第4章:转录处理逻辑
欢迎回来!
在之前的第3章:摘要数据结构(Pydantic模型)中,我们学习了定义会议摘要预期结构的Pydantic模型——数据如何通过行动项、决策等部分进行组织。
现在我们要解决核心挑战:如何将原始且可能冗长的会议转录文本转化为由SummaryResponse Pydantic模型定义的整洁结构化格式?
这正是转录处理逻辑的职责所在。
转录处理逻辑解决了什么问题?
假设我们有一个冗长的多页文档——可能是详细报告。
我们需要从中提取特定信息:所有提到的截止日期、做出的决策以及每个章节的简明摘要。通读整个文档来寻找所有内容可能令人应接不暇。
会议转录文本和AI模型的情况与此类似:
- 转录文本可能非常长:会议很容易生成数千甚至数万字的转录文本
- AI模型存在限制:大多数AI模型都有"上下文窗口"限制,即它们能同时处理的文本量上限。这个限制通常远小于长转录文本。我们无法直接将整个转录文本交给AI并要求"总结并找出行动项"——文本量会超出限制
- 需要结构化数据:如第3章所述,我们不仅需要自由格式的文本摘要,更需要可预测结构(如
SummaryResponsePydantic模型)中的特定数据点(行动项、决策)
**转录处理逻辑**组件解决了这些问题。它就像熟练的分析师,知道如何分解长报告,逐节阅读,从每个部分提取所需信息,最终将所有内容整合成结构化的执行摘要。
在我们的项目中,该逻辑主要由backend/app/transcript_processor.py中的TranscriptProcessor类处理。
逻辑的核心思想
转录处理逻辑的核心方法包含以下步骤:
- 分块处理:将长转录文本分割为更易管理的小块(“分块”)
- 重叠处理:使这些分块存在部分重叠。这非常重要,可以避免跨分块边界的行动项或决策被遗漏
- AI分块处理:将每个小块发送给AI模型(通过下一章将介绍的Pydantic-AI代理实现的AI模型交互)
- 提取结构化数据:AI被特别指示(借助Pydantic-AI代理和第3章的Pydantic模型)返回该分块的结构化信息(如行动项、决策)
- 结果聚合:收集所有处理分块的结构化结果
- 最终组装:将所有分块的结构化数据组合成代表整个会议摘要的最终
SummaryResponse对象
在整体流程中的位置
让我们回顾第1章:后端API网关的流程,了解转录处理逻辑的位置:
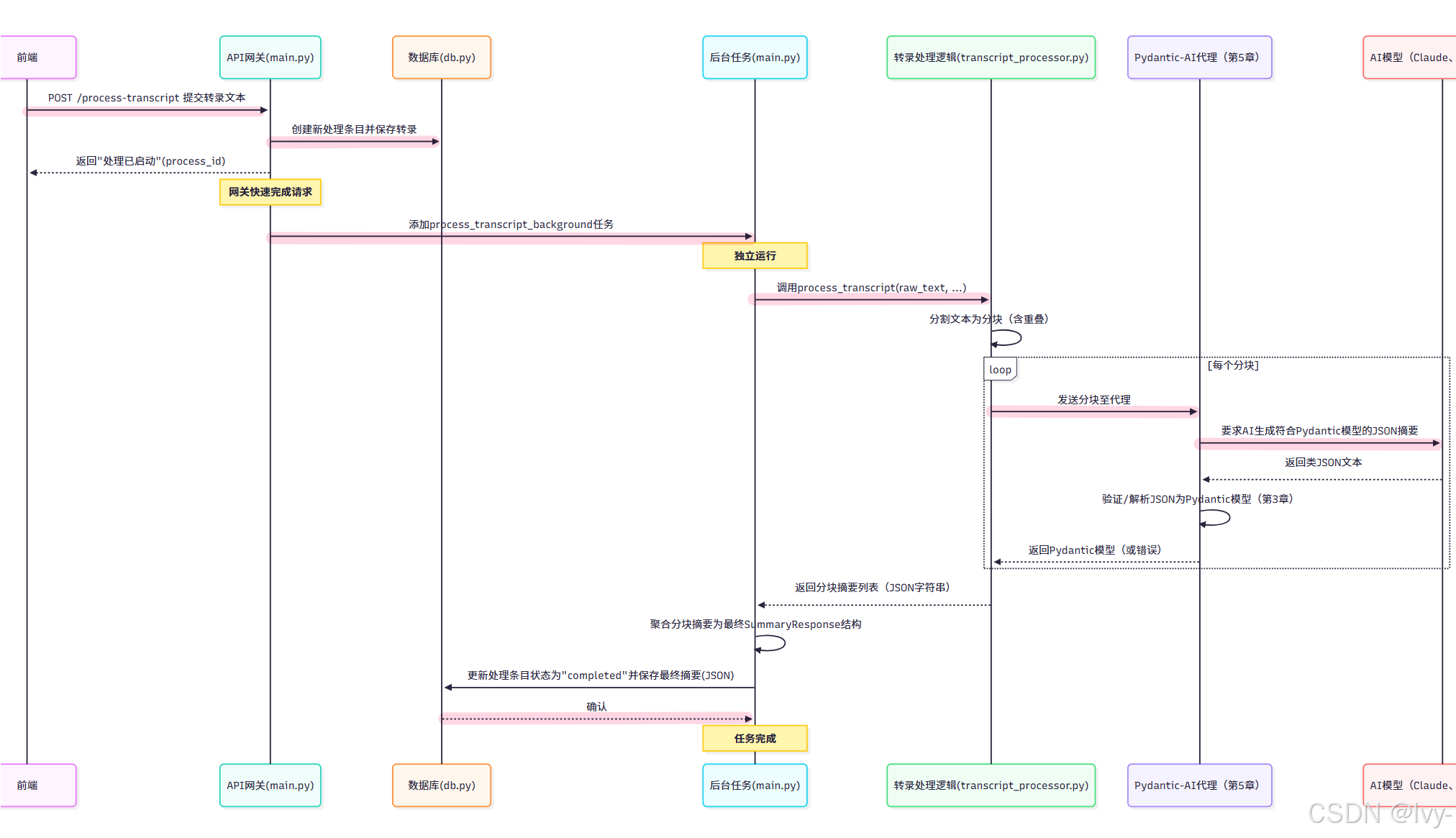
如流程所示,API网关(APIGateway)接收请求后,快速将实际繁重工作交给BackgroundTask。
BackgroundTask随后调用转录处理逻辑(TranscriptProcessor)。
TranscriptProcessor负责关键的分块工作,将这些分块通过AIAgent发送给AI,获取结构化数据并返回结果进行聚合。BackgroundTask随后处理最终聚合并将结果保存到Database。
逐步解析:TranscriptProcessor内部
让我们查看backend/app/transcript_processor.py中TranscriptProcessor类的核心部分。
首先看类结构和初始化:
# backend/app/transcript_processor.py(简化版)
from typing import List, Tuple
# 导入必要库和Pydantic模型
from pydantic import BaseModel # 第3章已介绍
from pydantic_ai import Agent # 将在第5章介绍
# ... 导入具体AI模型类(AnthropicModel、OllamaModel等)
import logging
from db import DatabaseManager # 第6章介绍
logger = logging.getLogger(__name__)
db = DatabaseManager() # 获取数据库实例
# (此处定义Block、Section、SummaryResponse等Pydantic模型 - 参见第3章)
# class Block(BaseModel): ...
# class Section(BaseModel): ...
# class SummaryResponse(BaseModel): ...
class TranscriptProcessor:
"""使用AI模型处理会议转录文本"""
def __init__(self):
"""初始化转录处理器"""
logger.info("TranscriptProcessor已初始化")
# 实际应用中可能在此加载模型配置,但我们通过调用时获取
pass # 简化版
说明:
- 导入必要类型和类,包括第3章定义的Pydantic模型
- 获取日志记录器和
DatabaseManager实例(第6章详述,处理器可能需要从数据库获取API密钥) - 定义
TranscriptProcessor类,__init__方法保持简洁,主要逻辑在process_transcript中
接下来是关键方法process_transcript:
# backend/app/transcript_processor.py(简化版)
# ...(导入和类__init__)...
class TranscriptProcessor:
# ... __init__方法 ...
async def process_transcript(self, text: str, model: str, model_name: str, chunk_size: int = 5000, overlap: int = 1000) -> Tuple[int, List[str]]:
"""
将转录文本分块处理,生成每个分块的结构化摘要
"""
logger.info(f"处理转录文本,分块大小={chunk_size},重叠={overlap}")
all_json_data = [] # 存储每个分块JSON摘要的列表
agent = None # 稍后初始化
try:
# --- 简化版:选择和初始化AI模型及代理 ---
# 这部分涉及从数据库获取API密钥(第6章)
# 并创建正确的Agent(第5章)
# 此处展示代理创建的简化示例:
# 示例:使用Ollama(假设已运行)
# 实际根据'model'参数条件选择
from pydantic_ai.models.ollama import OllamaModel
llm = OllamaModel(model_name=model_name)
agent = Agent(
llm,
result_type=SummaryResponse, # 告知代理需要SummaryResponse蓝图数据
result_retries=3, # 若AI输出格式错误则重试
)
logger.info(f"为模型{model_name}初始化代理完成")
# --- 文本分块 ---
step = chunk_size - overlap
# 处理重叠过大的边界情况
if step <= 0:
logger.warning("重叠≥分块大小,调整重叠参数")
overlap = max(0, chunk_size - 100) # 调整重叠
step = chunk_size - overlap # 重新计算步长
chunks = [text[i:i+chunk_size] for i in range(0, len(text), step)]
num_chunks = len(chunks)
logger.info(f"将转录文本分割为{num_chunks}个分块")
# --- 处理每个分块 ---
for i, chunk in enumerate(chunks):
logger.info(f"处理分块 {i+1}/{num_chunks}...")
try:
# --- 要求AI代理处理此分块 ---
# 指示代理返回符合SummaryResponse模型的数据
summary_result = await agent.run(
f"""根据以下会议转录分块,按照要求的JSON结构({SummaryResponse.model_json_schema()})提取相关信息。若无相关内容,返回空块。转录分块:--- {chunk} ---""",
# 实际应用中可在此添加上下文信息
)
# 结果'summary_result'应为SummaryResponse对象(感谢Pydantic-AI!)
# 需要从代理响应中获取实际数据
if hasattr(summary_result, 'data') and isinstance(summary_result.data, SummaryResponse):
final_summary_pydantic = summary_result.data
elif isinstance(summary_result, SummaryResponse):
final_summary_pydantic = summary_summary_result
else:
logger.error(f"分块{i+1}的代理返回类型异常:{type(summary_result)},跳过分块")
continue # 跳过此分块
# 将Pydantic对象转回JSON字符串存储/传递
chunk_summary_json = final_summary_pydantic.model_dump_json()
all_json_data.append(chunk_summary_json)
logger.info(f"成功生成分块{i+1}的JSON摘要")
except Exception as chunk_error:
logger.error(f"处理分块{i+1}时出错:{chunk_error}", exc_info=True)
# 决定如何处理分块错误(如添加错误标记,跳过)
logger.info(f"完成所有{num_chunks}个分块的处理")
# 返回分块数和JSON字符串列表
return num_chunks, all_json_data
except Exception as e:
logger.error(f"转录处理过程中出错:{str(e)}", exc_info=True)
raise # 重新抛出异常供后台任务捕获
说明:
- 初始化:初始化空列表
all_json_data存储分块结果 - AI模型及代理设置:该部分(代码中已简化)根据
model和model_name参数选择正确的AI模型(AnthropicModel、OllamaModel等),然后使用pydantic-ai库创建Agent实例,关键是指定result_type为第3章的SummaryResponse模型,从而指导AI生成结构化输出 - 分块处理:将转录
text分割为chunks。逻辑使用chunk_size和overlap确定每个块的大小和重叠量。例如,chunk_size=100和overlap=20时,第一个块是字符0-99,第二个是字符80-179,第三个是160-259,依此类推。step即chunk_size - overlap - 处理循环:遍历每个
chunk agent.run():对每个分块调用await agent.run(...)。这是与AI核心交互的部分。pydantic-ai代理将chunk文本发送给配置的AI模型,附带指令(“prompt”)要求按SummaryResponse的Pydantic模式生成JSON格式摘要。pydantic-ai库处理与AI的通信,并尝试将AI的文本输出解析/验证为SummaryResponse对象- 结果收集:若代理成功返回有效的
SummaryResponse对象(final_summary_pydantic),则通过model_dump_json()转换为JSON字符串并加入all_json_data列表。此处存储JSON字符串因其易于传递和存储(如可能存储在数据库中间步骤,不过简化流程中直接由后台任务聚合) - 返回结果:处理所有分块后,方法返回总分块数和JSON字符串列表(
all_json_data)
try…except
try 块是 Python 中用于异常处理的结构,包裹可能发生错误的代码。
当 try 块中的代码出现异常时,程序会跳转到对应的
except块处理错误,避免程序崩溃。
异常处理方式
外层 try 捕获整个处理流程的异常并记录,内层 try 针对单个分块处理错误进行捕获,确保一个分块出错不影响其他分块处理。
分块摘要聚合
process_transcript方法返回JSON字符串列表,每个字符串代表单个分块的结构化摘要。最后一步是将这些摘要组合成整个会议的最终摘要。
该步骤发生在backend/app/main.py的process_transcript_background函数中(调用TranscriptProcessor的后台任务)。
查看聚合逻辑的简化片段:
# backend/app/main.py(简化版process_transcript_background片段)
# ...(导入和函数定义)...
async def process_transcript_background(process_id: str, transcript: TranscriptRequest):
"""处理转录的后台任务"""
try:
# ...(调用processor.process_transcript)...
num_chunks, all_json_data = await processor.process_transcript(...)
# 创建最终聚合摘要的结构
final_summary = {
"MeetingName": "", # 尝试从分块获取
"SectionSummary": {"title": "章节摘要", "blocks": []},
"CriticalDeadlines": {"title": "关键截止日期", "blocks": []},
"KeyItemsDecisions": {"title": "关键项与决策", "blocks": []},
"ImmediateActionItems": {"title": "即时行动项", "blocks": []},
"NextSteps": {"title": "后续步骤", "blocks": []},
"OtherImportantPoints": {"title": "其他要点", "blocks": []},
"ClosingRemarks": {"title": "结束语", "blocks": []}
}
# 遍历每个分块的JSON摘要
for json_str in all_json_data:
try:
json_dict = json.loads(json_str) # 转换为Python字典
# 聚合会议名称(取首个找到的)
if "MeetingName" in json_dict and json_dict["MeetingName"]:
if not final_summary["MeetingName"]: # 未设置时才设置
final_summary["MeetingName"] = json_dict["MeetingName"]
# 聚合各部分的块
for key in final_summary:
# 检查分块数据中是否存在该键及'blocks'列表
if key != "MeetingName" and key in json_dict and isinstance(json_dict[key], dict) and "blocks" in json_dict[key]:
# 将分块中的blocks扩展到最终列表
if isinstance(json_dict[key]["blocks"], list):
final_summary[key]["blocks"].extend(json_dict[key]["blocks"])
except json.JSONDecodeError as e:
logger.error(f"解析JSON分块失败:{e},数据:{json_str[:100]}...")
# 处理错误——可能跳过该分块数据
# ...(将final_summary保存至数据库——第6章介绍)...
await processor.db.update_process(process_id, status="completed", result=json.dumps(final_summary))
except Exception as e:
# ...(处理错误并更新数据库状态)...
pass
说明:
- 初始化最终结构:创建字典
final_summary,预填充预期键和每个部分空列表,匹配SummaryResponse结构(此处用Python字典表示) - 遍历聚合:遍历
TranscriptProcessor返回的all_json_data列表。每个json_str(代表单个分块的SummaryResponse的JSON字符串)转换为Python字典(json_dict) - 组合块:对每个相关部分键(如
ImmediateActionItems、KeyItemsDecisions),检查分块的json_dict是否有该部分数据。若有,将该分块的blocks(行动项、决策等列表)扩展(extend)到final_summary字典的对应列表中 - 会议名称:通常从首个找到会议名称的分块摘要数据中提取
- 保存:最终将完整的
final_summary字典(现在包含所有分块聚合的块)转换为JSON字符串并保存到该处理条目的数据库(详见第6章:数据库管理)
这种简单聚合策略有效,因为每个分块摘要提取该分块中存在的特定条目(行动项、决策)。
通过组合所有分块的这些条目列表,我们获得整个转录文本的完整列表。整体摘要可能稍欠连贯,但对从长文本提取离散结构化条目是有效策略。
要点
- 转录处理逻辑是分析原始会议转录文本的核心组件
- 其主要挑战是通过分块和重叠处理长转录文本
使用**AI模型**(通过第5章的Pydantic-AI代理)从每个分块提取结构化信息(匹配Pydantic模型)- 收集所有分块的结构化结果并聚合为单一最终摘要结构
- 该处理发生在后端API网关启动的后台任务中,前端可快速获得响应
- 聚合后的最终摘要通过数据库管理系统保存
该组件是后端智能的核心,将复杂问题(理解长会议)分解为AI可处理的小块,然后将结果重组为有用的结构化格式。方便了测试和工程化
总结
我们已经看到TranscriptProcessor严重依赖"AI模型"和"Pydantic-AI代理"来获取分块的结构化数据。但我们的代码如何具体与AI模型交互?什么是"Pydantic-AI代理"?
下一章我们将深入探讨AI模型交互,重点介绍pydantic-ai库如何帮助我们与不同AI服务商通信,并特别请求符合Pydantic蓝图的数据。