一、理论深度提升:补充算法细节与数学基础
1. K-Means 算法核心公式(增强专业性)
在 “原理步骤” 中加入数学表达式,说明聚类目标:
K-Means 的目标是最小化簇内平方和(Within-Cluster Sum of Squares, WCSS):J=∑i=1K∑x∈Ci∥x−μi∥2
其中,Ci 是第 i 个簇,μi 是簇中心。算法通过迭代更新簇中心 μi 和分配样本到最近中心,逐步优化 J。
2. 颜色空间选择(扩展知识边界)
新增小节说明 RGB 颜色空间的局限性,推荐更适合聚类的颜色空间(如 Lab):
- RGB:各通道高度相关,欧氏距离不能准确反映视觉差异。
- Lab:基于人眼感知,通道独立,聚类效果更符合视觉预期(可补充代码示例,需安装
colorama库)。
二、K-Means 颜色聚类(K-Means Color Clustering)
1.概念与作用
K-Means 颜色聚类是借助 K-Means 聚类算法 对图像(或颜色集合)中的颜色进行分组,目的是提取出最具代表性的若干种颜色(聚类中心),实现颜色简化或风格化。比如:
1)简化图像色彩:把照片的上百种颜色压缩为 5 - 10 种主色,生成类似插画、低多边形艺术的效果。
2)色彩分析:快速找出图像里占比高的颜色,用于设计配色参考、图像分类(如区分风景照的 “暖色调”“冷色调” )。
2.原理步骤
1)数据准备:把图像的每个像素(RGB 形式,如 (r, g, b) )视为高维空间(3 维,对应 RGB 通道)中的点。
2)聚类分组:用 K-Means 算法将这些点聚成 K 类(K 是你设定的聚类数,比如 5 类就提取 5 种主色 )。算法随机选 K 个初始中心,不断迭代调整,让同类点尽可能靠近自己的中心,不同类中心尽可能远离。
3)颜色替换:用每个聚类的中心颜色,替换该类所有像素的颜色。最终图像就只剩 K 种主色,实现色彩简化。
代码:(使用的时候记得修改图片路径)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from matplotlib.image import imread
def set_chinese_font():
"""设置 Matplotlib 支持中文显示的字体"""
import matplotlib.font_manager as fm
chinese_fonts = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC", "Microsoft YaHei"]
available_fonts = [f.name for f in fm.fontManager.ttflist]
for font in chinese_fonts:
if font in available_fonts:
plt.rcParams["font.family"] = font
print(f"已设置中文字体: {font}")
return True
print("警告: 未找到可用的中文字体,图表中的中文可能显示为方块")
return False
# 设置中文字体
set_chinese_font()
image_path = r"D:\keshihua\biancheng\PythonProject1\haimianbaobao.jpg"
try:
image = imread(image_path)
if image.shape[-1] == 4:
image = image[..., :3]
print(f"图像加载成功,尺寸: {image.shape}")
except FileNotFoundError:
print("错误:图片路径不存在,请检查路径!")
exit(1)
except Exception as e:
print(f"加载图片失败: {e}")
exit(1)
n_clusters = 5
pixels = image.reshape(-1, 3)
kmeans = KMeans(n_clusters=n_clusters, random_state=42, n_init='auto')
kmeans.fit(pixels)
if image.dtype == np.uint8:
main_colors = kmeans.cluster_centers_.astype(np.uint8)
else:
main_colors = kmeans.cluster_centers_
main_colors = main_colors.reshape(-1, 3)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title("原始图像")
plt.axis('off')
plt.subplot(1, 2, 2)
color_width = 1 / n_clusters
for i in range(n_clusters):
plt.fill_between(
x=[i * color_width, (i + 1) * color_width],
y1=0, y2=1,
color=main_colors[i] / 255.0 if image.dtype == np.uint8 else main_colors[i],
edgecolor='white'
)
plt.axis('off')
plt.title(f"提取的 {n_clusters} 种主色")
plt.tight_layout()
plt.show()
print("提取的主色 (RGB 数值):")
for i, color in enumerate(main_colors):
if image.dtype == np.uint8:
print(f"主色 {i+1}: {color}")
else:
print(f"主色 {i+1}: {color.round(3)}")运行结果:

三、渐变色(Gradient Color)
1.概念与作用
渐变色是指 两种或多种颜色之间平滑过渡的色彩效果 ,能营造柔和、连贯的视觉感受。结合 K-Means 颜色聚类,常用来:
1)可视化聚类结果:用聚类得到的主色,生成从一种主色平滑过渡到另一种主色的色带,直观展示 “提取了哪些主色” 。
2)设计配色方案:基于图像主色,快速生成协调的渐变色,用于 UI 设计、海报背景等。
2.实现方式:
1)提取主色:先用 K-Means 聚类得到 K 个主色(聚类中心)。
2)创建渐变映射:用 LinearSegmentedColormap(Matplotlib 工具),把主色按顺序排列,让颜色在色带中平滑过渡。
3)生成渐变图像:用创建好的颜色映射,生成从左到右(或其他方向)的渐变色带。
代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from matplotlib.image import imread
from matplotlib.colors import LinearSegmentedColormap
# 设置中文字体
def set_chinese_font():
import matplotlib.font_manager as fm
chinese_fonts = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC", "Microsoft YaHei"]
available_fonts = [f.name for f in fm.fontManager.ttflist]
for font in chinese_fonts:
if font in available_fonts:
plt.rcParams["font.family"] = font
print(f"已设置中文字体: {font}")
return True
print("警告: 未找到可用的中文字体,图表中的中文可能显示为方块")
return False
set_chinese_font()
image_path = r"D:\keshihua\biancheng\PythonProject1\haimianbaobao.jpg"
try:
image = imread(image_path)
if image.shape[-1] == 4:
image = image[..., :3]
print(f"图像加载成功,尺寸: {image.shape}")
except Exception as e:
print(f"加载图片失败: {e}")
exit(1)
n_clusters = 5 # 可调整聚类数量
pixels = image.reshape(-1, 3)
kmeans = KMeans(n_clusters=n_clusters, random_state=42, n_init='auto')
kmeans.fit(pixels)
if image.dtype == np.uint8:
main_colors = kmeans.cluster_centers_.astype(np.uint8)
else:
main_colors = kmeans.cluster_centers_
main_colors = main_colors.reshape(-1, 3)
# 归一化颜色到 [0,1] 范围
main_colors_normalized = main_colors / 255.0 if image.dtype == np.uint8 else main_colors
# 创建渐变色映射(按聚类中心顺序过渡)
cmap = LinearSegmentedColormap.from_list('custom_gradient', main_colors_normalized, N=200)
# 生成水平渐变色条
gradient = np.linspace(0, 1, 500).reshape(1, -1) # 500 个渐变点
gradient_image = cmap(gradient)[0, :, :3] # 提取 RGB 值
plt.figure(figsize=(14, 8))
# 子图 1:原始图像
plt.subplot(2, 2, 1)
plt.imshow(image)
plt.title("原始图像")
plt.axis('off')
# 子图 2:主色提取(色块形式)
plt.subplot(2, 2, 2)
color_width = 1 / n_clusters
for i in range(n_clusters):
plt.fill_between(
x=[i * color_width, (i + 1) * color_width],
y1=0, y2=1,
color=main_colors_normalized[i],
edgecolor='white',
linewidth=1
)
# 添加颜色标签
plt.text(
(i * color_width + (i + 1) * color_width) / 2,
0.5,
f"#{i+1}",
ha='center',
va='center',
color='white' if np.mean(main_colors_normalized[i]) < 0.5 else 'black',
fontweight='bold'
)
plt.axis('off')
plt.title(f"提取的 {n_clusters} 种主色")
# 子图 3:渐变色条(水平)
plt.subplot(2, 1, 2)
plt.imshow(gradient_image.reshape(1, -1, 3), aspect='auto')
plt.title("主色之间的平缓过渡")
plt.axis('off')
# 添加主色标记点(修复颜色格式问题)
for i in range(n_clusters):
pos = i / (n_clusters - 1) if n_clusters > 1 else 0.5 # 计算位置
plt.plot([pos * 499], [0], 'wo', markersize=8, markeredgecolor='black') # 白色圆点
# 修复:使用 tuple 格式传递颜色,而不是字符串
plt.plot([pos * 499], [0], 'o', color=tuple(main_colors_normalized[i]), markersize=5)
plt.tight_layout()
plt.show()
print("提取的主色 (RGB 数值):")
for i, color in enumerate(main_colors):
rgb_str = f"RGB({color[0]:3d}, {color[1]:3d}, {color[2]:3d})"
hex_str = '#{:02x}{:02x}{:02x}'.format(*color) if image.dtype == np.uint8 else ''
print(f"主色 #{i+1}: {rgb_str} {hex_str if hex_str else ''}")
原图:

四、常见问题与优化策略(提升实用性)
1. 如何选择最优 K 值?
新增小节介绍肘部法则(Elbow Method),通过 WCSS 曲线确定最佳聚类数:
# 计算不同K值的WCSS
wcss = []
for k in range(2, 10):
kmeans = KMeans(k, random_state=42).fit(pixels)
wcss.append(kmeans.inertia_)
# 绘制肘部曲线
plt.plot(range(2, 10), wcss, 'bo-')
plt.xlabel("聚类数 K")
plt.ylabel("WCSS")
plt.title("肘部法则确定最优K值")2. 聚类结果不稳定怎么办?
建议:
- 增加
n_init参数(如n_init=10),重复初始化多次取最优。 - 使用层次聚类(Hierarchical Clustering)作为预聚类,提供更稳定的初始中心。
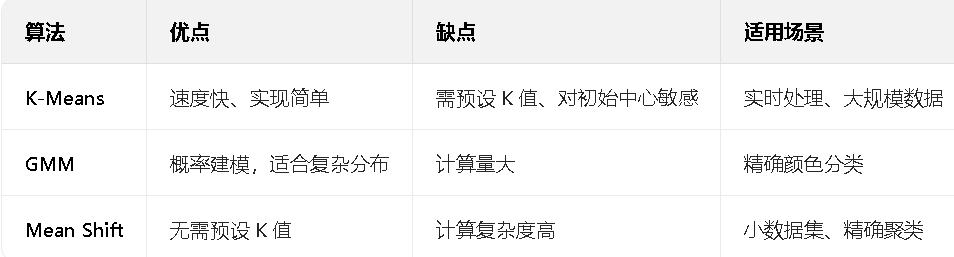
3. 对比其他颜色聚类算法
新增表格对比 K-Means 与其他算法的优缺点: