数,他是可以带参数的,现在我们就来看看main函数中的参数是什么?又有什么作用呢?
#include <iostream>
#include <stdlib.h>
int main(int argc, char *argv[])
{
for (int i = 0; i < argc; i++)
{
printf("argv[%d] : %s\n", i, argv[i]);
}
// std::cout << "PATH : " << getenv("PATH") << std::endl;
// std::cout << "LOGNAME : " << getenv("LOGNAME") << std::endl;
// printf("hello world\n");
return 0;
}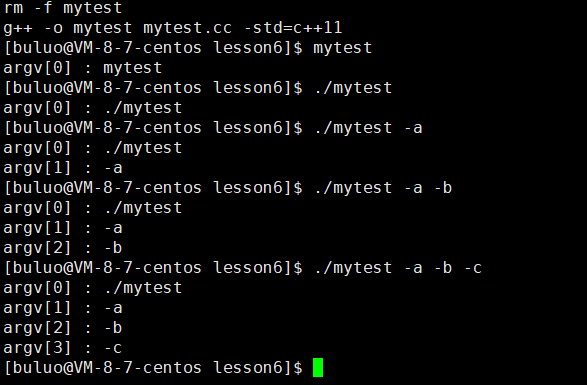
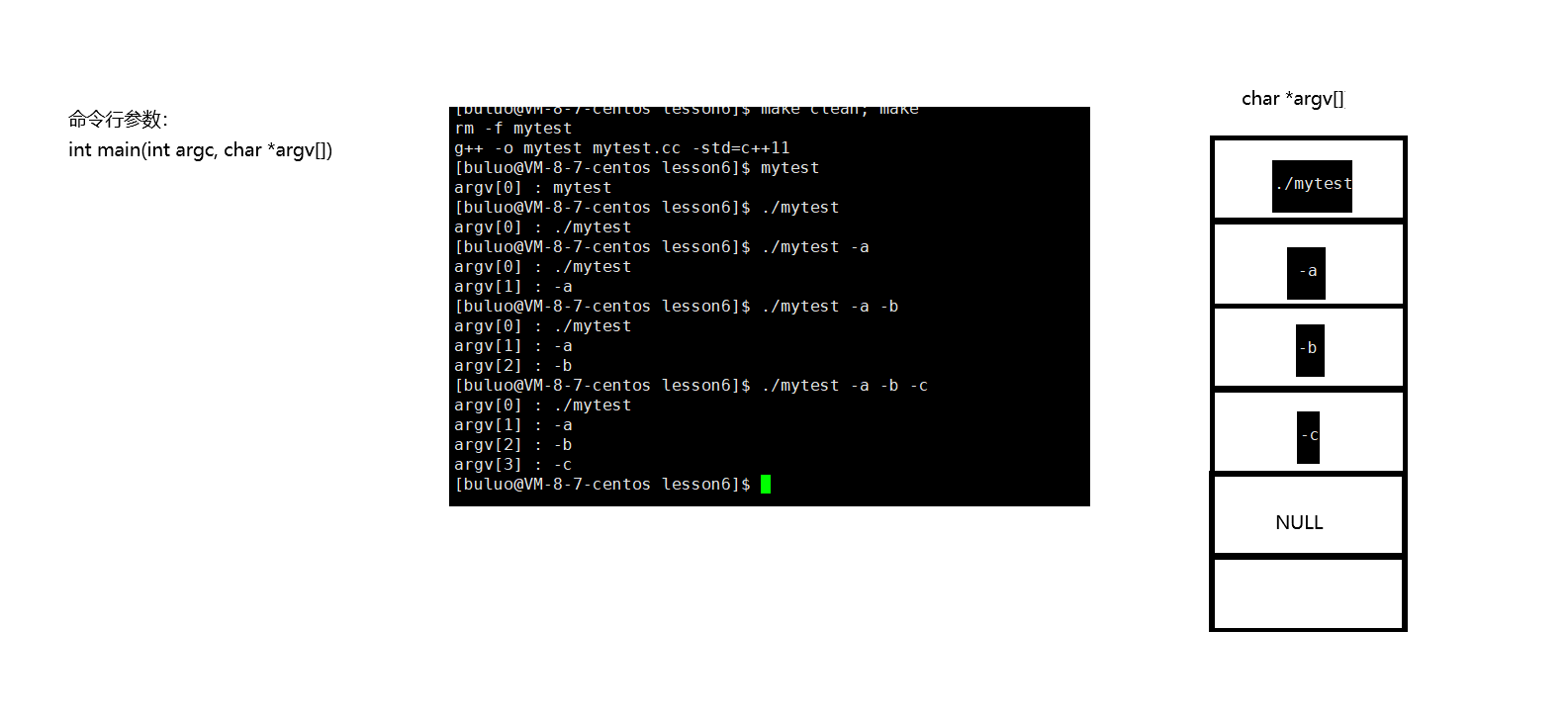
我们可以看到所谓的命令行参数就是将我们在命令行输入的指令按照字符串分别拆解成单独的字符串,而argc记录拆解后字符串的个数,argv中保留相关的信息,那么这些命令行参数又有什么用呢?
我们再执行一段代码
#include <iostream>
#include <stdlib.h>
#include <string.h>
int main(int argc, char *argv[])
{
if (argc != 2)
{
printf("请重新输入!\n");
exit(0);
}
if (strcmp(argv[1], "-a") == 0)
{
std::cout << "功能1" << std::endl;
}
else if (strcmp(argv[1], "-b") == 0)
{
std::cout << "功能2" << std::endl;
}
else if (strcmp(argv[1], "-c") == 0)
{
std::cout << "功能3" << std::endl;
}
// for (int i = 0; i < argc; i++)
// {
// printf("argv[%d] : %s\n", i, argv[i]);
// }
// std::cout << "PATH : " << getenv("PATH") << std::endl;
// std::cout << "LOGNAME : " << getenv("LOGNAME") << std::endl;
// printf("hello world\n");
return 0;
}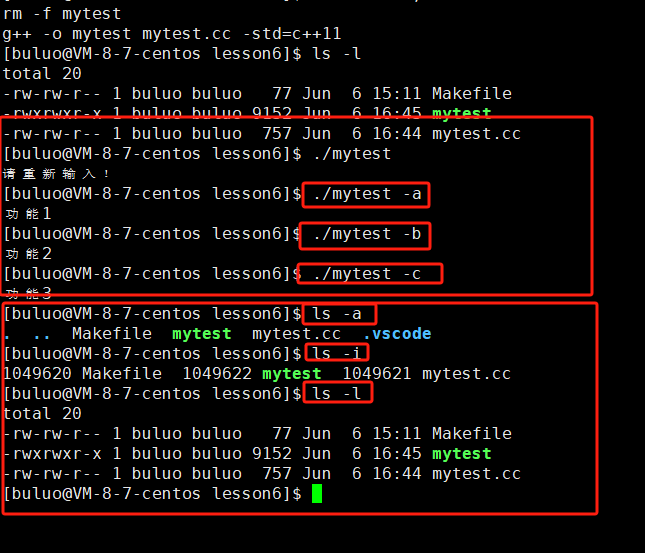
这下大家应该就明白了,通过这样的方式我们就可以像系统指令一样,利用不同的参数选项,实现不一样的功能。这样为指令,工具,软件等提供命令行选项的支持。
那么这个命令行参数和环境变量有什么关系,我还是没理解这个命令行参数和环境变量有什么关系。别着急,接着往下看,难道我们的main函数只能有上面那两个参数吗?答案:当然不是了,main函数还有一个参数就是用来给我们提供环境变量的,现在我们就来看一看main函数的第三个参数。
#include <iostream>
#include <stdlib.h>
#include <string.h>
int main(int argc, char *argv[], char *env[])
{
for (int i = 0; env[i]; i++)
{
printf("env[%d] : %s\n", i, env[i]);
}
return 0;
}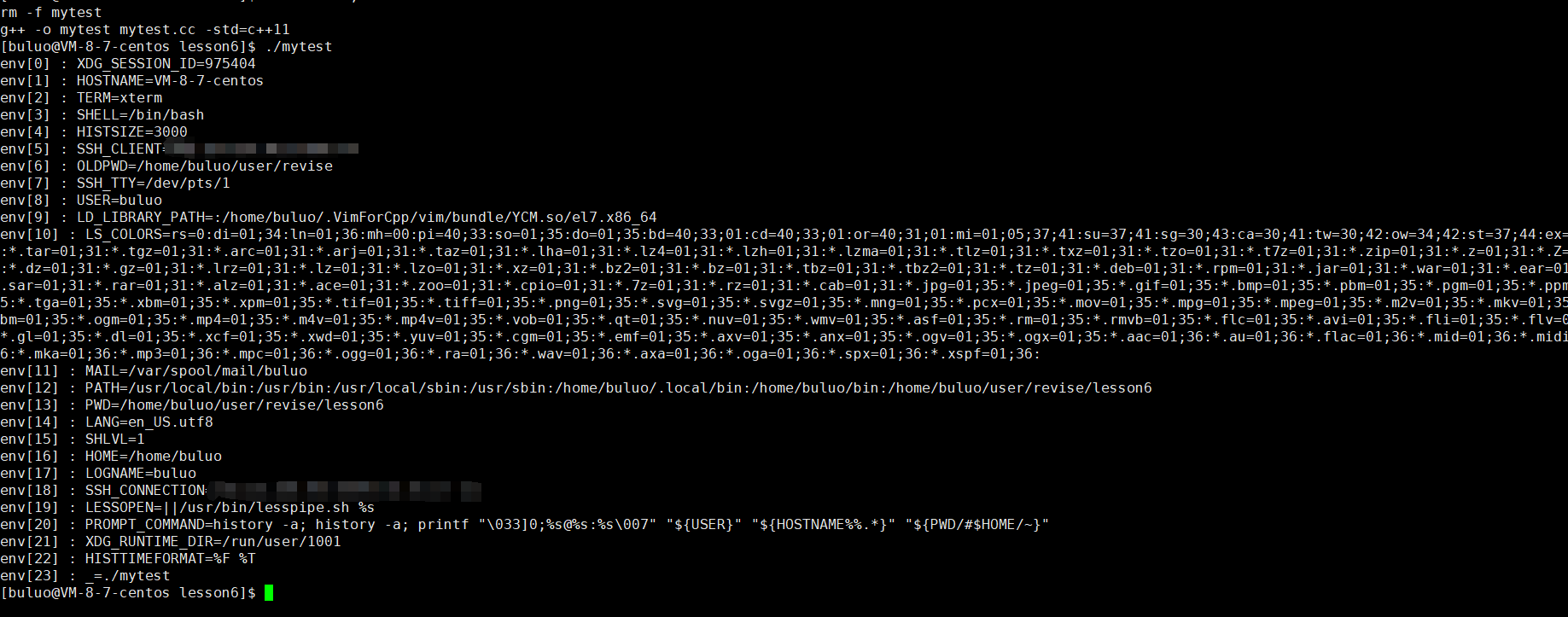
我们所运行的进程,都是子进程,bash(Bash是一种Linux系统中的命令行解释器)在启动的时候,会从操作系统的配置文件中读取环境变量信息,创建子进程会继承父进程的环境变量!!所以环境变量具有全局性。
好奇的大家可能就会说,继承就是全局了,我怎么感觉不出来呢?你得让我看到才算,我比较喜欢眼见为实的东西,好,现在我们在执行一段代码感受一下。
#include <iostream>
#include <stdlib.h>
#include <string.h>
int main(int argc, char *argv[], char *env[])
{
std::cout << "MY_VALUE : " << getenv("MY_VALUE") << std::endl;
return 0;
}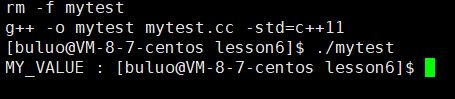
可以看到在执行完这段代码后,并没有输出环境变量中的MY_VALUE的信息,那是因为这时环境变量中并没有关于MY_VALUE这个字段的内容,现在我们通过命令行往环境变量中增加MY_VALUE这个字段。指令:export MY_VALUE=123

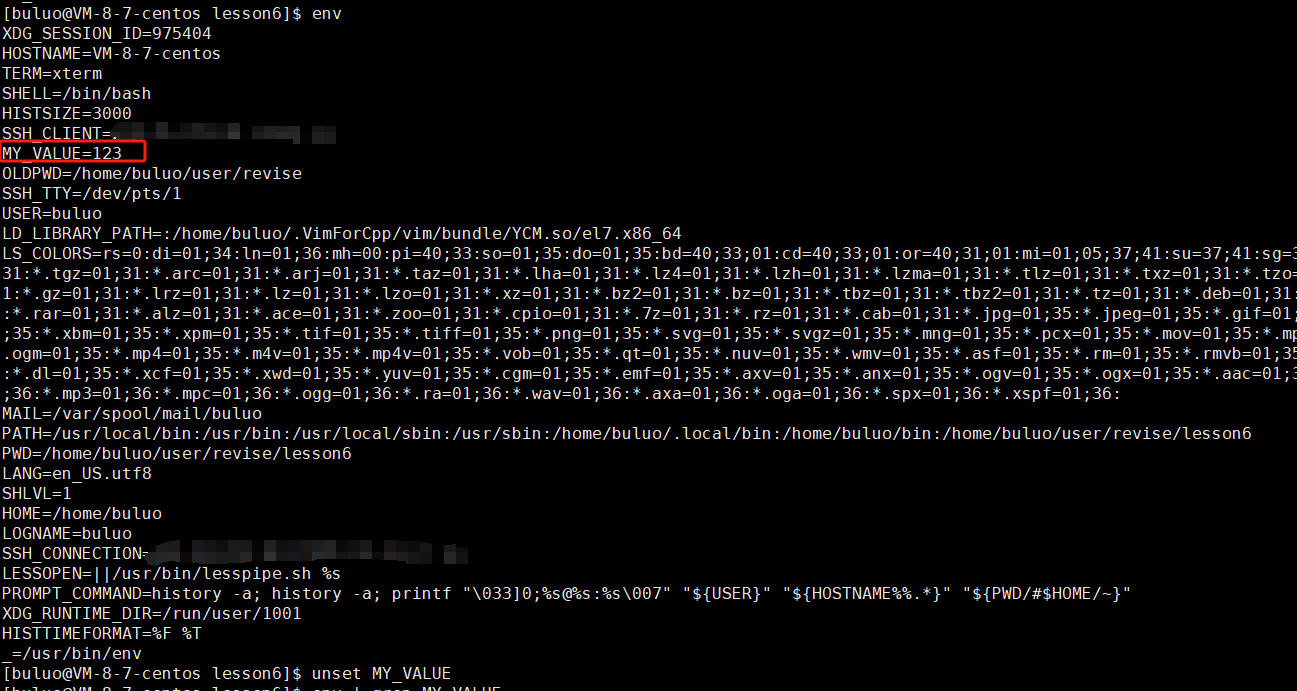
可以看到在我们导入相关数据之后,我们的子进程也根据全局的环境变量的改变,子进程也收到了相关数据,再继续执行时,就可以正确执行了,所以环境变量具有全局性。
另外,获取环境变量还可以通过第三方变量获取。
#include <iostream>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int main()
{
extern char **environ;
for (int i = 0; environ[i]; i++)
{
printf("environ[%d] : %s\n", i, environ[i]);
}
return 0;
}
可以看到也获得了相关的环境变量。
程序地址空间
程序地址空间(Program Address Space)是指操作系统为每个运行的程序(进程)分配的虚拟内存区域,用于存储程序的代码、数据和运行时所需的资源。它是一个抽象的、连续的虚拟内存视图,由操作系统和硬件共同管理。

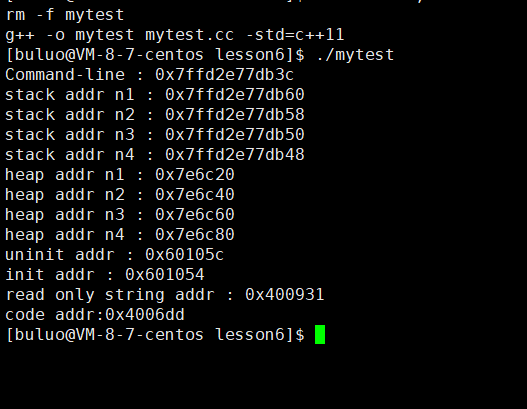
现在我们通过代码实际感受一下进程的空间分布。
#include <iostream>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int uninit_val;
int init_val = 100;
int main(int argc, char *argv[])
{
const char *str = "hello world";
int *n1 = (int *)malloc(4);
int *n2 = (int *)malloc(4);
int *n3 = (int *)malloc(4);
int *n4 = (int *)malloc(4);
printf("Command-line : %p\n", &argc);
printf("stack addr n1 : %p\n", &n1);
printf("stack addr n2 : %p\n", &n2);
printf("stack addr n3 : %p\n", &n3);
printf("stack addr n4 : %p\n", &n4);
printf("heap addr n1 : %p\n", n1);
printf("heap addr n2 : %p\n", n2);
printf("heap addr n3 : %p\n", n3);
printf("heap addr n4 : %p\n", n4);
printf("uninit addr : %p\n", &uninit_val);
printf("init addr : %p\n", &init_val);
printf("read only string addr : %p\n", str);
printf("code addr:%p\n", main);
return 0;
} 
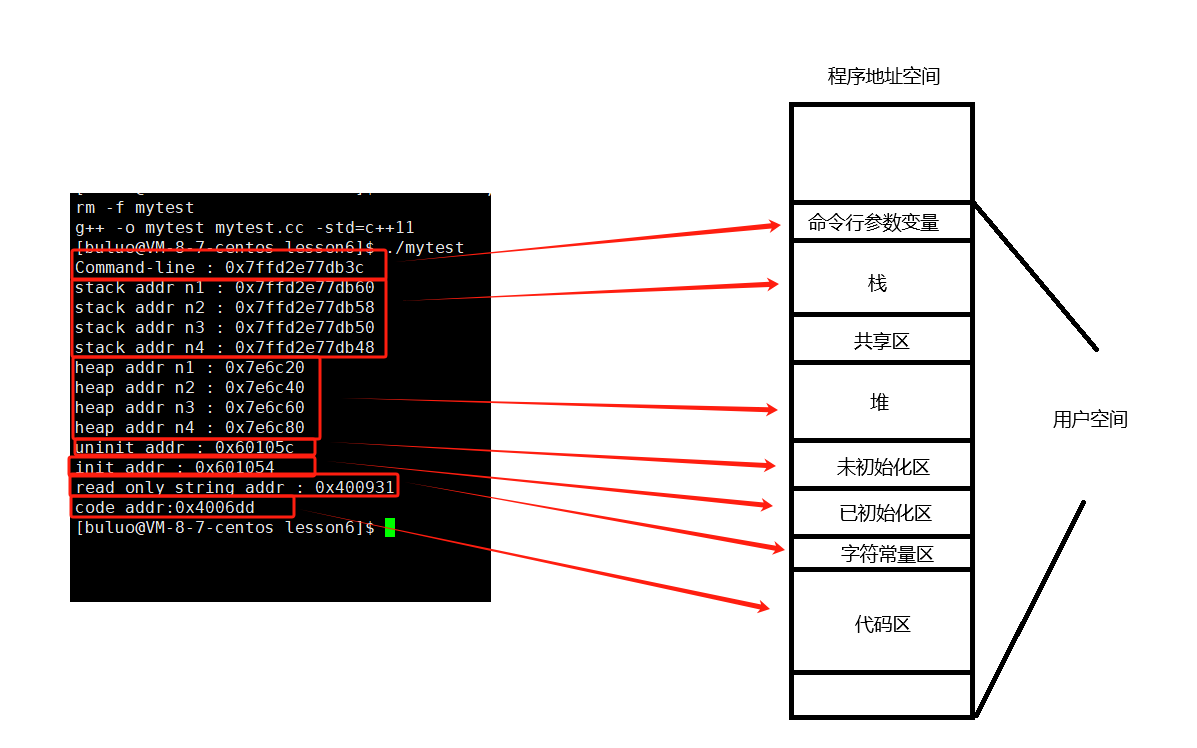
通过这样的代码,相信大家对程序地址空间有了一点认识了,关于深层次的理解,我们下一篇博客继续!!!!