代码仓库地址:git@github.com:Liucc-123/python_learn.git
函数介绍
函数是组织好的、可重复使用的,用来实现单一、或相关功能的代码段。
函数可以提高应用的模块性和代码的可重复性。python 有许多内置的函数比如 print 打印函数,python 也支持用户实现自己的函数,这类函数也称之为自定义函数。
定义一个函数
定义一个函数需要遵循以下规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串 — 用于存放函数说明。
- 函数内容以冒号 : 起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方,不带表达式的 return 相当于返回 None。

语法
Python 定义函数使用 def 关键字,一般格式如下:
def 函数名(参数列表):
函数体
实例
默认情况下,参数是按照顺序参数进行匹配的。
示例:定义hello() 函数,打印输出“hello world”
#!/usr/bin/python3
def hello() :
print("Hello World!")
hello()
更复杂点儿的示例,函数带参数:
#!/usr/bin/python3
def max(a, b):
if a > b:
return a
else:
return b
a = 4
b = 5
print(max(a, b))
以上输出结果:
:::color1
5
:::
def area(width, height):
return width * height
def print_welcome(name):
print("Welcome", name)
print_welcome("李星云")
width=4
height=5
print("面积是:", area(width, height))
以上输出结果:
:::color1
Welcome 李星云
面积是: 20
:::
函数调用
当一个函数定义好之后,可以在另一个函数中调用此函数,或者在 python 命令提示符中调用。
注意:必须有调用方调用函数,这个函数才有作用,否则仅仅定义一个函数是没有任何输出的。
下面例子中,调用了 printme()函数:
#!/usr/bin/python3
# 定义函数
def printme( str ):
# 打印任何传入的字符串
print (str)
return
# 调用函数
printme("我要调用用户自定义函数!")
printme("再次调用同一函数")
以上示例输出结果:
:::color2
我要调用用户自定义函数!
再次调用同一函数
:::
函数调用机制

说明如下:
- python 的内存结构可以粗浅的理解为由数据区、代码区及栈组成
- 代码区:存放 python 代码的地方,python 解释器会将用户代码翻译为指令,然后由 CPU 顺序的执行
- 栈:程序执行的地方,每调用一个新函数就会开辟一个新栈,当函数返回后,这片内存空间就会被释放
- 数据区:存放变量、对象的地方
- 主程序从
result = area(4, 5)开始 - 此时会调用 area()函数,会开辟一个新栈。实参 4, 5 会被分别传递给参数 width 及 height,此时数据区会创建一块区间用来存放变量 width 和 height 的值
- 继续执行函数 area的函数体
width * height得到结果 20,数据区再创建一块空间存放临时变量 值20 - area 函数执行完毕,出栈,将结果
20返回给调用方也就是主栈 result,此时会释放这个栈空间 - 继续执行主程序
print("面积是:", result),主栈空间释放 - 控制台打印输出对应的值
面积是: 20
函数的传参机制
数值和字符串的传参机制
数值传参机制
示例代码:
# 字符串和数值类型传参机制
def f1(a):
print(f"f1() a的值:{a} 地址是:{id(a)}")
a += 1
print(f"f1() a的值:{a} 地址是:{id(a)}")
a = 10
print(f"调用f1()前 a的值:{a} 地址是:{id(a)}")
f1(a)
print(f"调用f1()后 a的值:{a} 地址是:{id(a)}")
:::info
以上示例输出结果:
调用f1()前 a的值:10 地址是:4357169600
f1() a的值:10 地址是:4357169600
f1() a的值:11 地址是:4357169632
调用f1()后 a的值:10 地址是:4357169600
:::

:::color2
说明如下:
- 在主栈空间定义了变量 a=10,假设地址值是 0x1122
- 调用函数f1(a),在函数内修改变量 a。因为变量a 是数值类型,python会在数据区创建一块新的空间保存修改后的值 11.所以函数外部的变量 a 并不会受到影响
- 在函数内打印 id(a),会发现变量 a 的地址已发生改变
- 出栈,因为函数内对变量 a 的修改不会影响到外部变量 a,所以打印 id(a),a 的地址值 仍是 0x1122
:::
字符串传参机制
示例代码:
def f2(name):
print(f"f2() name:{name} 地址是:{id(name)}")
name += "hi"
print(f"f2() name的值:{name} 地址是:{id(name)}")
name = "tom"
print(f"调用f2()前 name的值:{name} 地址是:{id(name)}")
f2(name)
print(f"调用f2()后 name的值:{name} 地址是:{id(name)}")
:::info
以上示例输出结果:
调用f2()前 name的值:tom 地址是:4307138768
f2() name:tom 地址是:4307138768
f2() name的值:tomhi 地址是:4307139584
调用f2()后 name的值:tom 地址是:4307138768
:::
:::success
总结:数值和字符串类型是不可变数据类型,当该类型的变量的值发生变化时,该变量对应的内存地址也会发生变化。也即不可变类型的数据值如果发生变化,那么这个变量已经不再是原来的那个变量了,即使他们的变量值是一样的。
:::
list、tuple、set 和dict 的传参机制
列表的传参机制
def f1(my_list):
print(f"②f1() my_list: {my_list} 地址:{id(my_list)} my_list[0]: {my_list[0]} 第一个元素地址:{id(my_list[0])}")
my_list[0] = "陆林轩"
print(f"③f1() my_list: {my_list} 地址:{id(my_list)} my_list[0]: {my_list[0]} 第一个元素地址:{id(my_list[0])}")
print("-" * 30 + "list" + "-" * 30)
my_list = ["李星云", "姬如雪", "张子凡"]
print(f"①my_list: {my_list} 地址:{id(my_list)} my_list[0]: {my_list[0]} 第一个元素地址:{id(my_list[0])}")
f1(my_list)
print(f"④my_list: {my_list} 地址:{id(my_list)} my_list[0]: {my_list[0]} 第一个元素地址:{id(my_list[0])}")
print("-" * 30 + "tuple" + "-" * 30)
my_tuple = ("hi", "ok", "hello")
print(f"①my_tuple: {my_tuple} 地址:{id(my_tuple)}")
f2(my_tuple)
print(f"④my_tuple: {my_tuple} 地址:{id(my_tuple)}")
def f3(my_set):
print(f"②f3() my_set: {my_set} 地址:{id(my_set)}")
my_set.add("红楼")
print(f"③f3() my_set: {my_set} 地址:{id(my_set)}")
print("-" * 30 + "set" + "-" * 30)
my_set = {"水浒", "西游", "三国"}
print(f"①my_set: {my_set} 地址:{id(my_set)}")
f3(my_set)
print(f"④my_set: {my_set} 地址:{id(my_set)}")
def f4(my_dict):
print(f"②f4() my_dict: {my_dict} 地址:{id(my_dict)}")
my_dict['address'] = "兰若寺"
print(f"③f4() my_dict: {my_dict} 地址:{id(my_dict)}")
print("-" * 30 + "dict" + "-" * 30)
my_dict = {"name": "小倩", "age": 18}
print(f"①my_dict: {my_dict} 地址:{id(my_dict)}")
f4(my_dict)
print(f"④my_dict: {my_dict} 地址:{id(my_dict)}")

:::color2
列表传参机制:
创建列表后,会在数据区开辟一块空间存储列表,地址比如为 0x9800,里面存放了三个元素
调用 f1 函数,将列表作为参数传递进去,此时开辟一个新的栈空间,指针my_list和主栈的指针 mylist 指向的是同一块空间
f1 函数修改第一个元素的值,是列表第一个元素指向了新的地址(陆林轩),但列表的自身的地址并未发生更改。
所以最终打印可以发现调用 f1 函数前后,列表的地址不会发生更改,只有第一个元素的地址发生了变化。
因此说,列表是可变数据类型,当列表的元素发生更改时,列表的地址并不会发生更改。“可变数据类型”中的“可变”是指变量地址是否会发生变化。
:::
小结
- python 数据类型主要有整型 int / 浮点型 float / 字符串 str / 布尔值 bool / 元组 tuple / 列表 list / 字典 dict / 集合 set,数据类型分为两个大类,一种是可变数据类型,一种是不可变数据类型。
- 可变数据类型和不可变数据类型。
- 可变数据类型:当该数据类型的变量的值发生了变化,如果它的内存地址不变,那么这个数据类型就是可变数据类型。
- 不可变数据类型:当该数据类型的变量的值发生了变化,如果它的内存地址改变了,那么这个数据类型就是不可变数据类型。
- python 的数据类型。
- 不可变数据类型:数值类型(int、float)、bool(布尔)、string(字符串)、tuple(元组)。
- 可变数据类型:list(列表)、set(集合)、dict(字典)。
递归机制
定义
递归函数,简单来说,就是自己调用自己的函数,它将问题分解为更小的同类子问题,通过不断的自我调用来解决复杂问题。
递归函数的核心特点:
- 自我调用:函数内部直接或间接调用自身
- 基准条件:递归函数必须具备终止递归的条件
- 逐步推进:每次调用都使问题规模向基准条件方向靠拢
递归能解决什么问题?
- 各种数学问题:汉诺塔、八皇后、阶乘问题、迷宫问题等
- 一些算法中也会用到递归:快排、归并排序、二分查找、分支算法等
- 需要用栈数据结构解决的问题
递归举例
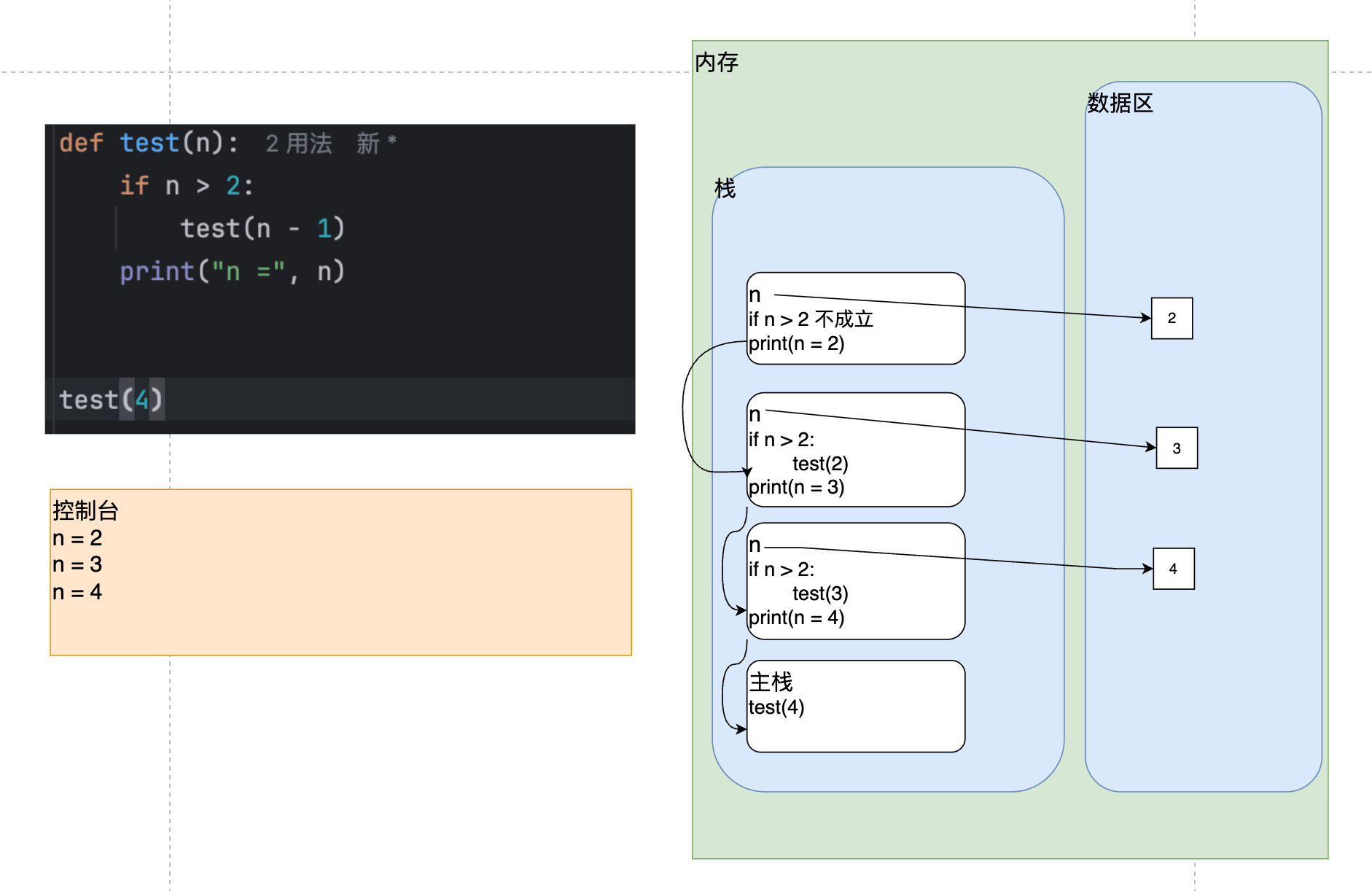
1、分析下面代码的执行流程:
def test(n):
if n > 2:
test(n - 1)
print("n =", n)
test(4)
上面代码的执行流程分析如下:
2、阶乘问题
# 阶乘问题
def factorial(n):
if n == 1:
return 1
else:
return n * factorial(n - 1)
print(factorial(4))
上面代码的执行流程分析如下:

递归重要规则
- 执行一个函数时,就会开辟一个新的栈空间
- 函数的变量是独立的,比如每个栈空间的变量 n 都是互相独立的
- 递归的走向必须是向递归的基准条件逐渐逼近的,否则就是无限递归了
- 当函数执行完毕,或遇到 return 语句,这个函数对应的栈空间和数据区就会被释放,且遵循谁调用,就将结果返回给谁
练习题
- 斐波那契问题
## 题目一:请使用递归的方式,求出斐波那契数 1,1,2,3,5,8,13… 给你一个整数 n,求出它的值是多少?
# 斐波那契数列 1,1,2,3,5,8,13…
# f(0)=1, f(1) = 1, f(n) = f(n-1) + f(n-2) (n >= 2)
def fibonacci(n):
if n == 0:
return 1
elif n == 1:
return 1
else:
return fibonacci(n - 1) + fibonacci(n - 2)
print(fibonacci(5))
- 猴子吃桃
## 题目二:猴子吃桃问题:有一堆桃子,猴子第一天吃了其中的一半,并再多吃了一个。以后每天猴子都吃其中的一半,然后再多吃一个。
# 当到第 10 天时,想再吃时(即还没吃),发现只有 1 个桃子了。问最初共多少个桃子?
"""
第 10天还有 1 个桃子
第9天还有:(1 + 1) * 2 = 4 个
第 8 天还有:(4 + 1) * 2 = 10 个
第 7 天还有:(10 + 1) * 2 = 22 个
...
"""
def eatPeach(day: int) -> int:
"""
查询这一天还剩多少个桃子
:param day: 第几天
:return: 这天还剩下几个桃子
"""
if day == 10:
return 1
return (eatPeach(day + 1) + 1) * 2
# 第一天还有多少个桃子,也即最初有多少个桃子
print(eatPeach(1))
- 求函数值
## 题目三:求函数值,已知 f(1) = 3; f(n)= 2*f(n-1)+1;请使用递归的思想,求出 f(n)的值?
def f(n: int) -> int:
if n == 1:
return 3
return 2 * f(n - 1) + 1
print(f(2))
- 汉诺塔
## 题目四:汉诺塔: 给定盘子的数量 num,有三个塔 a, b, c,打印出 num 个盘子从 a 塔移动到 c 塔的移动顺序
def hanoi_tower(num, a, b, c):
"""
打印指定数量 num 个盘子的移动顺序
:param num: 盘子的数量
:param a: 原始位置
:param b: 中间借助位置
:param c: 目标移动位置
:return:
"""
if num == 1:
# 只有一个盘,将其移动到 C 塔
print(f"第1个盘:{a} -> {c}")
else:
# 多个盘情况:我们认为两个盘,即最下面的盘和上面所有盘
# 1.先将上面所有盘移动到 B 塔,这时需要借助 C 塔来完成移动
hanoi_tower(num - 1, a, c, b)
# 2.然后移动最底下的盘
print(f"第{num}个盘:{a} -> {c}")
# 3.最后把剩余盘从 B 塔移动到 C 塔,这时需要借助 A 塔来完成移动
hanoi_tower(num - 1, b, a, c)
# 3个汉诺塔的移动顺序
hanoi_tower(3, "A", "B", "C")
以上示例输出结果如下:
:::success
第1个盘:A -> C
第2个盘:A -> B
第1个盘:C -> B
第3个盘:A -> C
第1个盘:B -> A
第2个盘:B -> C
第1个盘:A -> C
:::
函数作为参数传递
作用
将一个函数作为参数传递给另一个函数使用,提高了代码的复用性。
示例代码如下:
# 定义一个函数,可以返回两个数的最大值
def get_max_val(num1, num2):
max_val = num1 if num1 > num2 else num2
return max_val
def f1(fun, num1, num2):
"""
功能:调用fun返回num1和num2的最大值
:param fun: 表示接收一个函数
:param num1: 传入一个数
:param num2: 传入一个数
:return: 返回最大值
"""
return fun(num1, num2)
def f2(fun, num1, num2):
"""
功能:调用fun返回num1和num2的最大值,同时返回两个数的和
:param fun:
:param num1:
:param num2:
:return:
"""
return num1 + num2, fun(num1, num2)
print(f1(get_max_val, 10, 20))
print(f2(get_max_val, 10, 20))
sum, max = f2(get_max_val, 10, 20)
print(f"sum: {sum}, max: {max}")
以上示例代码运行结果如下:
:::info
20
(30, 20)
sum: 30, max: 20
:::
示例二:计算器函数
# 定义运算函数
def add(a, b):
return a + b
def subtract(a, b):
return a - b
# 高阶函数:接受运算函数作为参数
def calculate(operation, x, y):
return operation(x, y) # 调用传入的函数
# 传递函数作为参数
print(calculate(add, 5, 3)) # 输出: 8
print(calculate(subtract, 10, 4)) # 输出: 6
注意事项
- 函数作为参数传递,传递的不是数据,而是业务处理逻辑
- 传递函数时使用函数名而非函数调用(不带括号)
- 被传递的函数需满足目标函数的参数签名
lambda匿名参数
lambda函数定义
Python使用 lambda 关键字来创建函数。
lambda 函数是一种小型的、匿名的函数,可以有任意数量的参数,但只能有一个表达式。这种特性也决定了 lambda 函数只适合编写简单的函数。
lambda 函数不需要使用 def 关键字来定义函数
常用的场景:以函数的形式传参给其他函数使用,例如在 map()、filter()、reduce()等函数中
lambda 函数特点:
- lambda 函数是匿名的,它们没有函数名称,只能通过赋值给变量或作为参数传递给其他函数来使用。
- lambda 函数通常只包含一行代码,这使得它们适用于编写简单的函数。
lambda 函数语法:
lambda arguments: expression
- lambda是 python 的关键字,用于定义匿名函数
- arguments 是匿名函数的参数列表,可以为空,也可以有多个
- expression是一个表达式,用于计算并返回结果
以下示例的 lambda 函数没有参数列表:
f = lambda: print("你好,这是一个无参函数")
f()
输出结果为:
:::color2
你好,这是一个无参函数
:::
以下 lambda 函数用于计算参数 a和 10 的求和结果,并返回:
var = lambda a: a + 10
print(f"结果为{var(15)}")
输出结果为:
:::color2
结果为25
:::
lambda 函数也可以设置多个参数,用逗号隔开。
以下示例用于计算矩形(a,b)的面积:
area = lambda a, b: a * b
print(f"矩形面积为{area(10, 5)}")
输出结果为:
:::color2
矩形面积为50
:::
lambda 函数通常与内置函数如 map()、filter() 和 reduce() 一起使用,以便在集合上执行操作。例如:
numbers = [1, 2, 3, 4, 5]
squared = list(map(lambda x: x**2, numbers))
print(squared) # 输出: [1, 4, 9, 16, 25]
使用 lambda 函数与 filter() 一起,筛选偶数:
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers) # 输出:[2, 4, 6, 8]
使用 reduce() 和 lambda 表达式计算一个序列的累积乘积:
from functools import reduce
numbers = [1, 2, 3, 4, 5]
# 使用 reduce() 和 lambda 函数计算乘积
product = reduce(lambda x, y: x * y, numbers)
print(product) # 输出:120
return 语句
return [表达式] 语句用于退出函数,选择性地向调用方返回一个表达式。不带参数值的 return 语句返回 None。
:::color2
需要说明的是,None 虽然是空,但也是一个有效的数据,通过内置函数 id()也是有对应的值的。
:::
示例代码:
def getStr():
print("hello")
res = getStr()
print(res)
print(id(res))
以上输出结果:
:::color2
hello
None
4358644536
:::
全局变量和局部变量
基本介绍
- 全局变量:定义在函数外部,在整个程序范围内都可以访问,拥有全局作用域
- 局部变量:定义在函数内部,在函数内部可以访问,拥有局部作用于
代码示例:
# n1 是全局变量
n1 = 100
def f1():
# n2是局部变量
n2 = 200
print(n2) # 200
# 可以访问全局变量n1
print(n1) # 100
# 调用
f1()
print(n1) # 100
# 不能访问局部变量n2
# print(n2) # NameError: name n2' is not defined.
注意事项
- 函数内部修改全局变量 n1,默认是新创建了一个变量n1,全局变量 n1 的值并不会被修改
n1 = 100
def f1():
# n1 重新定义了
n1 = 200
print(n1) # 200
f1()
print(n1) # 100
- python 通过
global关键字允许函数内直接修改全局变量,这种方式下的修改是真的改变了全局变量的值
n1 = 100
def f1():
# n1 重新定义了
global n1
n1 = 200 # 全局变量n1的值被改为200
print(n1) # 200
f1()
print(n1) # 200