这篇论文主要研究的是滑坡位移的区间预测方法,提出了一种新型的预测模型,叫做复合区间预测模型(CIPM),并以三峡库区的白家堡滑坡为案例进行了应用和验证。论文的核心内容和贡献包括:
背景与问题
- 滑坡位移预测是滑坡灾害预警的重要环节。
- 传统预测多为点预测,无法有效反映预测结果的不确定性。
- 区间预测能量化预测误差和不确定性,更实用和安全。
方法创新
- 利用**变分模态分解(VMD)**对滑坡位移信号分解为多个内禀模态函数(IMF),分别建模。
- 采用**鲸鱼优化算法(WOA)优化的核极限学习机(KELM)**进行非线性建模,提高点预测精度。
- 利用Copula函数确定位移各分量与影响因子的关系,增强模型解释能力。
- 结合概率模型(PM)和非参数概率模型(NPM)对预测误差进行概率密度函数估计,通过差分进化算法(DE)优化参数,构建预测区间。
- 将不同IMF分量预测区间叠加得到总位移的置信区间。
实验与验证
- 在白家堡滑坡实际数据上应用CIPM,显示该方法在预测区间覆盖率和宽度等指标上优于传统的概率模型和非参数概率模型。
- 将该模型应用于其他滑坡案例(熟坪滑坡、白水河滑坡),与已有方法比较,结果显示CIPM具有更优的准确性和可靠性。
优点与不足
- CIPM综合了多种先进算法,既保证了预测的准确性,又能量化预测的不确定性,增强滑坡预警系统的实用性。
- 受限于GPS监测数据规模较小,误差拟合存在一定局限,但可以通过引入邻近监测点数据和多源数据融合来改善。
- 该方法针对典型堆积滑坡验证有效,未来还需在其他滑坡类型中检验其适用性。
总结
- 本文提出的CIPM为滑坡位移预测提供了一种新思路,克服了点预测的局限,能够同时兼顾预测的准确度和置信区间的可靠性。
- 该方法对滑坡灾害评估和风险防控具有重要参考价值。
简而言之,这篇论文是在解决滑坡位移预测中“如何给出可靠且精确的预测区间”这一难题,提出了一套结合信号分解、机器学习优化和概率建模的综合方案,并通过实际数据验证了其优越性。
文章目录
《Journal of Earth Science》是一本由中国地质大学主办的双月刊(bimonthly),原名为《Journal of China University of Geosciences》,自1990年创刊以来,逐渐发展为国际化地球科学领域的重要学术期刊
题目:基于Copula和VMD-WOA-KELM方法的滑坡位移数据驱动组合区间预测方法
作者:李龙奇*,杨云煌,周天志,王梦芸
单位:成都理工大学地质灾害防治与地质环境保护国家重点实验室,成都 610059,中国
李龙奇 ORCID:http://orcid.org/0000-0003-0784-3791
[1] Li L, Yang Y, Zhou T, et al. Data-driven combination-interval prediction for landslide displacement based on copula and VMD-WOA-KELM method[J]. Journal of Earth Science, 2025, 36(1): 291-306.
全文翻译
摘要:
为了解决点预测在量化滑坡位移预测可靠性方面存在的困难,本文提出了一种基于Copula和变分模态分解(VMD)相结合的核极限学习机(KELM)并融合鲸鱼优化算法(WOA)的数据驱动组合区间预测方法(CIPM)。
首先,采用VMD方法将位移数据分解为三个具有不同波动特征的本征模态函数(IMF)分量以及一个残差分量。然后,基于Copula模型选择各个IMF分量的关键影响因子,并建立相应的WOA-KELM模型以进行点预测。
接着,分别利用参数法(PM)和非参数法(NPM)估计每个分量的预测误差概率密度函数(PDF),从而获得95%置信水平下的预测区间(PI)。在此基础上,通过差分进化算法(DE)构建基于PI加权组合的组合模型,用于构造组合区间(CI)。最终,将各个分量的CI进行叠加,得到总体的PI。
对比案例研究表明,该CIPM方法在构建滑坡位移的高性能预测区间方面表现优异。
关键词:滑坡位移;区间预测;组合方法;Copula;滑坡;VMD-WOA-KELM
0 引言
滑坡是一种常见的自然灾害,对人类生命和财产构成了巨大威胁(Liu 等, 2016;Li 等, 2010)。近年来,中国三峡库区频繁发生滑坡,主要由强降雨和水库水位剧烈变化所引发(Ma 等, 2017;Zhou 等, 2016;Yin 等, 2010)。为此,大量研究围绕滑坡预测与治理展开(Huang 等, 2017;Intrieri 等, 2013;Li 等, 2012)。其中,合理预测滑坡位移对灾害的预警具有重要意义。
滑坡演化是一个复杂的非线性动态过程,其变形通常受多种因素影响,如地质条件、外部环境变化以及人为活动等。一些学者(Herrera 等, 2009;Corominas 等, 2005)尝试建立物理模型,通过建立滑坡变形与岩土材料物理参数之间的关系来进行预测。尽管这类模型物理意义明确,但其所需参数往往难以获取,并且在大型复杂滑坡体转化过程中这些参数会持续变化,因此限制了物理模型的应用。
近年来,从最初的确定性模型到位移-时间统计分析模型,再到非线性机器学习模型,研究者逐步提出了所谓的数据驱动模型(Zhou 等, 2016;Lian 等, 2014;Yin 和 Yan, 1996;Saito, 1965)。这些模型多基于位移监测数据及其相关影响因子建立。与物理模型相比,数据驱动模型所需的数据更易获取。然而,传统统计分析、非线性回归或多项式拟合等方法已被证实难以有效进行滑坡变形预测。
近年来,不少学者尝试将信号分解技术(如经验模态分解 EMD、集合经验模态分解 EEMD、自适应噪声的完全集合经验模态分解 CEEMDAN)(Li LQ 等, 2021;Deng 等, 2017;Lin 等, 2011)与机器学习方法(如支持向量机 SVM、极限学习机 ELM、人工神经网络 ANN)(Cao 等, 2016;Du 等, 2013;Liu 等, 2016;Wu 等, 2016;Zhou 等, 2016;Lian 等, 2014)相结合来解决上述问题。该类方法将滑坡位移分解为一系列具有不同特征的分量,利用机器学习模型分别预测这些分量,再将各预测值叠加得到总体预测值。相比传统统计预测方法,这种方式具有更高的预测精度和更强的泛化能力。
然而,上述研究多聚焦于确定性的点预测,缺乏对预测过程中的不确定性评估与预测结果可靠性量化的考虑。对于复杂动态滑坡系统,在位移预测过程中存在诸如地质条件、监测技术和预测模型等多方面的不确定性(Phoon 和 Kulhawy, 1999a, b),这些可通过构建预测区间(PI)来量化(Wan 等, 2014)。近年来,区间预测已广泛应用于多个领域(Lins 等, 2015;Shrivastava 和 Panigrahi, 2013;Khosravi 等, 2010;Shrestha 和 Solomatine, 2006),但在滑坡位移预测方面相关研究仍较少。
例如,Wang 等(2019)采用输出层为两个节点的PSO-ELM模型,直接预测区间上下限。Ma 等(2018)结合自助法(Bootstrap)与机器学习计算由系统误差与随机误差引起的不确定性区间。然而,前者稳定性较低、计算成本较高;而后者对参数选择要求较高,一旦陷入局部最优,预测精度会大幅下降。
为此,本文提出一种基于Copula与VMD-WOA-KELM模型的组合区间预测方法。首先,通过VMD将实际监测位移分解为若干分量,并分别基于Copula模型确定其关键影响因子;然后利用这些因子建立WOA-KELM模型,对各分量进行动态点预测,并同步计算其预测误差。
接下来,通过比较各分量误差概率密度函数(PDF)在高斯分布与高斯-t混合分布下的拟合效果,选择最佳的先验分布形式构建参数法PI;同时,采用最优窗口宽核密度估计方法获取误差PDF,从而构建非参数法PI。最后,利用差分进化算法(DE)将两种方法所得PI加权融合,构造总位移的最终预测区间。
1 方法论
1.1 滑坡位移的 VMD 分解
变分模态分解(VMD)是一种由 Dragomiretskiy 和 Zosso(2014)提出的新型自适应信号分解算法。它能够将复杂的非平稳信号分解为具有各自中心频率的不同模态分量 μ _ k \mu\_k μ_k。VMD 不仅能有效克服 EMD 过程中存在的模态混叠问题,还能通过镜像延拓处理端点效应,并在滤除噪声的同时保留原始信号中的有用成分(Li 等, 2018;Xu 和 Niu, 2018)。
滑坡的发生通常伴随着突变的位移变化。如果直接使用原始位移数据序列进行预测,训练的模型可能会误将突变段识别为异常数据(Li 等, 2019),从而增加位移预测的难度。同时,在位移初期稳定阶段根据预测误差概率密度函数(PDF)估计第一个突变点的误差,会导致预测结果出现较大偏差。该点的预测效果不佳会引起误差激增,进一步导致后续误差估计中产生积累效应,从而降低区间预测模型的可靠性。
因此,我们使用 VMD 将位移信号分解为一系列位移分量,以提取局部特征。各个分量的预测误差 PDF 相对稳定,本文主要关注的是如何针对每个分量准确地构建其误差 PDF,并用于有效估计下一时刻的误差。
1.2 Copula 相关性分析
选择有效的输入数据有助于提高预测精度,并充分发挥模型的预测性能,这通常依赖于对输入与输出数据之间相关性的准确评估。传统的线性相关性分析方法对于满足非正态分布特征的随机变量存在一定的局限性,尤其难以处理具有“厚尾”特性的变量。
Copula 方法为解决该问题提供了新的思路。Sklar(1996)提出,对于多个边缘分布函数 F _ 1 ( x _ 1 ) , F _ 2 ( x _ 2 ) , … , F _ N ( x _ N ) F\_1(x\_1), F\_2(x\_2), \dots, F\_N(x\_N) F_1(x_1),F_2(x_2),…,F_N(x_N),存在一个 Copula 函数 C C C,使得联合分布函数 F ( x _ 1 , x _ 2 , … , x _ N ) F(x\_1, x\_2, \dots, x\_N) F(x_1,x_2,…,x_N) 满足以下关系:
F ( x 1 , x 2 , … , x N ) = C ( F 1 ( x 1 ) , F 2 ( x 2 ) , … , F N ( x N ) ) (1) F(x_1, x_2, \dots, x_N) = C(F_1(x_1), F_2(x_2), \dots, F_N(x_N)) \tag{1} F(x1,x2,…,xN)=C(F1(x1),F2(x2),…,FN(xN))(1)
其中, F ( x _ 1 , x _ 2 , … , x _ N ) F(x\_1, x\_2, \dots, x\_N) F(x_1,x_2,…,x_N) 是多个边缘分布的联合分布函数。
常见的 Copula 函数主要分为两类(Reboredo, 2011):
- 椭圆 Copula 函数:包括高斯 Copula 和 Student t Copula;
- 阿基米德 Copula 函数:包括 Gumbel、Clayton 和 Frank Copula。
在实际应用中,通常通过赤池信息准则(AIC)和贝叶斯信息准则(BIC)确定目标数据的最优 Copula 函数(Gao, 2019;Posada 和 Buckley, 2004)。
拟合优度损失函数 L L L 表达如下:
L = ∑ i = 1 n ( p e i − p i ) 2 (2) L = \sum_{i=1}^{n} (pe_i - p_i)^2 \tag{2} L=i=1∑n(pei−pi)2(2)
其中, p e _ i pe\_i pe_i 为经验概率, p _ i p\_i p_i 为理论频率, n n n 为样本数。
AIC 和 BIC 公式如下:
A I C = − 2 ln ( L ) + 2 m (3) AIC = -2 \ln(L) + 2m \tag{3} AIC=−2ln(L)+2m(3)
B I C = − 2 ln ( L ) + m ln ( n ) (4) BIC = -2 \ln(L) + m \ln(n) \tag{4} BIC=−2ln(L)+mln(n)(4)
其中, m m m 为模型参数数量, n n n 为样本数, L L L 为最大对数似然函数。
在本研究中,我们选择使 AIC 和 BIC 最小的 Copula 函数作为最优函数。各影响因子与位移之间的相关性可以通过 Kendall 秩相关系数 τ \tau τ 和上尾相关系数进行评估。当其值大于 0.6 时,表明两个变量之间存在强相关性(Liao 等, 2019;Deng 等, 2017)。
具体的计算过程可参考 Tang(2018)的文献。
1.3 点预测方法:WOA-KELM
根据 Sebbar 等人(2020)的研究,与传统神经网络和支持向量机(SVM)方法相比,核极限学习机(KELM)作为极限学习机(ELM)的一种优化形式,具有训练时间短、避免过拟合和减轻局部最优问题等优势。ELM 是一种单隐层前馈神经网络模型,具有良好的泛化能力和极快的训练速度(Huang et al., 2003; Huang et al., 2006a, b)。其基本结构如图 1 所示。
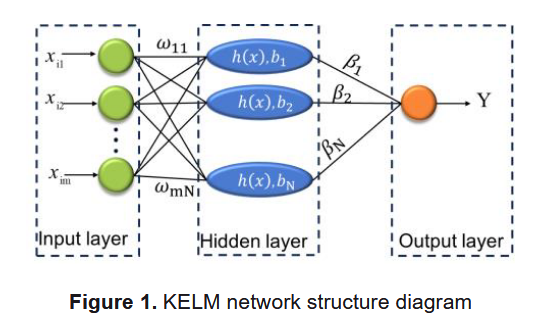
对于一个样本 ( x i , y i ) (x_i, y_i) (xi,yi),其中 x i = [ x i 1 , x i 2 , . . . , x i m ] T ∈ R m x_i = [x_{i1}, x_{i2}, ..., x_{im}]^T \in \mathbb{R}^m xi=[xi1,xi2,...,xim]T∈Rm, y i ∈ R y_i \in \mathbb{R} yi∈R,其输出函数为:
f ( x ) = ∑ i = 1 N β i h ( ω i ⋅ x i + b i ) (5) f(x) = \sum_{i=1}^{N} \beta_i h(\omega_i \cdot x_i + b_i) \tag{5} f(x)=i=1∑Nβih(ωi⋅xi+bi)(5)
其中:
- N N N 为隐层节点数;
- β i = [ β 1 , β 2 , . . . , β N ] \beta_i = [\beta_1, \beta_2, ..., \beta_N] βi=[β1,β2,...,βN] 为隐层到输出层的权重向量;
- ω i = [ ω 1 i , ω 2 i , . . . , ω m i ] \omega_i = [\omega_{1i}, \omega_{2i}, ..., \omega_{mi}] ωi=[ω1i,ω2i,...,ωmi] 为输入到隐层的权重;
- b i = [ b 1 , b 2 , . . . , b N ] b_i = [b_1, b_2, ..., b_N] bi=[b1,b2,...,bN] 为隐层节点的偏置;
- h ( ⋅ ) h(\cdot) h(⋅) 为激活函数。
通过最小二乘法,根据隐藏层输出矩阵 H H H 和实际输出 Y Y Y 求得输出权重矩阵 β \beta β:
β ^ = H + Y (6) \hat{\beta} = H^+Y \tag{6} β^=H+Y(6)
其中 H + H^+ H+ 为 H H H 的 Moore–Penrose 广义逆矩阵:
H = [ h ( ω 1 ⋅ x 1 + b 1 ) ⋯ h ( ω N ⋅ x 1 + b N ) ⋮ ⋱ ⋮ h ( ω 1 ⋅ x m + b 1 ) ⋯ h ( ω N ⋅ x m + b N ) ] (7) H = \begin{bmatrix} h(\omega_1 \cdot x_1 + b_1) & \cdots & h(\omega_N \cdot x_1 + b_N) \\ \vdots & \ddots & \vdots \\ h(\omega_1 \cdot x_m + b_1) & \cdots & h(\omega_N \cdot x_m + b_N) \end{bmatrix} \tag{7} H= h(ω1⋅x1+b1)⋮h(ω1⋅xm+b1)⋯⋱⋯h(ωN⋅x1+bN)⋮h(ωN⋅xm+bN) (7)
为提高模型的泛化能力和稳定性,Huang 等人(2012)引入了核函数,形成核极限学习机(KELM)。其输出权重采用岭回归与正交投影理论进行估计:
β = H T ( 1 C + H H T ) − 1 Y (8) \beta = H^T\left(\frac{1}{C} + HH^T\right)^{-1}Y \tag{8} β=HT(C1+HHT)−1Y(8)
因此输出函数可写为:
f ( x ) = h ( x ) H T ( 1 C + H H T ) − 1 T (9) f(x) = h(x) H^T\left(\frac{1}{C} + HH^T\right)^{-1}T \tag{9} f(x)=h(x)HT(C1+HHT)−1T(9)
将核函数 K ( x , x i ) K(x, x_i) K(x,xi) 代替 H ( x ) H(x) H(x),得:
f ( x ) = [ K ( x , x 1 ) ⋮ K ( x , x N ) ] T ( 1 C + H H T ) − 1 T (10) f(x) = \begin{bmatrix} K(x, x_1) \\ \vdots \\ K(x, x_N) \end{bmatrix}^T \left(\frac{1}{C} + HH^T\right)^{-1}T \tag{10} f(x)= K(x,x1)⋮K(x,xN) T(C1+HHT)−1T(10)
其中核函数选用高斯径向基函数(RBF):
K ( x , x i ) = exp ( − λ ∥ x − x i ∥ 2 ) (11) K(x, x_i) = \exp\left(-\lambda \|x - x_i\|^2\right) \tag{11} K(x,xi)=exp(−λ∥x−xi∥2)(11)
λ \lambda λ 为核参数。为了进一步提高预测精度,引入鲸鱼优化算法(WOA),该算法模拟座头鲸的觅食行为,具备较强的全局搜索能力和收敛性能(Mirjalili et al., 2014),用于优化参数 C C C 和 λ \lambda λ。
1.4 预测区间构建方法
滑坡位移点预测中包含的不确定性主要来自于地质条件变化、监测系统误差以及预测模型误差等。为了定量刻画这些综合不确定性,定义预测误差 ε \varepsilon ε 为:
ε = y − y ^ (12) \varepsilon = y - \hat{y} \tag{12} ε=y−y^(12)
其中 y y y 为真实值, y ^ \hat{y} y^ 为预测值。利用历史误差数据构建概率密度函数(PDF),在此基础上建立 95% 的预测区间(PI)。本文采用参数法(PIPM)与非参数法(NPIPM)并结合形成组合区间预测方法(CIPM),以提升预测区间的鲁棒性和可信度。
1.4.1 参数预测区间方法(PIPM)
PIPM 假设预测误差服从先验分布,常用高斯分布:
f ( x ) = 1 σ 2 π exp ( − ( x − μ ) 2 2 σ 2 ) (13) f(x) = \frac{1}{\sigma\sqrt{2\pi}} \exp\left(-\frac{(x - \mu)^2}{2\sigma^2}\right) \tag{13} f(x)=σ2π1exp(−2σ2(x−μ)2)(13)
但实际误差常具有偏态、厚尾或多峰特征,因此采用学生 t 分布拟合更合理:
f ( x ) = Γ ( v + 1 2 ) v π Γ ( v 2 ) [ 1 + ( x − μ ) 2 v σ 2 ] − v + 1 2 (14) f(x) = \frac{\Gamma\left(\frac{v+1}{2}\right)}{\sqrt{v\pi}\Gamma\left(\frac{v}{2}\right)} \left[1 + \frac{(x - \mu)^2}{v\sigma^2}\right]^{-\frac{v+1}{2}} \tag{14} f(x)=vπΓ(2v)Γ(2v+1)[1+vσ2(x−μ)2]−2v+1(14)
本文采用高斯-学生 t 混合分布建模误差:
f ( x ) = ∑ i = 1 2 ω i f i ( x i ) , ∑ i = 1 2 ω i = 1 (15) f(x) = \sum_{i=1}^{2} \omega_i f_i(x_i), \quad \sum_{i=1}^{2} \omega_i = 1 \tag{15} f(x)=i=1∑2ωifi(xi),i=1∑2ωi=1(15)
通过最小二乘法拟合混合分布的参数。累积分布函数为:
Q M ( ε ) = ∫ − ∞ + ∞ f M ( ε ) d ε (16) Q_M(\varepsilon) = \int_{-\infty}^{+\infty} f_M(\varepsilon) d\varepsilon \tag{16} QM(ε)=∫−∞+∞fM(ε)dε(16)
预测区间为:
[ L ^ 1 , U ^ 1 ] = [ y ^ pred + Q ^ M ( α 1 ) , y ^ pred + Q ^ M ( α 2 ) ] (17) [\hat{L}_1, \hat{U}_1] = [\hat{y}_{\text{pred}} + \hat{Q}_M(\alpha_1), \hat{y}_{\text{pred}} + \hat{Q}_M(\alpha_2)] \tag{17} [L^1,U^1]=[y^pred+Q^M(α1),y^pred+Q^M(α2)](17)
其中 α 1 = α 2 , α 2 = 1 − α 2 \alpha_1 = \frac{\alpha}{2}, \alpha_2 = 1 - \frac{\alpha}{2} α1=2α,α2=1−2α。
1.4.2 非参数预测区间方法(NPIPM)
NPIPM 基于核密度估计(KDE)直接对误差数据拟合概率密度函数,无需假设先验分布:
f ( x ) = 1 n h ∑ i = 1 N K ( x − X i h ) (18) f(x) = \frac{1}{nh} \sum_{i=1}^{N} K\left(\frac{x - X_i}{h}\right) \tag{18} f(x)=nh1i=1∑NK(hx−Xi)(18)
核函数 K ( ⋅ ) K(\cdot) K(⋅) 采用高斯函数:
K ( x ) = 1 2 π exp ( − x 2 2 ) (19) K(x) = \frac{1}{\sqrt{2\pi}} \exp\left(-\frac{x^2}{2}\right) \tag{19} K(x)=2π1exp(−2x2)(19)
带宽 h h h 通过改进插值法获得(Ye et al., 2017):
h = ( ∫ K 2 ( t ) d t k 2 2 ∫ f ( x ) d x ) 1 / 5 n − 1 / 5 (20) h = \left( \frac{\int K^2(t)dt}{k_2^2 \int f(x)dx} \right)^{1/5} n^{-1/5} \tag{20} h=(k22∫f(x)dx∫K2(t)dt)1/5n−1/5(20)
其中 k 2 = ∫ t 2 K ( t ) d t k_2 = \int t^2 K(t)dt k2=∫t2K(t)dt。最终预测区间为:
[ L ^ 2 , U ^ 2 ] = [ y ^ pred + F ^ OWWK ( α 1 ) , y ^ pred + F ^ OWWK ( α 2 ) ] (21) [\hat{L}_2, \hat{U}_2] = [\hat{y}_{\text{pred}} + \hat{F}_{\text{OWWK}}(\alpha_1), \hat{y}_{\text{pred}} + \hat{F}_{\text{OWWK}}(\alpha_2)] \tag{21} [L^2,U^2]=[y^pred+F^OWWK(α1),y^pred+F^OWWK(α2)](21)
1.4.3 基于 PIPM 与 NPIPM 的组合区间预测方法(CIPM)
为综合两种方法优势,构建 CIPM。引入差分进化算法(DE)优化加权系数 λ \lambda λ,以实现最优的预测区间性能(Wang, 2018)。组合区间如下:
{ L ^ comb = λ L ^ 1 + ( 1 − λ ) L ^ 2 U ^ comb = λ U ^ 1 + ( 1 − λ ) U ^ 2 (22) \begin{cases} \hat{L}_{\text{comb}} = \lambda \hat{L}_1 + (1 - \lambda) \hat{L}_2 \\ \hat{U}_{\text{comb}} = \lambda \hat{U}_1 + (1 - \lambda) \hat{U}_2 \end{cases} \tag{22} {L^comb=λL^1+(1−λ)L^2U^comb=λU^1+(1−λ)U^2(22)
其中 λ \lambda λ 通过最小化覆盖宽度准则(CWC)优化得到。
1.5 点预测与区间预测评估指标
点预测常用以下指标评价(Xiang, 2012):
- 决定系数( R 2 R^2 R2)
- 均方根误差(RMSE)
- 平均绝对百分比误差(MAPE)
区间预测则采用以下指标(Wang et al., 2020;Shrivastava et al., 2016;Khosravi et al., 2011):
- PICP(预测区间覆盖率):
P I C P = ξ N test (23) PICP = \frac{\xi}{N_{\text{test}}} \tag{23} PICP=Ntestξ(23)
- PINAW(预测区间平均宽度归一化):
P I N A W = 1 N test ∑ i = 1 N test U ^ ( x i ) − L ^ ( x i ) R (24) PINAW = \frac{1}{N_{\text{test}}} \sum_{i=1}^{N_{\text{test}}} \frac{\hat{U}(x_i) - \hat{L}(x_i)}{R} \tag{24} PINAW=Ntest1i=1∑NtestRU^(xi)−L^(xi)(24)
- CWC(基于覆盖率的宽度评价指标):
C W C = P I N A W [ 1 + γ ⋅ exp ( − η ( P I C P − μ ) ) ] (25) CWC = PINAW \left[1 + \gamma \cdot \exp\left(-\eta(PICP - \mu)\right)\right] \tag{25} CWC=PINAW[1+γ⋅exp(−η(PICP−μ))](25)
其中,当 P I C P ≥ μ PICP \geq \mu PICP≥μ 时, γ = 0 \gamma = 0 γ=0(指数项被消除),否则 γ = 1 \gamma = 1 γ=1。参数 η \eta η 控制惩罚强度,常取 30(Khosravi et al., 2011)。
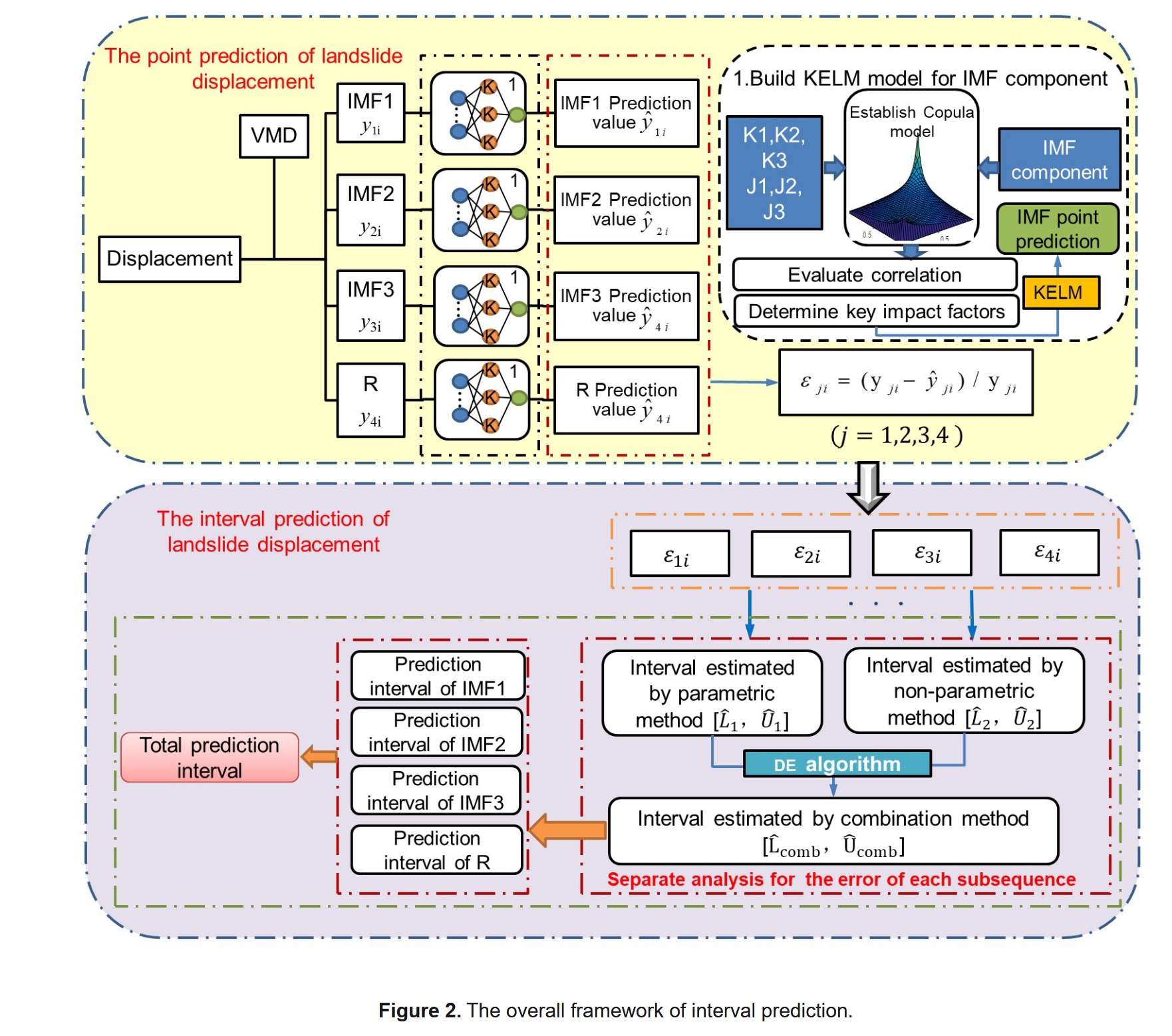
1.6 区间预测流程
基于上述方法的预测区间构建流程如图 2 所示。
2 白家堡滑坡案例研究
2.1 地质背景
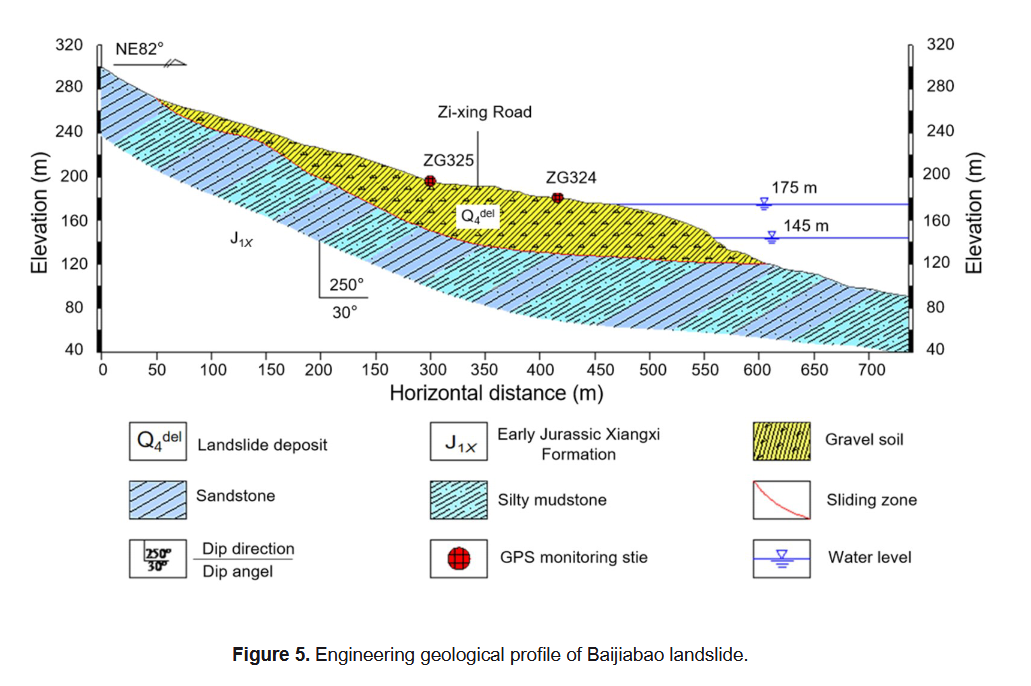
白家堡滑坡位于湖北省秭归县香溪河右岸(见图3),是一典型的库岸堆积体滑坡(Li C.D.等,2021)。滑坡后缘以基岩为界,标高为275 m,前缘直抵香溪河,剪出口标高在125~135 m之间。滑坡左侧为基岩边界,右侧为山脊边界。
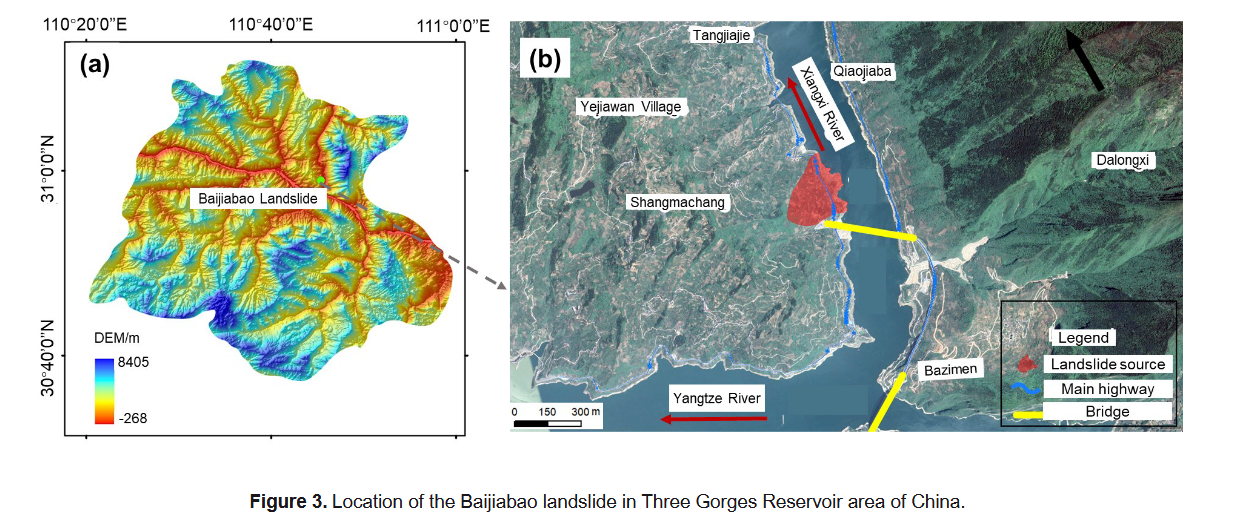
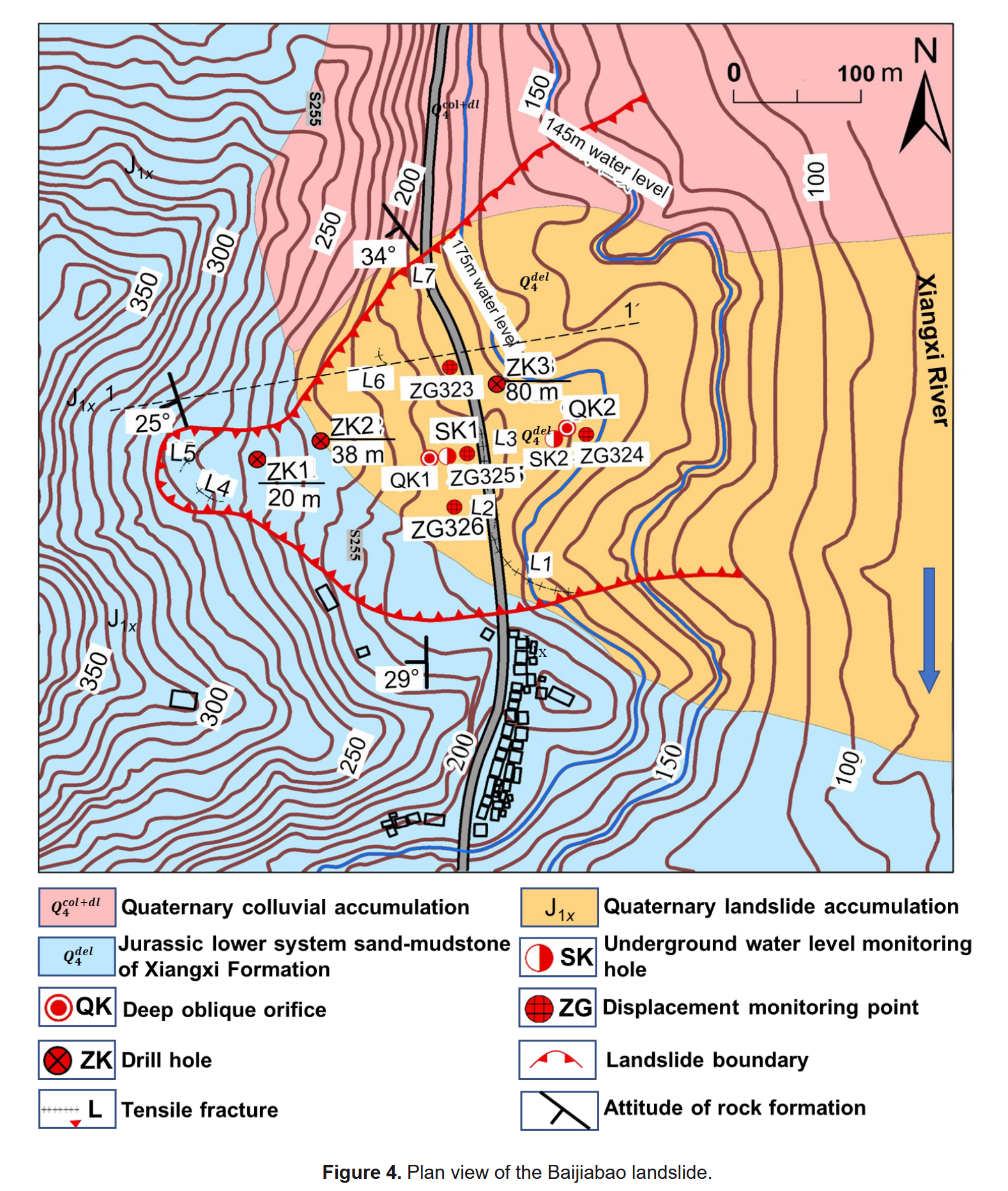
滑坡体呈簸箕状,前缘宽约500 m,后缘宽约300 m,纵向长度约550 m,面积约为2.2 × 10⁵ m²,滑体平均厚度约为45 m。地形自西向东倾斜,西侧坡度为35°~50°,东侧坡度为0°~25°。滑体主要由第四系粉质黏土和碎石土组成,滑带厚度一般为0.2~0.3 m,岩性为粉质黏土,下伏基岩为下侏罗统的长石砂岩、粉砂质泥岩和泥质粉砂岩,倾向260°~285°,倾角30°~40°。
图4和图5分别给出了滑坡的平面图和工程地质剖面图。滑坡表面共布设了四个GPS监测点(ZG323~ZG326),用于定期监测滑坡位移。
2.2 变形特征分析
图6展示了2007年1月至2019年12月期间滑坡累计位移、库水位变化及降雨量情况。表1则进一步列出了2010年1月至2012年12月的详细监测数据,包括位移、降雨及库水位。
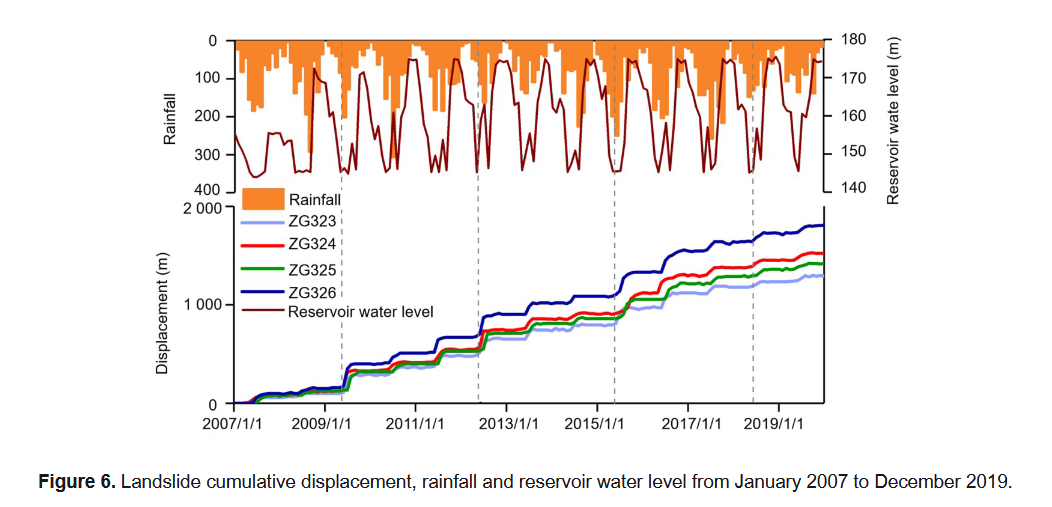
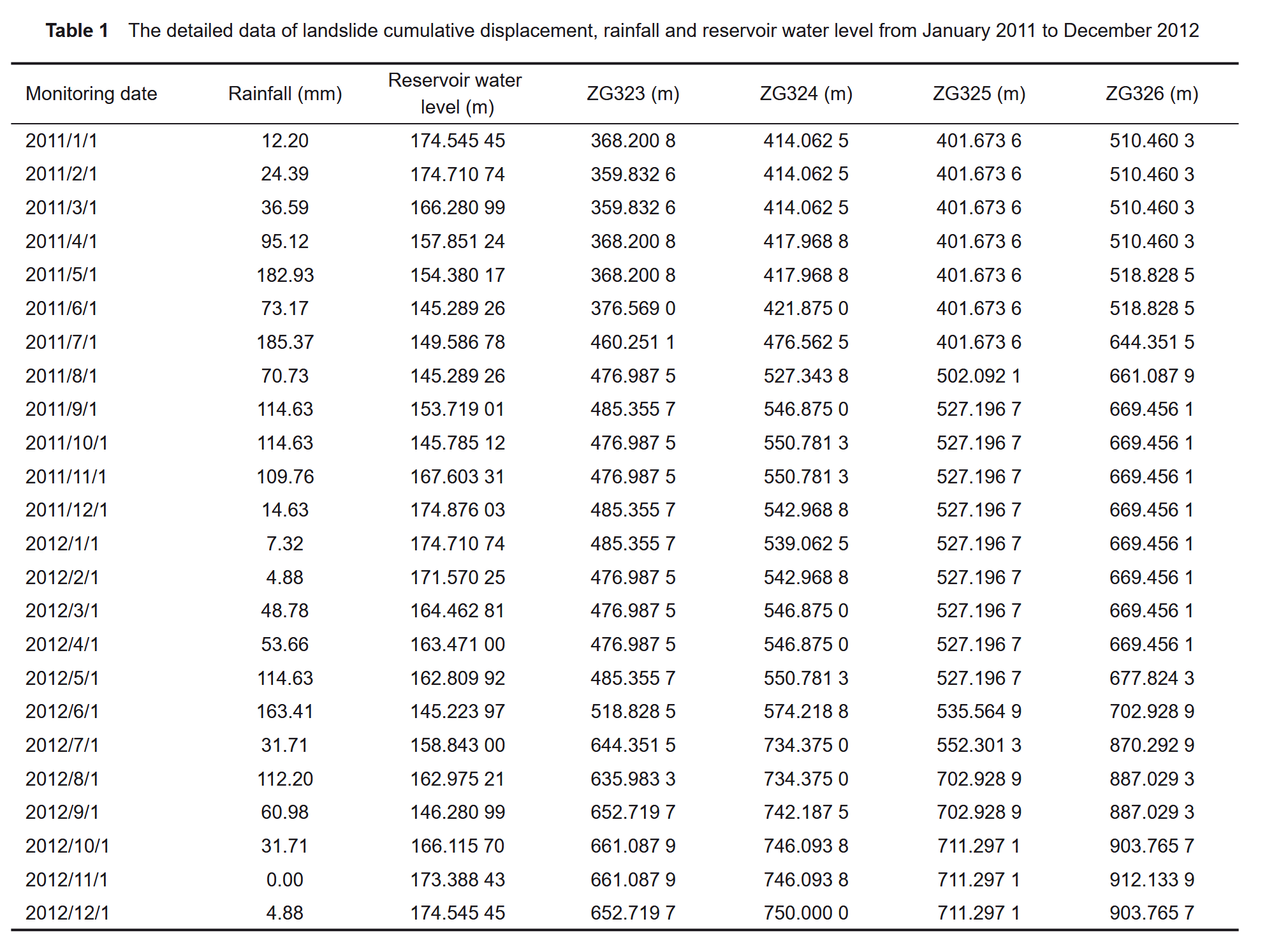
根据苗等人(2018)的研究,滑坡演化过程可分为稳定型、指数型、阶梯型和收敛型。白家堡滑坡的变形属于典型的阶梯型变形,主要受滑体内部结构、库水位波动和强降雨的综合影响(Li L.Q.等,2021;Yao W.M.等,2019;Du等,2013)。
每年3月至7月期间,库水位从高位下降至低位,滑坡的位移增量常集中于5月开始;而在8月至次年4月期间,库水位回升,滑坡位移趋于稳定。这表明滑坡变形与库水位下降呈正相关。然而,库水位自3月开始下降,滑坡位移通常在5月才显著增加,存在约两个月的滞后,难以直接用库水位的月变化解释位移峰值的产生。因此,选取以下因素作为主要影响因子:
- 库水位下降量(DRWL):当月(K1)、前一月(K2)、前两月(K3)
- 累计降雨量(AR):当月(J1)、前一月(J2)、前两月(J3)
2.3 累计位移的分解
相比其他监测点,ZG326的位移变化最为明显,因此选用其数据作为研究基础。采用变分模态分解(VMD)方法对其位移进行分解,最终通过多次试验确定最优参数:模态数为4,惩罚因子α为2000,步长为0.2(Li等,2018)。原始位移被分解为3个内禀模态函数(IMF)和一个残差项(见图7)。
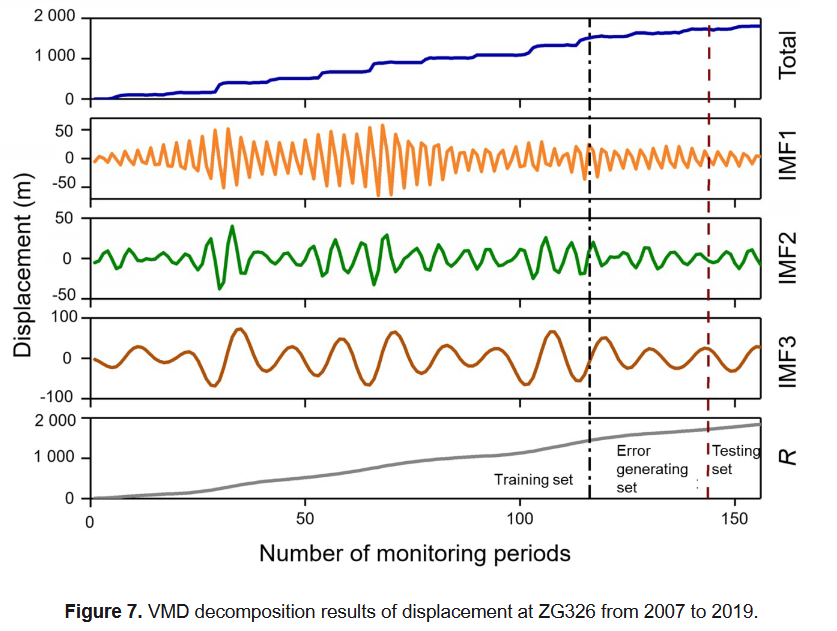
依据Zhang等人(2021)的方法,使用K-means聚类对各IMF进行分析:IMF2和IMF3被判定为周期项位移,残差项为趋势项位移,IMF1为随机项位移。该方法较以往更细致地识别出周期性分量。
ZG326的156个位移样本按8:4的比例划分为训练集与备用集,其中备用集的最后12个样本用于测试。采用逐步预测策略:在每次预测前先将上一次的真实位移值加入训练集并更新模型。每一步均通过鲸鱼优化算法-核极限学习机(WOA-KELM)优化模型参数,从而不断提高预测精度。
2.4 基于Copula模型的关键影响因子选择
参考以往研究(Cao等,2016;Zhou等,2016),趋势位移采用前1~3个月的趋势值进行预测;对于周期项和随机项,采用Copula理论分析其与6个影响因子的相关性(K1~K3、J1~J3)。
对每组变量测试了5种典型的Copula函数,并通过AIC和BIC最小准则筛选最优函数。结果显示,Gumbel Copula函数在各组合中表现最佳,能较好反映上尾依赖关系。图8a和8b分别展示了K2与IMF3、J2与IMF3的Gumbel密度函数。
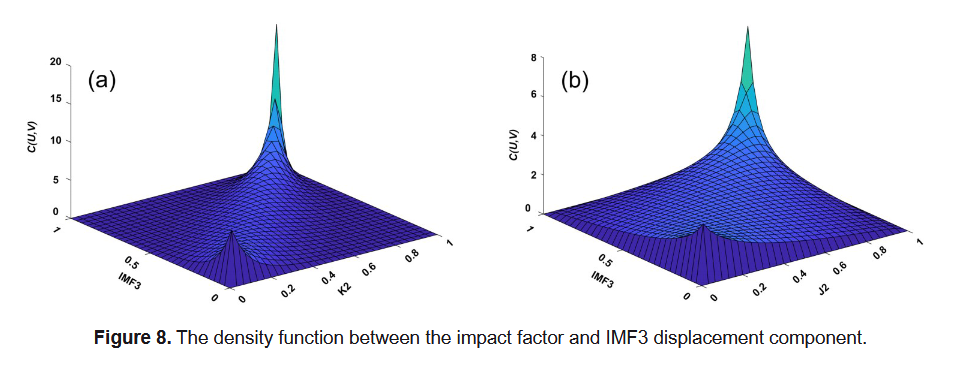
进一步分析其Kendall’s τ值及上尾依赖系数(详见表2)发现,IMF3与全部6个影响因子均有较强相关性,尤其是K2、K3、J1和J2影响最显著,因此选用这四个变量作为WOA-KELM模型的输入。

2.5 位移的点预测
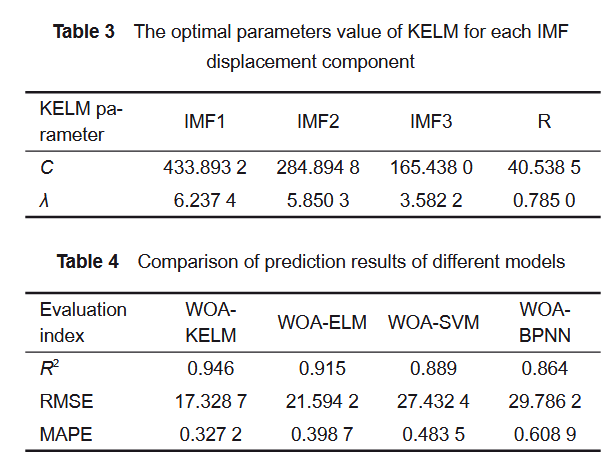
针对每个位移分量,分别建立基于训练数据集的 WOA-KELM 模型,并用于预测备用数据集。参考以往研究(Zhang 等,2021;Mirjalili 等,2014),在每个模型中,鲸鱼优化算法(WOA)设置变量个数为 2,搜索代理数为 30,最大迭代次数为 200。待优化变量向量(C, λ)的上限和下限分别设为 (1000, 10) 和 (10, 0)。通过交叉验证预测值和真实值,得到适应度函数值。每个模型的最优 C 和 λ 由 WOA 优化获得,详见表 3。将最优的 C 和 λ 引入各自的 KELM 模型后,可获得每个位移分量的预测值。所有位移分量的预测值叠加,即得出预测的累计位移。为验证所构建 WOA-KELM 模型的有效性与优越性,使用相同的数据分别进行 WOA-ELM、WOA-SVM 和 WOA-BPNN 的预测工作。预测精度评价指标见表 4。结果表明,WOA-KELM 在四种模型中表现最佳,其 R²、RMSE 和 MAPE 分别为 0.946、17.3287 和 0.3272。这也反映出 WOA-KELM 在处理高维非线性数据时具有更强的泛化能力和学习能力。
2.6 位移的区间预测
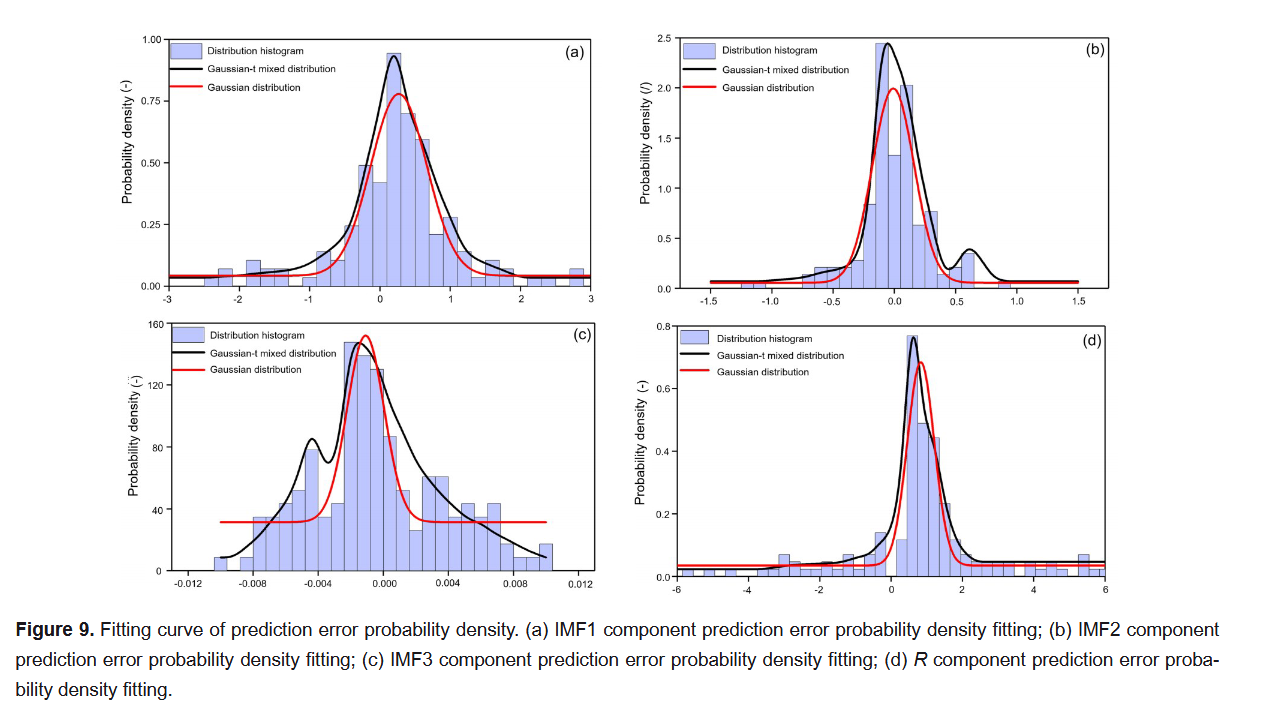
在为每个位移分量生成误差数据集的过程中,可能存在欠拟合现象,因为本研究中仅能使用 40 组数据。这会导致难以选择能真实反映误差分布的合理先验分布。为了解决这一问题,我们选取其他三个监测点的位移误差数据,作为监测点 ZG326 的补充数据,因为这四个位置具有相同的内外部条件。采用高斯分布与高斯-t混合分布,利用最小二乘法拟合每个补充后的位移分量误差的概率密度函数(PDF)。通过优化拟合程度确定各误差分布模型的参数。图 9 显示,高斯-t混合分布在所有四个位移分量上都比高斯分布更接近真实分布。因此,后续 PIPM(概率区间预测模型)分析采用高斯-t混合分布。
在预测某一时刻的位移区间前,需要将上一时刻的真实误差加入误差生成集。同时,根据更新后的真实误差分布,重新确定高斯-t混合分布模型的参数和 PDF。通过反复使用第 1.4.1 节提出的方法,可得到每个位移分量在 95% 置信水平下的预测区间(PI),再将其叠加获得基于 PIPM 的总位移预测区间,详见图 10a。
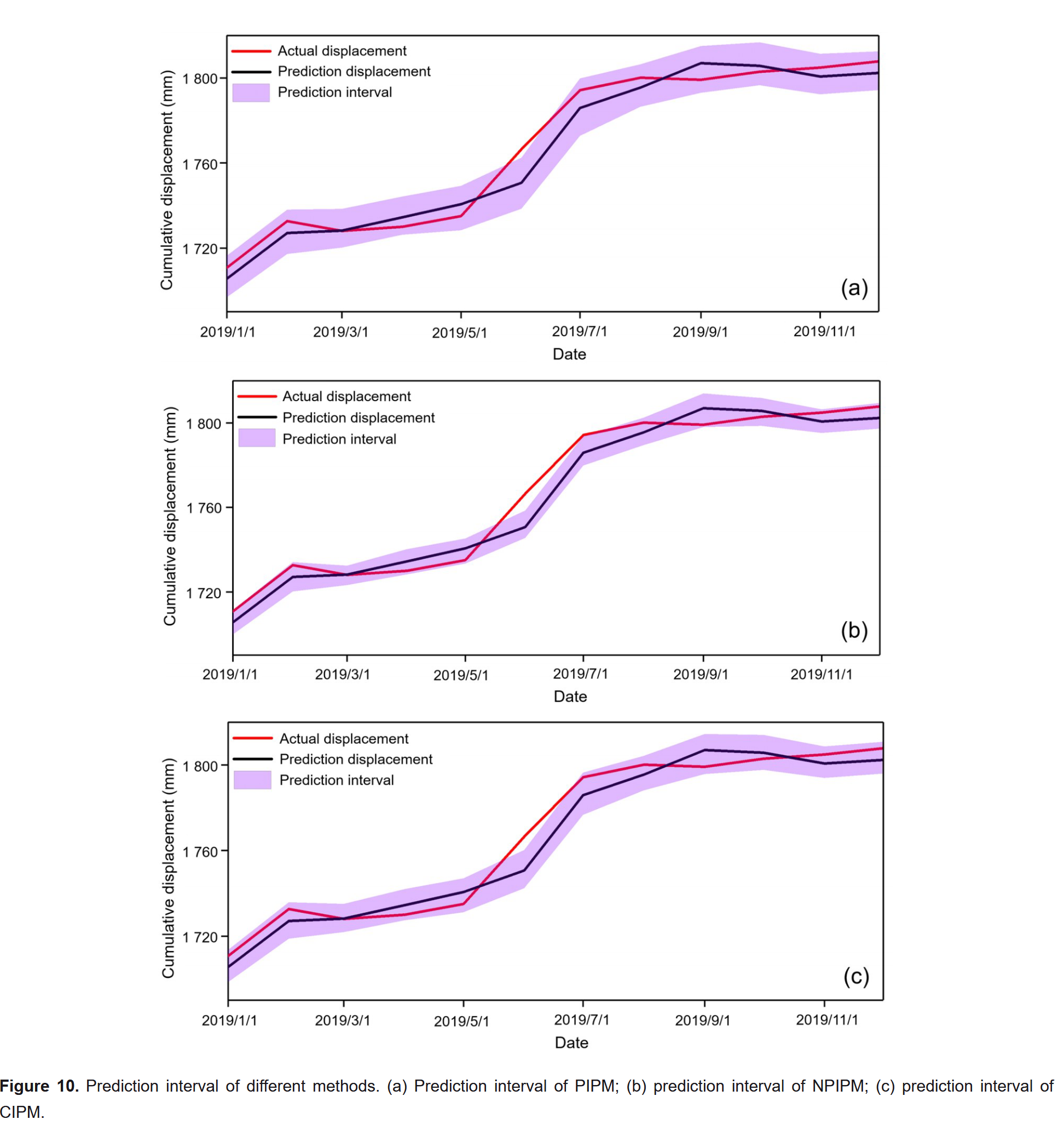
另一方面,根据误差生成集中的真实数据,对每个位移分量的预测误差的 PDF 进行估计。估计结果用于计算测试集每一时刻基于 NPIPM(非参数区间预测模型)的 PI。在估计每一时刻的 PI 前,同样需将前一时刻的真实误差数据纳入误差生成集,同时更新误差的真实 PDF。NPIPM 的预测区间见图 10b。
此外,差分进化算法(DE)的种群规模、放大因子和最大迭代次数分别设为 40、1 和 100。经过 100 次迭代后,最优权重系数 λ 为 0.448。根据公式(22),将 PIPM 和 NPIPM 构建的 PI 结合,得到最终的复合置信区间(CI),如图 10c 所示。
从图 10 可见,PIPM 构建的 PI 虽具有较高的覆盖率,但区间宽度较大,预测精度较低;NPIPM 构建的 PI 虽区间更窄,但对真实位移的覆盖率较低,预测可靠性差。因此,这两种 PI 方法均难以同时兼顾预测精度与可靠性。而由 CIPM(复合区间预测模型)构建的 PI,在预测精度方面优于 PIPM,在预测可靠性方面优于 NPIPM,说明在上述三种方法中,CIPM 是预测白家堡滑坡位移区间的最有效手段。
3 讨论
3.1 模型性能评估
本节采用两种指标评价CIPM模型的预测性能。一是比较第2.6节中提到的不同区间构造方法所得的预测区间(PI);二是将CIPM的结果与前人研究中其他方法的预测结果进行对比。
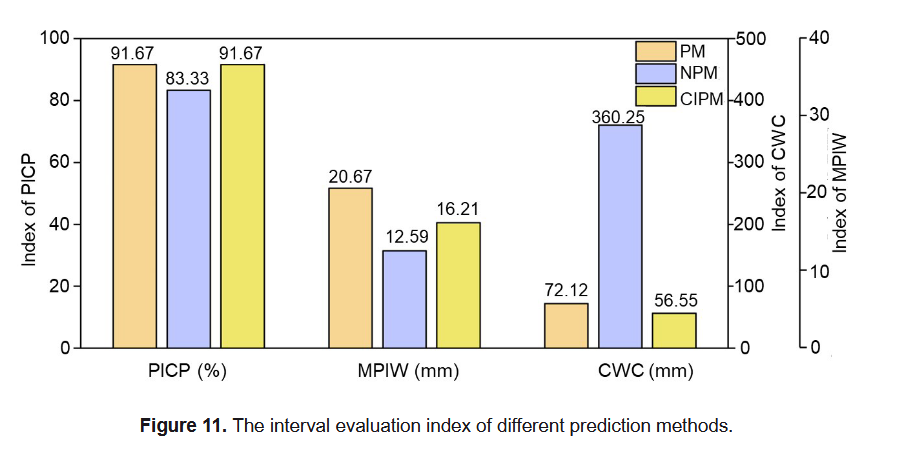
对于第一种评价方式,图11展示了基于三种方法的预测区间覆盖率(PICP)、预测区间平均宽度归一化指标(PINAW)和覆盖加权系数(CWC)等指标值。虽然CIPM构造的PI在PICP和PINAW指标上表现为中等,分别为91.67和16.21,但其CWC值为56.55,是三者中最低的,较PIPM方法低15.57,较NPIPM方法低303.7,体现了CIPM在滑坡位移区间预测中的优越性。
对于第二种评价方式,我们将CIPM应用于王等人(2019)和马等人(2018)报道的熟坪滑坡和白水河滑坡案例,并与DES-PSO-ELM及Bootstrap-ELM-ANN两种方法的预测结果进行比较(见表5)。结果显示,三种方法获得的PICP值基本相同,说明它们均能较好覆盖真实位移数据的变化范围。然而,CIPM所得PI的带宽更窄,导致对应的CWC值最小,体现了更优的预测性能。

3.2 CIPM的局限性与后续工作
白家堡滑坡为三峡库区典型的堆积体滑坡,具有显著的阶梯型变形特征。本文提出的CIPM旨在对该类滑坡位移进行区间预测,但其对其他类型滑坡的适用性仍需进一步验证。
由于本研究所采用的GPS监测数据量较小,误差生成集可能不足以拟合准确的概率密度函数(PDF)。为缓解该问题,我们引入了同一滑坡附近监测点的误差数据作为目标点ZG326误差数据的补充。随着时间推移,实时监测数据逐步积累,误差生成集的规模将满足拟合PDF的要求,且未来可直接利用目标点的监测数据进行PDF拟合。此方法具有较好的灵活性,适用于数据规模大小不一的情形,具备较广的适用性。
此外,本研究中采用GPS监测的位移数据计算预测误差。尽管GPS技术相比传统人工监测有较大提升,但仍存在一定监测局限性。强烈建议结合GPS、InSAR及TDR等多源数据,共同挖掘目标斜坡的真实信息。
另一个问题是,已知的位移数据在预测过程中被假设为未知并用作测试集。该做法是为了验证和评估模型有效性,为后续真实未知位移的预测提供可靠依据。实际应用中,只需利用已有的真实位移数据和未来降雨预报及库水位调控方案得到的相关影响因子数据,构建未知位移的预测区间,为工程人员提供有效参考。
4 结论
滑坡位移的区间预测克服了点预测的局限性,量化了位移预测过程中存在的不确定性,是滑坡预警系统的重要组成部分。本文基于白家堡滑坡数据,提出了一种结合Copula理论与VMD-WOA-KELM的新型复合区间预测模型(CIPM)。
首先,通过Copula模型确定不同位移内禀模态函数(IMF)分量的主要影响因子,并利用WOA-KELM构建它们的非线性关系,从而建立了性能显著提升的点预测模型。其次,通过差分进化算法结合概率模型(PM)和非参数概率模型(NPM)估计预测误差的概率密度函数,并基于各IMF预测区间(PI)叠加得到最终位移置信区间(CI)。
为验证所提CIPM的优越性,将其构造的置信区间与基于PM和NPM的预测区间进行对比,结果表明CIPM不仅满足预测的可靠性要求,还兼顾了预测的准确性。进一步将本方法应用于熟坪滑坡和白水河滑坡案例,并与其他两种区间预测方法比较,结果显示CIPM表现最佳且稳定性较好。
该方法可为滑坡灾害评估和防治提供有力参考。