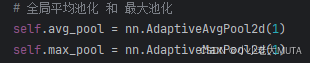
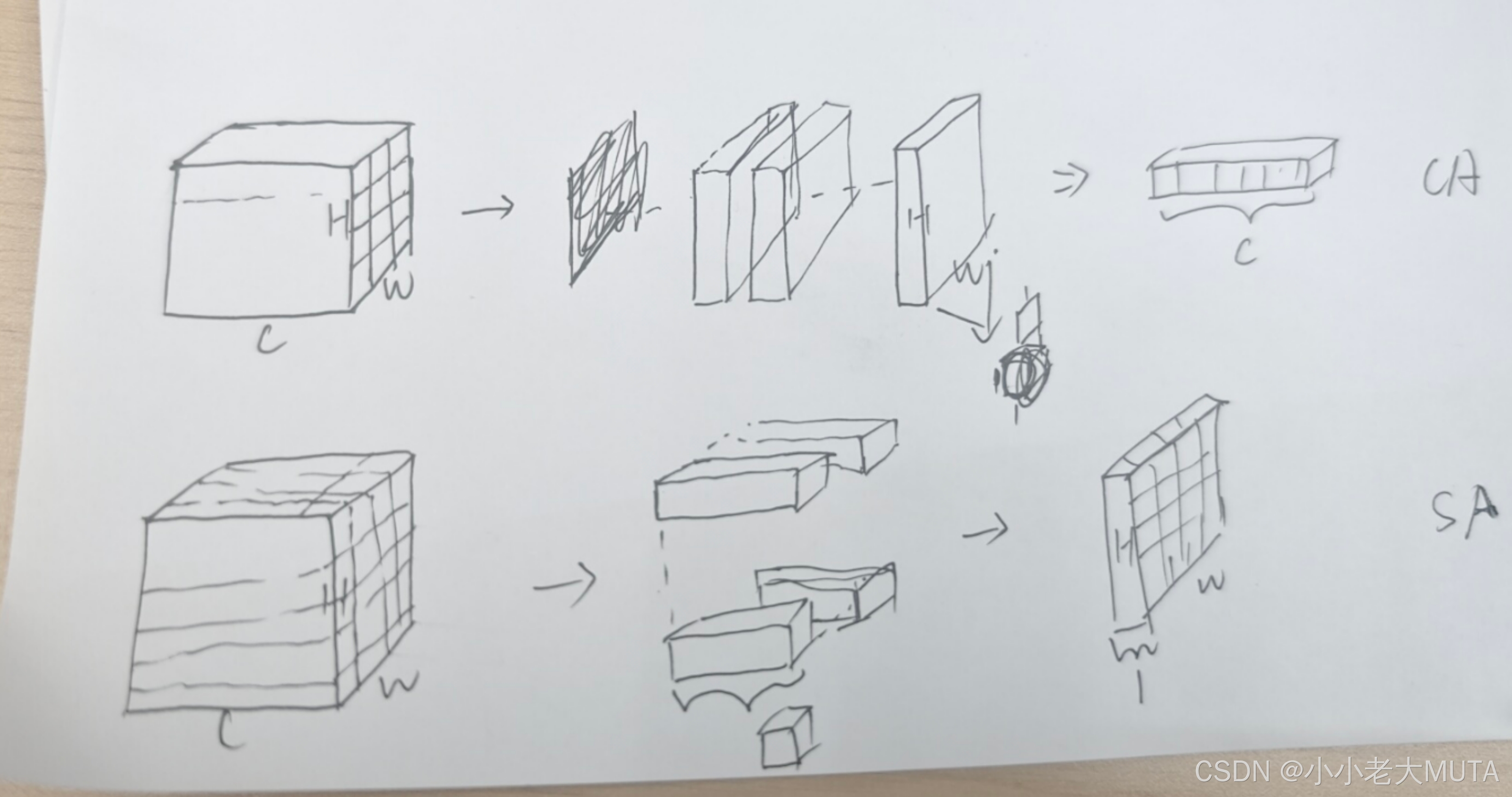
知识点:
空间注意力机制 spatial attention SA;
SA 中平均池化和最大池化的操作;
torch.max;
参考博客:通俗易懂理解通道注意力机制(CAM)与空间注意力机制(SAM)-CSDN博客
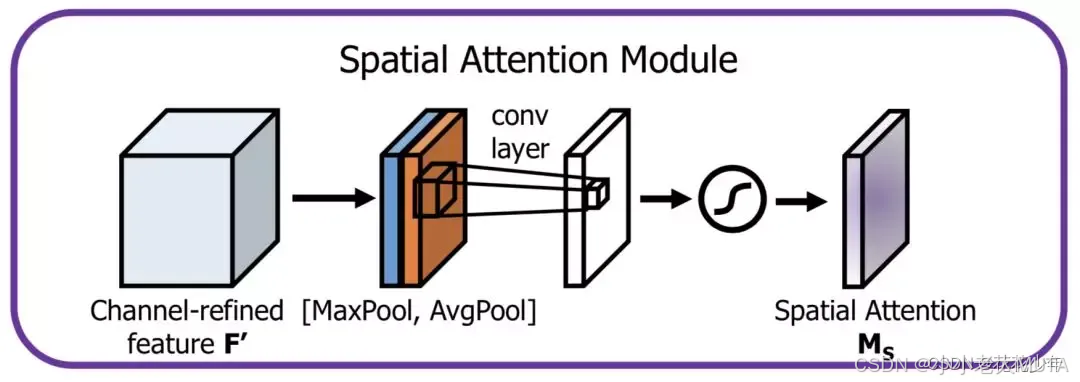

空间注意力机制代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class SpatialAttention(nn.Module):
def __init__(self,kernel_size=7):
"""
初始化空间注意力模块
Args:
kernel_size (int): 卷积核大小,通常为7x7
"""
super().__init__()
# 确保kernel_size是奇数,以便padding
assert kernel_size % 2 ==1
padding = kernel_size // 2
self.sigmoid = nn.Sigmoid()
# 定义7x7卷积层,输入通道为2(平均池化和最大池化的结果),输出通道为1
self.conv = nn.Conv2d(
in_channels=2, # 输入通道数为2(平均池化和最大池化的结果)
out_channels=1, # 输出通道数为1(生成空间注意力图)
kernel_size=kernel_size, # 卷积核大小,通常为7x7
padding=padding, # 填充,保持特征图大小不变
bias=False # 不使用偏置
)
def forward(self, x):
"""
前向传播
Args:
x (torch.Tensor): 输入特征图 [B, C, H, W]
Returns:
torch.Tensor: 经过空间注意力加权后的特征图
"""
# 沿着通道维度进行平均池化和最大池化
avg_pool = torch.mean(x, dim=1, keepdim=True) # F_avg^s [B,1,H,W]
# 注意这里返回值是两个,最大值和索引,要用两个参数接
max_pool,_ = torch.max(x, dim=1, keepdim=True) # F_max^s [B,1,H,W]
# 拼接平均池化和最大池化的结果
pooled_features = torch.cat((avg_pool, max_pool), dim=1) # [B,2,H,W]
# 通过 7 * 7 卷积层处理
spatial_attention = self.conv(pooled_features)
# sigmoid激活
spatial_attention = self.sigmoid(spatial_attention)
return x * spatial_attention
if __name__ == '__main__':
# 创建测试数据
batch_size=2
channels=3
height=64
width = 64
x = torch.randn(batch_size, channels, height, width)
sa=SpatialAttention(kernel_size=7)
outputs=sa(x)
print(f"input shape:{x.shape}")
print(f"output shape:{outputs.shape}")
沿通道维度的平均池化
avg_pool = torch.mean(x, dim=1, keepdim=True) # F_avg^s [B,1,H,W]沿通道维度的最大池化
max_values, _ = torch.max(x, dim=1, keepdim=True) # F_max^s [B,1,H,W]注意这里返回是两个值,最大值索引也返回了,必须要用两个参数接!!!
vs 通道注意力机制中的池化操作