写在前面
本文基于Pytorch,采用CNN卷积神经网络实现手写数字识别,共采用了2个卷积层、1个池化层和2个线性层。
实验准备
首先需要先导入必要的依赖包
import torch
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
from model import CNN然后需要准备数据集并进行加载
# 1. 数据准备
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 下载并加载训练集和测试集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)随后定义了CNN卷积模型,包含2个卷积层、1个最大池化层以及2个线性层
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = self.dropout1(x)
x = x.view(-1, 64 * 7 * 7) # 展平
x = torch.relu(self.fc1(x))
x = self.dropout2(x)
x = self.fc2(x)
return x初始化参数
# 2. 定义模型
model = CNN().to(device)
# 3. 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)训练与测试
训练函数
def train(model, device, train_loader, optimizer, criterion, epoch):
model.train()
train_loss = 0
correct = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss += loss.item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
train_loss /= len(train_loader.dataset)
accuracy = 100. * correct / len(train_loader.dataset)
print(f'Train Epoch: {epoch} \tLoss: {train_loss:.6f} \tAccuracy: {accuracy:.2f}%')
return train_loss, accuracy
测试函数
# 5. 测试函数
def test(model, device, test_loader, criterion):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'Test set: Average loss: {test_loss:.6f} \tAccuracy: {accuracy:.2f}%')
return test_loss, accuracy训练出最优模型
def main():
epochs = 10
best_accuracy = 0.0
model_save_path = 'best_model.pth'
for epoch in range(1, epochs + 1):
train_loss, train_acc = train(model, device, train_loader, optimizer, criterion, epoch)
test_loss, test_acc = test(model, device, test_loader, criterion)
# 保存最佳模型
if test_acc > best_accuracy:
best_accuracy = test_acc
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': test_loss,
'accuracy': test_acc
}, model_save_path)
print(f"New best model saved with accuracy: {best_accuracy:.2f}%")
print(f"Training complete. Best test accuracy: {best_accuracy:.2f}%")实际预测
加载模型
def load_model(model_path):
model = CNN()
checkpoint = torch.load(model_path, map_location='cpu') # 使用CPU加载
model.load_state_dict(checkpoint['model_state_dict'])
model.eval() # 设置为评估模式
return model图像预处理
def preprocess_image(image_path):
# 与训练时相同的转换
transform = transforms.Compose([
transforms.Grayscale(), # 转换为灰度图
transforms.Resize((28, 28)), # MNIST是28x28
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
image = Image.open(image_path)
image = transform(image).unsqueeze(0) # 添加batch维度
return image预测函数
def predict(model, image_tensor):
with torch.no_grad():
output = model(image_tensor)
_, predicted = torch.max(output.data, 1)
probabilities = torch.softmax(output, dim=1)
return predicted.item(), probabilities.squeeze().tolist()可视化函数
def visualize_prediction(image_path, prediction, probabilities):
image = Image.open(image_path)
plt.imshow(image, cmap='gray')
plt.title(f'Predicted: {prediction}')
plt.axis('off')
# 显示概率分布
plt.figure()
plt.bar(range(10), probabilities)
plt.xticks(range(10))
plt.xlabel('Digit')
plt.ylabel('Probability')
plt.title('Prediction Probabilities')
plt.show()主函数
def recognition(image_path):
# 参数设置
model_path = 'best_model.pth'
# 加载模型
model = load_model(model_path)
print("Model loaded successfully.")
# 预处理图像
image_tensor = preprocess_image(image_path)
# 进行预测
prediction, probabilities = predict(model, image_tensor)
print(f"Predicted digit: {prediction}")
print("Probabilities for each digit (0-9):")
for i, prob in enumerate(probabilities):
print(f"{i}: {prob * 100:.2f}%")
# 可视化结果
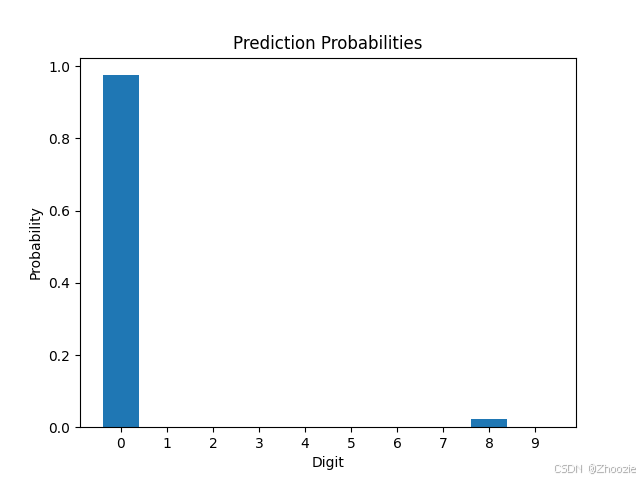
visualize_prediction(image_path, prediction, probabilities)最后,调用主函数检测手写数字体。以手写数字0为例

检测结果如下所示,展示了CNN模型对每一个数字的检测概率,据条形图可知数字0的概率最大。