25年5月来自北大、理想汽车和 UC Berkeley 的论文“GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control”。
世界模型的最新进展彻底改变动态环境模拟,使系统能够预见未来状态并评估潜在行动。在自动驾驶中,这些功能可帮助车辆预测其他道路使用者的行为、执行风险意识规划、加速模拟训练并适应新场景,从而提高安全性和可靠性。当前的方法在保持强大的 3D 几何一致性或在遮挡处理期间累积伪影方面表现出不足,这两者对于自动导航任务中的可靠安全评估都至关重要。为了解决这个问题,GeoDrive 将强大的 3D 几何条件明确地集成到驾驶世界模型中,以增强空间理解和动作可控性。具体而言,首先从输入帧中提取 3D 表示,然后根据用户指定的自车轨迹获取其 2D 渲染。为了实现动态建模,提出一个训练期间的动态编辑模块,通过编辑车辆的位置来增强渲染。大量实验表明,该方法在动作精度和 3D 空间-觉察方面均显著优于现有模型,从而能够构建更逼真、适应性更强、更可靠的场景建模,从而实现更安全的自动驾驶。此外,该模型可以泛化到新轨迹,并提供交互式场景编辑功能,例如目标编辑和目标轨迹控制。
GeoDrive 如图所示:

给定初始参考图像 I_0 和自车轨迹 {C_t},框架合成遵循输入轨迹的真实未来帧。利用参考图像中的 3D 几何信息来指导世界建模。首先,重建 3D 表示,然后沿着用户指定的轨迹渲染视频序列,并进行动态物体处理。渲染后的视频为生成遵循输入轨迹的时空一致视频提供几何指导。其训练流水线如图所示:
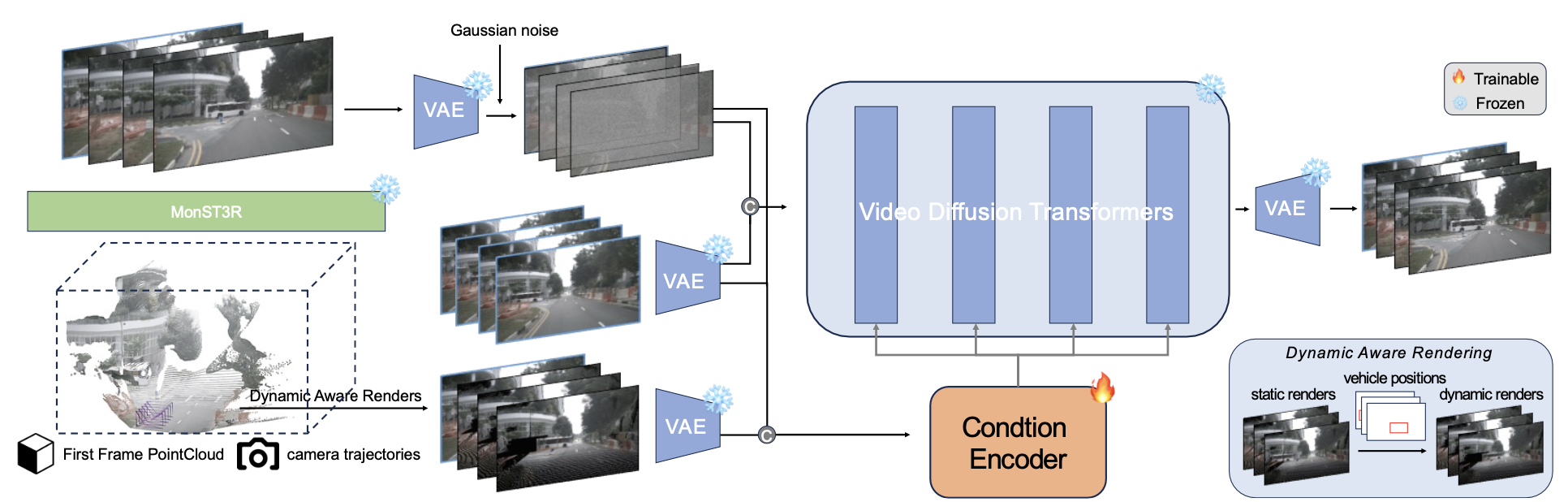
从参考图像中提取 3D 表示
为了利用 3D 信息进行 3D 一致性生成,首先从单幅输入图像 I_0 构建 3D 表示。采用 MonST3R [81],这是一个现成的密集立体视觉模型,可以同时预测 3D 几何形状和相机姿态,这与训练范式一致。在推理过程中,复制参考图像以满足 MonST3R 的跨视图匹配要求。
给定 RGB 帧 {I_t},MonST3R 通过跨帧跨视图特征匹配来预测每像素 3D 坐标 {O_t} 和置信度得分 {D_t}。
将 D_0 设置为 τ(通常 τ = 0.65),第 t 个参考帧的彩色点云结果如下:
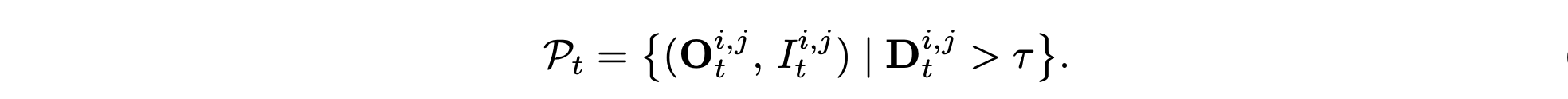
为了抵消序列中有效匹配和无效匹配之间的不平衡,用焦点损失来训练置信度图 D_0。此外,为了将静态场景几何与运动目标分离,MonST3R 采用基于 Transformer 的解耦器。该模块处理参考帧的初始特征(跨视图上下文进行丰富),并将其分离为静态和动态部分。解耦器使用可学习的提示 token 来划分注意图:静态 token 关注较大的平面,动态 token 关注紧凑且运动丰富的区域。通过排除动态对应关系,获得稳健的相机姿态估计:
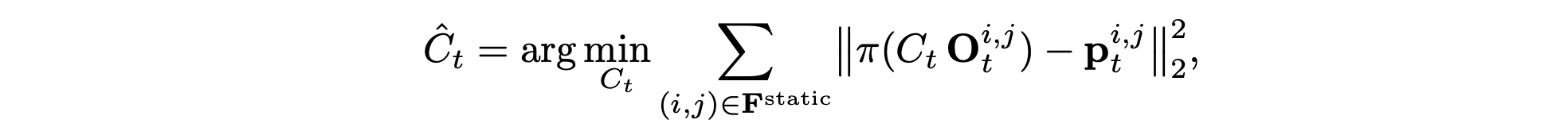
利用动态编辑渲染 3D 视频
为了实现精确的输入轨迹跟踪,模型会渲染一段视频,作为生成过程的视觉引导。用标准射影几何技术,通过用户提供的每个相机配置 C_t = (R_t, T_t, f_t) 将参考点云 P_0 投影。每个 3D 点 Pw_i ∈ P_0 经过刚性变换到相机坐标系 Pc_i = R_tPw_i +T_t,然后使用相机的内参矩阵 K_t 进行透视投影,得到图像坐标 p_i。仅考虑 P_ic_z ∈ [0.1, 100.0 m] 深度范围内的有效投影,并使用 z-缓冲处理遮挡,最终为每个相机位置生成渲染视图 I ̃_t。
静态渲染的局限性。由于仅使用第一帧点云,渲染场景在整个序列中保持静态。这与现实世界的自动驾驶环境存在显著差异,因为在现实世界中,车辆和其他动态物体处于持续运动状态。渲染的静态特性未能捕捉到区分自动驾驶数据集和传统静态场景的动态本质。
动态编辑。为了解决这一局限性,提出动态编辑来生成具有静态背景和移动车辆的渲染图 R。具体而言,当用户为场景中的移动车辆提供一系列二维边框信息时,会动态调整它们的位置,从而在渲染图中营造出运动的视觉效果。这种方法不仅可以在生成过程中引导自身车辆的轨迹,还可以引导场景中其他车辆的移动。如图展示此过程。这种设计显著缩小静态渲染与动态现实世界场景之间的差异,同时实现对其他车辆的灵活控制——这是 Vista [13] 和 GAIA [23] 等现有方法无法实现的功能。

双-分支控制实现时空一致性
虽然基于点云的渲染能够准确地保留视图之间的几何关系,但它存在一些视觉质量问题。渲染后的视图通常包含大量遮挡、由于传感器覆盖范围有限而导致的区域缺失,并且与真实相机图像相比视觉保真度较低。为了提升质量,调整潜在视频扩散模型 [5],以优化投影视图,同时通过专门的调节来保持 3D 结构保真度。
在此基础上,进一步改进将上下文特征集成到预训练扩散Transformer (DiT) 中的方案,这借鉴 VideoPainter [2] 提出的方法。然而,根据自身特定需求引入关键的区别。采用动态渲染来捕捉时间和上下文的细微差别,从而为生成过程提供更具自适应性的表示。令 δ_φ(z_t, t, C) 表示修改后的 DiT 主干网络 δ_φ 第 i 层的特征输出,其中 z_R 表示通过 VAE 编码器 E 的动态渲染潜特征,z_t 是时间步长 t 的噪声潜特征。
这些渲染图通过轻量级条件编码器进行处理,该编码器提取必要的背景线索,而无需复制主干架构的大量部分。将条件编码器的特征集成到冻结的 DiT 中,其公式如下:
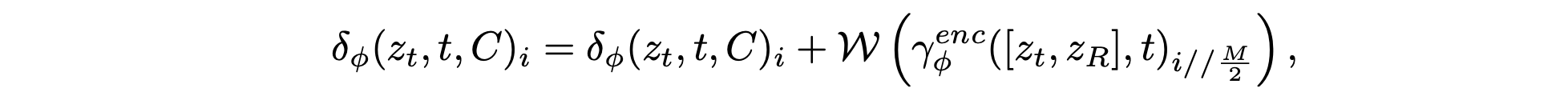
其中 γenc_φ 表示处理噪声潜变量 z_t 的连接输入和渲染潜变量 z_R 的条件编码器,M 表示 DiT 主干网中的总层数。W 是一个可学习的线性变换,初始化为零,以防止早期训练中的噪声崩溃。提取的特征以结构化的方式选择性地融合到冻结的 DiT 中,确保只有相关的上下文信息引导生成过程。最终的视频序列通过冻结的 VAE 解码器 D 解码为 Iˆ_t = D(z(0)_t)。
通过将训练限制在条件编码器 g_φ(占总参数的 6%),保持预训练模型的照片级真实感,并获得精确的相机控制。时间相干性自然地源于视频 Transformer 的动态建模以及跨帧 {I ̃_t} 特征的几何一致性,从而实现忠实轨迹的视频合成。
训练配置。仅在 nuScenes [7] 上进行训练,通过 MonST3R 处理每个片段,以获得公制尺度的 3D 重建和摄像机轨迹。初始帧 P_0 的 3D 重建通过可微分光栅化器沿估计的轨迹进行投影渲染,其中动态编辑利用 2D 边框注释来编辑车辆位置。整理 25,109 个视频-条件对用于训练。冻结基础扩散模型 (CogVideo-5B-I2V [22]),同时以 1 × 10−5 的学习率对条件编码器进行 28,000 步训练,持续 4 天。
基准和基线方法。将 GeoDrive 与两个最相关的基线模型(Vista[13]、Terra[1])以及其他几个驾驶世界模型进行了比较,这几个基线模型以单幅图像和自我动作为条件。遵循 Vista 的协议,从跨越 25 帧剪辑的传感器和标定数据中计算轨迹,作为它们的条件输入。通过在 GT 视频上运行 MonST3R 来估计条件相机姿势。虽然以不同的模态为条件,但所有方法的轨迹都是从同一个真值视频剪辑中提取的,以确保动作条件一致。在 NuScenes 验证集上评估所有方法。为了评估轨迹控制精度,从 1087 个具有平衡驾驶轨迹的视频子集进行采样。视觉质量通过 PSNR、SSIM[63]、LPIPS[29]、FID[20]和 FVD[57]进行量化。而轨迹保真度指标采用平均位移误差(ADE)和最终位移误差(FDE)。
将 GeoDrive 与场景重建方法 StreetGaussians [73] 进行比较。在 Waymo 验证集上进行评估,并筛选出 5 个场景进行测试。新轨迹是通过水平移动前置摄像头的原始轨迹生成的。由于新轨迹没有真实值,用 FID 和 FVD 来评估生成质量。