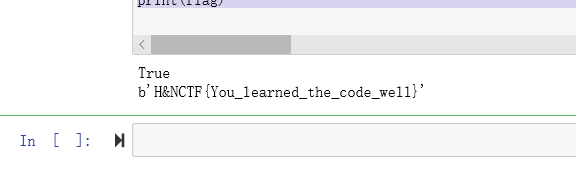
还是学了非常多的知识的,有待进步与提升
Misc:
芙宁娜的图片
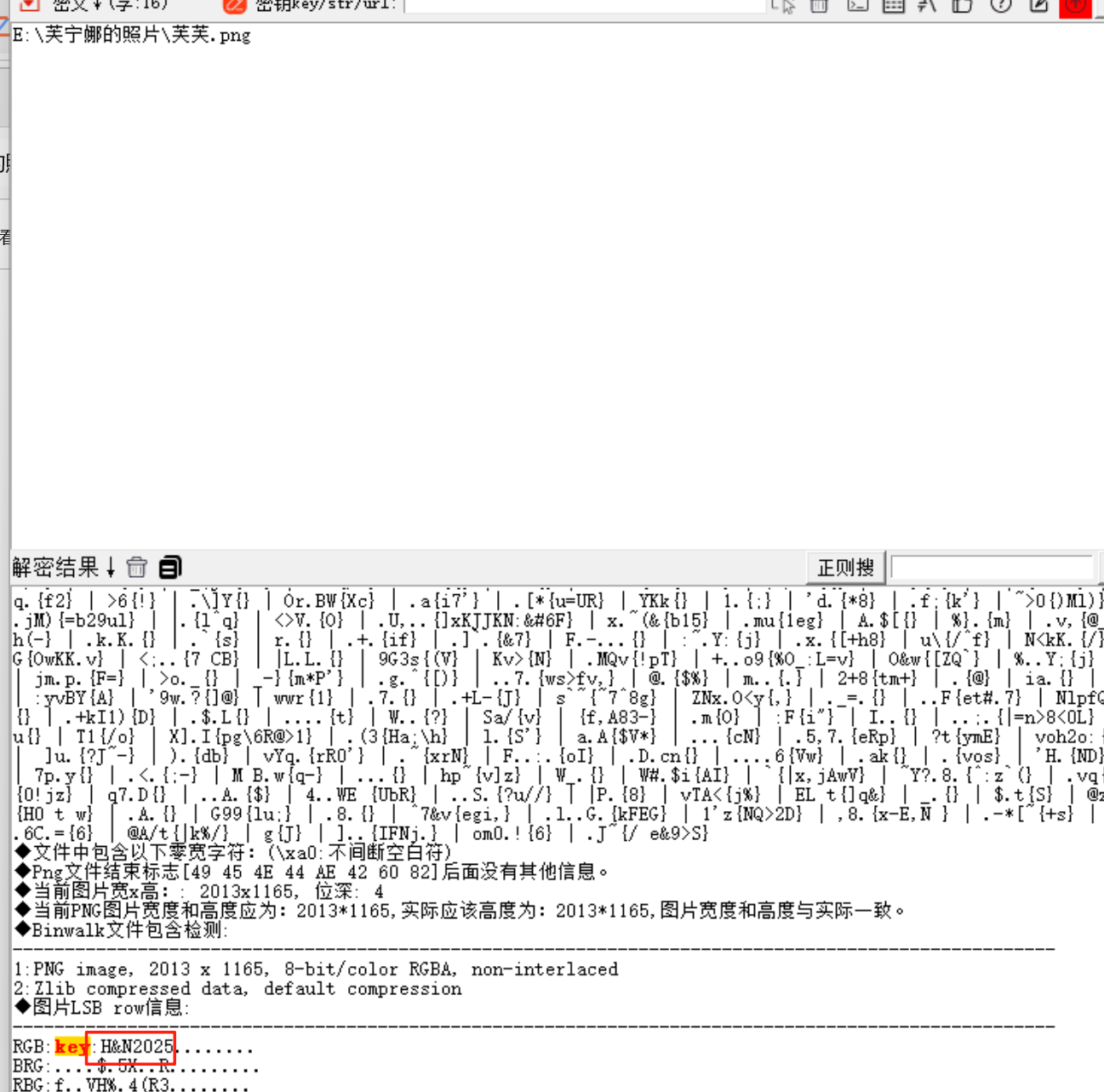
给了文档和图片,图片lsb藏了一个key,随波逐流直接梭出来
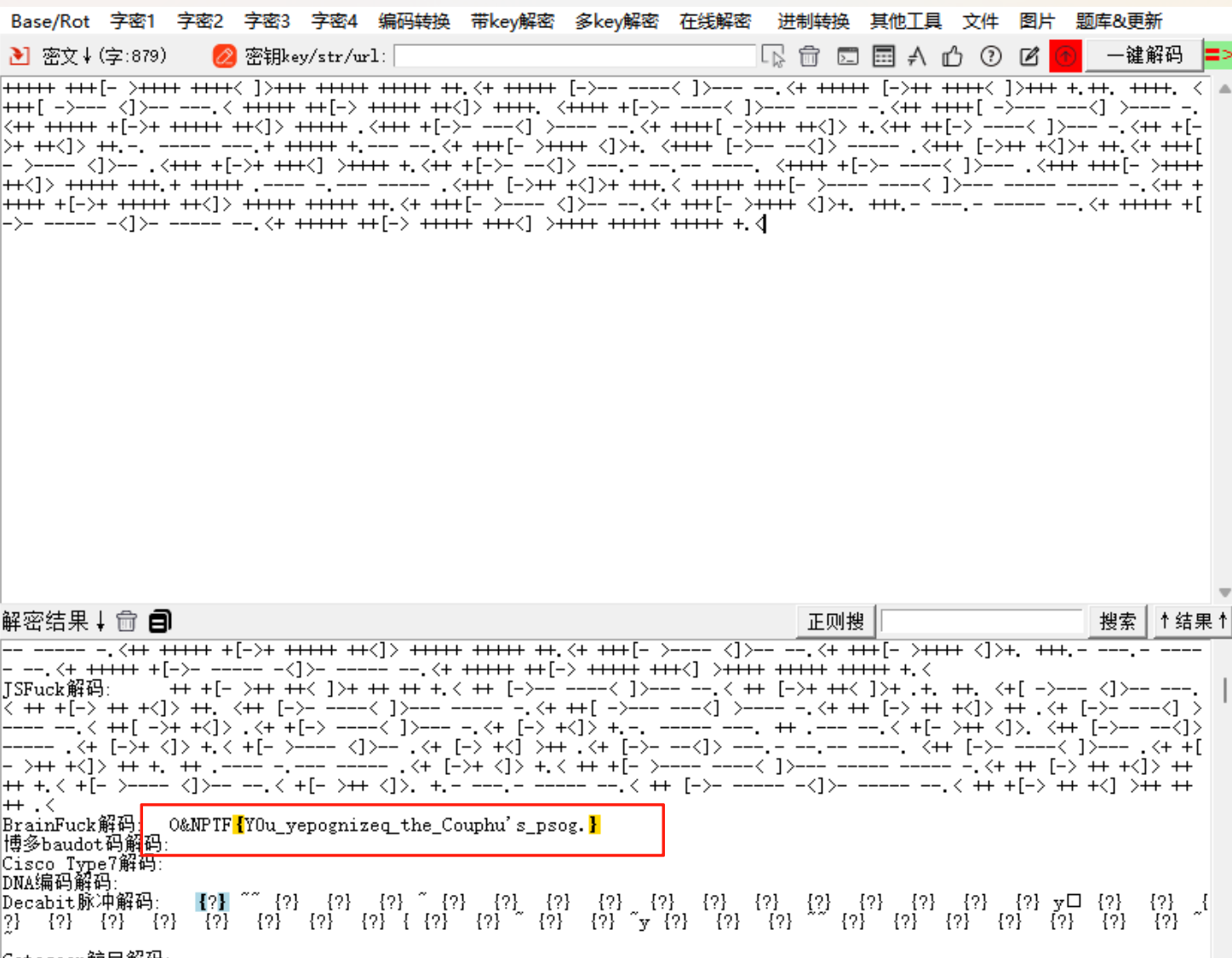
文档内容brainfuck得到一个加密后的flag
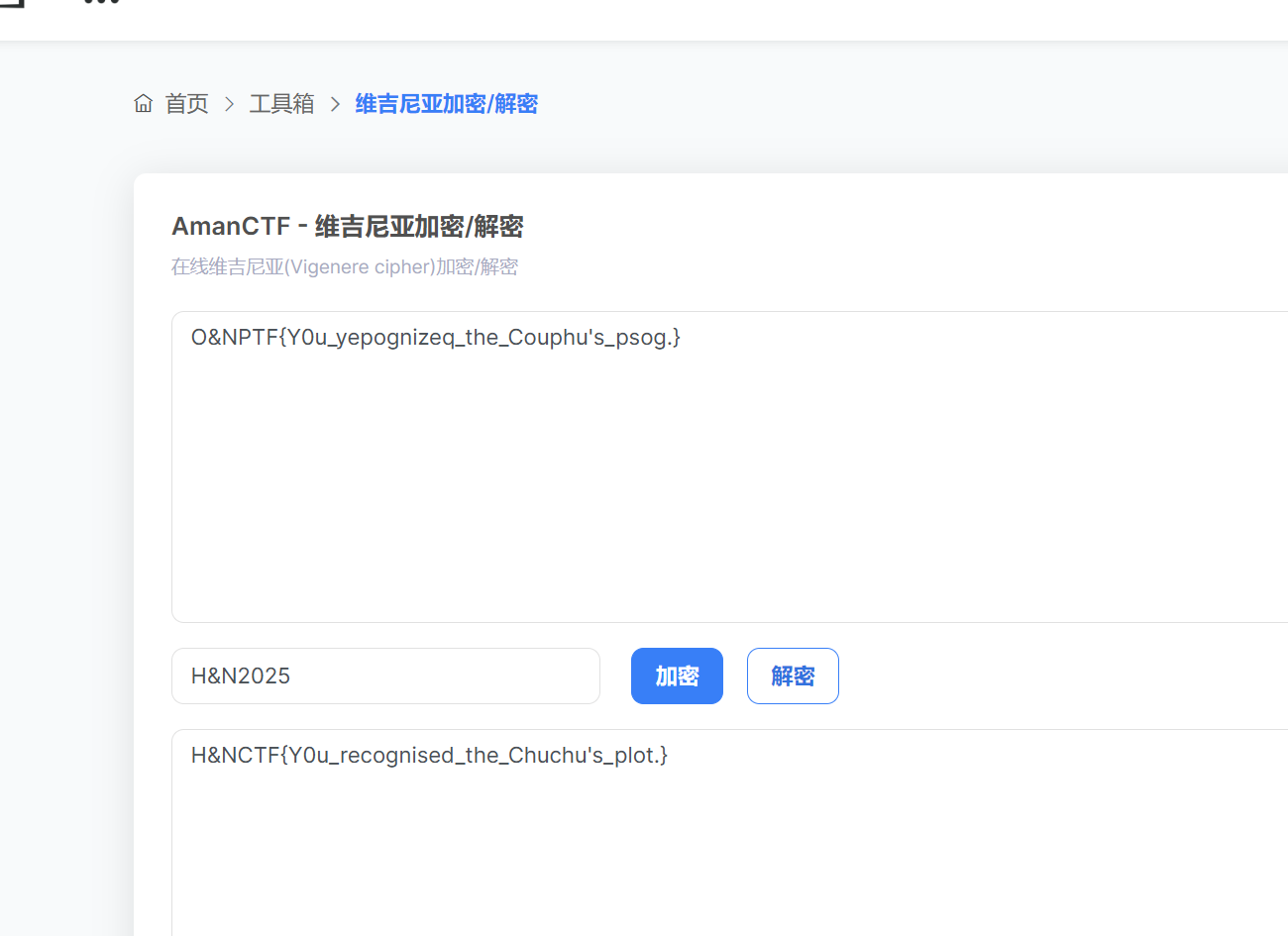
用key和加密后的flag进行维吉尼亚加密或者一把梭不行
注:为什么知道是维吉尼亚呢,因为看到了又flag{}的雏形了,非常像凯撒密码,但是图片提供了各key,所以很容易想到是维吉尼亚密码辣
好像只能用bugku的维吉尼亚解密
维吉尼亚加密/解密 - Bugku CTF平台
我用千千秀字和其他解密网站不行
星辉骑士
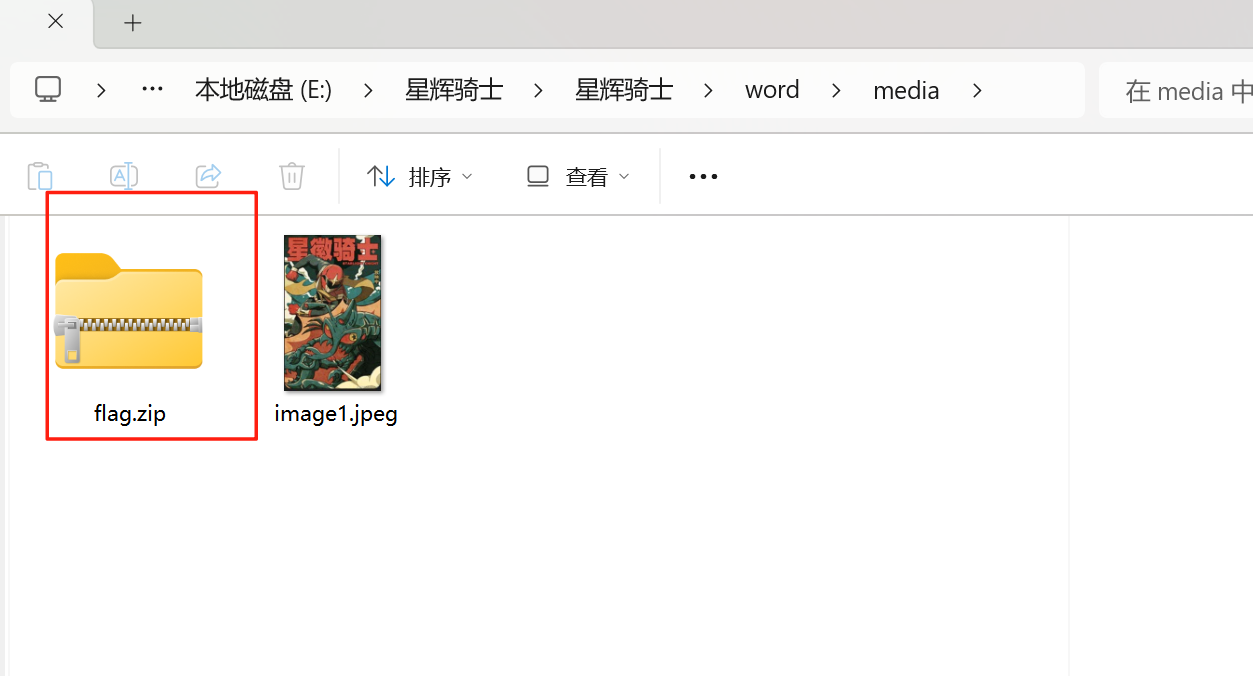
给了一个word文档,一张图片,没有发现什么信息,将其后缀改位zip
解压看到一个flag.zip
解压,发现需要密码
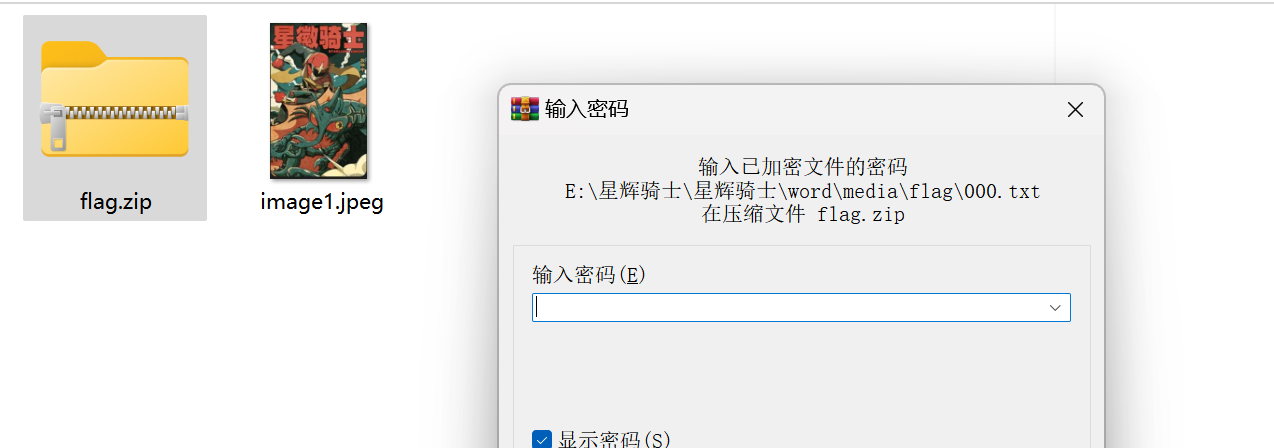
这时就要看看是真加密还是伪加密了
拖入010 editor
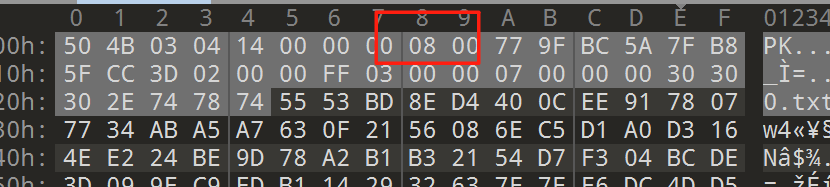
是伪加密了
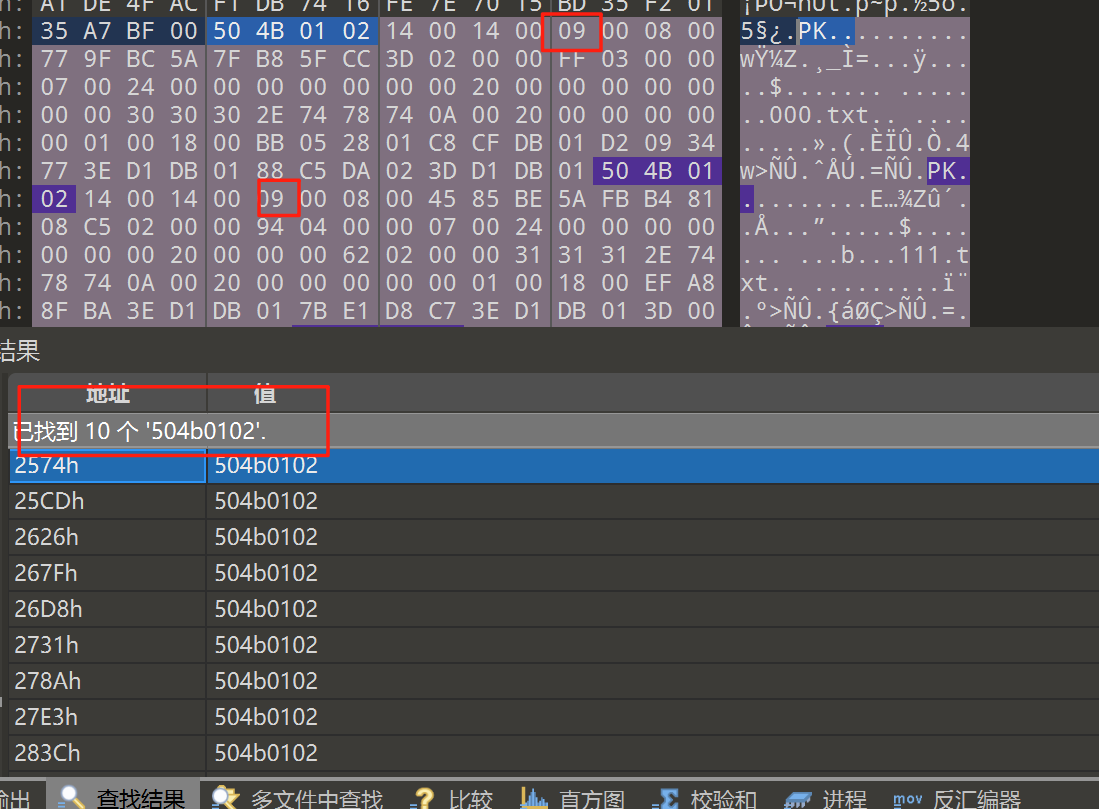
把十个09都改了改为偶数00
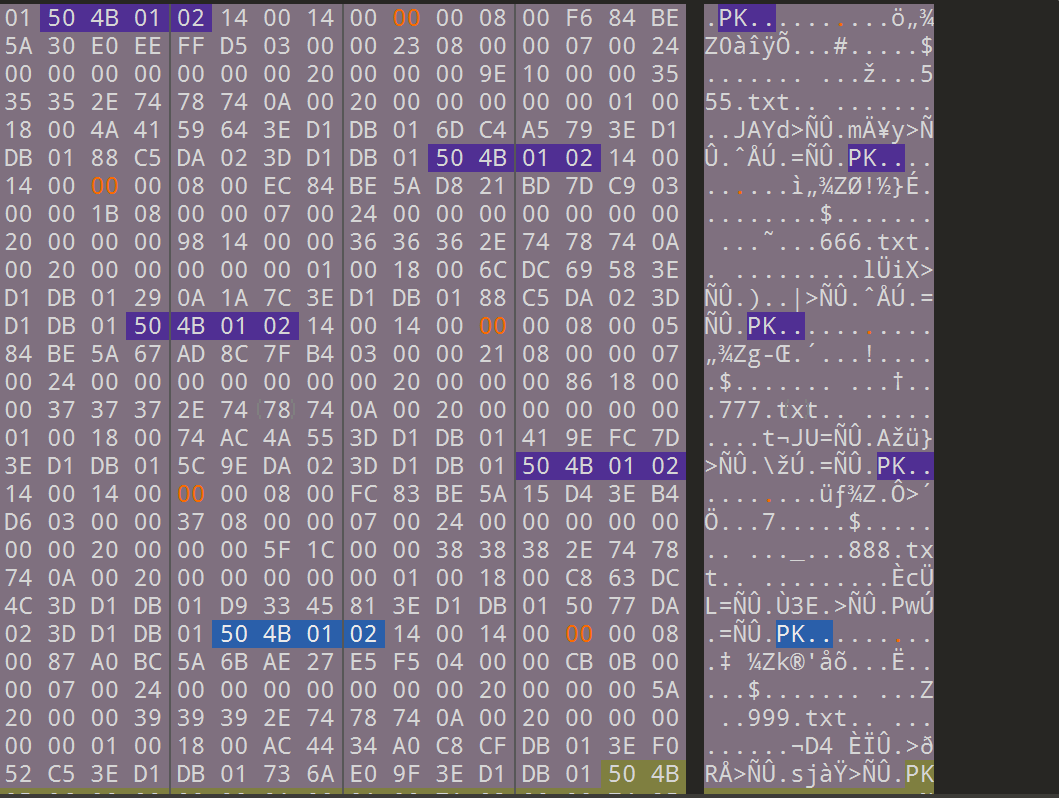
改了之后,保存,解压
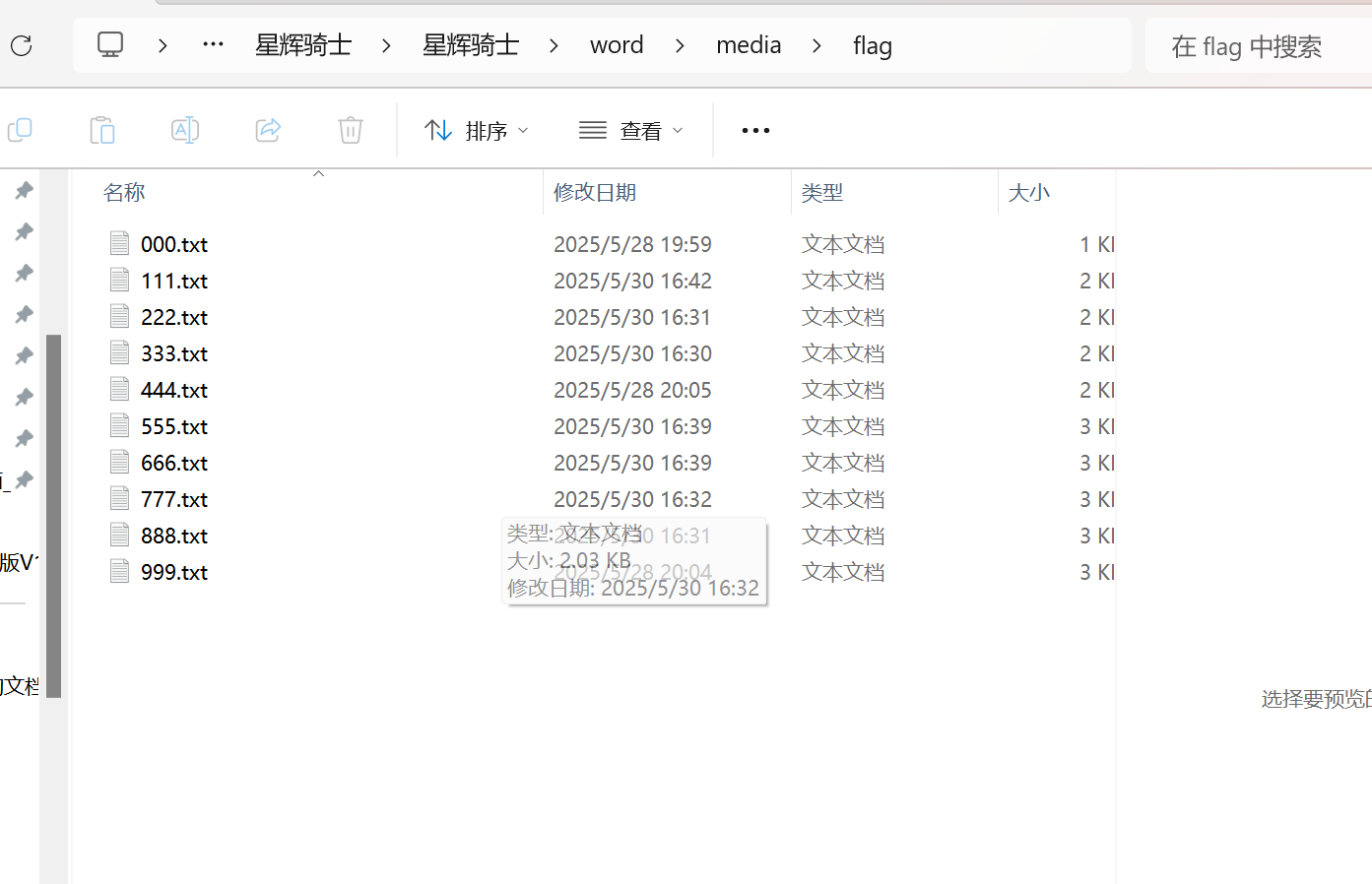
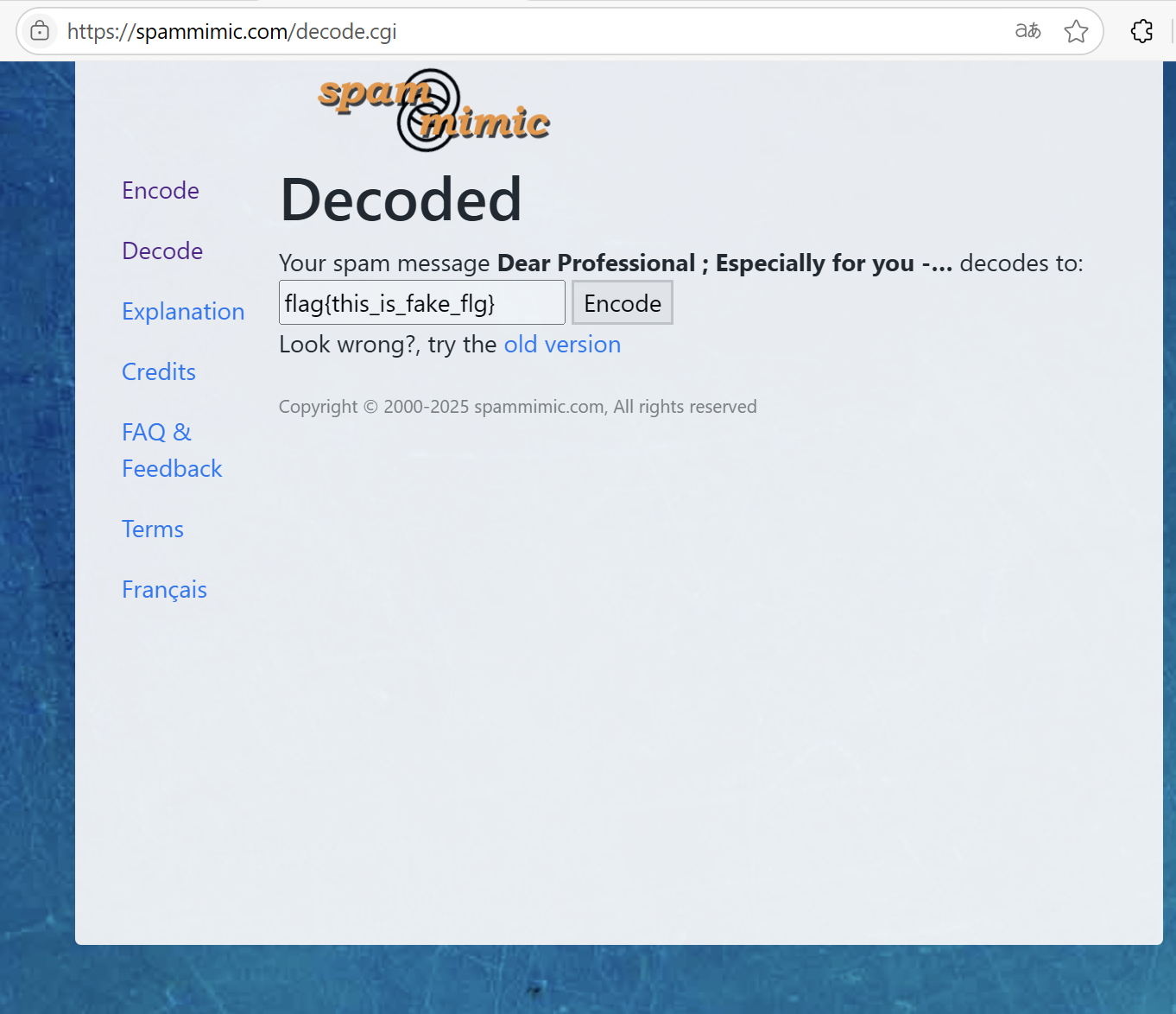
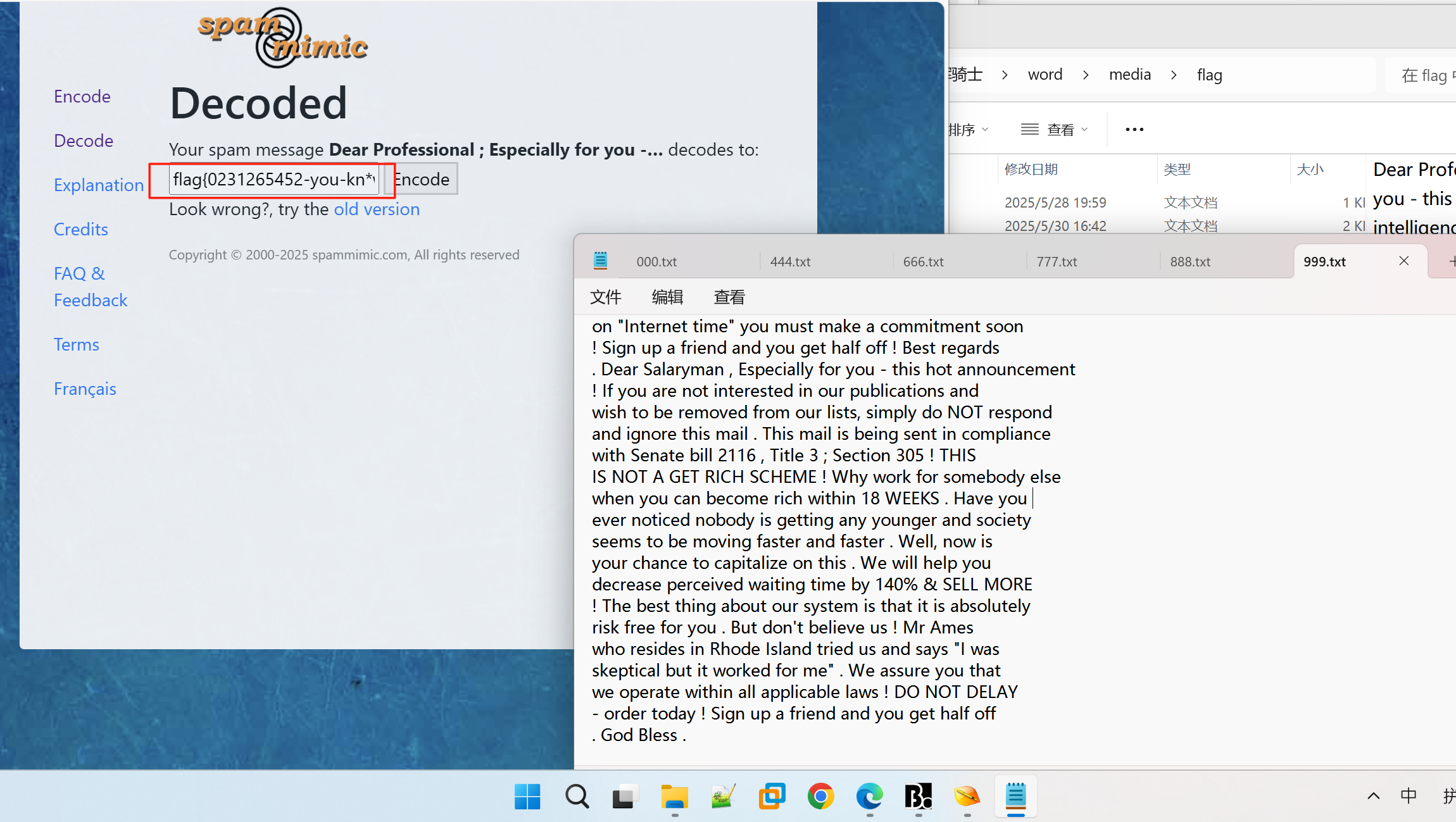
解压得到一堆文档,打开可以看到是垃圾邮件隐写
一个一个文档进行解密,还有假flag!
 乱成一锅粥了
乱成一锅粥了
题目附件是一个流量包
初见端倪

再往下翻翻
一共有9个zip
 导出字节流都解压
导出字节流都解压
txt文件内容类似base64编码,将其合并一起发现解码出来是乱码,所以想到可能是顺序不对,又注意到,文件命名类似hash值
注:解压发现每个压缩包里都有50个txt文档,而且命名都一样
解密发现是数字,猜测md5解密后的内容在00-50之间,这样就可以按照序号拼接了
用ai帮我们把脚本写出来
import os
import hashlib
def generate_md5_mapping():
"""生成00到50的数字与其MD5值的映射关系"""
mapping = {}
for i in range(0, 51): # 包括50,所以是0-50共51个文件
# 格式化为两位数字符串:00, 01, ..., 50
original_name = f"{i:02d}"
# 计算MD5值
md5_hash = hashlib.md5(original_name.encode('utf-8')).hexdigest()
# 添加到映射表
mapping[md5_hash] = original_name
return mapping
def rename_files(folder_path, mapping):
"""根据映射表重命名文件"""
for md5_name in os.listdir(folder_path):
if md5_name.endswith('.txt'):
# 提取MD5部分(不含扩展名)
md5_key = os.path.splitext(md5_name)[0]
if md5_key in mapping:
original_name = mapping[md5_key]
new_filename = f"{original_name}.txt"
# 构建完整文件路径
old_path = os.path.join(folder_path, md5_name)
new_path = os.path.join(folder_path, new_filename)
# 重命名文件
os.rename(old_path, new_path)
print(f"成功重命名: {md5_name} -> {new_filename}")
else:
print(f"警告: 未找到映射 {md5_name} - 可能超出00-50范围")
if __name__ == "__main__":
# 使用原始字符串避免转义问题
folder_path = r"E:\粥\Down"
# 生成MD5映射表 (00-50)
md5_mapping = generate_md5_mapping()
# 执行重命名操作
rename_files(folder_path, md5_mapping)
print("\n操作完成! 所有文件已恢复为原始数字名称")
print(f"共处理文件: {len(md5_mapping)}个 (00-50)")
将文件内容按照01到50合并在一起
import os
def combine_files(folder_path, output_file):
"""将01.txt到50.txt的文件内容按顺序合并"""
# 确保输出文件路径正确
output_path = os.path.join(folder_path, output_file)
# 创建01-50的文件名列表
file_names = [f"{i:02d}.txt" for i in range(1, 51)]
# 按顺序合并文件内容
with open(output_path, 'w', encoding='utf-8') as outfile:
for filename in file_names:
file_path = os.path.join(folder_path, filename)
# 检查文件是否存在
if not os.path.exists(file_path):
print(f"警告: 文件 {filename} 不存在,跳过")
continue
# 读取并写入内容
with open(file_path, 'r', encoding='utf-8') as infile:
content = infile.read()
outfile.write(content)
# 可选:在文件之间添加分隔符
# outfile.write("\n\n--- 文件分割线 ---\n\n")
print(f"\n合并完成! 所有内容已保存到: {output_path}")
print(f"共合并了 {len(file_names)} 个文件 (01.txt - 50.txt)")
if __name__ == "__main__":
# 配置路径
folder_path = r"E:\粥\Down" # 包含01-50.txt的文件夹
output_file = "combined_content.txt" # 合并后的文件名
# 执行合并
combine_files(folder_path, output_file)
将其base64解码,发现是一张图片
都转码得到9张图片,将其拼接得到二维码

扫一扫就能得到flag了
谁动了黑线
待定
OSINT
时间图片属性都有
Chasing Freedom 1
可以看到船号是闽平渔65599,而且识图可以知道大概位置

是平潭岛蓝眼泪的位置
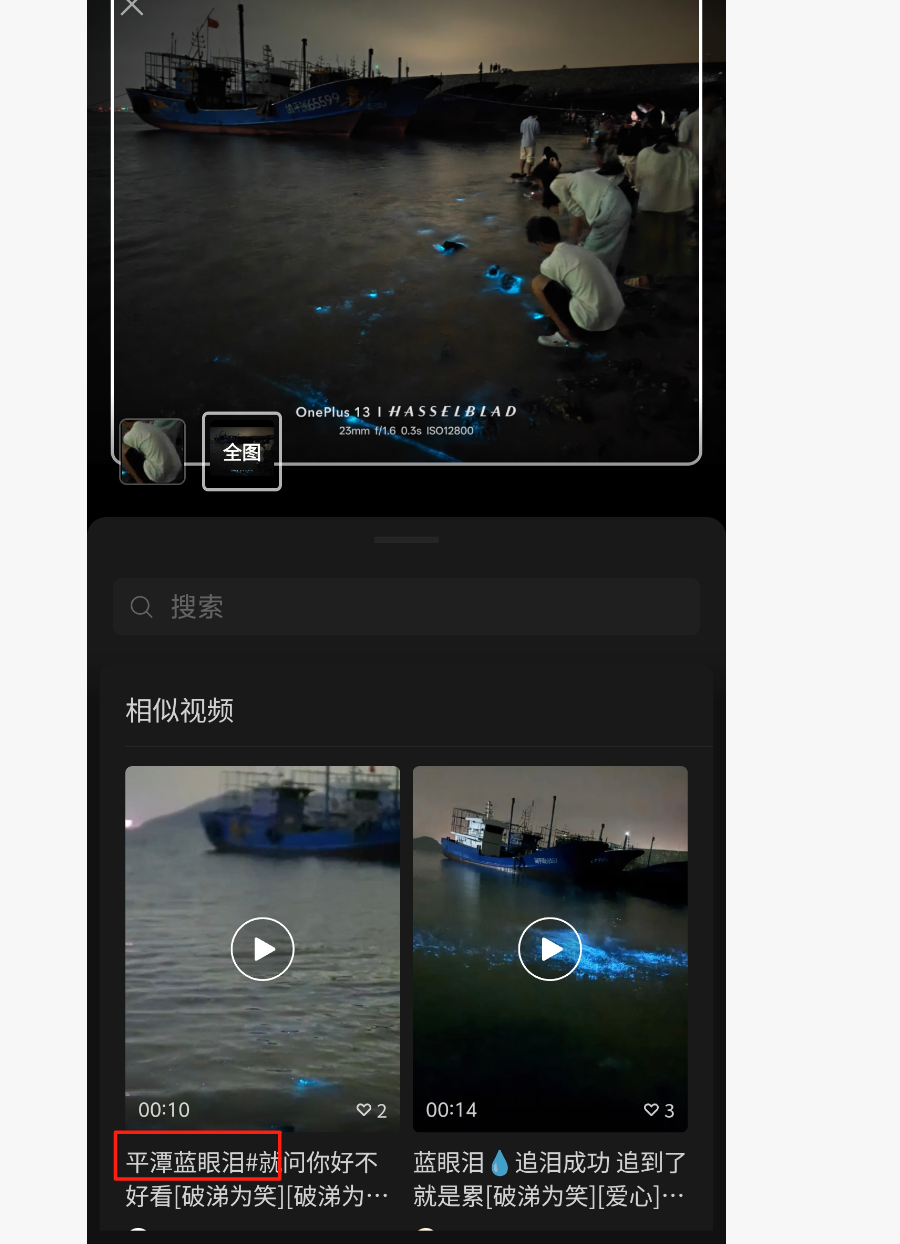
搜这个渔船停在那里
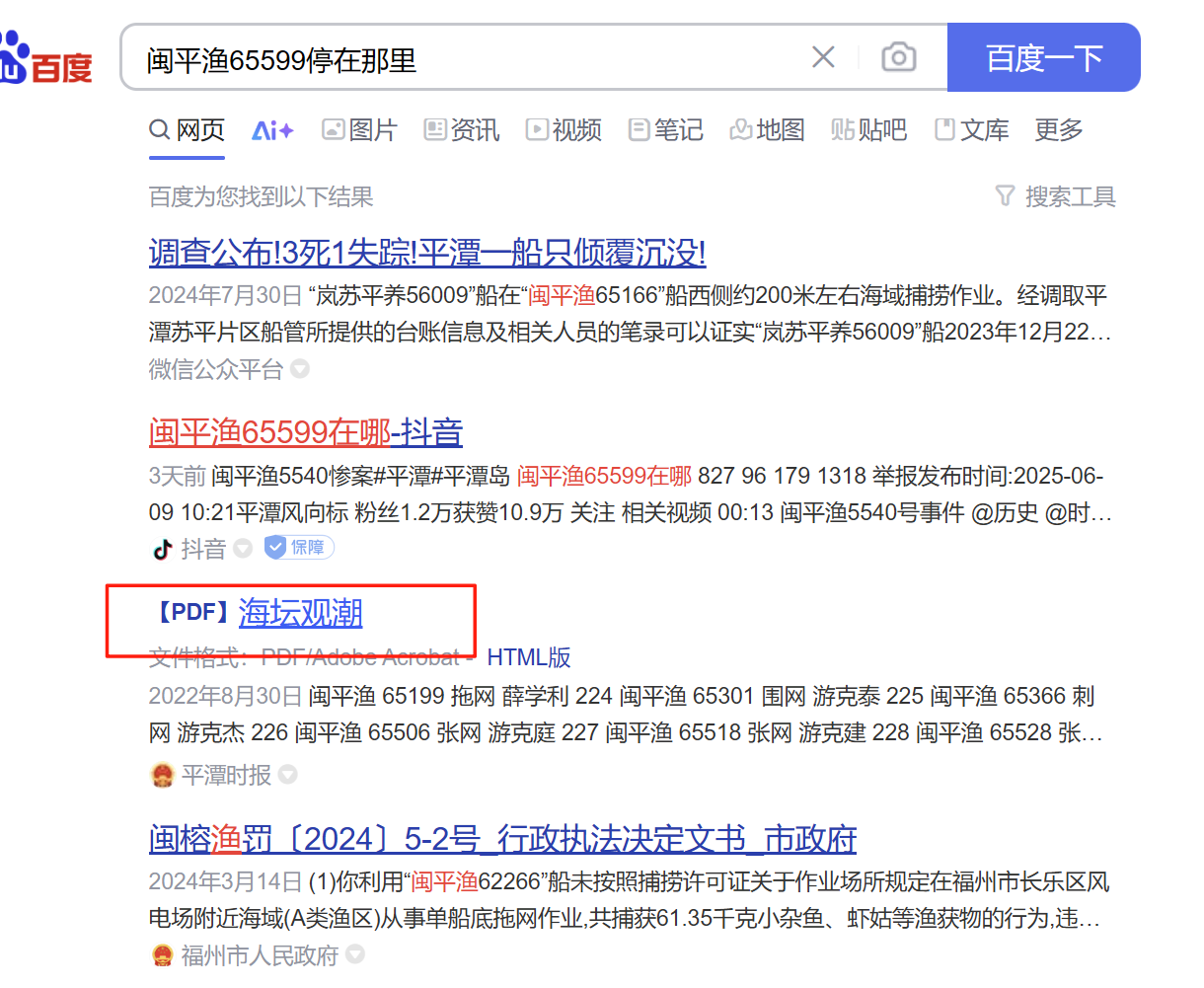
点开海坛观潮,搜船号

再高德地图搜索地址,全都试了一遍,最后试了一遍丁鼻垄就对了......
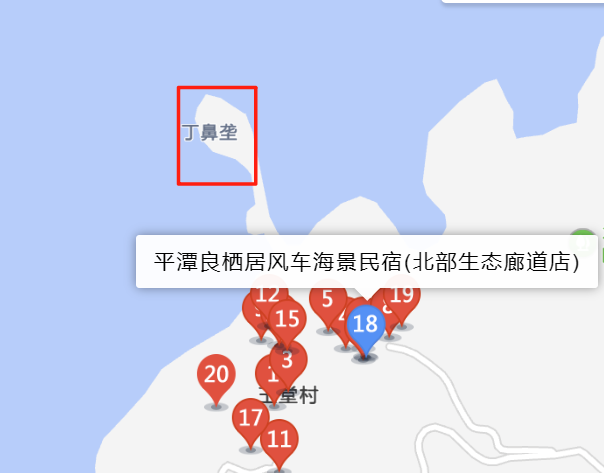
H&NCTF{0503-丁鼻垄}
Chasing Freedom 2

用小红书登app都行识图
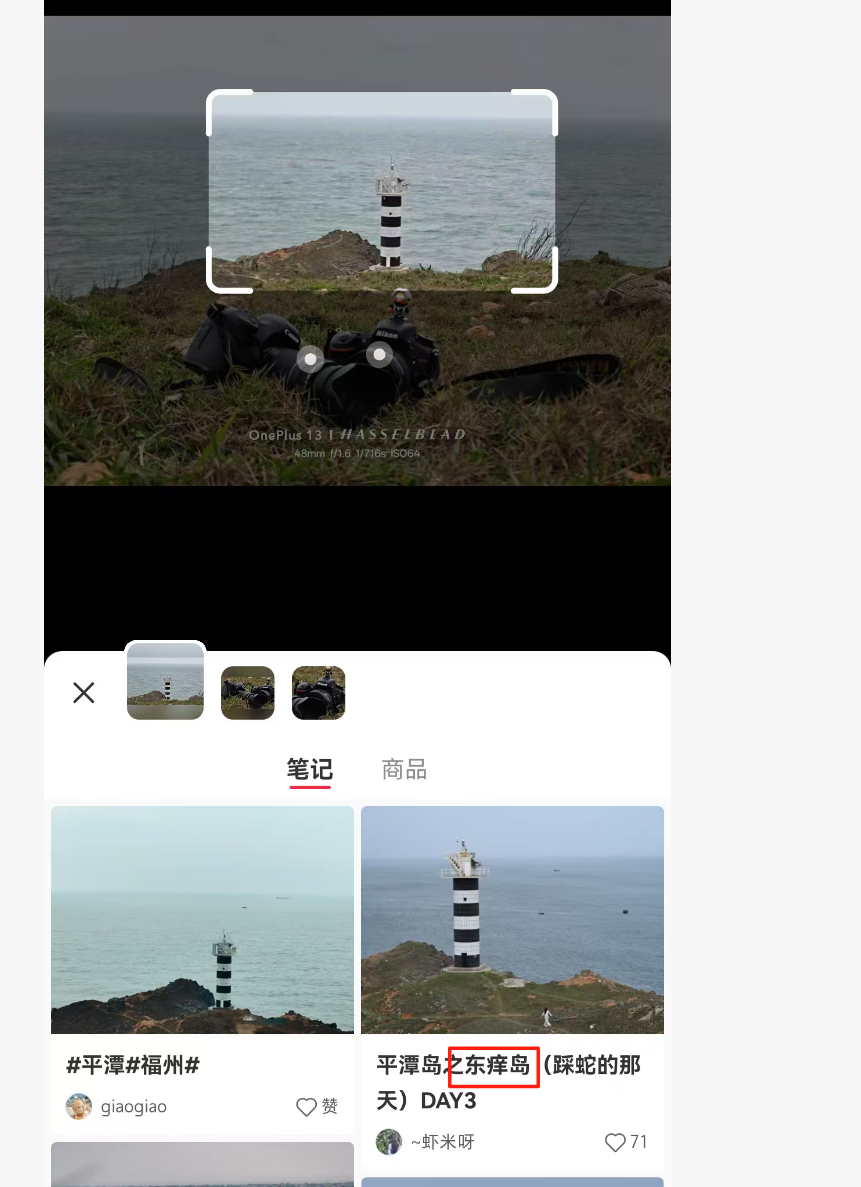
输进去不对加一个灯塔就提交成功了
H&NCTF{0504-东庠岛灯塔}
Chasing Freedom 3

直接搜“岚庠渡 码头”

一号不对二号三号枚举一下就可以了
H&NCTF{0504-流水码头-岚庠渡3号}
猜猜我在哪儿?
待定
CRYPTO
哈基coke
猫脸
import numpy as np
import cv2
def arnold_decode(image, shuffle_times, a, b):
""" Arnold inverse shuffle for rgb image """
# 确保图像是numpy数组格式
if isinstance(image, str):
image = cv2.imread(image)
# 创建输出图像数组
decoded_image = np.zeros_like(image, dtype=np.uint8)
h, w = image.shape[0], image.shape[1]
N = h
for time in range(shuffle_times):
for new_x in range(h):
for new_y in range(w):
# 逆变换
ori_x = ((a*b + 1) * new_x - b * new_y) % N
ori_y = (-a * new_x + 1 * new_y) % N
decoded_image[ori_x, ori_y, :] = image[new_x, new_y, :]
image = decoded_image.copy()
# 确保图像数据是8位无符号整数
decoded_image = np.clip(decoded_image, 0, 255).astype(np.uint8)
cv2.imwrite('decoded_flag.png', decoded_image, [int(cv2.IMWRITE_PNG_COMPRESSION), 0])
return decoded_image
# 使用示例
if __name__ == "__main__":
img_path = 'en_flag.png' # 替换为加密后的图像路径
decoded_img = arnold_decode(img_path, 6, 9, 1)
print("解密完成,结果已保存为 decoded_flag.png")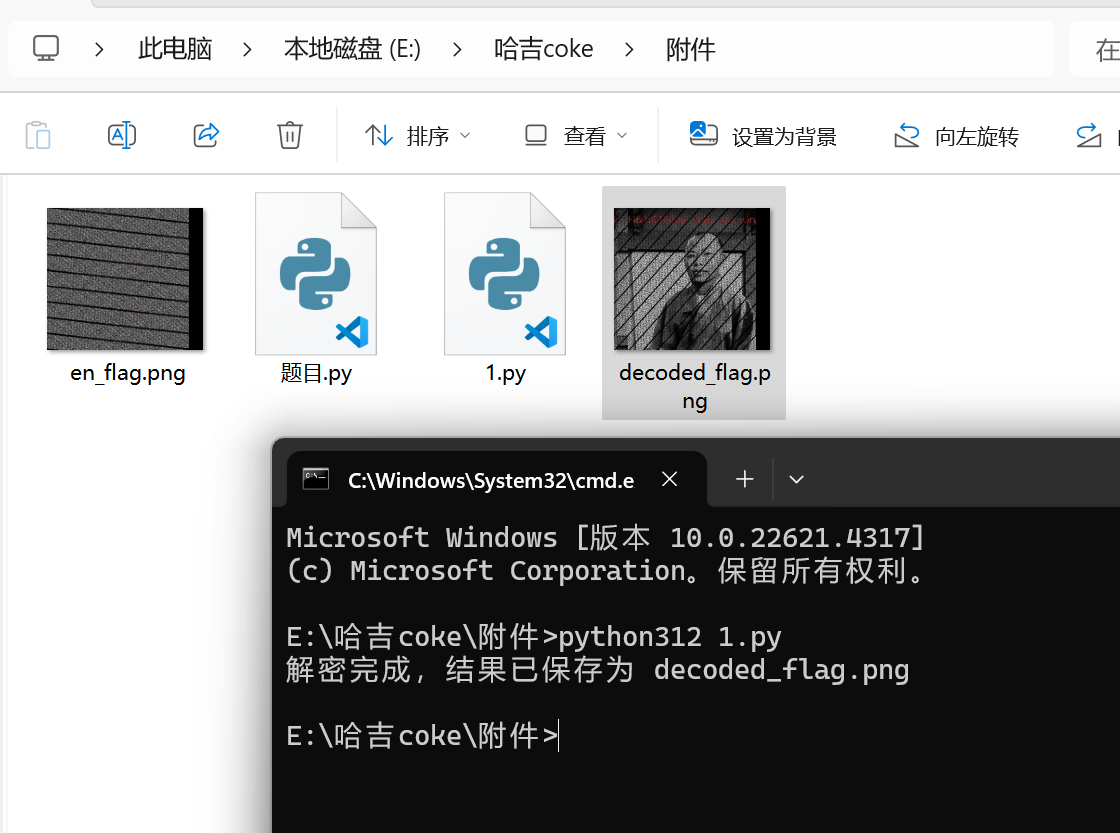

lcgp
恢复 LCG 参数
a, b, m(模数、乘数、增量)反推出初始种子
cc(满足cc = 2024^flag mod n)求离散对数
flag = log₍₂₀₂₄₎cc mod n还原原始 flag 字符串
from sage.all import *
from Crypto.Util.number import long_to_bytes, GCD, isPrime
# 给定 LCG 输出序列
c = [11250327355112956284720719987943941825496074893551827972877616718074592862130806975889275745497426515405562887727117008818863728803549848574821067056997423443681347885027000632462241968640893471352200125748453396098854283137158609264944692129301617338233670002547470932851350750870478630955328653729176440142198779254117385657086615711880537380965161180532127926250520546846863536247569437, 1289730679860726245234376434590068355673648326448223956572444944595048952808106413165882424967688302988257332835229651422892728384363094065438370663362237241013242843898967355558977974152917458085812489310623200114007728021151551927660975648884448177346441902806386690751359848832912607313329587047853601875294089502467524598036474193845319703759478494109845743765770254308199331552085163360820459311523382612948322756700518669154345145757700392164795583041949318636, 147853940073845086740348793965278392144198492906678575722238097853659884813579087132349845941828785238545905768867483183634111847434793587821166882679621234634787376562998606494582491550592596838027522285263597247798608351871499848571767008878373891341861704004755752362146031951465205665840079918938797056361771851047994530311215961536936283541887169156535180878864233663699607369701462321037824218572445283037132205269900255514050653933970174340553425147148993214797622395988788709572605943994223528210919230924346860415844639247799805670459, 7426988179463569301750073197586782838200202717435911385357661153208197570200804485303362695962843396307030986052311117232622043073376409347836815567322367321085387874196758434280075897513536063432730099103786733447352512984165432175254784494400699821500026196293994318206774720213317148132311223050562359314735977091536842516316149049281012797103790472349557847649282356393682360276814293256129426440381745354969522053841093229320186679875177247919985804406150542514337515002645320320069788390314900121917747534146857716743377658436154645197488134340819076585888700553005062311578963869641978771532330577371974731136, 10389979373355413148376869524987139791217158307590828693700943753512488757973725227850725013905113587408391654379552713436220790487026223039058296951420273907725324214990441639760825661323514381671141482079783647253661594138658677104054180912818864005556386671430082941396497098166887200556959866845325602873713813206312644590812141400536476615405444030140762980665885244721798105034497461675317071497925846844396796854201566038890503298824928152263774446268093725702310124363765630370263370678902342200494544961012407826314577564991676315451785987248633724138137813024481818431889574317602521878974976264742037227074]
# 差分构造
t = [c[i] - c[i-1] for i in range(1, len(c))]
# 恢复模数 m
m = 0
for i in range(1, len(t)-1):
m = GCD(t[i+1] * t[i-1] - t[i]**2, m)
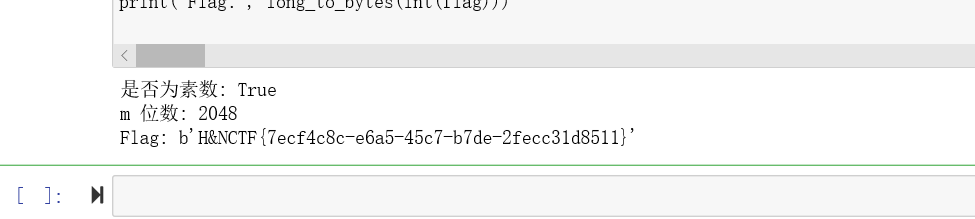
print("是否为素数:", isPrime(m))
print("m 位数:", m.bit_length())
# 恢复参数 a, b
a = (c[3] - c[2]) * inverse_mod(c[2] - c[1], m) % m
b = (c[2] - a * c[1]) % m
# 恢复种子 cc
a_inv = inverse_mod(a, m)
cc = (c[0] - b) * a_inv % m
# 离散对数部分
n = 604805773885048132038788501528078428693141138274580426531445179173412328238102786863592612653315029009606622583856638282837864213048342883583286440071990592001905867027978355755042060684149344414810835371740304319571184567860694439564098306766474576403800046937218588251809179787769286393579687694925268985445059
g = Mod(2024, n)
y = Mod(cc, n)
flag = discrete_log(y, g)
print("Flag:", long_to_bytes(int(flag)))
数据处理
from tqdm import tqdm
from itertools import permutations
from Crypto.Util.number import long_to_bytes
from sage.all import *
# 1. 模数 Zmod(2^512)
Z = Zmod(2^512)
# 2. 目标参数(手动合并换行)
m = Z(5084057673176634704877325918195984684237263100965172410645544705367004138917087081637515846739933954602106965103289595670550636402101057955537123475521383)
c = Z(2989443482952171039348896269189568991072039347099986172010150242445491605115276953489889364577445582220903996856271544149424805812495293211539024953331399)
# 3. 恢复出混淆过的 flag
new_flag = str(discrete_log(c, m))
# 4. 映射表恢复原始数字
lowercase = '0123456789' # 正确的数字顺序
uppercase_pattern = '7***4****5' # 映射前的字符格式
# 5. 尝试所有 0123689 的排列来恢复原始 flag
for i in tqdm(permutations("0123689")):
up = f"7{''.join(i[:3])}4{''.join(i[3:])}5"
table = str.maketrans(up, lowercase)
flag = new_flag.translate(table)
try:
res = long_to_bytes(int(flag)).decode()
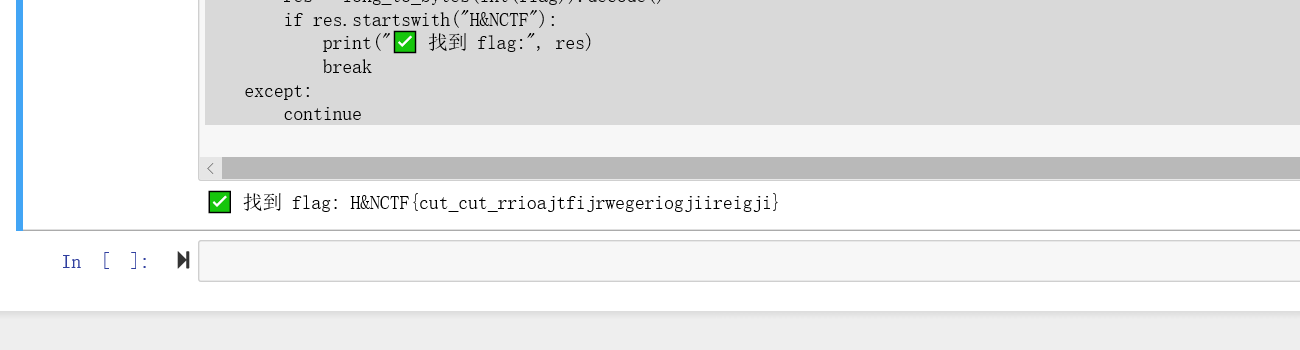
if res.startswith("H&NCTF"):
print("✅ 找到 flag:", res)
break
except:
continue
(Python 版本,无需 Sage)
from Crypto.Util.number import *
import sympy
import itertools
# 设定大数参数
m = 5084057673176634704877325918195984684237263100965172410645544705367004138917087081637515846739933954602106965103289595670550636402101057955537123475521383
c = 2989443482952171039348896269189568991072039347099986172010150242445491605115276953489889364577445582220903996856271544149424805812495293211539024953331399
n = 2 ** 512
# 计算离散对数
flag = sympy.discrete_log(n, c, m) # 即 c ≡ m^flag mod n
flag_str = str(flag)
# 替换映射相关
digits = '0123689'
target_digits = '0123456789'
# 枚举可能的密码本并尝试解码
for p in itertools.permutations(digits):
up = '7' + ''.join(p[:3]) + '4' + ''.join(p[3:]) + '5'
trans_table = str.maketrans(up, target_digits)
translated = flag_str.translate(trans_table)
try:
decoded = long_to_bytes(int(translated))
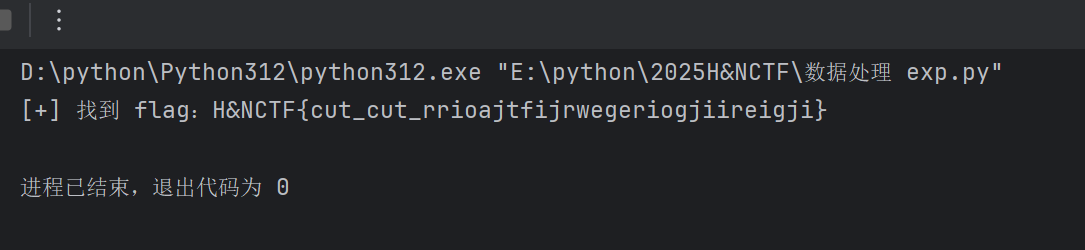
if b'H&NCTF' in decoded:
print(f"[+] 找到 flag:{decoded.decode()}")
break
except Exception:
continue
ez-factor
from Crypto.Util.number import long_to_bytes, inverse
from sage.all import PolynomialRing, Zmod, gcd
# ===========================
# 已知参数(从题目中整理)
# ===========================
N = 155296910351777777627285876776027672037304214686081903889658107735147953235249881743173605221986234177656859035013052546413190754332500394269777193023877978003355429490308124928931570682439681040003000706677272854316717486111569389104048561440718904998206734429111757045421158512642953817797000794436498517023
hint = 128897771799394706729823046048701824275008016021807110909858536932196768365642942957519868584739269771824527061163774807292614556912712491005558619713483097387272219068456556103195796986984219731534200739471016634325466080225824620962675943991114643524066815621081841013085256358885072412548162291376467189508
ciphertext = 32491252910483344435013657252642812908631157928805388324401451221153787566144288668394161348411375877874802225033713208225889209706188963141818204000519335320453645771183991984871397145401449116355563131852618397832704991151874545202796217273448326885185155844071725702118012339804747838515195046843936285308
e = 65537
r_bit_length = 248 # r 是一个 248 位的小素数
# ===========================
# Step 1. 使用 Coppersmith’s 方法恢复 r
# ===========================
PR.<x> = PolynomialRing(Zmod(N)) # 多项式环 Z_N[x]
f = x - hint # f(x) = x - hint
# 尝试找到小根 r,使得 f(r) ≡ 0 mod N
roots = f.small_roots(X=2^r_bit_length, beta=0.4, epsilon=0.01)
if not roots:
print("[-] 未找到满足条件的小根 r,建议调节 beta 或 epsilon 参数后重试")
exit()
r = int(roots[0])
print("[+] 找到小根 r =", r)
# ===========================
# Step 2. 利用 r 分解 N
# ===========================
p = gcd(hint - r, N)
if p == 1 or N % p != 0:
print("[-] 恢复 p 失败,p 可能不是 N 的因子")
exit()
q = N // p
phi = (p - 1) * (q - 1)
d = inverse(e, phi)
# ===========================
# Step 3. 解密密文
# ===========================
m = pow(ciphertext, d, N)
flag = long_to_bytes(int(m))
if b'H&NCTF' in flag:
print("[+] 可能的flag:", flag)
else:
print("[!] 没有找到明显的flag格式,可能需要进一步处理")

three vertical lines
from Crypto.Util.number import long_to_bytes, inverse
from sage.all import *
# 1. 把 n 写成一行:
n = Integer(72063558451087451183203801132459543552092564094711815404066471440396765744526854383117910805713050240067432476705168314622044706081669935956972031037827580519320550326077291392722314265758802332280697884744792689996718961355845963752788234205565249205191648439412084543163083032775054018324646541875754706761793307667356964825613429368358849530455220484128264690354330356861777561511117)
# 2. 这里改用整数环,构造多项式环
R = PolynomialRing(Integers(n), 'x')
x = R.gen()
# 3. 计算 t 满足 t^5 = 4/3 mod n
# 由于 n 不是素数,GF(n) 不适用,改用mod n的整数环中的多项式求解,或者用扩展欧几里得算法求5次根,这里直接计算t:
# 先计算逆元 3^-1 mod n
inv3 = inverse_mod(3, n)
four_thirds = (4 * inv3) % n
# 计算四分之三的5次根 t:这里没有现成函数,需要自定义尝试或者用数论方法。
# 之前用的 GF(n)(4/3).nth_root(5) 在 n 不是素数时不可用
# 假设你有 t,下面直接填上:
# 也可以尝试在 Sage 中用 discrete_log 或者其它算法计算
t = pow(four_thirds, inverse_mod(5, (n-1)), n) # 这是一个尝试的做法,不保证成功
# 4. 构造矩阵 M
M = Matrix(ZZ, [
[1, t],
[0, n]
])
# 5. LLL 找到短向量
q, p = M.LLL()[0]
q, p = abs(q), abs(p)
print(3 * p**5 + 4 * q**5 == n)
# 6. 密文 c,同样合并成一行:
c = Integer(2864901454060087890623075705953001126417241189889895476561381971868301515757296100356013797346138819690091860054965586977737630238293536281745826901578223)
e = Integer(65537)
d = inverse(e, (p - 1)*(q - 1))
m = pow(c, d, p*q)
m_int = int(m) # 转换成普通整数
flag = long_to_bytes(m_int)
print(flag)