VSCode+CMake简直就是C++程序开发者的福音,无论是进行Qt开发,音视频开发,后端程序开发,Cuda开发,CMake都是神一样的存在。
首先确保你已经安装好了Cuda Toolkit,比如我的是Cuda 12.3。
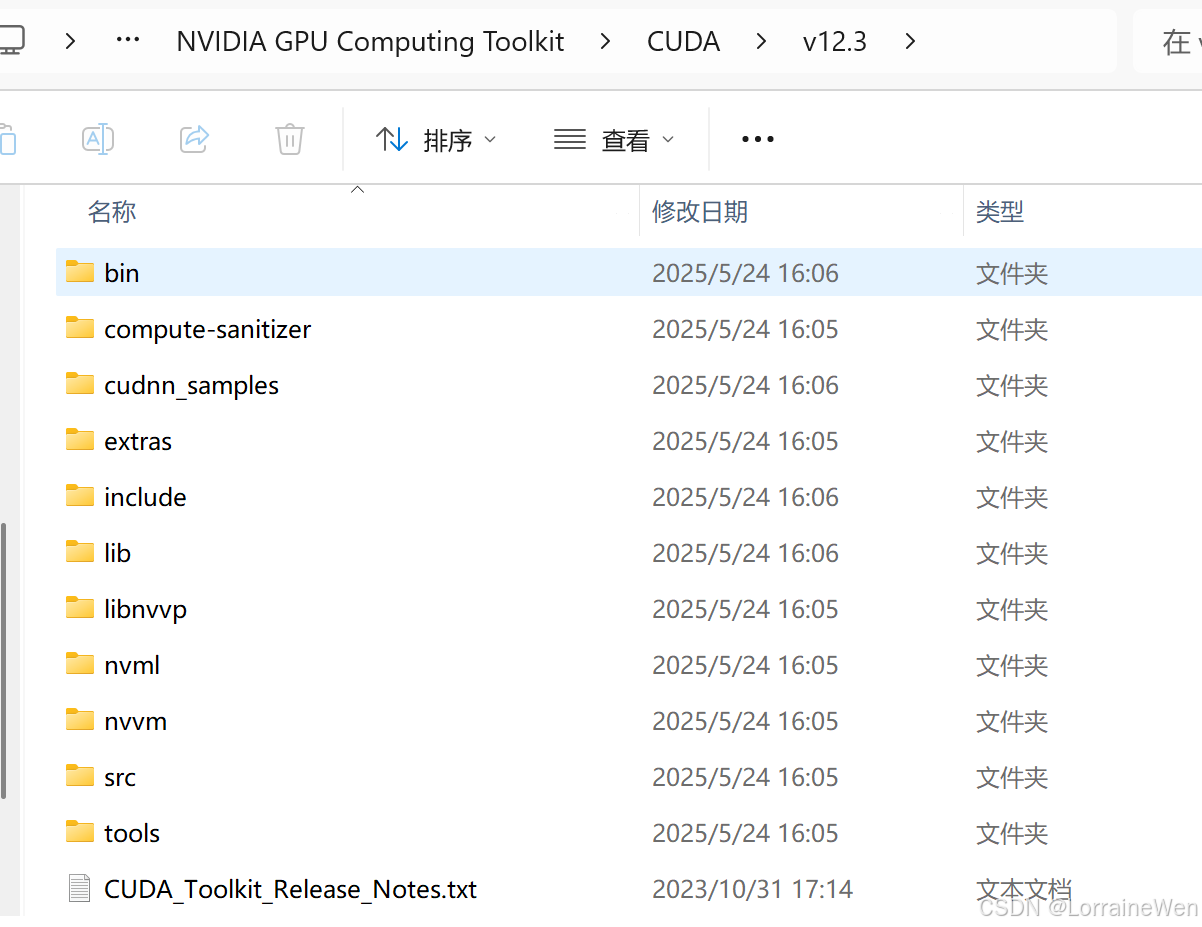
确保你已经配置了环境变量:

VSCode下载好插件:


CMakeLists.txt如下:
cmake_minimum_required(VERSION 3.18)
project(CudaTest LANGUAGES CXX CUDA)
# 设置CUDA标准
set(CMAKE_CUDA_STANDARD 17)
set(CMAKE_CUDA_STANDARD_REQUIRED ON)
#设置CUDA架构
set(CMAKE_CUDA_ARCHITECTURES "75")
# 添加CUDA头文件
include_directories("$ENV{CUDA_PATH}/include")
# 添加可执行文件
add_executable(cuda_test cuda_kernel.cu)main.cu如下:
#include <stdio.h>
#include <cuda_runtime.h>
// CUDA核函数:执行向量加法
__global__ void vectorAdd(const float *a, const float *b, float *c, int n) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
c[idx] = a[idx] + b[idx];
}
}
// 验证GPU计算结果
void verifyResult(float *a, float *b, float *c, int n) {
for (int i = 0; i < n; i++) {
if (fabs(a[i] + b[i] - c[i]) > 1e-5) {
printf("计算结果错误!\n");
return;
}
}
printf("计算结果正确!\n");
}
int main() {
const int n = 1000;
const int size = n * sizeof(float);
float *h_a = (float*)malloc(size);
float *h_b = (float*)malloc(size);
float *h_c = (float*)malloc(size);
for (int i = 0; i < n; i++) {
h_a[i] = rand() / (float)RAND_MAX;
h_b[i] = rand() / (float)RAND_MAX;
}
float *d_a, *d_b, *d_c;
cudaMalloc(&d_a, size);
cudaMalloc(&d_b, size);
cudaMalloc(&d_c, size);
cudaMemcpy(d_a, h_a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, size, cudaMemcpyHostToDevice);
int threadsPerBlock = 256;
int blocksPerGrid = (n + threadsPerBlock - 1) / threadsPerBlock;
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_a, d_b, d_c, n);
cudaMemcpy(h_c, d_c, size, cudaMemcpyDeviceToHost);
verifyResult(h_a, h_b, h_c, n);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
free(h_a);
free(h_b);
free(h_c);
return 0;
}
创建一个空文件夹:
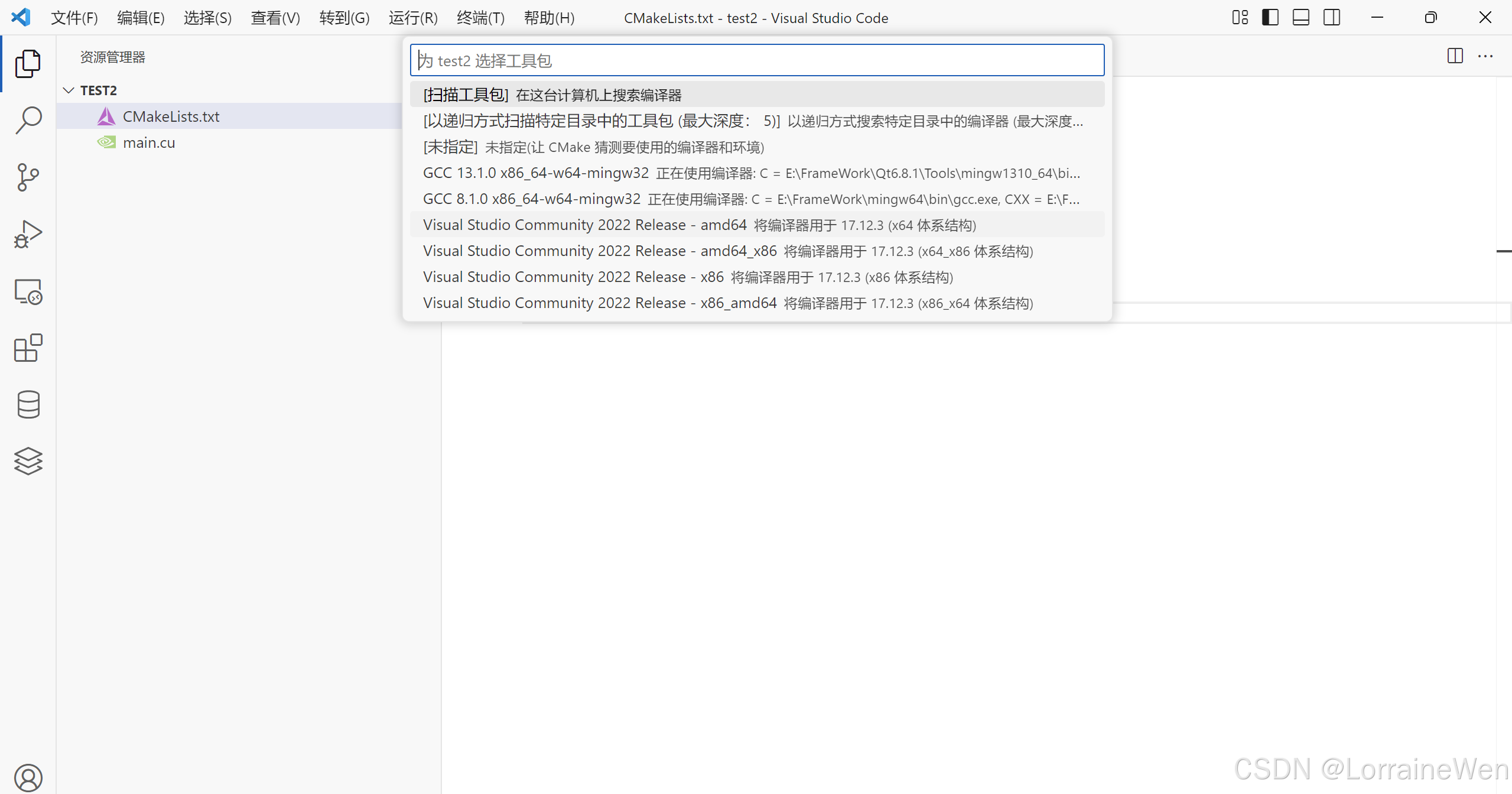
按下Ctrl shift P:点击CMake:Configure。
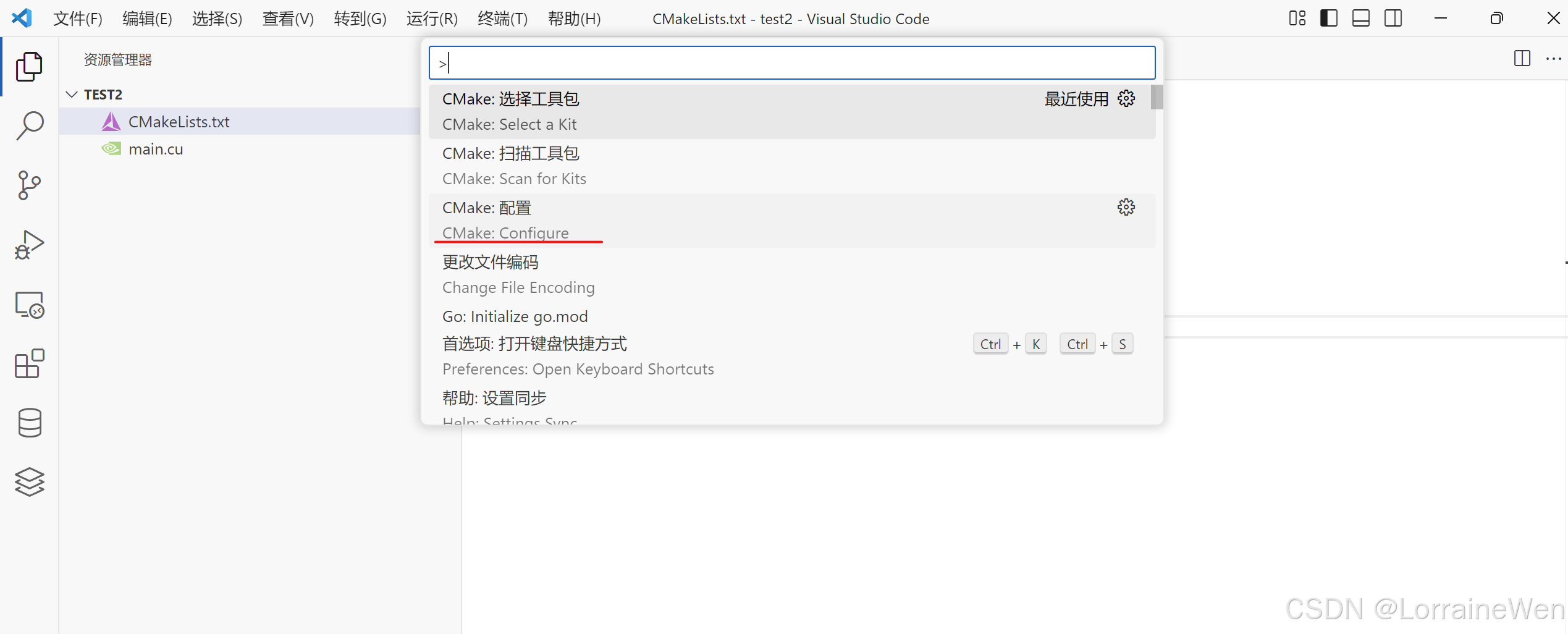
选择工具包,必须选择VS2022的amd64架构,不能用mingw!
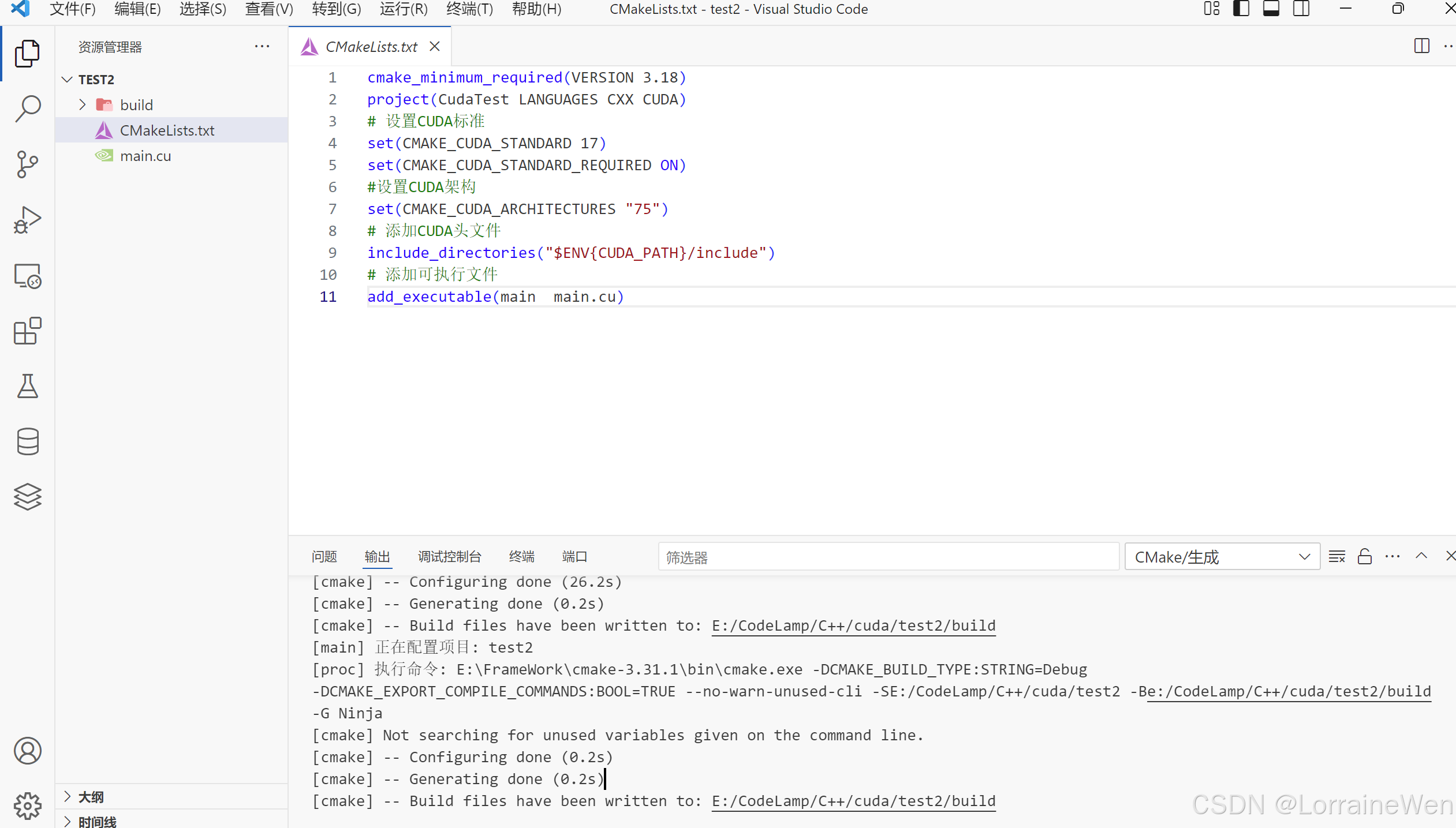
build文件生成完毕:
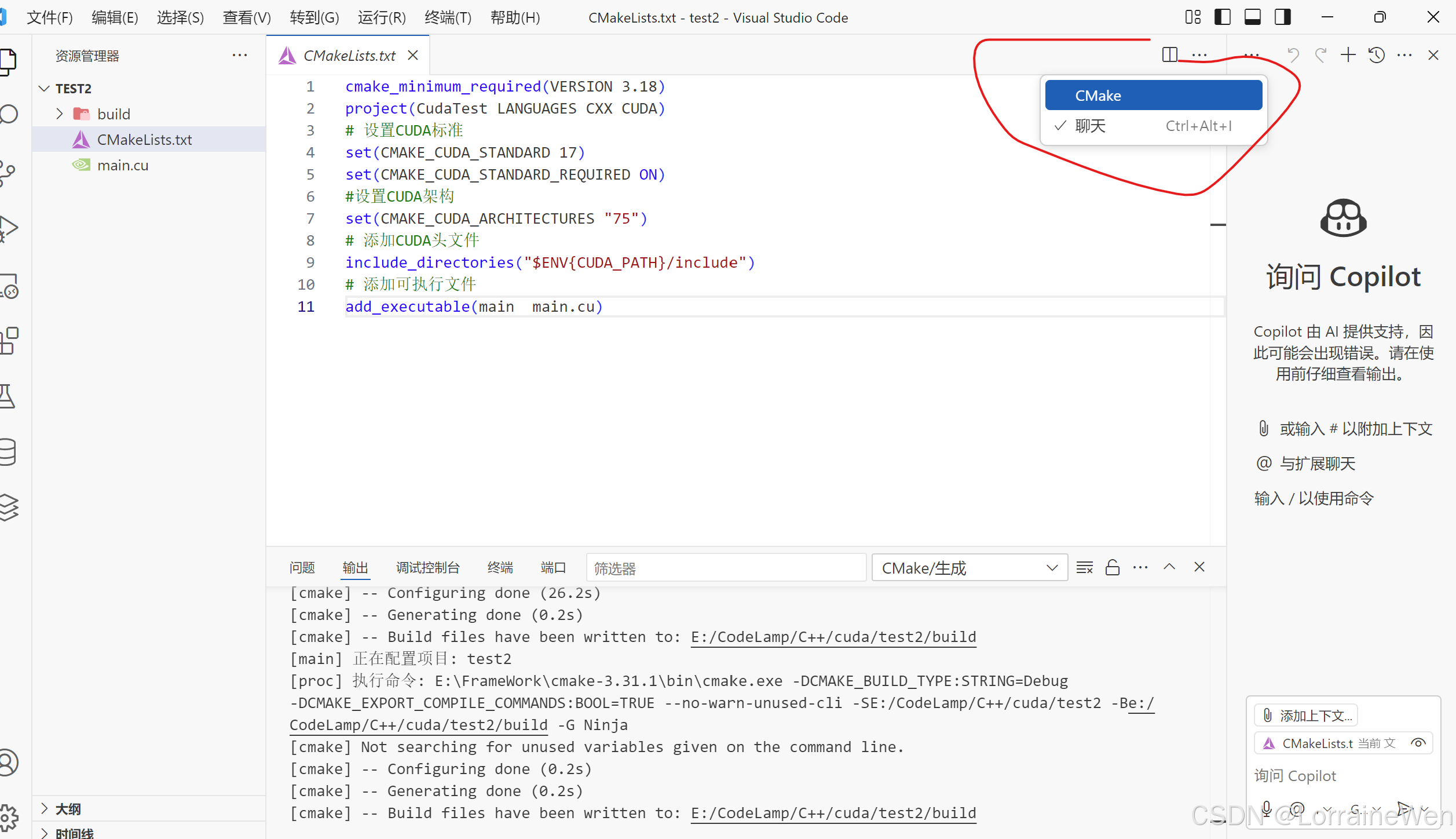
打开CMake插件,博主将CMake插件的窗口移动到右边窗口了,将copilot切换为CMake插件窗口(你们下载好的CMake插件窗口应该在左边,所以不用切换):
点击设置生成目标:
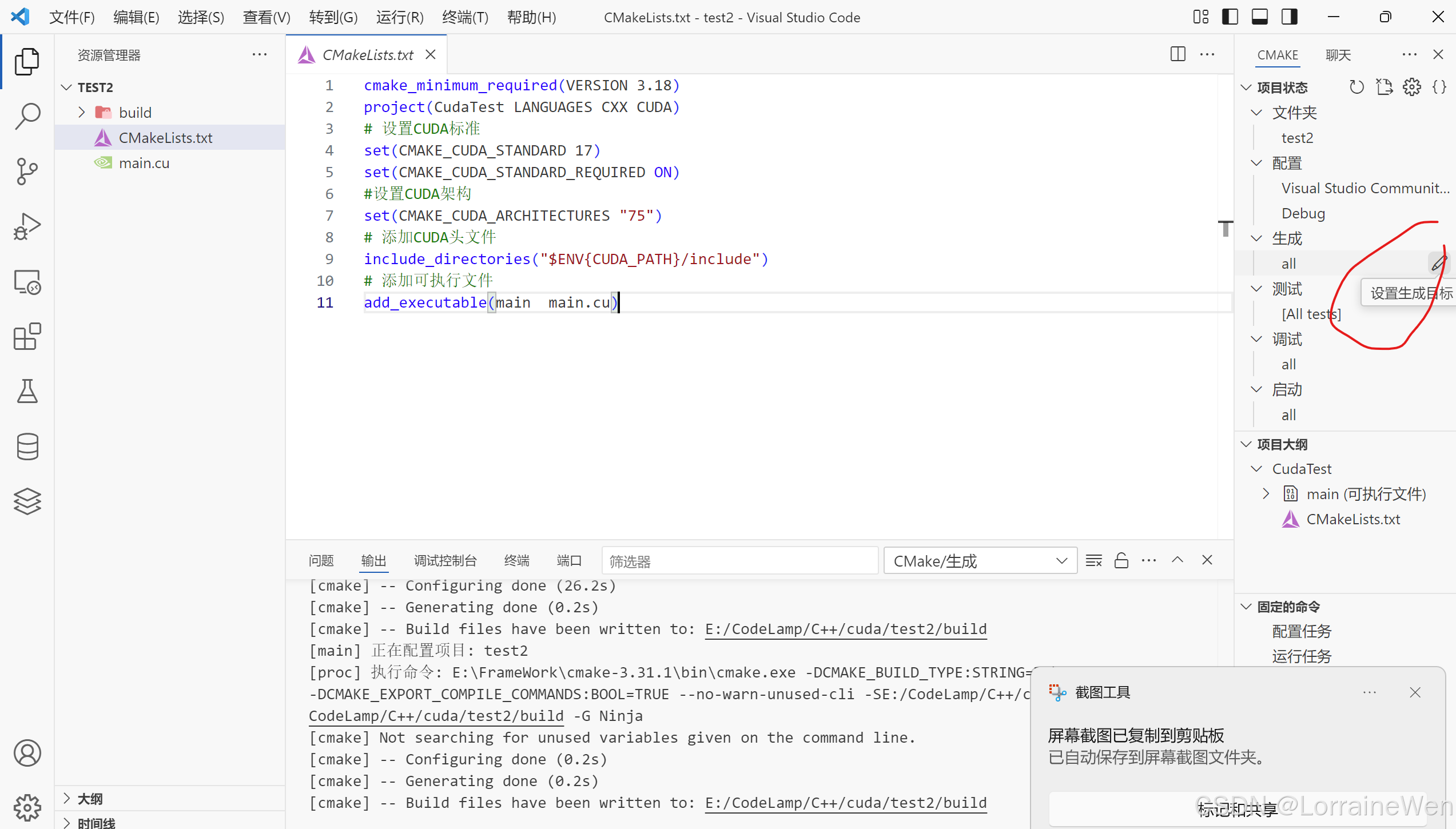
选择main.exe:
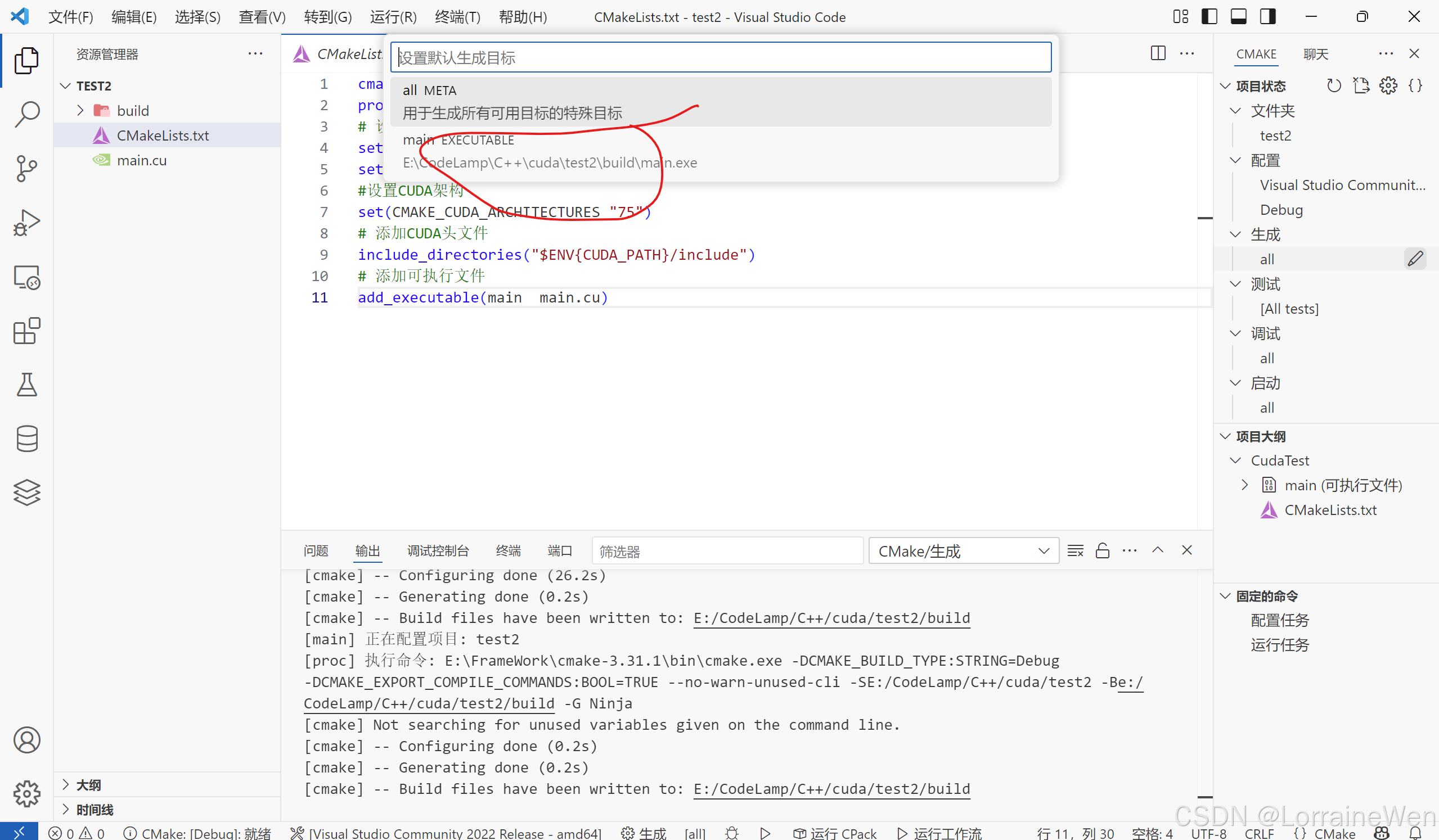
点击运行:
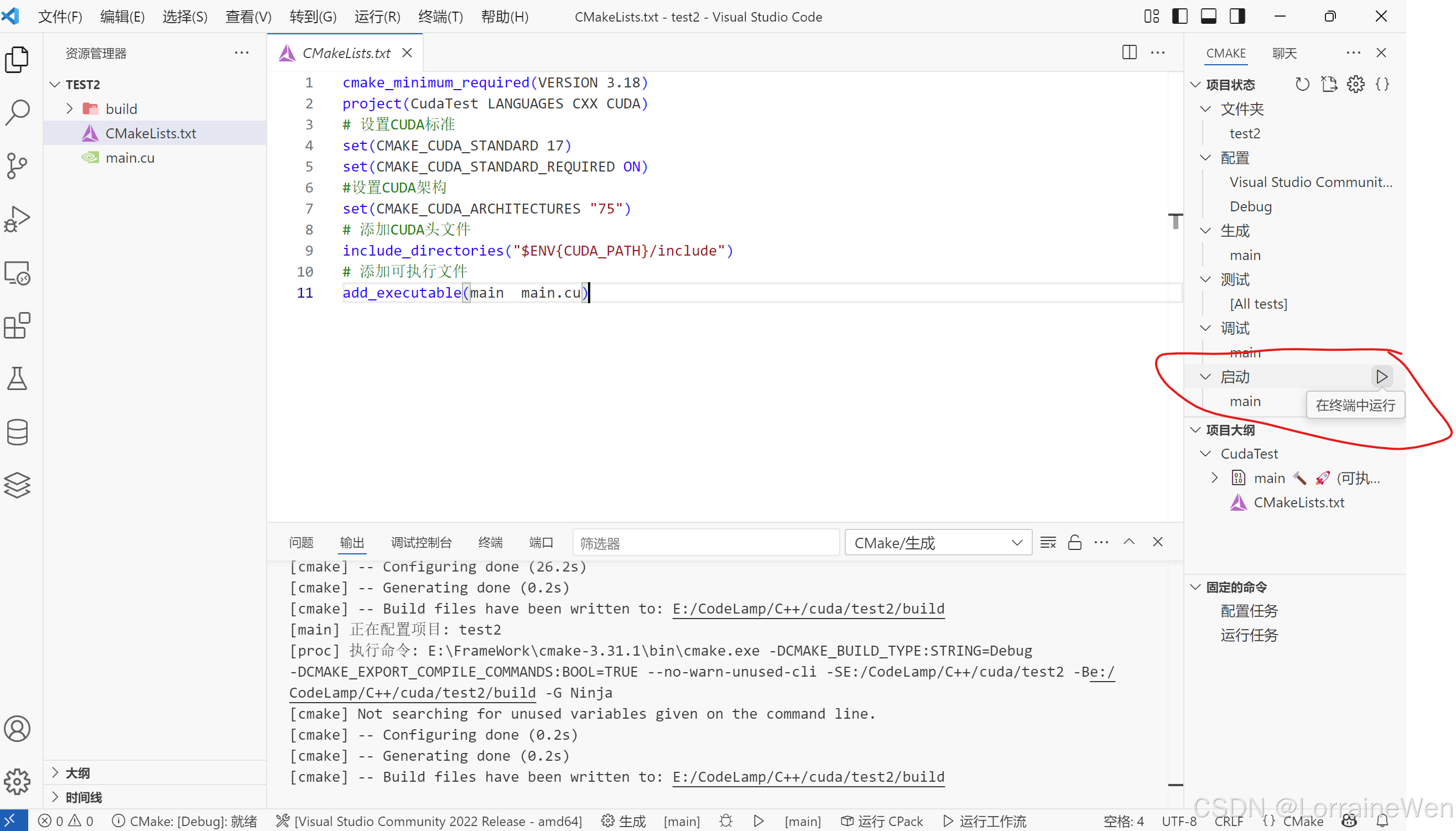
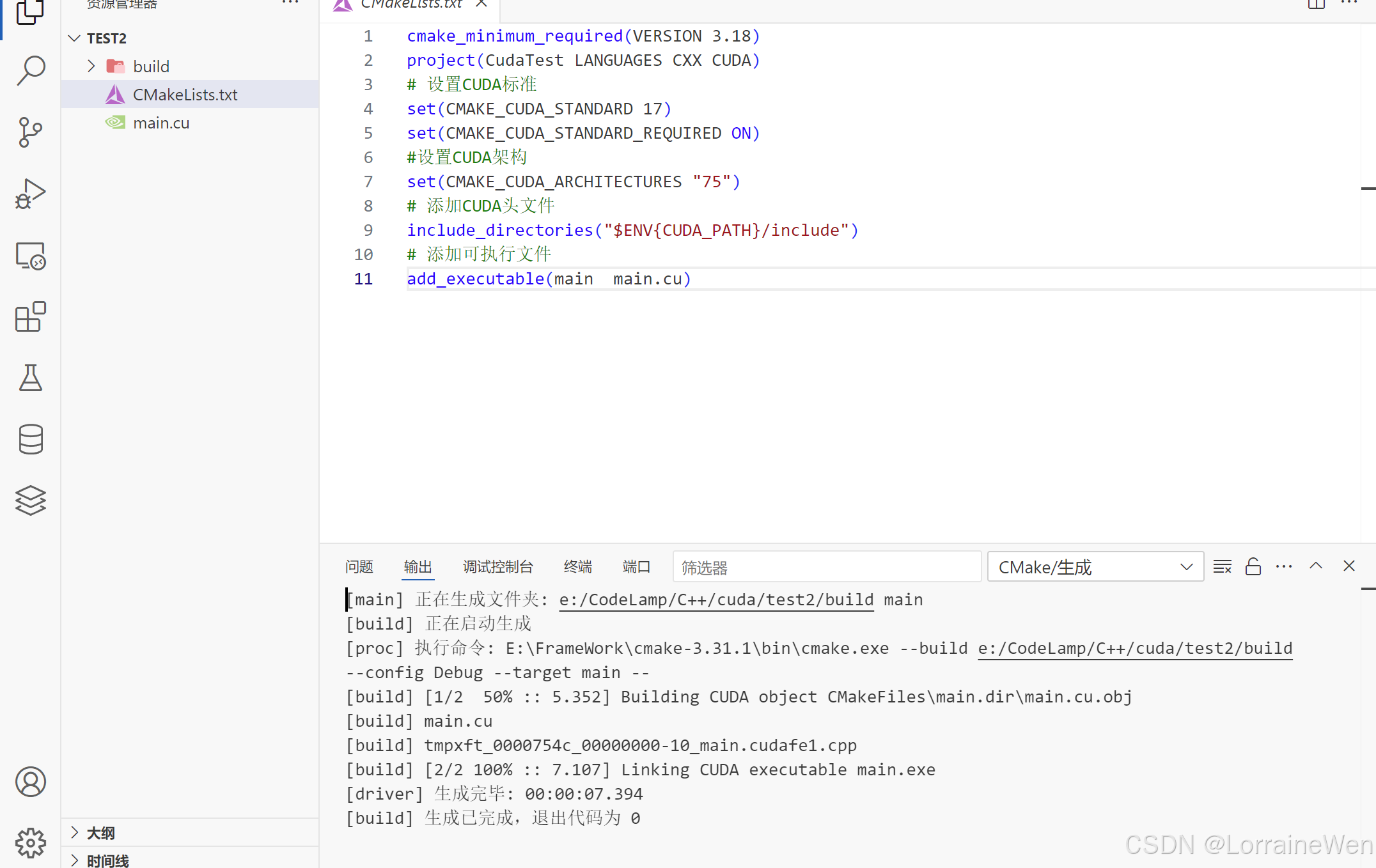
编译完成:
输出结果:
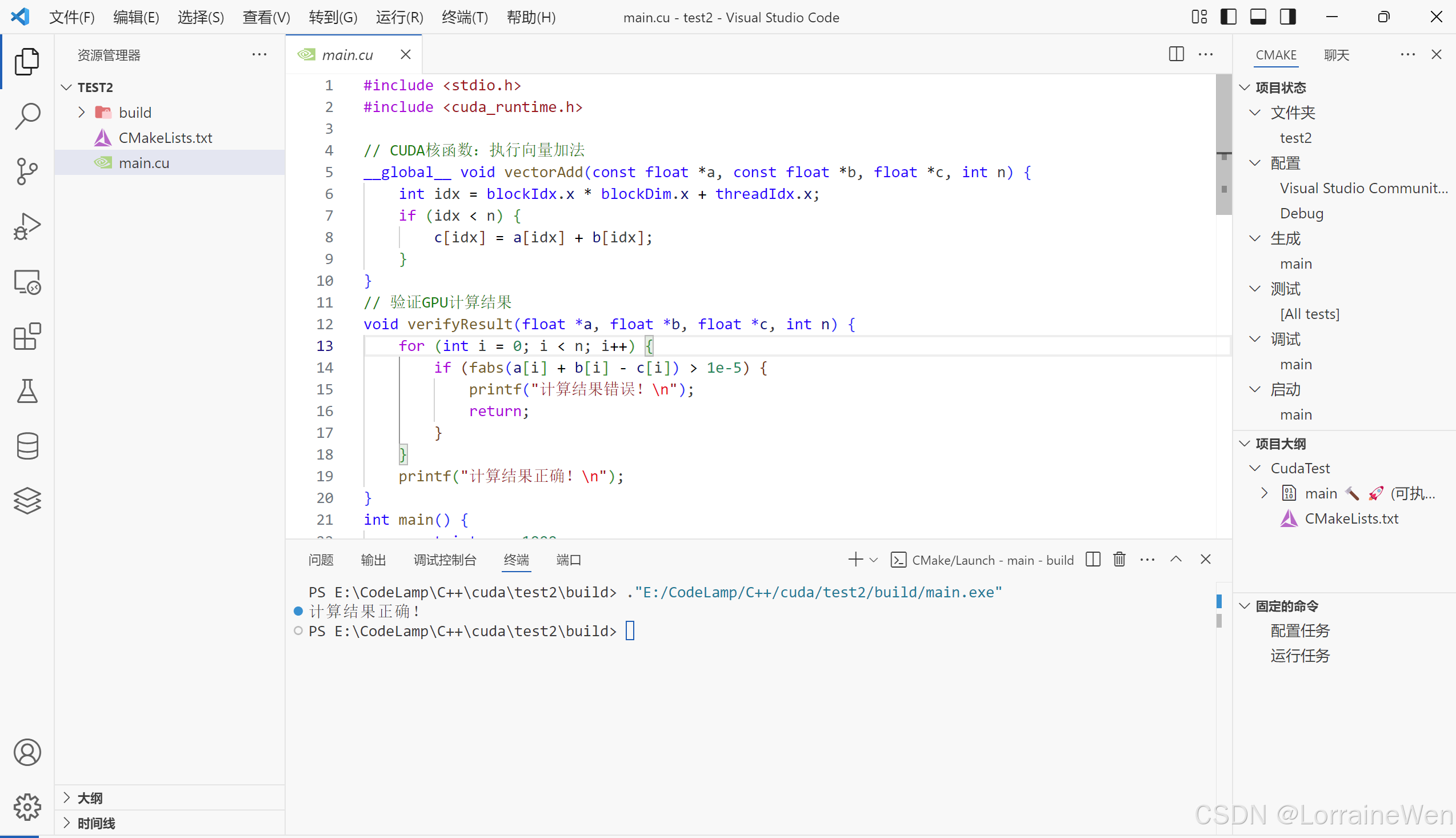
至此VSCode加CMake编译cuda程序配置完毕。