序列化技术详解:从原理到实践
什么是序列化
序列化(Serialization)是计算机科学中一项重要的数据处理技术,它指的是将对象实例的状态转换为可以存储或传输的格式的过程。与之相对的反序列化(Deserialization)则是将数据流重新构建为对象的过程。
核心概念
| 概念 | 技术定义 | 通俗解释 |
|---|---|---|
| 序列化 | 将数据结构或对象状态转换为可存储或可传输的格式(通常为字节流)的过程 | 把内存中的对象"打包"成可以保存/发送的数据 |
| 反序列化 | 将序列化后的数据重新构造为原始数据结构或对象的过程 | 把保存/接收的数据"解包"回内存中的对象 |
为什么需要序列化
- 数据持久化:将内存中的对象保存到文件或数据库中
- 网络传输:在不同系统间传输复杂数据结构
- 进程间通信:在不同进程间传递对象数据
- 分布式计算:在集群节点间交换数据
序列化工作流程
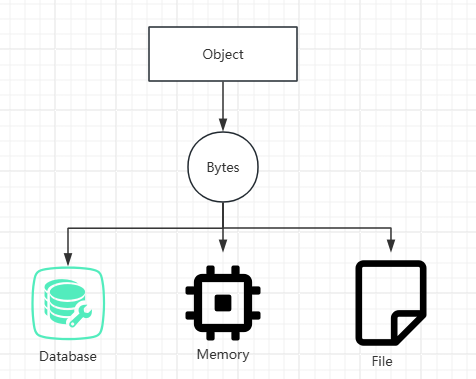
- 原始对象:内存中的数据结构或对象实例
- 序列化过程:转换为字节流或特定格式的字符串
- 传输/存储:通过网络传输或持久化存储
- 反序列化过程:重建为内存中的对象
C++序列化实现示例
#include <iostream>
#include <sstream>
#include <string>
// 示例数据结构
struct Person {
int id;
std::string name;
float salary;
// 序列化为字符串
std::string serialize() const {
std::ostringstream oss;
// 先写入id
oss << id << " ";
// 写入名字长度和名字内容(处理包含空格的情况)
oss << name.size() << " " << name << " ";
// 写入薪水
oss << salary;
return oss.str();
}
// 从字符串反序列化
static Person deserialize(const std::string& data) {
std::istringstream iss(data);
Person p;
size_t nameLength;
// 读取id
iss >> p.id;
// 读取名字长度
iss >> nameLength;
// 跳过空格
iss.ignore(1);
// 读取指定长度的名字
p.name.resize(nameLength);
iss.read(&p.name[0], nameLength);
// 读取薪水
iss >> p.salary;
return p;
}
};
int main() {
// 原始数据
Person original{42, "Alice Smith", 85000.5f};
// 序列化演示
std::string serialized = original.serialize();
std::cout << "序列化结果: " << serialized << std::endl;
// 输出示例: 42 11 Alice Smith 85000.5
// 反序列化演示
Person restored = Person::deserialize(serialized);
std::cout << "反序列化结果: "
<< restored.id << ", "
<< restored.name << ", "
<< restored.salary << std::endl;
}
序列化技术进阶
- 二进制序列化:更紧凑,效率更高
- 跨语言序列化:Protocol Buffers、Thrift等
- 自描述格式:JSON、XML等
- 性能优化:零拷贝技术、内存池等
常见序列化格式对比
| 格式 | 优点 | 缺点 | 典型应用场景 |
|---|---|---|---|
| JSON | 可读性好,跨语言支持 | 体积较大,解析稍慢 | Web API,配置文件 |
| Protocol Buf | 高效紧凑,跨语言 | 需要定义schema,不可读 | 微服务通信,高性能场景 |
| XML | 可扩展性好,支持验证 | 冗长,解析开销大 | 企业级系统,文档存储 |
| MessagePack | 二进制,比JSON高效 | 兼容性要求高 | 实时通信,移动应用 |
总结
序列化技术是现代软件开发中的基础能力,理解其原理和实现方式对于设计高效的数据存储和传输方案至关重要。在实际项目中,应根据具体需求选择合适的序列化方案,平衡性能、可维护性和开发效率等因素。