
华为云Flexus+DeepSeek征文 | 当大模型遇见边缘计算:Flexus赋能低延迟AI Agent
🌟 嗨,我是IRpickstars!
🌌 总有一行代码,能点亮万千星辰。
🔍 在技术的宇宙中,我愿做永不停歇的探索者。
✨ 用代码丈量世界,用算法解码未来。我是摘星人,也是造梦者。
🚀 每一次编译都是新的征程,每一个bug都是未解的谜题。让我们携手,在0和1的星河中,书写属于开发者的浪漫诗篇。
目录
一、引言
随着人工智能技术的飞速发展,大语言模型(LLM)已经成为AI应用的核心驱动力。然而,传统的云端部署模式在面对实时性要求较高的场景时,往往存在网络延迟、带宽限制等问题。边缘计算的兴起为解决这一困境提供了新的思路。本文将深入探讨如何利用华为云Flexus弹性云服务器结合DeepSeek大模型,构建高性能、低延迟的AI Agent系统。
二、技术背景与架构设计
2.1 技术栈选择
在构建边缘AI Agent系统时,我们选择了以下技术栈:
- 华为云Flexus:提供弹性、高性能的计算资源
- DeepSeek模型:国产化大语言模型,具备优秀的推理能力
- Docker容器化:确保环境一致性和快速部署
- Redis缓存:提升响应速度
- Nginx负载均衡:保证系统稳定性
2.2 整体架构设计
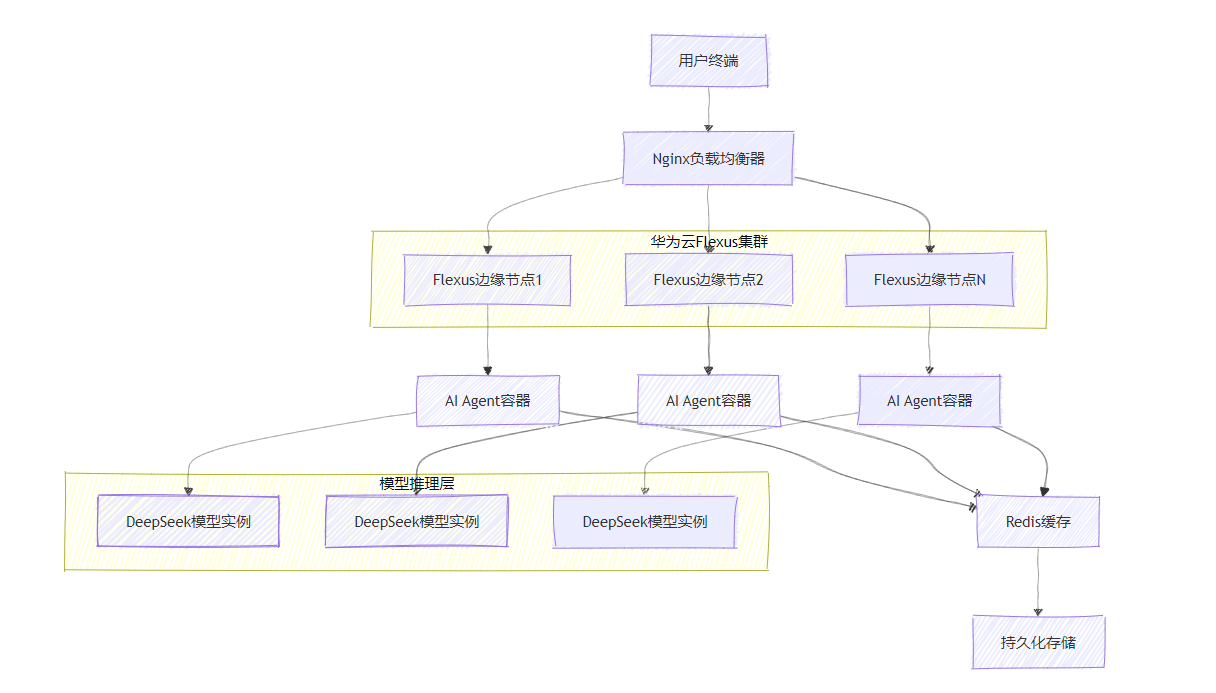
图1:基于华为云Flexus的边缘AI Agent架构图
2.3 核心优势分析
- 低延迟响应:边缘部署减少数据传输距离
- 高可用性:多节点部署,自动故障转移
- 弹性扩缩容:根据负载动态调整资源
- 成本优化:按需付费,资源利用率最大化
三、环境搭建与配置
3.1 华为云Flexus实例创建
步骤1:登录华为云控制台
- 访问华为云官网,登录控制台
- 进入弹性云服务器ECS服务
- 选择Flexus云服务器
步骤2:配置实例规格
# 推荐配置
CPU: 8核
内存: 16GB
存储: 100GB SSD
网络: 5Mbps带宽
操作系统: Ubuntu 20.04 LTS
步骤3:安全组配置
# 开放必要端口
HTTP: 80
HTTPS: 443
SSH: 22
自定义: 8080 (AI Agent服务端口)
自定义: 6379 (Redis端口)
3.2 基础环境安装
#!/bin/bash
# 系统更新和基础软件安装脚本
# 更新系统包
sudo apt update && sudo apt upgrade -y
# 安装Docker
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
# 启动Docker服务
sudo systemctl start docker
sudo systemctl enable docker
# 安装Docker Compose
sudo curl -L "https://github.com/docker/compose/releases/download/v2.20.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
# 安装Python环境
sudo apt install python3 python3-pip python3-venv -y
# 创建虚拟环境
python3 -m venv ai_agent_env
source ai_agent_env/bin/activate
echo "基础环境安装完成!"3.3 DeepSeek模型部署
步骤1:创建模型服务目录结构
mkdir -p ai_agent_project/{models,src,config,data,logs}
cd ai_agent_project步骤2:编写模型服务代码
# src/deepseek_service.py
import torch
import asyncio
import logging
from typing import Dict, List, Optional
from transformers import AutoTokenizer, AutoModelForCausalLM
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import redis
import json
import hashlib
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class ChatRequest(BaseModel):
"""聊天请求模型"""
message: str
session_id: Optional[str] = None
max_tokens: int = 512
temperature: float = 0.7
class ChatResponse(BaseModel):
"""聊天响应模型"""
response: str
session_id: str
tokens_used: int
response_time: float
class DeepSeekAgent:
"""DeepSeek AI Agent核心类"""
def __init__(self, model_name: str = "deepseek-ai/deepseek-coder-6.7b-instruct"):
"""
初始化DeepSeek Agent
Args:
model_name: 模型名称
"""
self.model_name = model_name
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.tokenizer = None
self.model = None
self.redis_client = None
# 性能统计
self.request_count = 0
self.total_response_time = 0.0
logger.info(f"初始化DeepSeek Agent,使用设备: {self.device}")
async def initialize(self):
"""异步初始化模型和Redis连接"""
try:
# 初始化Redis客户端
self.redis_client = redis.Redis(
host='localhost',
port=6379,
decode_responses=True,
socket_connect_timeout=5
)
# 加载分词器
logger.info("加载分词器...")
self.tokenizer = AutoTokenizer.from_pretrained(
self.model_name,
trust_remote_code=True
)
# 加载模型
logger.info("加载模型...")
self.model = AutoModelForCausalLM.from_pretrained(
self.model_name,
torch_dtype=torch.float16 if self.device.type == "cuda" else torch.float32,
device_map="auto",
trust_remote_code=True
)
logger.info("模型初始化完成")
except Exception as e:
logger.error(f"模型初始化失败: {e}")
raise
def _generate_cache_key(self, message: str, temperature: float, max_tokens: int) -> str:
"""生成缓存键"""
content = f"{message}_{temperature}_{max_tokens}"
return hashlib.md5(content.encode()).hexdigest()
async def _get_cached_response(self, cache_key: str) -> Optional[str]:
"""获取缓存响应"""
try:
cached = self.redis_client.get(cache_key)
if cached:
logger.info("命中缓存")
return json.loads(cached)
return None
except Exception as e:
logger.warning(f"缓存读取失败: {e}")
return None
async def _set_cached_response(self, cache_key: str, response: str, ttl: int = 3600):
"""设置缓存响应"""
try:
self.redis_client.setex(
cache_key,
ttl,
json.dumps(response)
)
except Exception as e:
logger.warning(f"缓存写入失败: {e}")
async def generate_response(self, request: ChatRequest) -> ChatResponse:
"""
生成响应
Args:
request: 聊天请求
Returns:
ChatResponse: 聊天响应
"""
import time
start_time = time.time()
try:
# 生成缓存键
cache_key = self._generate_cache_key(
request.message,
request.temperature,
request.max_tokens
)
# 尝试获取缓存
cached_response = await self._get_cached_response(cache_key)
if cached_response:
response_time = time.time() - start_time
return ChatResponse(
response=cached_response,
session_id=request.session_id or "default",
tokens_used=len(self.tokenizer.encode(cached_response)),
response_time=response_time
)
# 构建输入
messages = [
{
"role": "user",
"content": request.message
}
]
# 编码输入
inputs = self.tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(self.device)
# 生成响应
with torch.no_grad():
outputs = self.model.generate(
inputs,
max_new_tokens=request.max_tokens,
temperature=request.temperature,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id,
eos_token_id=self.tokenizer.eos_token_id
)
# 解码响应
response_tokens = outputs[0][inputs.shape[-1]:]
response_text = self.tokenizer.decode(
response_tokens,
skip_special_tokens=True
)
# 缓存响应
await self._set_cached_response(cache_key, response_text)
# 计算响应时间
response_time = time.time() - start_time
# 更新统计信息
self.request_count += 1
self.total_response_time += response_time
return ChatResponse(
response=response_text,
session_id=request.session_id or "default",
tokens_used=len(response_tokens),
response_time=response_time
)
except Exception as e:
logger.error(f"生成响应失败: {e}")
raise HTTPException(status_code=500, detail=str(e))
def get_performance_stats(self) -> Dict:
"""获取性能统计"""
avg_response_time = (
self.total_response_time / self.request_count
if self.request_count > 0 else 0
)
return {
"total_requests": self.request_count,
"average_response_time": avg_response_time,
"model_device": str(self.device),
"model_name": self.model_name
}
# 初始化FastAPI应用
app = FastAPI(title="DeepSeek AI Agent", version="1.0.0")
# 全局Agent实例
agent = DeepSeekAgent()
@app.on_event("startup")
async def startup_event():
"""应用启动时初始化"""
await agent.initialize()
@app.post("/chat", response_model=ChatResponse)
async def chat_endpoint(request: ChatRequest):
"""聊天接口"""
return await agent.generate_response(request)
@app.get("/health")
async def health_check():
"""健康检查接口"""
return {"status": "healthy", "stats": agent.get_performance_stats()}
@app.get("/stats")
async def get_stats():
"""获取性能统计"""
return agent.get_performance_stats()
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080, workers=1)
四、Docker容器化部署
4.1 创建Dockerfile
# Dockerfile
FROM nvidia/cuda:11.8-devel-ubuntu20.04
# 设置环境变量
ENV DEBIAN_FRONTEND=noninteractive
ENV PYTHONUNBUFFERED=1
# 安装系统依赖
RUN apt-get update && apt-get install -y \
python3 \
python3-pip \
python3-dev \
git \
curl \
&& rm -rf /var/lib/apt/lists/*
# 设置工作目录
WORKDIR /app
# 复制requirements文件
COPY requirements.txt .
# 安装Python依赖
RUN pip3 install --no-cache-dir -r requirements.txt
# 复制应用代码
COPY src/ ./src/
COPY config/ ./config/
# 暴露端口
EXPOSE 8080
# 设置启动命令
CMD ["python3", "src/deepseek_service.py"]4.2 创建requirements.txt
# requirements.txt
torch>=2.0.0
transformers>=4.35.0
fastapi>=0.104.0
uvicorn>=0.24.0
redis>=5.0.0
pydantic>=2.0.0
numpy>=1.24.0
accelerate>=0.24.0
bitsandbytes>=0.41.0
4.3 Docker Compose配置
# docker-compose.yml
version: '3.8'
services:
redis:
image: redis:7-alpine
container_name: ai_agent_redis
ports:
- "6379:6379"
volumes:
- redis_data:/data
command: redis-server --appendonly yes
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 10s
timeout: 5s
retries: 5
networks:
- ai_agent_network
ai_agent:
build: .
container_name: ai_agent_service
ports:
- "8080:8080"
depends_on:
redis:
condition: service_healthy
volumes:
- ./models:/app/models
- ./logs:/app/logs
environment:
- CUDA_VISIBLE_DEVICES=0
- REDIS_HOST=redis
- REDIS_PORT=6379
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
networks:
- ai_agent_network
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/health"]
interval: 30s
timeout: 10s
retries: 3
start_period: 120s
nginx:
image: nginx:alpine
container_name: ai_agent_nginx
ports:
- "80:80"
- "443:443"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf
- ./ssl:/etc/nginx/ssl
depends_on:
ai_agent:
condition: service_healthy
networks:
- ai_agent_network
volumes:
redis_data:
networks:
ai_agent_network:
driver: bridge五、负载均衡与高可用配置
5.1 Nginx配置
# nginx.conf
events {
worker_connections 1024;
}
http {
upstream ai_agent_backend {
# 轮询负载均衡
server ai_agent:8080 weight=1 max_fails=3 fail_timeout=30s;
# 如果有多个实例,可以添加更多server
# server ai_agent_2:8080 weight=1 max_fails=3 fail_timeout=30s;
}
# 限流配置
limit_req_zone $binary_remote_addr zone=api_limit:10m rate=10r/s;
server {
listen 80;
server_name localhost;
# API接口代理
location /api/ {
limit_req zone=api_limit burst=20 nodelay;
proxy_pass http://ai_agent_backend/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# 超时设置
proxy_connect_timeout 30s;
proxy_send_timeout 60s;
proxy_read_timeout 60s;
# 缓存设置
proxy_cache_bypass $http_upgrade;
}
# 健康检查
location /health {
proxy_pass http://ai_agent_backend/health;
access_log off;
}
# 静态文件服务
location /static/ {
alias /var/www/static/;
expires 1y;
add_header Cache-Control "public, immutable";
}
# 访问日志
access_log /var/log/nginx/ai_agent_access.log;
error_log /var/log/nginx/ai_agent_error.log;
}
}5.2 监控与日志配置
# src/monitoring.py
import psutil
import logging
import time
import json
from datetime import datetime
from typing import Dict, Any
class SystemMonitor:
"""系统监控类"""
def __init__(self, log_file: str = "/app/logs/monitor.log"):
"""
初始化监控器
Args:
log_file: 日志文件路径
"""
self.log_file = log_file
# 配置日志
logging.basicConfig(
filename=log_file,
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
self.logger = logging.getLogger(__name__)
def get_system_metrics(self) -> Dict[str, Any]:
"""获取系统指标"""
try:
# CPU使用率
cpu_percent = psutil.cpu_percent(interval=1)
# 内存使用情况
memory = psutil.virtual_memory()
memory_percent = memory.percent
memory_available = memory.available / (1024**3) # GB
# 磁盘使用情况
disk = psutil.disk_usage('/')
disk_percent = disk.percent
disk_free = disk.free / (1024**3) # GB
# 网络统计
network = psutil.net_io_counters()
# GPU使用情况(如果可用)
gpu_info = self._get_gpu_info()
metrics = {
"timestamp": datetime.now().isoformat(),
"cpu_percent": cpu_percent,
"memory_percent": memory_percent,
"memory_available_gb": round(memory_available, 2),
"disk_percent": disk_percent,
"disk_free_gb": round(disk_free, 2),
"network_bytes_sent": network.bytes_sent,
"network_bytes_recv": network.bytes_recv,
"gpu_info": gpu_info
}
return metrics
except Exception as e:
self.logger.error(f"获取系统指标失败: {e}")
return {}
def _get_gpu_info(self) -> Dict[str, Any]:
"""获取GPU信息"""
try:
import torch
if torch.cuda.is_available():
gpu_count = torch.cuda.device_count()
gpu_info = []
for i in range(gpu_count):
memory_allocated = torch.cuda.memory_allocated(i) / (1024**3) # GB
memory_reserved = torch.cuda.memory_reserved(i) / (1024**3) # GB
gpu_info.append({
"device_id": i,
"name": torch.cuda.get_device_name(i),
"memory_allocated_gb": round(memory_allocated, 2),
"memory_reserved_gb": round(memory_reserved, 2)
})
return {"available": True, "devices": gpu_info}
else:
return {"available": False, "devices": []}
except Exception as e:
self.logger.warning(f"获取GPU信息失败: {e}")
return {"available": False, "devices": []}
def log_metrics(self):
"""记录系统指标"""
metrics = self.get_system_metrics()
if metrics:
self.logger.info(f"系统指标: {json.dumps(metrics)}")
def start_monitoring(self, interval: int = 60):
"""开始监控"""
self.logger.info("开始系统监控")
while True:
try:
self.log_metrics()
time.sleep(interval)
except KeyboardInterrupt:
self.logger.info("监控已停止")
break
except Exception as e:
self.logger.error(f"监控异常: {e}")
time.sleep(interval)
# 集成到主服务中
def start_background_monitoring():
"""启动后台监控"""
import threading
monitor = SystemMonitor()
monitor_thread = threading.Thread(
target=monitor.start_monitoring,
args=(30,), # 每30秒记录一次
daemon=True
)
monitor_thread.start()
return monitor
六、性能优化策略
6.1 模型量化优化
# src/model_optimization.py
import torch
from transformers import BitsAndBytesConfig
from typing import Optional
class ModelOptimizer:
"""模型优化器"""
@staticmethod
def create_quantization_config(
load_in_4bit: bool = True,
bnb_4bit_quant_type: str = "nf4",
bnb_4bit_use_double_quant: bool = True,
bnb_4bit_compute_dtype: torch.dtype = torch.float16
) -> BitsAndBytesConfig:
"""
创建量化配置
Args:
load_in_4bit: 是否使用4位量化
bnb_4bit_quant_type: 量化类型
bnb_4bit_use_double_quant: 是否使用双重量化
bnb_4bit_compute_dtype: 计算数据类型
Returns:
BitsAndBytesConfig: 量化配置
"""
return BitsAndBytesConfig(
load_in_4bit=load_in_4bit,
bnb_4bit_quant_type=bnb_4bit_quant_type,
bnb_4bit_use_double_quant=bnb_4bit_use_double_quant,
bnb_4bit_compute_dtype=bnb_4bit_compute_dtype
)
@staticmethod
def optimize_model_loading(model_name: str, device: str = "auto") -> dict:
"""
优化模型加载参数
Args:
model_name: 模型名称
device: 设备类型
Returns:
dict: 优化后的加载参数
"""
# 检查可用内存
if torch.cuda.is_available():
gpu_memory = torch.cuda.get_device_properties(0).total_memory
gpu_memory_gb = gpu_memory / (1024**3)
# 根据GPU内存选择优化策略
if gpu_memory_gb < 8:
# 小显存优化:使用8位量化
return {
"torch_dtype": torch.float16,
"device_map": device,
"quantization_config": ModelOptimizer.create_quantization_config(),
"low_cpu_mem_usage": True,
"trust_remote_code": True
}
elif gpu_memory_gb < 16:
# 中等显存优化:使用半精度
return {
"torch_dtype": torch.float16,
"device_map": device,
"low_cpu_mem_usage": True,
"trust_remote_code": True
}
else:
# 大显存:标准加载
return {
"torch_dtype": torch.float16,
"device_map": device,
"trust_remote_code": True
}
else:
# CPU模式
return {
"torch_dtype": torch.float32,
"device_map": "cpu",
"low_cpu_mem_usage": True,
"trust_remote_code": True
}
6.2 缓存策略优化
# src/cache_manager.py
import json
import hashlib
import time
from typing import Any, Optional, Dict
import redis
from datetime import datetime, timedelta
class AdvancedCacheManager:
"""高级缓存管理器"""
def __init__(self, redis_host: str = "localhost", redis_port: int = 6379):
"""
初始化缓存管理器
Args:
redis_host: Redis主机地址
redis_port: Redis端口
"""
self.redis_client = redis.Redis(
host=redis_host,
port=redis_port,
decode_responses=True,
socket_connect_timeout=5,
socket_timeout=5
)
# 缓存层级配置
self.cache_levels = {
"hot": {"ttl": 300, "prefix": "hot:"}, # 5分钟热缓存
"warm": {"ttl": 1800, "prefix": "warm:"}, # 30分钟温缓存
"cold": {"ttl": 7200, "prefix": "cold:"} # 2小时冷缓存
}
# 统计信息
self.stats = {
"hits": 0,
"misses": 0,
"total_requests": 0
}
def _generate_key(self, data: Dict[str, Any], level: str = "warm") -> str:
"""
生成缓存键
Args:
data: 待缓存的数据
level: 缓存级别
Returns:
str: 缓存键
"""
# 创建唯一标识符
content = json.dumps(data, sort_keys=True)
hash_key = hashlib.sha256(content.encode()).hexdigest()
prefix = self.cache_levels[level]["prefix"]
return f"{prefix}{hash_key}"
def get(self, data: Dict[str, Any]) -> Optional[Any]:
"""
获取缓存数据
Args:
data: 查询参数
Returns:
Optional[Any]: 缓存的数据或None
"""
self.stats["total_requests"] += 1
# 按优先级查找缓存
for level in ["hot", "warm", "cold"]:
cache_key = self._generate_key(data, level)
try:
cached_data = self.redis_client.get(cache_key)
if cached_data:
self.stats["hits"] += 1
# 如果是温缓存或冷缓存命中,提升到热缓存
if level != "hot":
self._promote_to_hot(data, json.loads(cached_data))
return json.loads(cached_data)
except Exception as e:
print(f"缓存读取错误 [{level}]: {e}")
continue
self.stats["misses"] += 1
return None
def set(self, data: Dict[str, Any], value: Any, level: str = "warm"):
"""
设置缓存数据
Args:
data: 键数据
value: 值数据
level: 缓存级别
"""
cache_key = self._generate_key(data, level)
ttl = self.cache_levels[level]["ttl"]
try:
# 添加元数据
cache_value = {
"data": value,
"timestamp": datetime.now().isoformat(),
"level": level
}
self.redis_client.setex(
cache_key,
ttl,
json.dumps(cache_value)
)
except Exception as e:
print(f"缓存写入错误: {e}")
def _promote_to_hot(self, data: Dict[str, Any], cached_data: Dict[str, Any]):
"""将缓存提升到热缓存"""
try:
self.set(data, cached_data["data"], "hot")
except Exception as e:
print(f"缓存提升错误: {e}")
def get_stats(self) -> Dict[str, Any]:
"""获取缓存统计信息"""
hit_rate = (
self.stats["hits"] / self.stats["total_requests"]
if self.stats["total_requests"] > 0 else 0
)
return {
**self.stats,
"hit_rate": round(hit_rate * 100, 2),
"redis_info": self._get_redis_info()
}
def _get_redis_info(self) -> Dict[str, Any]:
"""获取Redis信息"""
try:
info = self.redis_client.info()
return {
"used_memory_mb": round(info.get("used_memory", 0) / (1024**2), 2),
"connected_clients": info.get("connected_clients", 0),
"total_commands_processed": info.get("total_commands_processed", 0)
}
except Exception as e:
return {"error": str(e)}
def clear_cache(self, pattern: str = "*"):
"""清理缓存"""
try:
keys = self.redis_client.keys(pattern)
if keys:
self.redis_client.delete(*keys)
return len(keys)
return 0
except Exception as e:
print(f"缓存清理错误: {e}")
return 0
七、部署与测试验证
7.1 一键部署脚本
#!/bin/bash
# deploy.sh - 一键部署脚本
set -e
echo "=== 华为云Flexus AI Agent 部署脚本 ==="
# 检查必要的工具
check_requirements() {
echo "检查部署要求..."
if ! command -v docker &> /dev/null; then
echo "错误: Docker 未安装"
exit 1
fi
if ! command -v docker-compose &> /dev/null; then
echo "错误: Docker Compose 未安装"
exit 1
fi
echo "✓ 环境检查通过"
}
# 创建必要的目录
create_directories() {
echo "创建项目目录..."
mkdir -p {models,logs,ssl,data}
echo "✓ 目录创建完成"
}
# 下载模型(如果需要)
download_models() {
echo "检查模型文件..."
if [ ! -d "models/deepseek-coder-6.7b-instruct" ]; then
echo "下载DeepSeek模型(这可能需要一些时间)..."
# 这里可以添加模型下载逻辑
echo "注意: 请手动下载模型文件到 models/ 目录"
fi
echo "✓ 模型检查完成"
}
# 构建和启动服务
deploy_services() {
echo "构建Docker镜像..."
docker-compose build
echo "启动服务..."
docker-compose up -d
echo "等待服务启动..."
sleep 30
# 健康检查
echo "执行健康检查..."
max_attempts=10
attempt=1
while [ $attempt -le $max_attempts ]; do
if curl -f http://localhost/api/health &> /dev/null; then
echo "✓ 服务启动成功"
return 0
fi
echo "等待服务启动... ($attempt/$max_attempts)"
sleep 10
((attempt++))
done
echo "❌ 服务启动失败"
docker-compose logs
exit 1
}
# 显示部署信息
show_deployment_info() {
echo ""
echo "=== 部署完成 ==="
echo "服务地址: http://$(curl -s ifconfig.me)/api"
echo "健康检查: http://$(curl -s ifconfig.me)/api/health"
echo "统计信息: http://$(curl -s ifconfig.me)/api/stats"
echo ""
echo "查看日志: docker-compose logs -f"
echo "停止服务: docker-compose down"
echo ""
}
# 主函数
main() {
check_requirements
create_directories
download_models
deploy_services
show_deployment_info
}
# 执行部署
main "$@"7.2 性能测试脚本
# tests/performance_test.py
import asyncio
import aiohttp
import time
import statistics
from typing import List, Dict, Any
import json
import matplotlib.pyplot as plt
import seaborn as sns
class PerformanceTester:
"""性能测试类"""
def __init__(self, base_url: str = "http://localhost/api"):
"""
初始化性能测试器
Args:
base_url: API基础URL
"""
self.base_url = base_url
self.results = []
async def single_request(self, session: aiohttp.ClientSession, message: str) -> Dict[str, Any]:
"""
执行单个请求
Args:
session: HTTP会话
message: 测试消息
Returns:
Dict[str, Any]: 请求结果
"""
start_time = time.time()
try:
async with session.post(
f"{self.base_url}/chat",
json={
"message": message,
"max_tokens": 100,
"temperature": 0.7
},
timeout=aiohttp.ClientTimeout(total=60)
) as response:
if response.status == 200:
data = await response.json()
end_time = time.time()
return {
"success": True,
"response_time": end_time - start_time,
"tokens_used": data.get("tokens_used", 0),
"server_response_time": data.get("response_time", 0),
"message_length": len(message)
}
else:
return {
"success": False,
"error": f"HTTP {response.status}",
"response_time": time.time() - start_time
}
except Exception as e:
return {
"success": False,
"error": str(e),
"response_time": time.time() - start_time
}
async def concurrent_test(self,
messages: List[str],
concurrent_users: int = 10,
iterations: int = 5) -> Dict[str, Any]:
"""
并发测试
Args:
messages: 测试消息列表
concurrent_users: 并发用户数
iterations: 迭代次数
Returns:
Dict[str, Any]: 测试结果
"""
print(f"开始并发测试: {concurrent_users}个并发用户, {iterations}次迭代")
async with aiohttp.ClientSession() as session:
all_results = []
for iteration in range(iterations):
print(f"执行第 {iteration + 1}/{iterations} 轮测试...")
# 创建并发任务
tasks = []
for i in range(concurrent_users):
message = messages[i % len(messages)]
task = self.single_request(session, message)
tasks.append(task)
# 执行并发请求
iteration_start = time.time()
results = await asyncio.gather(*tasks)
iteration_end = time.time()
# 收集结果
for result in results:
result["iteration"] = iteration + 1
result["total_iteration_time"] = iteration_end - iteration_start
all_results.append(result)
self.results = all_results
return self.analyze_results()
def analyze_results(self) -> Dict[str, Any]:
"""分析测试结果"""
successful_requests = [r for r in self.results if r["success"]]
failed_requests = [r for r in self.results if not r["success"]]
if not successful_requests:
return {
"error": "没有成功的请求",
"total_requests": len(self.results),
"failed_requests": len(failed_requests)
}
# 响应时间统计
response_times = [r["response_time"] for r in successful_requests]
server_response_times = [r["server_response_time"] for r in successful_requests]
# 吞吐量统计
total_time = max([r.get("total_iteration_time", 0) for r in self.results])
throughput = len(successful_requests) / total_time if total_time > 0 else 0
analysis = {
"总体统计": {
"总请求数": len(self.results),
"成功请求数": len(successful_requests),
"失败请求数": len(failed_requests),
"成功率": round(len(successful_requests) / len(self.results) * 100, 2),
"吞吐量 (req/s)": round(throughput, 2)
},
"响应时间统计": {
"平均响应时间": round(statistics.mean(response_times), 3),
"中位数响应时间": round(statistics.median(response_times), 3),
"最小响应时间": round(min(response_times), 3),
"最大响应时间": round(max(response_times), 3),
"95百分位": round(self._percentile(response_times, 95), 3),
"99百分位": round(self._percentile(response_times, 99), 3)
},
"服务器处理时间": {
"平均处理时间": round(statistics.mean(server_response_times), 3),
"中位数处理时间": round(statistics.median(server_response_times), 3),
"最小处理时间": round(min(server_response_times), 3),
"最大处理时间": round(max(server_response_times), 3)
}
}
# 错误统计
if failed_requests:
error_types = {}
for req in failed_requests:
error = req.get("error", "Unknown")
error_types[error] = error_types.get(error, 0) + 1
analysis["错误统计"] = error_types
return analysis
def _percentile(self, data: List[float], percentile: int) -> float:
"""计算百分位数"""
sorted_data = sorted(data)
index = int((percentile / 100) * len(sorted_data))
return sorted_data[index - 1] if index > 0 else sorted_data[0]
def generate_report(self, output_file: str = "performance_report.json"):
"""生成测试报告"""
analysis = self.analyze_results()
# 保存JSON报告
with open(output_file, 'w', encoding='utf-8') as f:
json.dump({
"test_timestamp": time.strftime("%Y-%m-%d %H:%M:%S"),
"analysis": analysis,
"raw_results": self.results
}, f, indent=2, ensure_ascii=False)
print(f"测试报告已保存到: {output_file}")
return analysis
def visualize_results(self):
"""可视化测试结果"""
if not self.results:
print("没有测试结果可视化")
return
successful_requests = [r for r in self.results if r["success"]]
if not successful_requests:
print("没有成功的请求可视化")
return
# 创建图表
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# 响应时间分布
response_times = [r["response_time"] for r in successful_requests]
axes[0, 0].hist(response_times, bins=20, alpha=0.7)
axes[0, 0].set_title("响应时间分布")
axes[0, 0].set_xlabel("响应时间 (秒)")
axes[0, 0].set_ylabel("频次")
# 响应时间趋势
axes[0, 1].plot(response_times)
axes[0, 1].set_title("响应时间趋势")
axes[0,八. 结论
当DeepSeek等大模型遇见边缘计算,为AI Agent的智能化和实时化带来了前所未有的机遇。华为云Flexus凭借其秒级弹性、按需付费、异构算力支持等特性,在这一融合趋势中扮演了至关重要的角色。它不仅可以作为强大的“近边缘”算力引擎,为资源受限的边缘设备提供低延迟、高性能的大模型推理能力,还能通过弹性伸缩有效应对AI Agent负载的动态变化,实现性能与成本的最佳平衡。
通过构建端-边-Flexus(近边缘)-云的协同架构,开发者可以充分利用DeepSeek的智能,结合Flexus的弹性,打造出响应更迅速、体验更流畅、能力更强大的AI Agent,广泛应用于智能零售、智慧城市、工业物联网、自动驾驶等众多领域,加速千行百业的智能化转型。虽然仍面临一些挑战,但Flexus与边缘计算、大模型的结合无疑为AI Agent的未来发展开辟了广阔的前景。
九. 参考链接
华为云 Flexus 产品页面与文档:
产品介绍: 华为云Flexus云服务_云服务器_Flexus-华为云
帮助文档: 成长地图_Flexus云服务-华为云
华为云 弹性伸缩 (Auto Scaling) 官方文档:
https://support.huaweicloud.com/productdocs/AS/index.html
华为云 容器镜像服务 SWR (SoftWare Repository for Container) 文档:
华为云 API网关 (API Gateway) 文档:
DeepSeek AI 相关信息 (请关注其官方发布渠道获取最新信息):
(通常为官方网站、GitHub项目、研究论文等)
边缘计算相关概念与标准:
ETSI MEC (Multi-access Edge Computing): ETSI - Multi-access Edge Computing - Standards for MEC
Flask Web Framework Documentation:
Welcome to Flask — Flask Documentation (3.1.x)
🌟 嗨,我是IRpickstars!如果你觉得这篇技术分享对你有启发:
🛠️ 点击【点赞】让更多开发者看到这篇干货
🔔 【关注】解锁更多架构设计&性能优化秘籍
💡 【评论】留下你的技术见解或实战困惑作为常年奋战在一线的技术博主,我特别期待与你进行深度技术对话。每一个问题都是新的思考维度,每一次讨论都能碰撞出创新的火花。
🌟 点击这里👉 IRpickstars的主页 ,获取最新技术解析与实战干货!
⚡️ 我的更新节奏:
- 每周三晚8点:深度技术长文
- 每周日早10点:高效开发技巧
- 突发技术热点:48小时内专题解析