在数据分析和机器学习领域,分类数据(Categorical Data)的处理是一个基础但至关重要的环节。分类数据指的是由有限数量的离散值组成的数据类型,如性别(男/女)、颜色(红/绿/蓝)或产品类别(电子产品/服装/食品)等。由于大多数机器学习算法只能处理数值型数据,因此我们需要将分类数据转换为数值形式,这一过程称为“编码”。
本文将深入探讨7种最常用的分类数据编码技术,包括One-hot encoding、Dummy encoding、Effect encoding、Label encoding、Ordinal encoding、Count encoding和Binary encoding。每种技术都有其独特的优势和适用场景,理解它们的差异对于构建高效的机器学习模型至关重要。
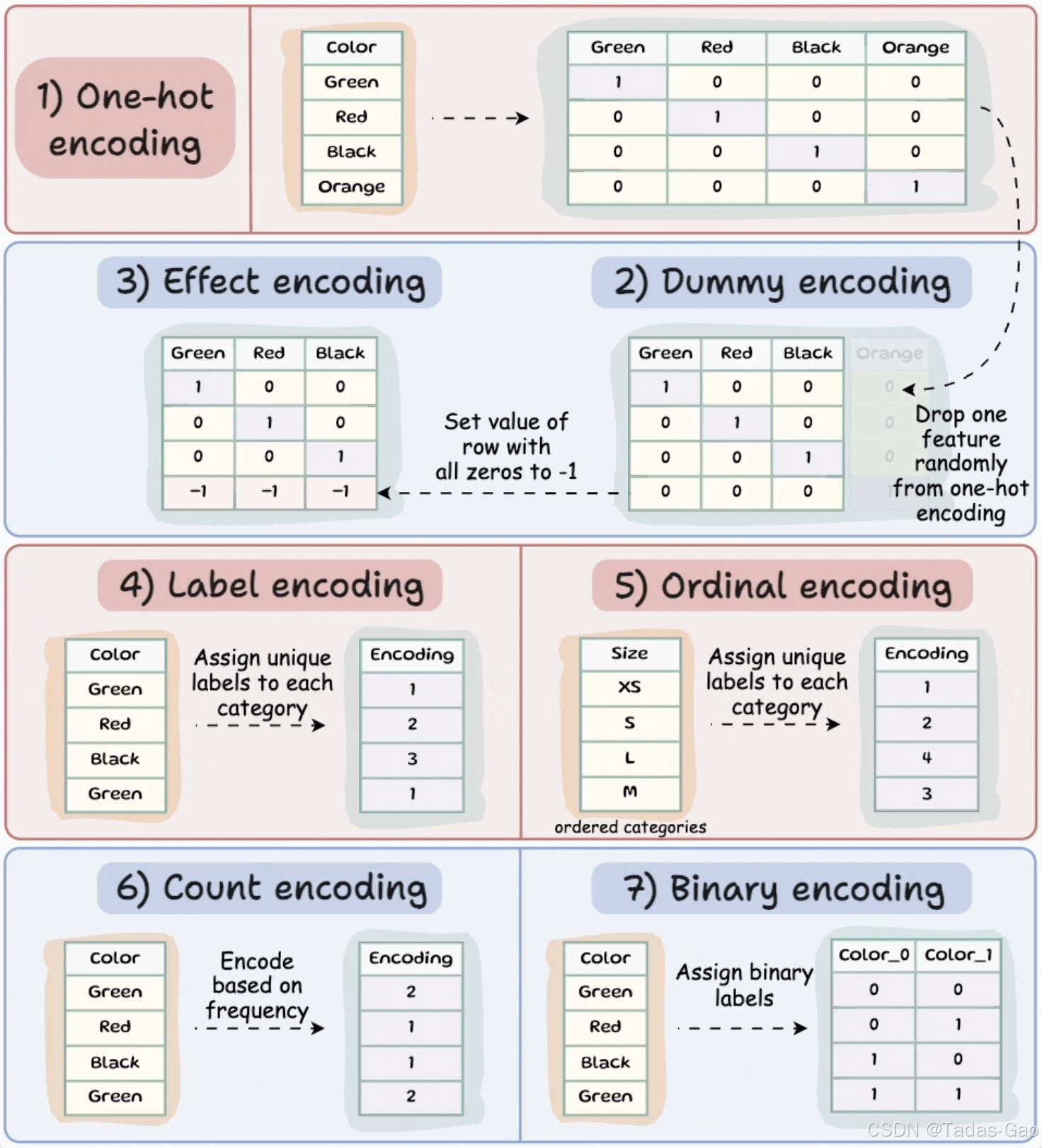
1. One-hot Encoding(独热编码)
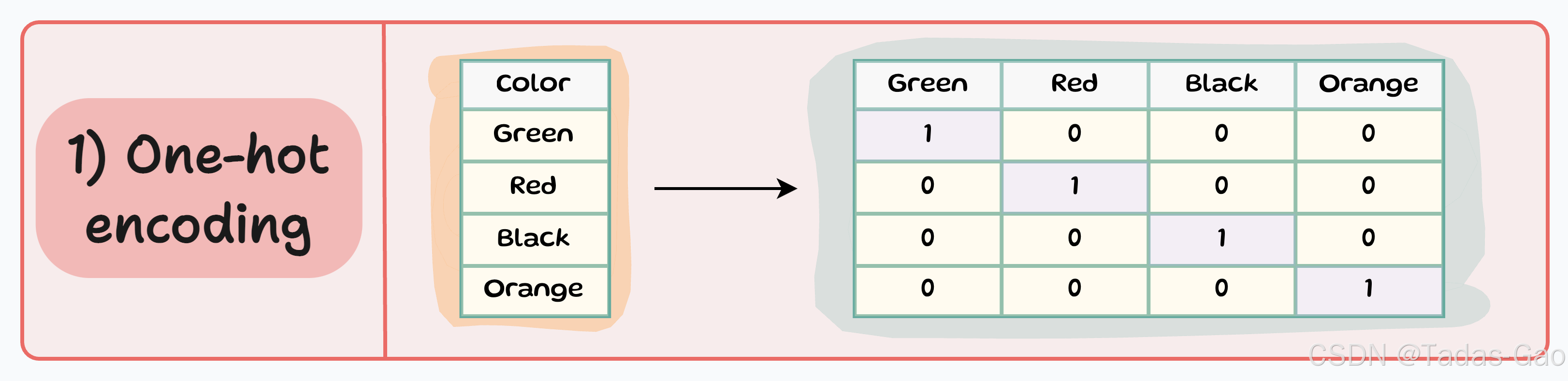
原理与特点
One-hot encoding是最常用的分类数据编码技术之一。它的核心思想是为每个类别创建一个新的二进制特征(0或1),表示该类别是否存在。对于有N个不同类别的分类变量,One-hot encoding会生成N个新的二进制特征。
特点
每个类别由0和1的二进制向量表示
每个样本中只有一个特征为1(“热”),其余为0
生成的特征数量等于唯一分类标签的数量
消除了类别间的隐含顺序关系
生活化案例
想象你正在为一家冰淇淋店记录顾客最喜欢的口味。假设有三种口味:香草、巧克力和草莓。使用One-hot encoding,我们可以这样表示:
香草:[1, 0, 0]
巧克力:[0, 1, 0]
草莓:[0, 0, 1]
代码实现
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
# 示例数据
data = pd.DataFrame({'Flavor': ['Vanilla', 'Chocolate', 'Strawberry', 'Chocolate', 'Vanilla']})
# 创建OneHotEncoder实例
encoder = OneHotEncoder(sparse_output=False)
# 拟合并转换数据
encoded_data = encoder.fit_transform(data[['Flavor']])
# 转换为DataFrame并添加列名
encoded_df = pd.DataFrame(encoded_data, columns=encoder.get_feature_names_out(['Flavor']))
print("原始数据:")
print(data)
print("\nOne-hot编码后的数据:")
print(encoded_df)
优缺点分析
优点
简单直观,易于实现
保留了所有类别信息
消除了类别间的顺序关系,适合没有内在顺序的分类变量
缺点
当类别数量很多时(高基数特征),会导致特征维度急剧增加(维度灾难)
生成的稀疏矩阵可能占用大量内存
对于某些模型(如线性回归),可能导致多重共线性问题
2. Dummy Encoding(虚拟编码)

原理与特点
Dummy encoding是One-hot encoding的一种变体,它通过删除一个类别来避免“虚拟变量陷阱”(Dummy Variable Trap)。虚拟变量陷阱指的是当所有虚拟变量都为0时,可以确定被删除的那个类别,这会导致多重共线性问题,影响某些模型的性能(如线性回归)。
特点
与One-hot encoding相同,但删除一个特征
特征数量 = 唯一分类标签数量 - 1
避免了虚拟变量陷阱问题
被删除的类别成为“参考类别”
生活化案例
继续使用冰淇淋口味的例子,如果我们选择“香草”作为参考类别,Dummy encoding表示如下:
香草:[0, 0](参考类别)
巧克力:[1, 0]
草莓:[0, 1]
代码实现
# 使用pandas的get_dummies函数实现Dummy encoding
dummy_encoded = pd.get_dummies(data['Flavor'], prefix='Flavor', drop_first=False)
# 删除一列以创建Dummy encoding(通常删除第一个或最后一个类别)
dummy_encoded = dummy_encoded.iloc[:, 1:] # 删除'Flavor_Vanilla'列
print("\nDummy编码后的数据(删除Vanilla作为参考类别):")
print(dummy_encoded)
优缺点分析
优点
解决了多重共线性问题
比One-hot encoding更节省空间(少一列)
在线性模型中有更好的解释性
缺点
参考类别的选择可能影响模型解释
仍然存在高基数特征维度问题
不如One-hot encoding直观
3. Effect Encoding(效应编码)
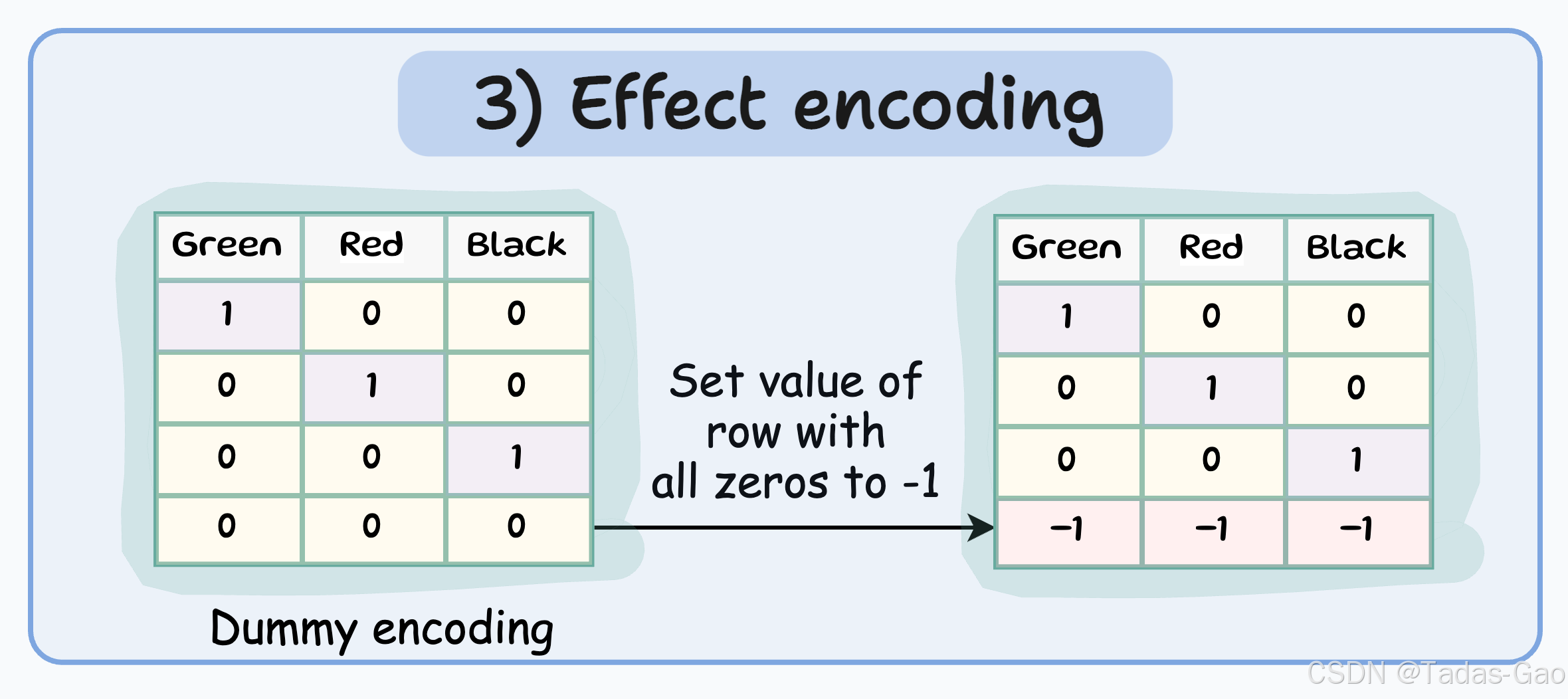
原理与特点
Effect encoding(也称为Sum Contrast Coding)是Dummy encoding的另一种变体。它不是简单地将参考类别编码为全0,而是将其编码为-1。这使得生成的二元特征不仅表示特定类别的存在与否,还表示参考类别与任何类别之间的对比。
特点
类似于Dummy encoding,但将全零行更改为-1
特征数量 = 唯一分类标签数量 - 1
适用于线性模型,可以更好地估计类别效应
参考类别的系数是其他类别系数的负和
生活化案例
使用冰淇淋口味的例子,Effect encoding表示如下(选择“香草”作为参考类别):
香草:[-1, -1]
巧克力:[1, 0]
草莓:[0, 1]
代码实现
import patsy
import pandas as pd
import statsmodels.api as sm
# 示例数据
data = pd.DataFrame({'Flavor': ['Vanilla', 'Chocolate', 'Strawberry', 'Chocolate', 'Vanilla']})
# 使用 patsy 进行 Effect 编码
effect_encoded = patsy.dmatrix(
"C(Flavor, Sum)", # Sum 表示 Effect 编码
data=data,
return_type='dataframe'
)
# 重命名列(可选)
effect_encoded.columns = ['Intercept', 'Flavor_Chocolate', 'Flavor_Strawberry']
print("\nEffect编码后的数据:")
print(effect_encoded.drop(columns='Intercept')) # 去掉截距项
优缺点分析
优点
特别适合线性模型和方差分析
可以更好地估计类别间的相对效应
参考类别的处理更加对称
缺点
实现较为复杂,不是所有库都直接支持
解释性不如One-hot或Dummy encoding直观
对于非线性和树模型可能没有优势
4. Label Encoding(标签编码)
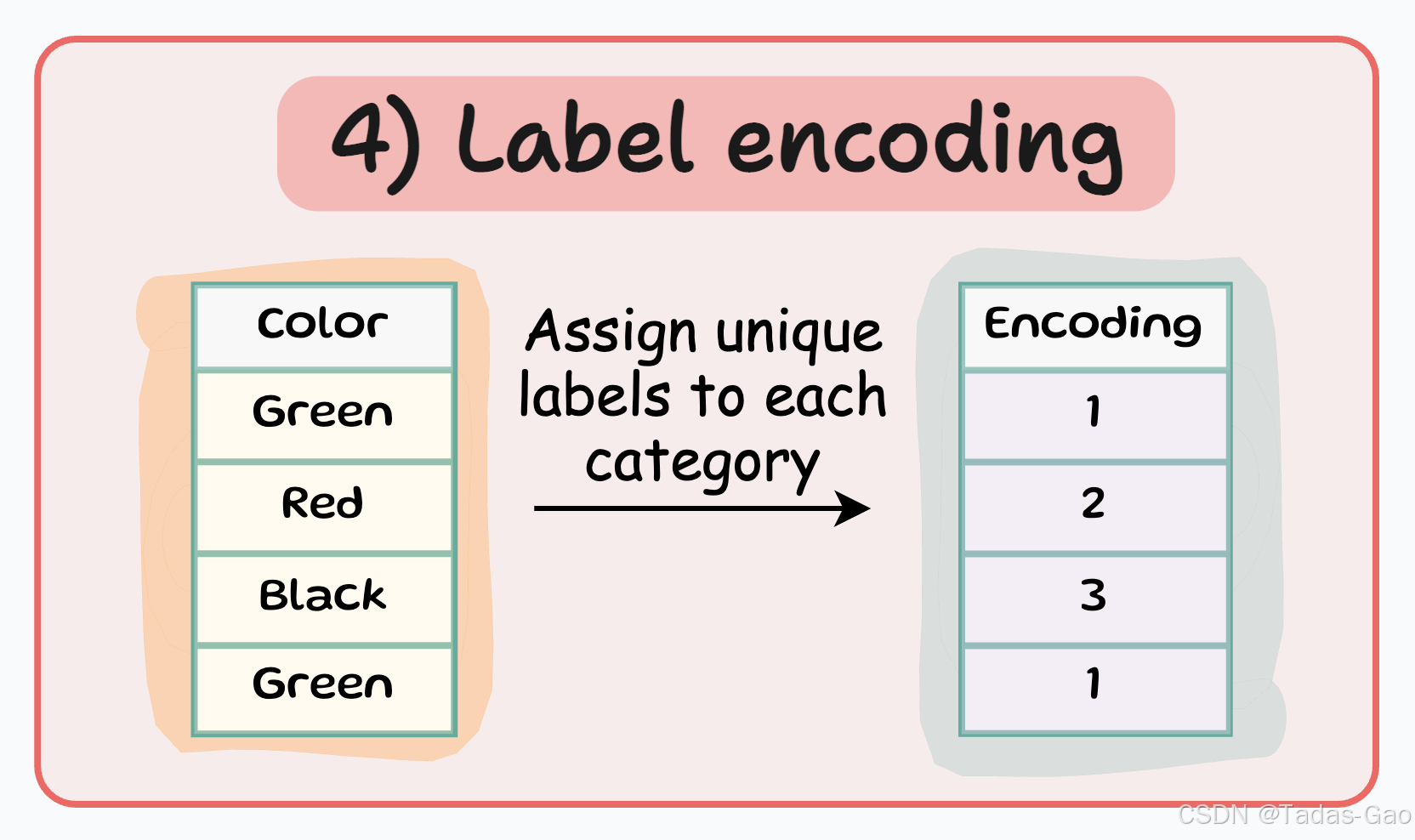
原理与特点
Label encoding是最简单的编码方式之一,它为每个类别分配一个唯一的整数标签。这种编码方式非常节省空间,因为它只增加一个特征列。
特点
为每个类别分配一个唯一的整数标签
特征数量 = 1
极其节省空间
可能引入不存在的顺序关系
生活化案例
对于冰淇淋口味:
香草:0
巧克力:1
草莓:2
代码实现
from sklearn.preprocessing import LabelEncoder
# 创建LabelEncoder实例
label_encoder = LabelEncoder()
# 拟合并转换数据
label_encoded = label_encoder.fit_transform(data['Flavor'])
# 转换为DataFrame
label_encoded_df = pd.DataFrame(label_encoded, columns=['Flavor_Label'])
print("\nLabel编码后的数据:")
print(label_encoded_df)
print("\n类别映射:", dict(zip(label_encoder.classes_, label_encoder.transform(label_encoder.classes_))))
优缺点分析
优点
极其简单高效
不增加数据维度
适用于树模型(如随机森林、梯度提升树)
缺点
引入了可能不存在的顺序关系(如算法可能认为香草(2) > 草莓(1) > 巧克力(0))
不适合线性模型、神经网络等
数值大小可能被误解为重要性或权重
5. Ordinal Encoding(序数编码)
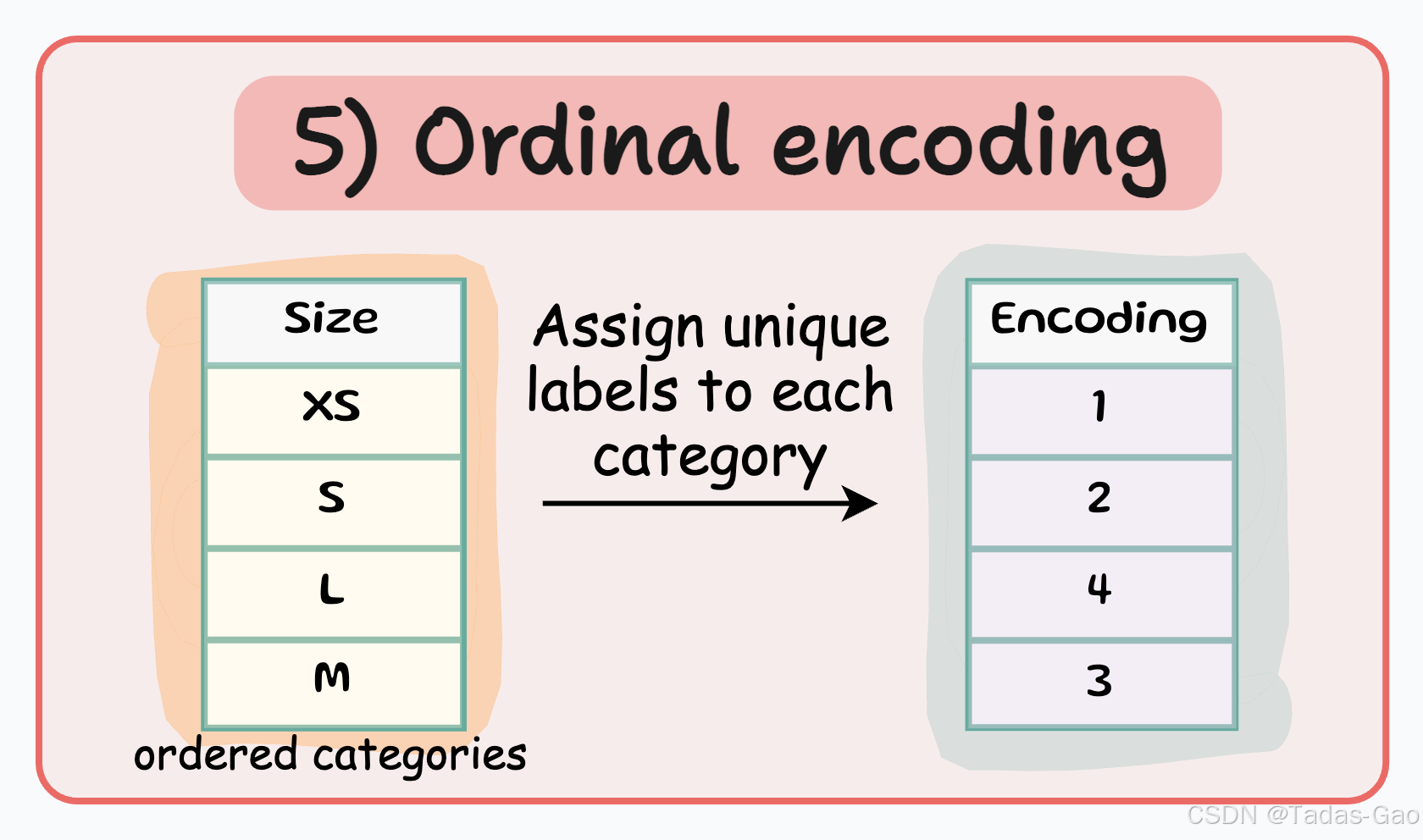
原理与特点
Ordinal encoding与Label encoding类似,但它专门用于具有内在顺序的分类变量。编码时按照类别的自然顺序分配数值,保留了顺序信息。
特点
为有序类别分配具有顺序意义的整数值
特征数量 = 1
保留了类别间的顺序关系
数值大小反映类别顺序
生活化案例
考虑教育程度分类:高中 < 本科 < 硕士 < 博士:
高中:0
本科:1
硕士:2
博士:3
代码实现
# 示例数据:教育程度
education_data = pd.DataFrame({'Education': ['High School', 'Bachelor', 'Master', 'PhD', 'Bachelor']})
# 定义类别顺序
education_order = ['High School', 'Bachelor', 'Master', 'PhD']
# 创建OrdinalEncoder实例
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder(categories=[education_order])
# 拟合并转换数据
ordinal_encoded = ordinal_encoder.fit_transform(education_data[['Education']])
# 转换为DataFrame
ordinal_encoded_df = pd.DataFrame(ordinal_encoded, columns=['Education_Ordinal'])
print("\n原始教育程度数据:")
print(education_data)
print("\nOrdinal编码后的数据:")
print(ordinal_encoded_df)
优缺点分析
优点
保留了有序分类变量的顺序信息
不增加数据维度
适用于能够利用顺序信息的模型
缺点
不适用于无序分类变量
仍然可能引入数值大小的误解(如认为博士(3)是本科(1)的3倍)
需要预先知道类别的正确顺序
6. Count Encoding(计数编码)
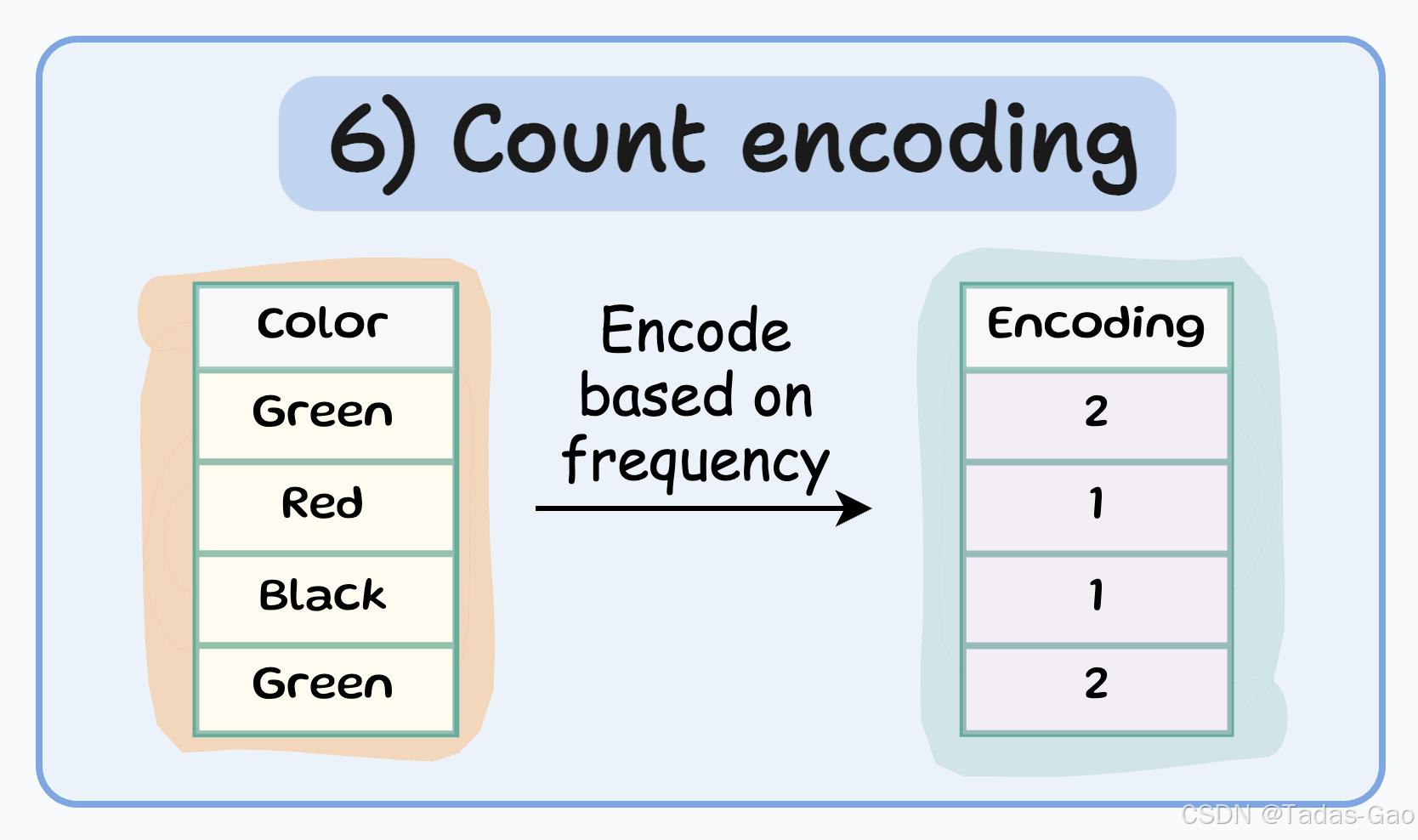
原理与特点
Count encoding(也称为频率编码)用每个类别在数据集中出现的次数(或频率)替换类别标签。这种方法特别适用于高基数分类特征。
特点
用类别的出现次数或频率替换类别
特征数量 = 1
保留了类别的分布信息
对高基数特征有效
生活化案例
假设我们有一个城市的客户数据集,其中“城市”是一个高基数分类变量(如100个不同城市)。我们可以用每个城市在数据集中出现的次数来编码:
北京(出现85次):85
上海(出现120次):120
广州(出现60次):60
代码实现
import pandas as pd
# 示例数据
city_data = pd.DataFrame({'City': ['Beijing', 'Shanghai', 'Guangzhou',
'Beijing', 'Shanghai', 'Shanghai']})
city_data['City_Count'] = city_data.groupby('City')['City'].transform('count')
# 输出结果
print("\n原始城市数据:")
print(city_data['City'])
print("\nCount编码后的数据:")
print(city_data)
print("\n计数映射:", city_data['City'].value_counts().to_dict())
优缺点分析
优点
对高基数分类变量非常有效
不增加数据维度
保留了类别的分布信息
可以揭示流行度或频率信息
缺点
不同但出现次数相同的类别会被编码为相同值
可能对罕见类别不友好(可能需要进行平滑处理)
如果类别出现次数与目标变量无关,可能引入噪声
7. Binary Encoding(二进制编码)
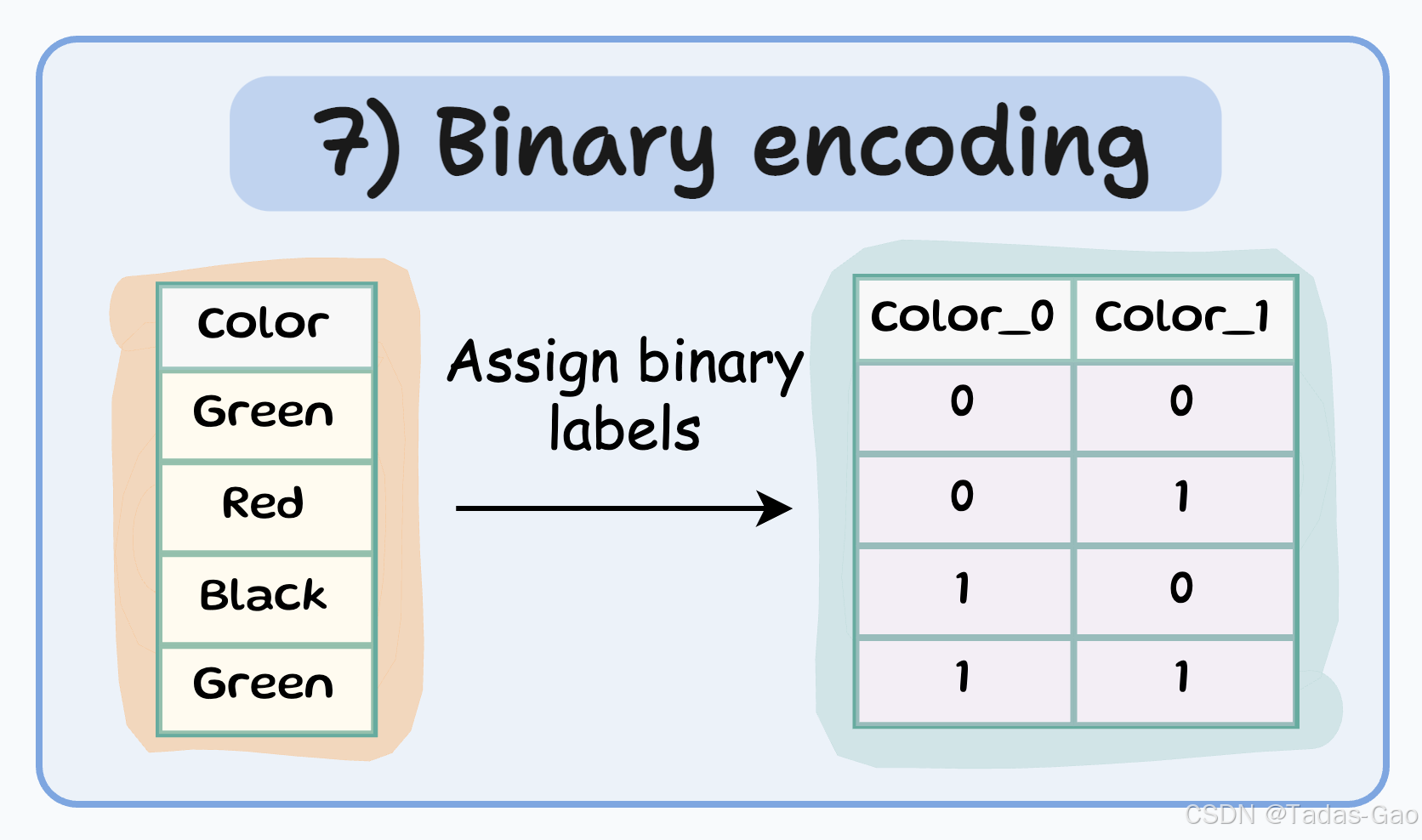
原理与特点
Binary encoding是One-hot encoding和Label encoding的组合。它首先将类别转换为数值(类似Label encoding),然后将这些数值转换为二进制代码,最后将二进制代码的每一位拆分为单独的特征列。
特点
将类别表示为二进制代码
特征数量 = log₂(n)(以2为底,n为类别数量)
介于One-hot和Label encoding之间的折中方案
特别适用于高基数分类特征
生活化案例
假设有8种冰淇淋口味,Binary encoding过程如下:
首先Label encoding:香草-0,巧克力-1,草莓-2,...,芒果-7
转换为二进制:0-000,1-001,2-010,...,7-111
拆分为单独的特征列:
香草:0,0,0
巧克力:0,0,1
草莓:0,1,0
...
芒果:1,1,1
代码实现
import pandas as pd
import category_encoders as ce
# 示例数据:大型分类变量
large_cat_data = pd.DataFrame({'Category': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J']})
# 创建 BinaryEncoder 实例
binary_encoder = ce.BinaryEncoder(cols=['Category'])
# 拟合并转换数据
binary_encoded = binary_encoder.fit_transform(large_cat_data)
print("\n原始分类数据:")
print(large_cat_data)
print("\nBinary 编码后的数据:")
print(binary_encoded)
优缺点分析
优点
大幅降低高基数特征的维度(相比One-hot)
保留了部分类别信息
比Label encoding保留了更多区分能力
适用于各种模型类型
缺点
实现相对复杂
解释性不如One-hot直观
对于类别数量不是2的幂的情况,可能仍有信息损失
编码技术对比
| 编码技术 | 特征数量 | 保留顺序 | 避免虚拟陷阱 | 适用场景 | 高基数适用性 | 示例 |
|---|---|---|---|---|---|---|
| One-hot | N | 否 | 否 | 无顺序分类变量,少量类别 | 差 | 颜色、性别 |
| Dummy | N-1 | 否 | 是 | 线性模型,少量类别 | 差 | 地区、品牌 |
| Effect | N-1 | 否 | 是 | 线性模型,方差分析 | 差 | 实验组别 |
| Label | 1 | 是(伪) | - | 树模型,任意基数 | 中 | ID类特征 |
| Ordinal | 1 | 是 | - | 有序分类变量 | 中 | 教育程度 |
| Count | 1 | 部分 | - | 高基数特征 | 优 | 城市、邮编 |
| Binary | log₂N | 部分 | - | 高基数特征 | 优 |
如何选择合适的编码技术
选择适当的编码技术取决于多个因素:
分类变量的性质
是否有内在顺序?(有序→Ordinal)
类别数量多少?(高基数→Count/Binary)
使用的模型类型
线性模型→Dummy/Effect encoding
树模型→Label/Ordinal encoding
神经网络→One-hot/Binary encoding
数据规模和计算资源
大数据集→避免One-hot(维度灾难)
有限资源→考虑Binary/Count encoding
业务需求和解释性
需要强解释性→One-hot/Dummy
更注重性能→Binary/Count
| 编码技术 | 数值关系风险 | 示例风险说明 |
|---|---|---|
| Ordinal | 高 | 博士(3)≠3×本科(1),只是顺序关系 |
| Label | 高 | 草莓(2)≠2×巧克力(1),只是随机编号 |
| One-hot | 无 | [0,1,0]与[1,0,0]无数值关系 |
| Count | 中 | 上海(120次)比北京(85次)多35次是实际计数 |