[技巧] 接口优化技巧合集
我们在日常开发过程难免会涉及到很多接口,对于接口优化来说,实际就是优化接口的耗时,这样才能提升用户的体验,让服务更快的响应用户的操作。
下面将会给大家分享几种常见的接口优化方式:
文中全部代码地址,Github:
https://github.com/ziyifast/ziyifast-code_instruction/tree/main/go-demo/go-interface-optimize
1. 批处理[batch操作数据库]
批量思想:批量操作数据库,在循环插入场景的接口中,可以在批处理执行完成后一次性插入或更新数据库,避免多次 IO。
//for循环单笔入库
list.stream().forEatch(msg->{
insert();
});
//批量入库
batchInsert();
示例代码
package main
import (
"fmt"
"time"
)
const batchSize = 1000 // 批量大小
var buffer []int // 模拟待插入数据的缓冲区
// ========== 批处理逻辑 ==========
func batchInsert(data int) {
buffer = append(buffer, data)
if len(buffer) >= batchSize {
flushBatch()
}
}
func flushBatch() {
if len(buffer) == 0 {
return
}
time.Sleep(1 * time.Millisecond) // 模拟IO延迟
buffer = buffer[:0] // 清空缓冲区
}
// ========== 非批处理逻辑 ==========
func singleInsert(data int) {
time.Sleep(1 * time.Millisecond) // 模拟每次插入都发生IO
}
// ================================
func main() {
const totalItems = 2000
// 测试批处理耗时
startBatch := time.Now()
buffer = nil // 重置buffer
for i := 0; i < totalItems; i++ {
batchInsert(i)
}
flushBatch() // 处理剩余数据
elapsedBatch := time.Since(startBatch)
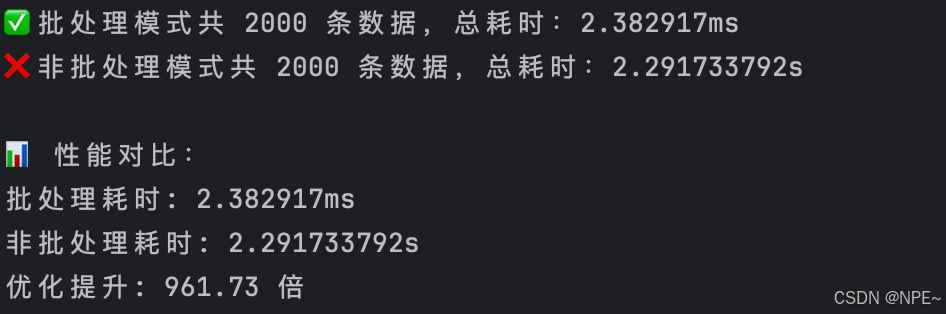
fmt.Printf("✅ 批处理模式共 %d 条数据,总耗时:%v\n", totalItems, elapsedBatch)
// 测试非批处理耗时
startSingle := time.Now()
for i := 0; i < totalItems; i++ {
singleInsert(i)
}
elapsedSingle := time.Since(startSingle)
fmt.Printf("❌ 非批处理模式共 %d 条数据,总耗时:%v\n", totalItems, elapsedSingle)
// 对比结果
fmt.Println("\n📊 性能对比:")
fmt.Printf("批处理耗时: %v\n", elapsedBatch)
fmt.Printf("非批处理耗时: %v\n", elapsedSingle)
fmt.Printf("优化提升: %.2f 倍\n", float64(elapsedSingle)/float64(elapsedBatch))
}
效果
2. 异步处理[协程/消息队列/任务框架]
异步思想:针对耗时比较长且不是结果必须的逻辑,我们可以考虑放到异步执行(类比后台下载,我们不等待它下载完成,可以去干其他的事情),这样能降低接口耗时。
例如发消息,比如用户续费了某个商品,我们可以前台只用告知用户订单是否支付成功即可。类似感谢用户的续费以及权益时长推送,就可以异步化,放到消息队列处理。
至于异步的实现方式,可以用线程池或者golang中的协程,也可以用消息队列,还可以用一些调度任务框架。
示例代码
package main
import (
"fmt"
"sync"
"time"
)
// ========== 异步逻辑 ==========
var wg sync.WaitGroup
func asyncTask() {
defer wg.Done()
time.Sleep(2 * time.Second) // 模拟耗时任务
}
func runAsyncTasks() {
startTime := time.Now()
for i := 0; i < 5; i++ {
wg.Add(1)
go asyncTask()
}
wg.Wait() // 等待所有 goroutine 完成
elapsed := time.Since(startTime)
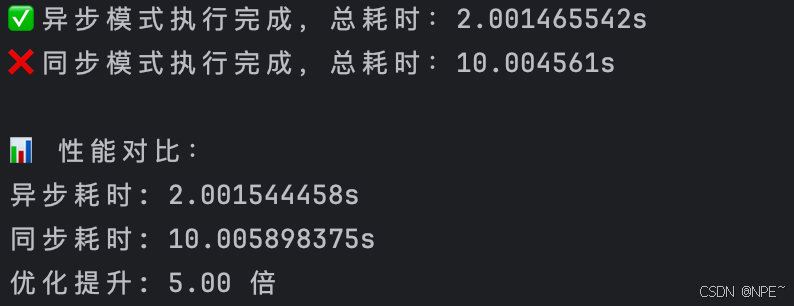
fmt.Printf("✅ 异步模式执行完成,总耗时:%v\n", elapsed)
}
// ========== 同步逻辑 ==========
func syncTask() {
time.Sleep(2 * time.Second) // 模拟耗时任务,比如调用给用户发消息接口
}
func runSyncTasks() {
startTime := time.Now()
for i := 0; i < 5; i++ {
syncTask()
}
elapsed := time.Since(startTime)
fmt.Printf("❌ 同步模式执行完成,总耗时:%v\n", elapsed)
}
// ================================
func main() {
// 测试异步执行
runAsyncTasks()
// 测试同步执行
runSyncTasks()
// 对比结果
fmt.Println("\n📊 性能对比:")
fmt.Printf("异步耗时: %v\n", asyncElapsedTime)
fmt.Printf("同步耗时: %v\n", syncElapsedTime)
fmt.Printf("优化提升: %.2f 倍\n", float64(syncElapsedTime)/float64(asyncElapsedTime))
}
var asyncElapsedTime time.Duration
var syncElapsedTime time.Duration
func init() {
// 预先运行一次以获取耗时数据
startAsync := time.Now()
for i := 0; i < 5; i++ {
wg.Add(1)
go asyncTask()
}
wg.Wait()
asyncElapsedTime = time.Since(startAsync)
startSync := time.Now()
for i := 0; i < 5; i++ {
syncTask()
}
syncElapsedTime = time.Since(startSync)
}
效果
3. 空间换时间[缓存]
一个很好理解的空间换时间的例子是合理使用缓存,针对一些频繁使用且不频繁变更的数据,可以提前缓存起来,需要时直接查缓存,避免频繁地查询数据库或者重复计算。
需要注意的是,空间换时间也是一把双刃剑,需要综合考虑你的使用场景,毕竟缓存带来的数据一致性问题也令人头疼。
这里的缓存可以是 R2M,也可以是本地缓存、memcached,或者 Map。
示例代码
package main
import (
"fmt"
"time"
)
// ========== 缓存逻辑 ==========
var cache = make(map[int]int)
func computeWithCache(n int) int {
if result, found := cache[n]; found {
return result
}
time.Sleep(1 * time.Millisecond) // 模拟耗时计算
result := n * n
cache[n] = result
return result
}
func runWithCache() {
startTime := time.Now()
for i := 0; i < 1000; i++ {
computeWithCache(i % 100) // 频繁访问少量数据
}
elapsed := time.Since(startTime)
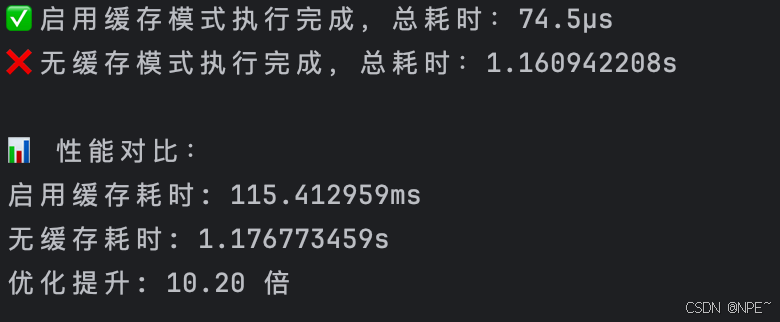
fmt.Printf("✅ 启用缓存模式执行完成,总耗时:%v\n", elapsed)
}
// ========== 无缓存逻辑 ==========
func computeNoCache(n int) int {
time.Sleep(1 * time.Millisecond) // 模拟耗时计算
return n * n
}
func runWithoutCache() {
startTime := time.Now()
for i := 0; i < 1000; i++ {
computeNoCache(i % 100) // 重复计算相同输入
}
elapsed := time.Since(startTime)
fmt.Printf("❌ 无缓存模式执行完成,总耗时:%v\n", elapsed)
}
// ================================
func main() {
// 测试启用缓存
runWithCache()
// 测试无缓存
runWithoutCache()
// 对比结果
fmt.Println("\n📊 性能对比:")
fmt.Printf("启用缓存耗时: %v\n", cachedElapsedTime)
fmt.Printf("无缓存耗时: %v\n", noCacheElapsedTime)
fmt.Printf("优化提升: %.2f 倍\n", float64(noCacheElapsedTime)/float64(cachedElapsedTime))
}
var cachedElapsedTime time.Duration
var noCacheElapsedTime time.Duration
func init() {
// 预先运行一次以获取耗时数据
startCached := time.Now()
for i := 0; i < 1000; i++ {
computeWithCache(i % 100)
}
cachedElapsedTime = time.Since(startCached)
startNoCache := time.Now()
for i := 0; i < 1000; i++ {
computeNoCache(i % 100)
}
noCacheElapsedTime = time.Since(startNoCache)
}
效果
4. 预处理[提前获取数据放入缓存]
也就是预取思想,就是提前要把查询的数据,提前计算好,放入缓存或者表中的某个字段,用的时候会大幅提高接口性能。跟上面那个例子很像,但是关注点不同。
举个简单的例子:理财产品,会有根据净值计算年化收益率的数据展示需求,利用净值去套用年化收益率计算公式计算的逻辑我们可以采用预处理,这样每一次接口调用直接取对应字段就可以了。
示例代码
package main
import (
"fmt"
"time"
)
// ========== 预处理逻辑 ==========
var precomputed = make(map[int]int)
func precompute() {
for i := 0; i < 100; i++ {
time.Sleep(1 * time.Millisecond) // 模拟预计算开销
precomputed[i] = i * i // 提前算好常用值
}
}
func usePrecomputed(n int) int {
return precomputed[n]
}
func runWithPrecompute() {
startTime := time.Now()
for i := 0; i < 1000; i++ {
usePrecomputed(i % 100)
}
elapsed := time.Since(startTime)
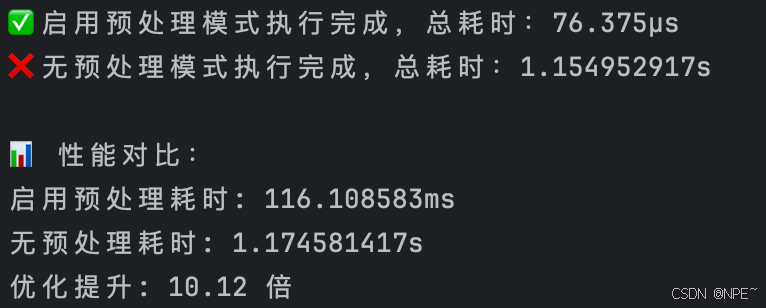
fmt.Printf("✅ 启用预处理模式执行完成,总耗时:%v\n", elapsed)
}
// ========== 实时计算逻辑 ==========
func realTimeCompute(n int) int {
time.Sleep(1 * time.Millisecond) // 模拟实时计算开销
return n * n
}
func runWithoutPrecompute() {
startTime := time.Now()
for i := 0; i < 1000; i++ {
realTimeCompute(i % 100)
}
elapsed := time.Since(startTime)
fmt.Printf("❌ 无预处理模式执行完成,总耗时:%v\n", elapsed)
}
// ================================
var withPrecomputeElapsed time.Duration
var withoutPrecomputeElapsed time.Duration
func init() {
// 预先运行一次获取耗时数据
start := time.Now()
precompute()
withPrecomputeElapsed = time.Since(start)
startNoPre := time.Now()
for i := 0; i < 1000; i++ {
realTimeCompute(i % 100)
}
withoutPrecomputeElapsed = time.Since(startNoPre)
}
func main() {
// 执行预处理版本
runWithPrecompute()
// 执行非预处理版本
runWithoutPrecompute()
// 输出性能对比
fmt.Println("\n📊 性能对比:")
fmt.Printf("启用预处理耗时: %v\n", withPrecomputeElapsed)
fmt.Printf("无预处理耗时: %v\n", withoutPrecomputeElapsed)
fmt.Printf("优化提升: %.2f 倍\n", float64(withoutPrecomputeElapsed)/float64(withPrecomputeElapsed))
}
效果
5. 池化思想[连接放入缓存]
我们都用过数据库连接池,线程池等,这就是池思想的体现,它们解决的问题就是避免重复创建对象或创建连接,可以重复利用,避免不必要的损耗,毕竟创建销毁也会占用时间。例如:某个客户端连接如果没有被建立,就去建立并放入缓存池,下次再用时,直接从池里拿就行,省去了创建的时间。
池化思想包含但并不局限于以上两种,总的来说池化思想的本质是预分配与循环使用,明白这个原理后,我们即使是在做一些业务场景的需求时,也可以利用起来。
示例代码
package main
import (
"fmt"
"sync"
"time"
)
// ========== 对象池逻辑 ==========
var objectPool = sync.Pool{
New: func() interface{} {
time.Sleep(10 * time.Millisecond) // 模拟首次创建对象的耗时
return &SomeObject{
Data: make([]byte, 1024),
}
},
}
type SomeObject struct {
Data []byte
}
// 预分配一定数量的对象到池中
func preAllocateToPool(count int) {
for i := 0; i < count; i++ {
objectPool.Put(objectPool.New())
}
}
func usePool() {
obj := objectPool.Get().(*SomeObject)
time.Sleep(100 * time.Microsecond) // 模拟使用对象
objectPool.Put(obj)
}
func runWithPool(iterations int) time.Duration {
const preAllocCount = 1000
preAllocateToPool(preAllocCount)
startTime := time.Now()
for i := 0; i < iterations; i++ {
usePool()
}
return time.Since(startTime)
}
// ========== 非池化逻辑 ==========
func createNewObject() *SomeObject {
time.Sleep(5 * time.Millisecond) // 模拟创建client耗时
return &SomeObject{
Data: make([]byte, 1024),
}
}
func runWithoutPool(iterations int) time.Duration {
startTime := time.Now()
for i := 0; i < iterations; i++ {
obj := createNewObject()
time.Sleep(100 * time.Microsecond) // 模拟使用对象
_ = obj // 不再使用,等待GC回收
}
return time.Since(startTime)
}
// ================================
func main() {
const iterations = 1000
// 执行对象池版本
withPoolElapsed := runWithPool(iterations)
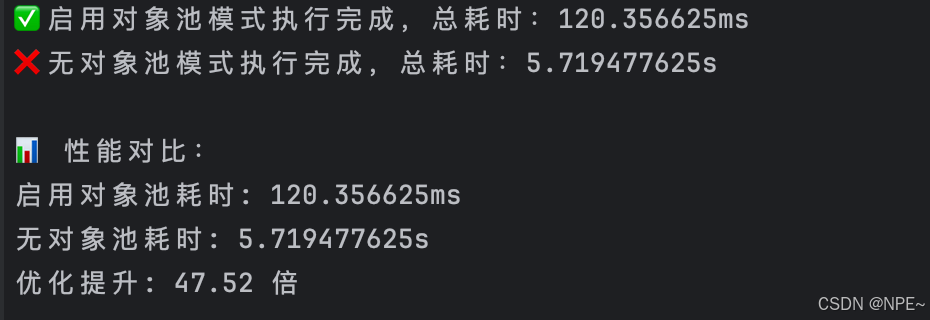
fmt.Printf("✅ 启用对象池模式执行完成,总耗时:%v\n", withPoolElapsed)
// 执行非对象池版本
withoutPoolElapsed := runWithoutPool(iterations)
fmt.Printf("❌ 无对象池模式执行完成,总耗时:%v\n", withoutPoolElapsed)
// 输出性能对比
fmt.Println("\n📊 性能对比:")
fmt.Printf("启用对象池耗时: %v\n", withPoolElapsed)
fmt.Printf("无对象池耗时: %v\n", withoutPoolElapsed)
fmt.Printf("优化提升: %.2f 倍\n", float64(withoutPoolElapsed)/float64(withPoolElapsed))
}
效果
6. 串行改并行[并发]
串行就是,当前执行逻辑必须等上一个执行逻辑结束之后才执行,并行就是两个执行逻辑互不干扰,所以并行相对来说就比较节省时间,当然是建立在没有结果参数依赖的前提下。
示例代码
package main
import (
"context"
"fmt"
"sync"
"time"
)
const maxConcurrency = 3 // 最大并发数
// ========== 并行逻辑 ==========
func doWork(id int, wg *sync.WaitGroup, ctx context.Context, tokenChan chan struct{}) {
defer wg.Done()
select {
case tokenChan <- struct{}{}: // 获取令牌
case <-ctx.Done(): // 上下文取消
fmt.Printf("💤 任务 %d 被取消\n", id)
return
}
defer func() {
<-tokenChan // 释放令牌
}()
// 模拟耗时操作
time.Sleep(100 * time.Millisecond)
}
func runParallel(ctx context.Context, totalTasks int) time.Duration {
var wg sync.WaitGroup
startTime := time.Now()
tokenChan := make(chan struct{}, maxConcurrency) // 控制并发的 channel
wg.Add(totalTasks)
for i := 0; i < totalTasks; i++ {
go func(i int) {
doWork(i, &wg, ctx, tokenChan)
}(i)
}
wg.Wait()
return time.Since(startTime)
}
// ========== 串行逻辑 ==========
func runSerial(totalTasks int) time.Duration {
startTime := time.Now()
for i := 0; i < totalTasks; i++ {
time.Sleep(100 * time.Millisecond)
}
return time.Since(startTime)
}
// ================================
func main() {
const totalTasks = 10
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
// 执行并行版本(带并发限制)
parallelElapsed := runParallel(ctx, totalTasks)
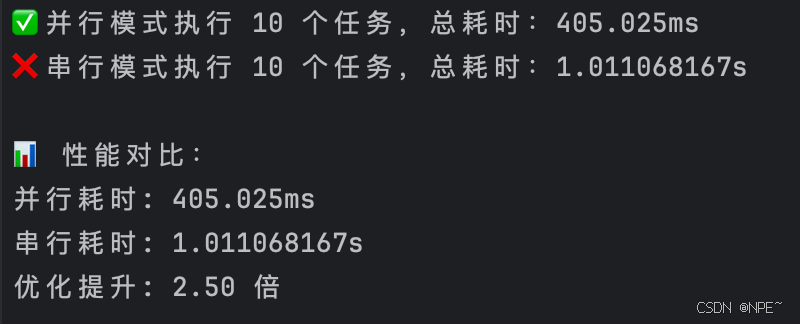
fmt.Printf("✅ 并行模式执行 %d 个任务,总耗时:%v\n", totalTasks, parallelElapsed)
// 执行串行版本
serialElapsed := runSerial(totalTasks)
fmt.Printf("❌ 串行模式执行 %d 个任务,总耗时:%v\n", totalTasks, serialElapsed)
// 输出性能对比
fmt.Println("\n📊 性能对比:")
fmt.Printf("并行耗时: %v\n", parallelElapsed)
fmt.Printf("串行耗时: %v\n", serialElapsed)
fmt.Printf("优化提升: %.2f 倍\n", float64(serialElapsed)/float64(parallelElapsed))
}
效果
7. 索引[数据库]
SQL加索引能大大提高数据查询效率,这个在接口以及数据库设计之初一般也会考虑到。不过我们需要注意一些SQL不生效的场景:

8. 避免大事务
所谓大事务问题,就是运行时间较长的事务,由于事务一致不提交,会导致数据库连接被占用,影响到别的请求访问数据库,影响别的接口性能。
例如:我们有一个电商场景。
用户下单时,系统需要完成以下操作:
插入订单主表
插入订单明细(多个商品)
扣减库存
增加积分
发送消息通知(如 Kafka、MQ)
这些操作中有些必须在事务中保证一致性,有些则可以异步或单独处理。下面就是不合理的接口设计:
func createOrderBad(db *sql.DB, order Order) error {
tx, _ := db.Begin()
// 1. 插入订单主表
if err := insertOrder(tx, order); err != nil {
tx.Rollback()
return err
}
// 2. 插入订单明细
for _, item := range order.Items {
if err := insertOrderItem(tx, item); err != nil {
tx.Rollback()
return err
}
}
// 3. 扣减库存(远程调用)
if err := deductInventory(order.Items); err != nil {
tx.Rollback()
return err
}
// 4. 增加用户积分(远程调用)
if err := addUserPoints(order.UserID); err != nil {
tx.Rollback()
return err
}
// 5. 发送 MQ 消息(非本地事务内操作)
sendOrderCreatedMessage(order)
return tx.Commit()
}
所以为避免大事务问题,我们可以通过以下方案规避:
1,RPC 调用不放到事务里面
2,查询操作尽量放到事务之外
3,事务中避免处理太多数据
9. 优化程序结构
程序结构问题一般出现在多次需求迭代后,代码叠加形成。会造成一些重复查询、多次创建对象等耗时问题。在多人维护一个项目时比较多见。解决起来也比较简单,我们需要针对接口整体做重构,评估每个代码块的作用和用途,调整执行顺序。
10.深分页问题
深分页问题比较常见,分页我们一般最先想到的就是 limit ,为什么会慢,我们可以看下这个 SQL:
select*from purchase_record where productCode ='PA9044'andstatus=4orderby orderTime desclimit100000,200
limit 100000,200 意味着会扫描 100200 行,然后返回 200 行,丢弃掉前 100000 行。所以执行速度很慢。一般可以采用标签记录法来优化,比如:
select*from purchase_record where productCode ='PA9044'and status=4 and id > 100000 limit200
这样优化的好处是命中了id主键索引,无论多少页,性能都还不错(因为不会一个一个去扫描,而是直接定位100000数据的位置,然后寻找大于100000的结果),但是局限性是需要一个连续自增的字段
11. SQL优化
SQL优化能大幅提高查询数据库的性能,从而提升接口的响应,由于本文重点讲述接口优化的方案,具体 sql 优化不再一一列举,大家可以结合索引、分页、等关注点考虑优化方案。
12. 细化锁力度(锁粒度避免过粗)
锁一般是为了在高并发场景下保护共享资源采用的一种手段,但是如果锁的粒度太粗,会很影响接口性能。
关于锁粒度:就是你要锁的范围有多大,不管是 synchronized 还是 redis 分布式锁,只需要在临界资源处加锁即可,不涉及共享资源的,不必要加锁,就好比你要上卫生间,只需要把卫生间的门锁上就可以,不需要把客厅的门也锁上。
错误的加锁方式:
type Service struct {
mu sync.Mutex
}
// 非共享资源:不需要加锁
func (s *Service) notShare() {
time.Sleep(10 * time.Millisecond) // 模拟操作耗时
fmt.Println("✅ 非共享资源操作完成")
}
// 共享资源:需要加锁保护
func (s *Service) share() {
time.Sleep(10 * time.Millisecond) // 模拟操作耗时
fmt.Println("🔒 共享资源操作完成")
}
// ❌ 错误方式:锁住了不该锁的非共享资源
func (s *Service) wrong() {
s.mu.Lock()
defer s.mu.Unlock()
s.share()
s.notShare()
}
正确的加锁方式:
// ✅ 正确方式:只锁共享资源
func (s *Service) right() {
s.notShare()
s.mu.Lock()
defer s.mu.Unlock()
s.share()
}
参考文章:https://mp.weixin.qq.com/s/ZGu_DrQwWu9rgNcGwynNNQ?poc_token=HPeRSWijFhfokKGIWgJom5_LjYLq0q7K_lrDNhNf