【大模型:知识库管理】--开源工具Ragflow介绍+本地搭建-CSDN博客
目录
1.启动ragflow
docker compose up -d
docker logs -f ragflow-server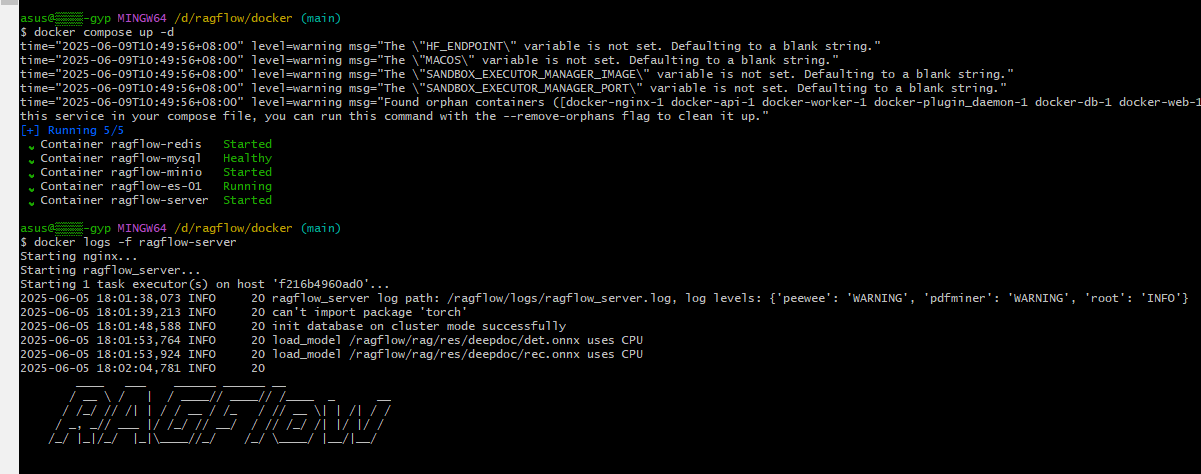
2.创建知识库
2.1.配置--切块方法
先配置:
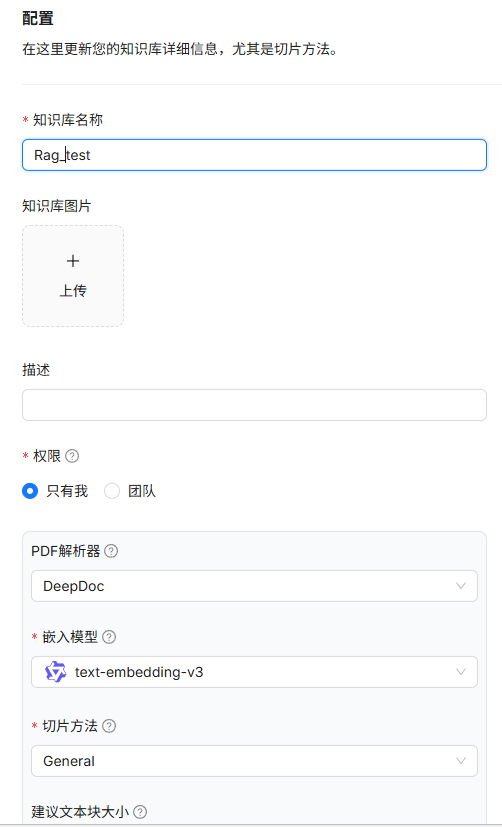
1.知识库名称:Rag_test
2.权限:只有我
3.PDF解析器:选用DeepDoc(Naive不好用)
4.嵌入模型:千问的![]()
5.切块方法:
| 模板 (Template) | 描述 (Description) | 文件格式 (File Formats) |
|---|---|---|
| 常规 (General) | 1.系统将使用视觉检测模型将连续文本分割成多个片段。 2.接下来,这些连续的片段被合并成Token数不超过“Token数”的块。 |
DOCX、XLSX、XLS (Excel 97-2003)、PPT、PDF、TXT、JPEG、JPG、PNG、TIF、GIF、CSV、JSON、EML、HTML |
| 问答 (Q&A) | 问答对,两列 | EXCEL, CSV/TXT |
简历(Resume) |
将简历解析为结构化数据 | DOCX、PDF、TXT |
| 手册 (Manual) | 使用最低的部分标题作为对文档进行切片的枢轴。 因此,同一部分中的图和表不会被分割, | |
| 表格 (Table) | 对于 csv 或 txt 文件,列之间的分隔符TAB。
|
EXCEL, CSV/TXT |
| 论文 (Paper) | LLM可以更好的概括论文中相关章节的内容, | |
| 书本 (Book) | 请为每本书设置页面范围, | DOCX, PDF, TXT |
| 法律 (Legal) | 使用文本特征来检测分割点 | DOCX, PDF, TXT |
| ppt (Presentation) | 每个页面都将被视为一个块。 并且每个页面的缩略图都会被存储。 | PDF, PPTX |
| (Tag) | 标签集独立存在,仅供其他知识库匹配使用。文件格式严格:XLSX 需两列无标题CSV/TXT 需 TAB 分隔 + 逗号分隔标签。 容错机制:非法格式数据自动跳过,避免污染标签集。 |
JPEG, JPG, PNG, TIF, GIF |
| 唯一 (one) | 整个文档被分成唯一块。 | DOCX, EXCEL, PDF, TXT |
2.2.上传知识库文件
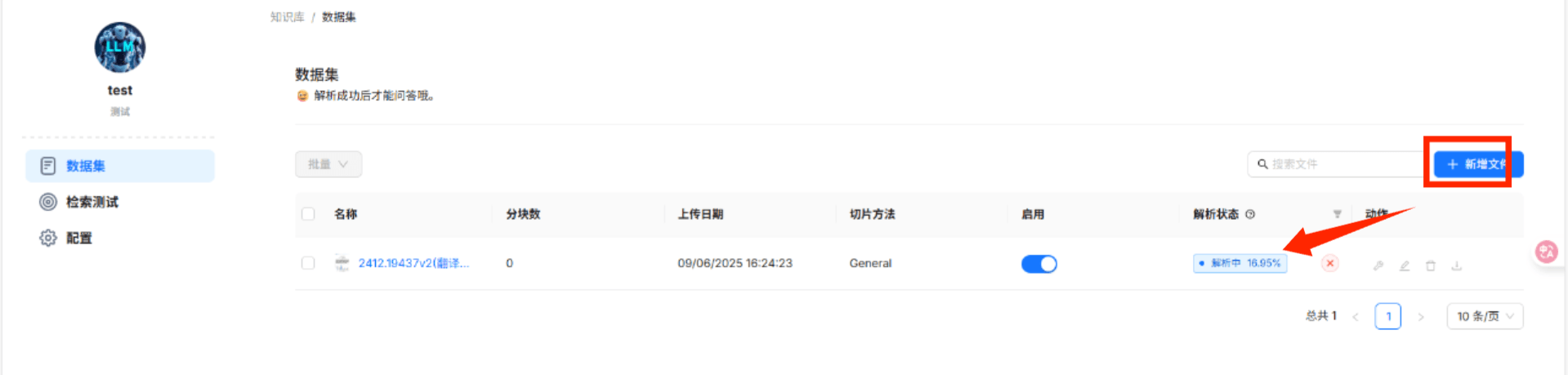
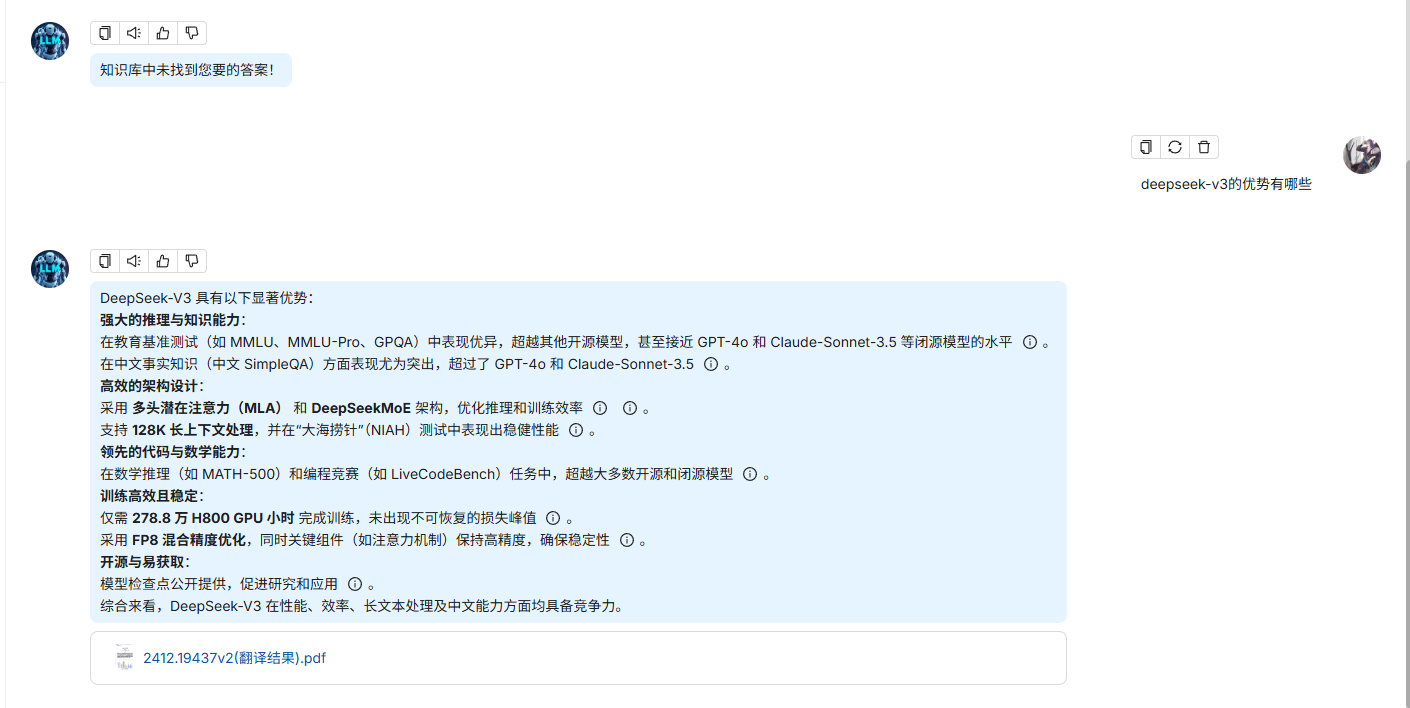
我i这里上传了deepseek-v3的论文翻译(53页),试试分快的情况。
鼠标放到进度条上面可以看到具体的解析过程:

等几分钟:
2.3.运行检索测试
RAGFlow 在其聊天中使用全文搜索和矢量搜索的多次调用。在设置 AI 聊天之前,请考虑调整以下参数以确保预期信息始终出现在答案中:
- 相似度阈值:相似度低于阈值的数据块将被过滤。默认设置为 0.2。
- 向量相似度权重:向量相似度占总分的百分比。默认设置为 0.3。
2.4.配置本地对话模型
在聊天页面增加一个聊天助手:
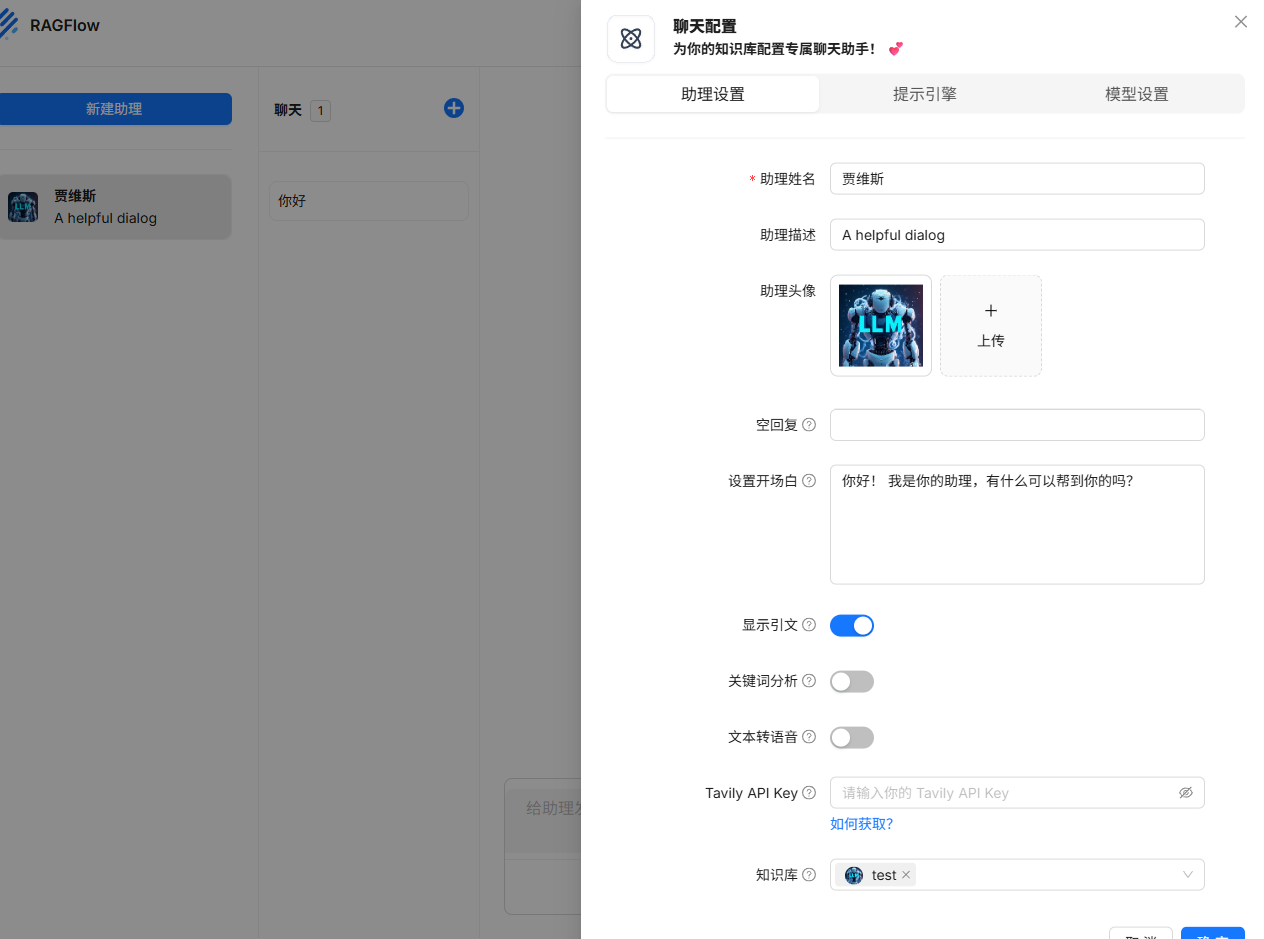
简单配置一下参数(可以使用默认)
默认提示词:
你是一个智能助手,请总结知识库的内容来回答问题,
请列举知识库中的数据详细回答。当所有知识库内容都与问题无关时,
你的回答必须包括“知识库中未找到您要的答案!”这句话。回答需要考虑聊天历史。
以下是知识库:
{knowledge}
以上是知识库。模型参数:
- Model :选择 Chat (对话) 模型。尽管您在系统模型设置中选择了默认聊天模型,但 RAGFlow 允许您为对话选择替代聊天模型,选择正确的对话模型十分重要,这个影响到系统能否正常运行,如果对话模型配置错误,将导致不能输出正确的对话内容。
- Freedom:指 LLM 即兴创作的级别。从 Improvise、Precise 到 Balance,每个自由度级别都对应于 Temperature、Top P、Presence Penalty 和 Frequency Penalty 的独特组合。
- Temperature: LLM 的预测随机性水平。值越高,LLM 的创意就越大。
- Top P:也称为“细胞核采样”,选用默认值即可。
- Max Tokens:LLM 响应的最大长度。请注意,如果此值设置得太低,则响应可能会减少。