更多精彩,详见文末~~~
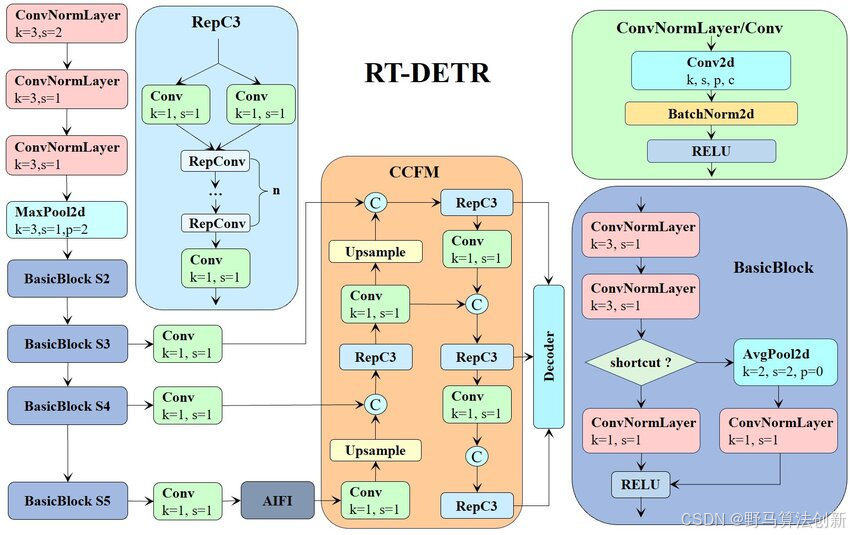
在目标检测的高速发展中,RT-DETR作为DETR(DEtection TRansformer)的高效变体,凭借其优异的性能和较快的推理速度,已经成为许多实际应用中的首选算法。然而,尽管RT-DETR在精度和效率上有了显著提升,但在实际应用中依然面临一些挑战和瓶颈。那么,如何在现有RT-DETR的基础上进行创新和改进,进一步提升其性能呢?今天,我们将从多个角度探讨如何对RT-DETR进行优化,突破现有局限,迎接更广泛的应用场景。
痛点一:推理速度瓶颈——如何加速推理?
尽管RT-DETR相比传统DETR在推理速度上已经有了显著改进,但在一些对实时性要求极高的场景(如自动驾驶、安防监控等),其推理速度仍显得不足够快。那么,如何进一步加速推理过程呢?
创新方向:轻量化网络设计
RT-DETR的推理速度瓶颈很大程度上来自其庞大的网络结构和计算复杂度。为了解决这一问题,可以通过以下创新方向进行优化:
网络剪枝:通过去除冗余的网络层和参数,减少计算量。尤其是在Transformer结构中的多头自注意力层,可以采用剪枝算法去除对结果贡献较小的头,从而加快推理速度。
量化与低精度计算:将模型权重从32位浮点数减少到16位甚至8位,这不仅能减小模型大小,还能加速推理过程,尤其适用于边缘设备。
卷积与Transformer结合:在RT-DETR中引入轻量级卷积神经网络(CNN)来进行特征提取,减少Transformer的计算负担。通过CNN进行初步的特征提取后,再将这些特征送入Transformer进行细化,可以大大提升模型的推理效率。
痛点二:小物体检测能力不足——如何提升小物体检测精度?
虽然RT-DETR在大物体检测上表现出色,但在小物体的检测精度上,仍然存在一定差距。传统DETR和RT-DETR对于小物体的定位和识别常常不尽如人意,这主要是因为小物体的特征较为模糊,且相较于大物体占据图像的像素较少,容易被忽略。
创新方向:引入多尺度特征融合
为了提升小物体的检测能力,可以采用以下几种创新方法:
多尺度特征融合:在RT-DETR中引入多尺度特征图,结合不同尺度的卷积层和自注意力机制,将不同层次的信息进行融合。这能帮助模型更好地捕捉小物体的细节,从而提升对小物体的检测能力。
注意力机制优化:优化自注意力机制,使其能够更加关注图像中的小物体区域,减少大物体对特征学习的干扰。可以通过调整注意力计算方式,使得对小物体的注意力分配更加集中,提高小物体的召回率。
生成锚框机制的创新:改进RT-DETR的锚框设计,使用更加动态和灵活的锚框机制,使得模型能够适应不同尺度的目标,尤其是小物体的检测。
痛点三:内存消耗高——如何优化内存使用?
在处理大规模数据集时,RT-DETR可能面临较高的内存消耗问题,尤其是在高分辨率图像或复杂的场景下,模型的计算需求和内存占用都可能达到瓶颈。
创新方向:内存优化技术
梯度累积与分布式训练:采用梯度累积技术,将多个小批次合并为一个大批次进行训练,从而减少每次训练时所需的内存。对于大规模数据集,可以结合分布式训练框架,将训练任务分配到多个设备上,进一步减少单个设备的内存压力。
内存映射优化:通过内存映射(memory-mapping)技术优化数据加载过程,避免在训练时将整个数据集加载到内存中,从而减少内存消耗。
痛点四:缺乏跨任务能力——如何提升多任务处理能力?
目前,RT-DETR虽然在目标检测中表现出色,但在多任务学习(如同时进行目标检测与目标跟踪、语义分割等任务)上,还存在一定的局限性。为了适应更多应用场景,RT-DETR需要具备更强的跨任务能力。
创新方向:多任务学习框架
联合优化目标函数:通过引入多任务学习框架,将目标检测与其他任务(如目标跟踪、语义分割)联合训练,利用共享的特征表示提高模型的泛化能力。
任务相关注意力机制:设计多任务相关的注意力机制,使得模型能够在不同任务间共享知识,提高多任务学习的效率。