目录
- Unsupervised Deep Embedding for Clustering Analysis (DEC 2016)
- Attributed Graph Clustering: A Deep Attentional Embedding Approach (DAEGC 2019)
- Structural Deep Clustering Network (SDCN 2020)
- Contrastive Multi-View Representation Learning on Graphs (MVGRL 2020)
- CommDGI: Community detection oriented deep graph infomax (CommDGI 2020))
- Adaptive Graph Encoder for Attributed Graph Embedding (AGE* 2020)
- Graph Contrastive Learning with Adaptive Augmentation (GCA 2021)
- Multi-view Contrastive Graph Clustering (MCGC 2021)
- Deep Fusion Clustering Network (DFCN 2021)
- Graph Debiased Contrastive Learning with Joint Representation Clustering (GDCL 2021)
- SAIL: Self-Augmented Graph Contrastive Learning (SAIL 2022)
- Augmentation-Free Self-Supervised Learning on Graphs (AFGRL 2022)
- Deep Graph Clustering via Dual Correlation Reduction (DCRN 2022)
- Attributed Graph Clustering with Dual Redundancy Reduction (AGC-DRR 2022)
- Self-consistent Contrastive Attributed Graph Clustering with Pseudo-label Prompt (SCAGC 2022)
- Scalable Self-Supervised Graph Clustering(S3GC 2022 )
- NCAGC: A Neighborhood Contrast Framework for Attributed Graph Clustering (NCAGC 2022)
- Cluster-guided Contrastive Graph Clustering Network (CCGC 2023)
- Hard Sample Aware Network for Contrastive Deep Graph Clustering (HSAN 2023)
- Simple Contrastive Graph Clustering (SCGC 2023)
- Dink-Net: Neural Clustering on Large Graphs (Dink-Net 2023)
- Attribute Graph Clustering via Learnable Augmentation (AGCLA 2023)
- CONVERT: Contrastive Graph Clustering with Reliable Augmentation (CONVERT 2023)
- Self-Contrastive Graph Diffusion Network (SCGDN 2023)
- Dual Contrastive Learning Network for Graph Clustering(MVGRL上改进DCLN 2023 )
- A Contrastive Variational Graph Auto-Encoder for Node Clustering (CVGAE 2023)
- Multi-level Graph Contrastive Prototypical Clustering (MLG-CPC 2023)
- Deep Contrastive Graph Learning with Clustering-Oriented Guidance (2024)
- Reliable Node Similarity Matrix Guided Contrastive Graph Clustering (2024)
- Deep Masked Graph Node Clustering (2024)
- Unsupervised node clustering via contrastive hard sampling (2024)
- GLAC-GCN: Global and Local Topology-Aware Contrastive Graph Clustering Network (2024)
- Revisiting Modularity Maximization for Graph Clustering: A Contrastive Learning Perspective (2024)
- Structure-enhanced Contrastive Learning for Graph Clustering (2024)
- Every Node is Different: Dynamically Fusing Self-Supervised Tasks for Attributed Graph Clustering (2024)
- ———————————————图重构———————————————
- AE, VAE,GAE,VGAE
- Rethinking Graph Auto-Encoder Models for Attributed Graph Clustering (R-GAE 2022)
- Redundancy-Free Self-Supervised Relational Learning for Graph Clustering(R2FGC 2023)
- Synergistic Deep Graph Clustering Network(Sync 2024)
- ———————————————others论文———————————————
- Contrastive-Clustering (2021)
- Select The Best: Enhancing Graph Representation with Adaptive Negative Sample Selection (2024)×强化学习
- Graph-Mamba: Towards Long-Range Graph Sequence Modeling with Selective State Spaces (2024)
- Provable Training for Graph Contrastive Learning (2023)
- ——————————————图对比学习论文—————————————
- Graph Contrastive Coding for Graph Neural Network Pre-Training (GCC 2020)
- Deep Graph Contrastive Representation Learning (GRACE 2020)
- Contrastive Multi-View Representation Learning on Graphs(MVGRL 2020)
- Graph Contrastive Learning with Augmentations(2020)
- GraphCL: Contrastive Self-Supervised Learning of Graph Representations (2021)
- Bootstrapped Graph Latents (BGRL 2021)
- Graph Contrastive Learning with Adaptive Augmentation (2021)
- SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation (2022)
- Neighbor Contrastive Learning on Learnable Graph Augmentation (2023)
- Self-Supervised Graph Representation Learning via Multi-Modal Contrast(SUGRL 2023 )
- ——————————————笔记——————————————
- *创新点
- 对比学习
- 模块度损失
- 正则化项
大多数论文可在 Awesome Graph Clustering下载
Unsupervised Deep Embedding for Clustering Analysis (DEC 2016)
- 使用重构损失进行预训练自编码器
- 网络使用簇分配硬化损失进行微调
- 使用软分配输出聚类结果
- 使用KL散度损失优化聚类 端到端优化
Attributed Graph Clustering: A Deep Attentional Embedding Approach (DAEGC 2019)
创新点:
- 我们开发了第一个基于图形注意力的自动编码器,为了有效地整合深度潜在表征学习的结构和内容信息。
- 我们提出了一种新的目标导向的分布式图聚类框架。该框架联合优化了嵌入学习和图聚类,使两个组件互惠互利。

Structural Deep Clustering Network (SDCN 2020)
- 结合GCN与自编码器:利用自编码器捕捉节点属性特征,GCN捕获图结构信息,通过传递操作符将两者动态融合。
- 双重自监督机制:通过聚类损失(KL散度)同时优化自编码器和GCN模块,确保两种信息源的一致性。

Contrastive Multi-View Representation Learning on Graphs (MVGRL 2020)
- 提出:与视觉表示学习不同,将视图数量增加到两个以上时并不能提高性能。
- 对邻接矩阵扩散生成扩散矩阵的视图
- 对两个嵌入进行GNN编码,MLP投影得到节点表示
- 对两个嵌入进行池化和MLP处理,得到图表示(对整个图的一个特征描述向量)
创新点:

CommDGI: Community detection oriented deep graph infomax (CommDGI 2020))
- Loss = 节点级对比损失 + 社区级簇中心损失 + 图级模块化损失
创新点:

Adaptive Graph Encoder for Attributed Graph Embedding (AGE* 2020)
现有的基于GCN的方法存在三个缺陷,其中图卷积滤波器和权重矩阵的纠缠()会损害性能和鲁棒性
- 精心设计的拉普拉斯平滑滤波器,过滤低频噪声(将滤波器H=I-kL中的k作为超参数,具体看AGE讲解)
- 自适应编码器,根据相似度矩阵选择可信赖的正负训练样本(动态阈值)
- Loss = 对比损失
创新点:

Graph Contrastive Learning with Adaptive Augmentation (GCA 2021)
- 数据增强方案:边丢弃(重要的边丢弃概率小,不重要的边丢弃概率大);特征掩码(保留重要节点的高频特征)。根据图的结构或节点重要性,自适应选择增强方式和强度,避免过度破坏语义信息。
节点的重要性是根据节点中心性(node centrality 是度量节点影响力广泛使用的度量),边的重要性则是根据节点对重要性- 对比学习:将相同、不同视图的不同节点都视为负样本对。

Multi-view Contrastive Graph Clustering (MCGC 2021)
- 每个节点及其 k个近邻(KNN)视为正样本对,使用InfoNce损失
- 重构视图损失
- 对比损失,样本集为特征



Deep Fusion Clustering Network (DFCN 2021)
Graph Debiased Contrastive Learning with Joint Representation Clustering (GDCL 2021)
- 图对比学习,先随机选择负样本
- KL散度损失
- 生成伪标签,从与正样本不同的簇中选择负样本,去偏假负样本

SAIL: Self-Augmented Graph Contrastive Learning (SAIL 2022)
- 知识蒸馏(将教师模型迁移到学生模型)
- 创建模型即为教师模型,注入噪声后降为学生模型,用Ht(教师模型的输出)监督学生模型
- Loss = 蒸馏损失(教师学生模型输出差异)+ 正则化项()

Augmentation-Free Self-Supervised Learning on Graphs (AFGRL 2022)
- 和GALC数据融合部分一样,全局+局部融合(KNN+A+K-means)
- 无数据增强
- 借鉴BGRL,无负样本
这里的q表示预测网络…

Deep Graph Clustering via Dual Correlation Reduction (DCRN 2022)
创新点:
- 我们提出了一种基于孪生网络的算法,以解决深度图聚类领域中表征坍塌的问题。
- 提出了一种双相关度降低策略(特征级和聚类级),以提高样本表示的判别能力。
强制跨视图样本级相相似矩阵和跨视图特征级相似矩阵分别近似两个单位矩阵- 在六个基准数据集上的广泛实验结果表明,所提出的方法优于现有方法。
Loss = Ln(节点级嵌入)+ Lf (聚类级嵌入)+ Lr(JS散度:为了缓解由GCN中的过度平滑引起的表征坍塌问题,我们引入传播正则化项)
MLP处理:
图扩散生成新的邻接矩阵
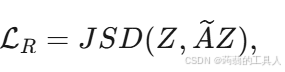



Attributed Graph Clustering with Dual Redundancy Reduction (AGC-DRR 2022)
- AGC-DRR 是首个采用对抗学习机制自适应学习邻接矩阵的属性图聚类算法
- 我们提出了一种双冗余减少策略,旨在降低输入空间和潜在特征空间中的信息冗余,从而提升聚类性能。
- 无需预训练

Self-consistent Contrastive Attributed Graph Clustering with Pseudo-label Prompt (SCAGC 2022)
- 是首个无需后处理的对比属性图聚类模型
- 通过利用聚类标签,我们提出了一种新的自监督CL损失函数
数据增强生成两个视图,经过GNN编码后再经过MLP全连接层,一个视图经过MLP生成N*K矩阵得到伪标签(簇对比),另一个视图通过伪标签对比学习(节点对比)。

Scalable Self-Supervised Graph Clustering(S3GC 2022 )
- 可扩展到超大规模数据集
- 随机游走采样,生成与给定节点相似的点
- 随机行走生成的节点被认为是正样本,而其余样本被认为是负样本
NCAGC: A Neighborhood Contrast Framework for Attributed Graph Clustering (NCAGC 2022)
- 双对比学习(节点对比+自表达对比)
- 领域对比模块:与其他对比学习方法不同,NCAGC在原始视图中选择正/负对,而不进行数据增强。
邻域对比模块利用对比学习方法通过最大化前K个最近邻节点的相似性(即正对)和最小化其他节点的相似性(即负对)来提高提取的节点表示的质量。- 自表达矩阵
对比性自表达模块被用来通过对比自表达层重构前后的节点表示来帮助学习更具辨别力的自表达系数矩阵。

Cluster-guided Contrastive Graph Clustering Network (CCGC 2023)
- 多层拉普拉斯过滤特征,使用MLP作为编码器
- 伪标签生成高置信度样本,将不同聚类中心作为负样本。
创新点:
- 我们提出了一种基于聚类的对比深度图聚类方法CCGC网络提高质量通过挖掘高置信度聚类信息改善正负样本的质量。
- 不使用精心设计的复杂图形数据增强,我们通过设计非共享参数编码器,从而避免-不恰当的图形数据引起的语义漂移。
- 六个基准数据集的广泛实验结果证明优越性。

具体做法是将负样本对的相似度矩阵(通过内积得到)与零矩阵进行比较MSE损失
将正样本对的相似度矩阵的每行之和与1进行比较:(2 - 2 * cosine_similarity)