参考链接:(28 封私信) 《CLIP-Adapter》上海AI Lab&罗格斯大学&港中文提出CLIP-Adapter,用极简方式微调CLIP中的最少参数! - 知乎 coOp方法:《coOp: learning to prompt for vision-language models》 ——Clip的prompt-tuning-CSDN博客
灵魂三问
动机是什么?
具体怎么实现的?
达到了什么效果?
动机
动机和coOp都一样,因为Clip的hard prompt难设计,或者说各种prompt最后实现的效果不同,很难决定说到底用哪种hard prompt。
coOp是提出了学习连续的soft prompt,也就是用few-shot(1-16)个样本去微调出合适的prompt 提升效果。
直接使用少量样本对整个网络参数进行微调很有可能会发生过拟合问题,所以Clip-Adapter提出只调整少量额外权重,而不是优化CLIP所有的参数。
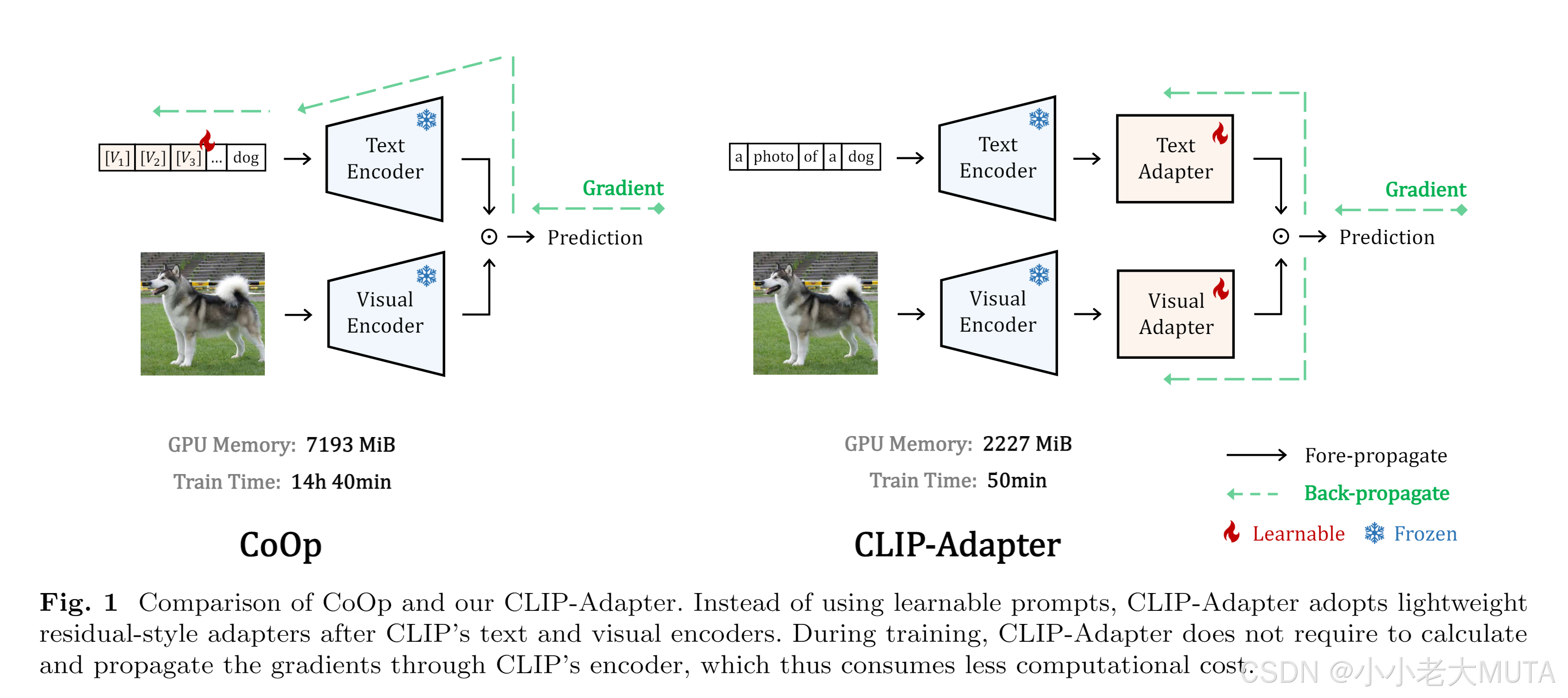
具体实现
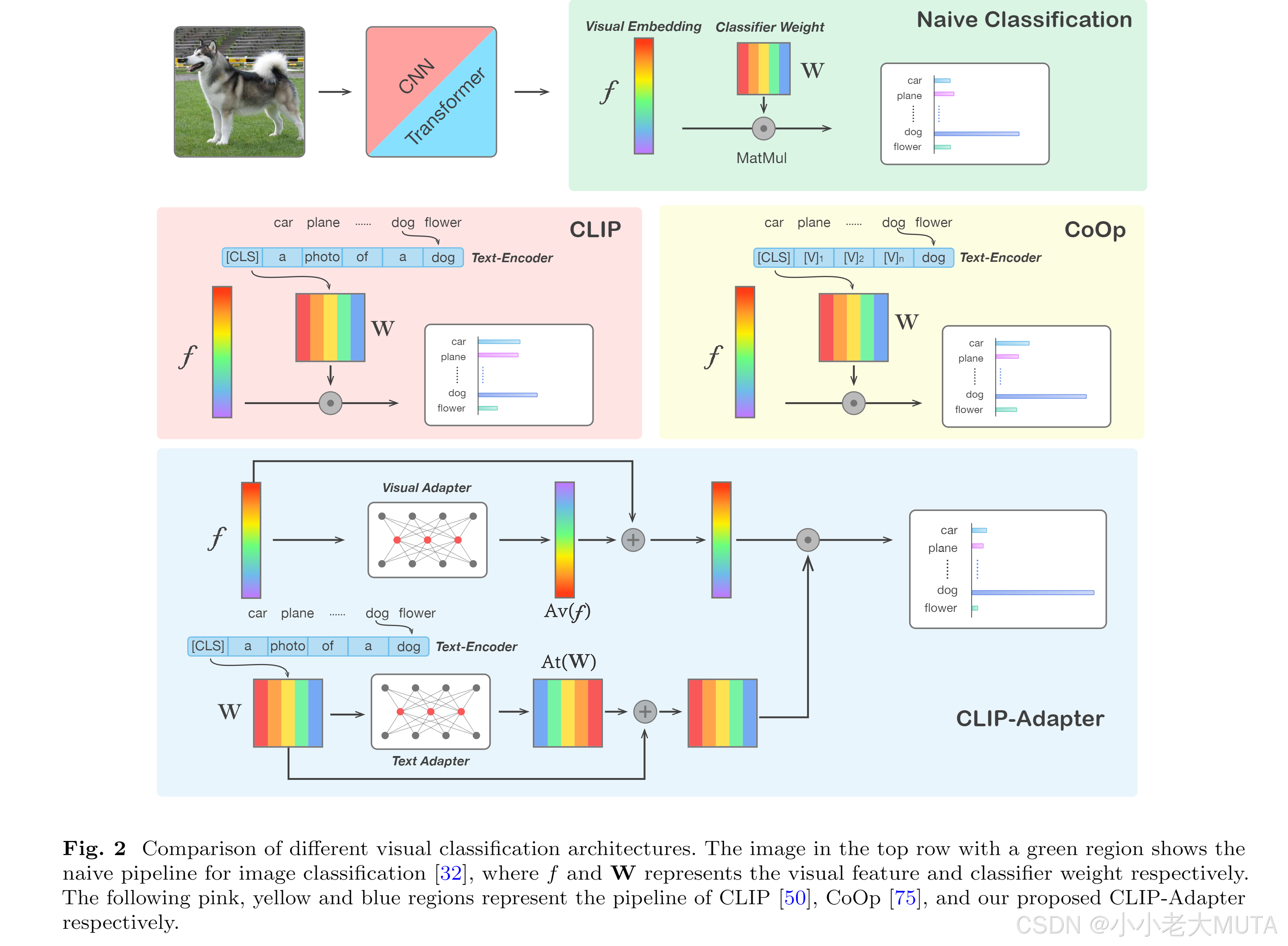
1. 在CLIP 的 Text Encoder 和 Visual Encod面,分别加上一个Adapter。
具体而言,这个Adapter就是两个MLP + 残差链接的实现,下图蓝色部分。
Adapter
公式4中:f是图像编码器输出的特征,W是原始CLIP图像主干的分类器权重;
公式5中:第一个W是文本编码器输出的特征,后面的W是原始CLIP文本主干的分类权重。
下面有实验结果显示reduction为4的时候效果最好。
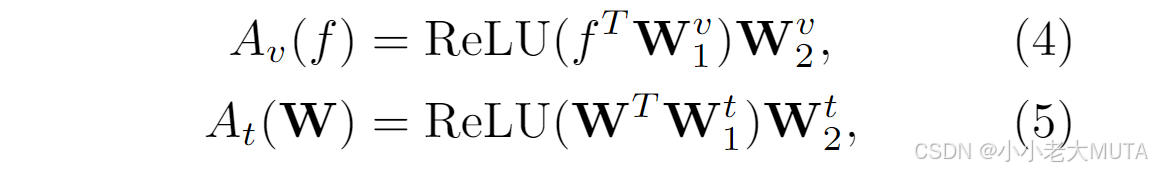
残差连接
采用残差连接来动态地将微调后的知识与CLIP主干中的原始知识混合;
将公式4得到的图像Adapter输出 与 原来的Image Encoder输出以一定比例相加(α常量);
文本特征同理。
α,β是超参数,超参数不同结果不同,下面有实验结果对比
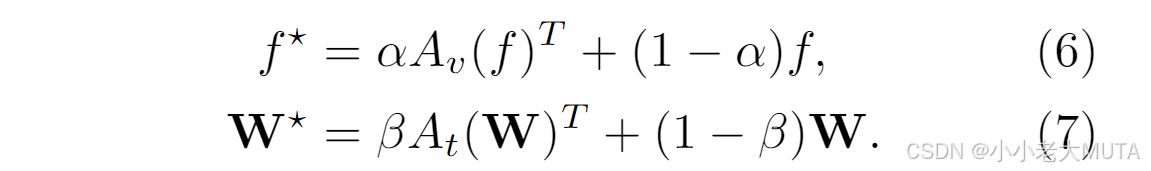
为什么要残差连接?
通过残差连接将原始预训练特征与微调后的特征混合,动态平衡新旧知识。
将复杂的映射问题分解为相对简单的子问题。网络只需学习输入与输出之间的残差,而不是直接学习复杂的映射。
简化学习问题、改善梯度流动和支持更深网络。
有三种变体:只有图像的Adapter; 只有文本的Adapter; 图像文本都有的Adapter.
实验部分有结果显示只有图像的Adapter效果最好。
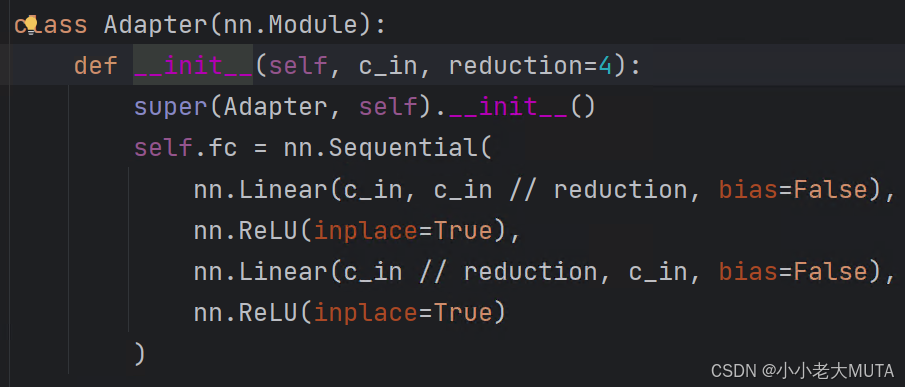
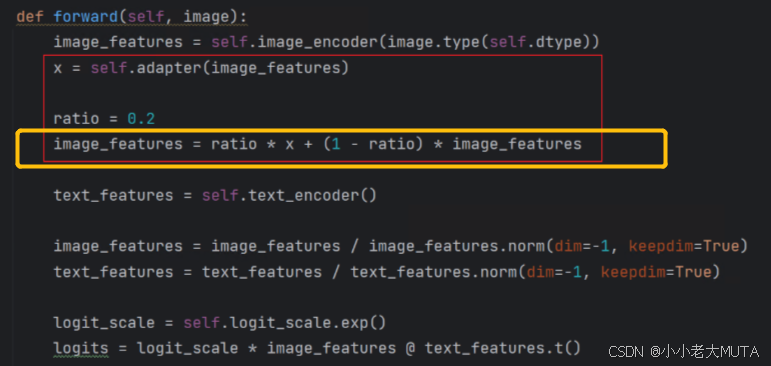
下面代码展示的只有图像的Adapter:
实验结果
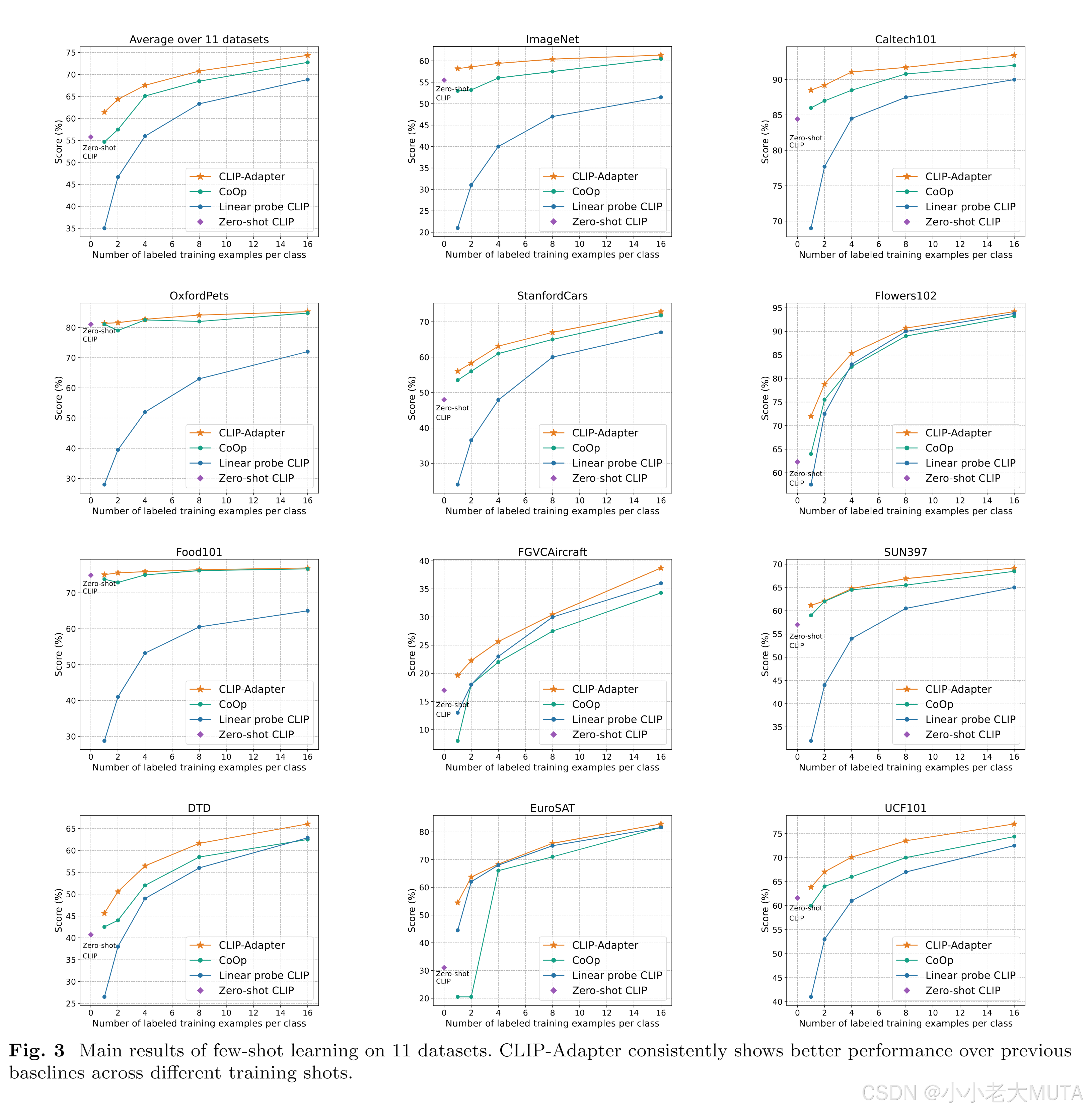
不同bootleneck layer隐藏层维度的结果:
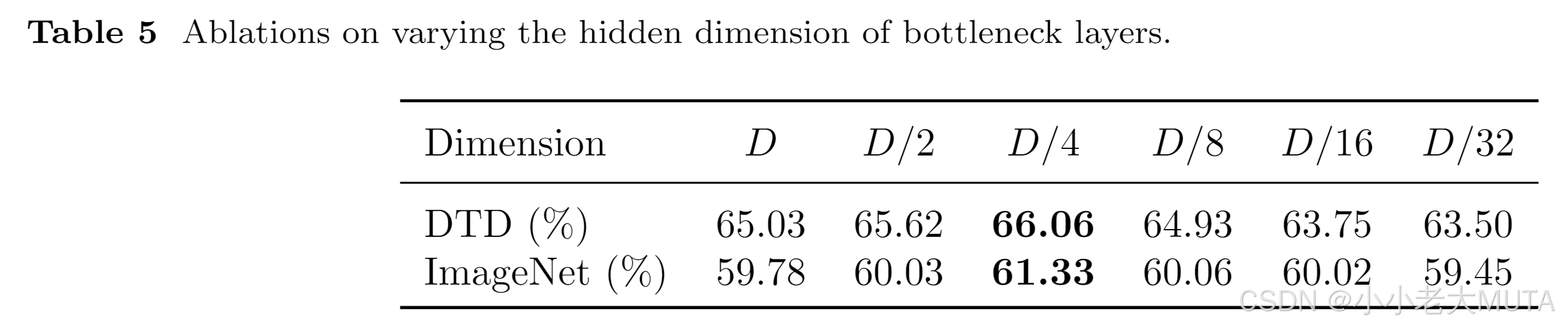
不同残差比的实验结果:
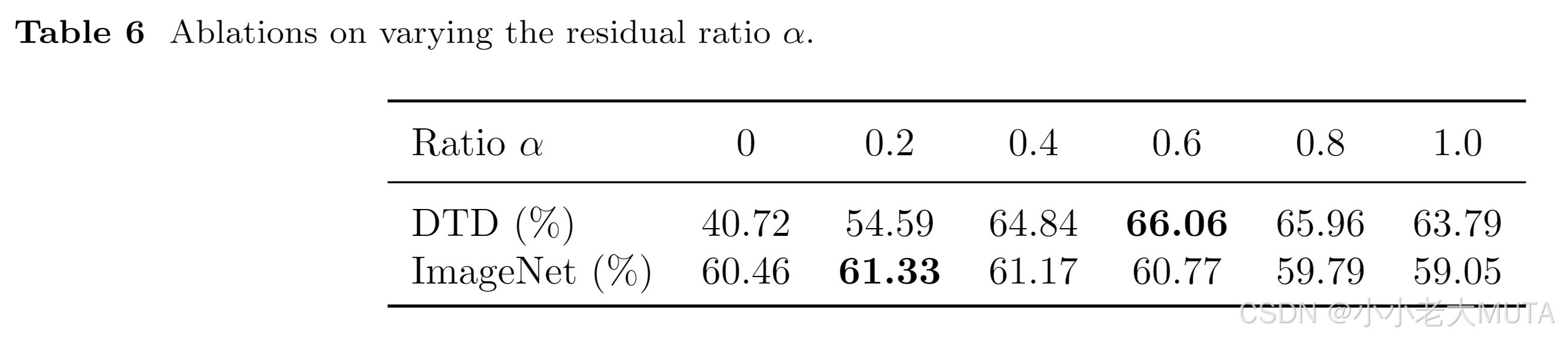
三种变体的结果对比:
可以看出只对图像做Adapter的效果最好。
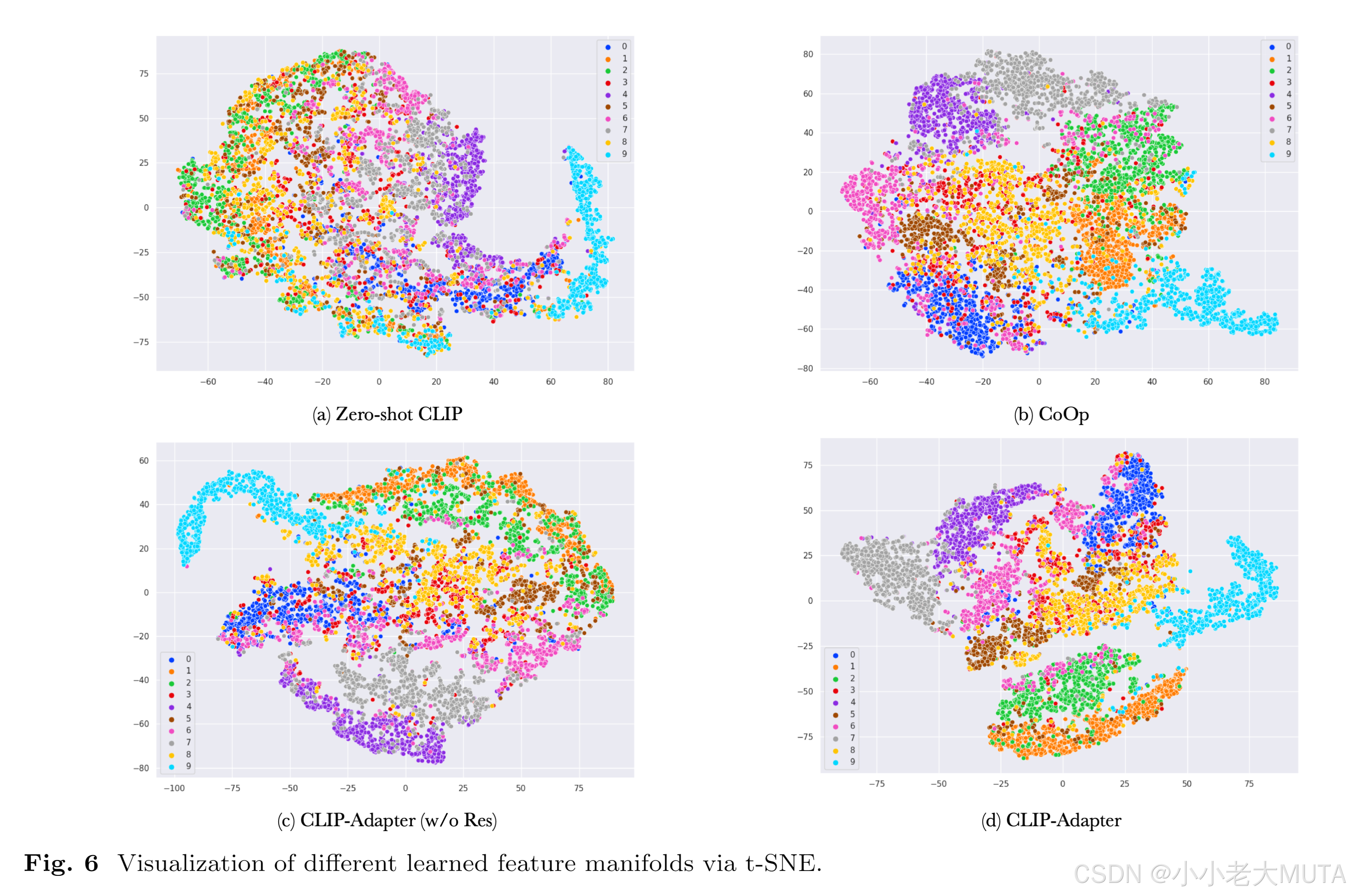
同类图形的相似性: